***本文章为个人记录***
目录
一、模拟登录知乎
(第一次运行程序)先模拟登录->保存cookie?
(其次运行程序)->运行已保存的cookie
????????模拟登录时没有做验证码处理,所以延时10秒手动通过验证码进行登录。登录后再将知乎账号数据cookie保存起来,为下次爬取浏览器直接使用(下次使用时不需要再进行模拟登录
第一次运行程序:
# 方法覆盖 每次启动spider前,都启动模拟登录
def start_requests(self):
from selenium.webdriver.chrome.options import Options
url = "https://www.zhihu.com/signin?next=%2F"
chrome_options = Options()
chrome_options.add_argument("--disable-extensions")
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(executable_path='C:/Users/86135/MySpider/chromedriver.exe',chrome_options=chrome_options)
# 模拟登录知乎
browser.get('https://www.zhihu.com/signin?next=%2F')
browser.find_element(By.XPATH,'//*[@id="root"]/div/main/div/div/div/div/div[1]/div/div[1]/form/div[1]/div[2]').click()
browser.find_element(By.CSS_SELECTOR,".SignFlow-account input[name='username']").send_keys("你的账号")
browser.find_element(By.CSS_SELECTOR,".SignFlow-password input[name='password']").send_keys("你的密码")
time.sleep(1)
move(700,500)
click()
browser.find_element(By.XPATH,'//*[@id="root"]/div/main/div/div/div/div/div[1]/div/div[1]/form/button').click()
time.sleep(10) # 手动通过验证码
# cookies保存浏览器数据,为下次打开浏览器做准备
browser.get("https://www.zhihu.com/")
cookies = browser.get_cookies()
pickle.dump(cookies,open("C:/Users/86135/MySpider/cookies/zhihu.cookie","wb"))
cookie_dict = {}
for cookie in cookies:
cookie_dict[cookie["name"]] = cookie["value"]
return [scrapy.Request(url=self.start_urls[0],dont_filter=True,cookies=cookie_dict)]其次运行程序:
# 方法覆盖 每次启动spider前,都启动模拟登录
def start_requests(self):
# cookies读取已保存的浏览器数据,继续爬取
cookies = pickle.load(open("C:/Users/86135/MySpider/cookies/zhihu.cookie","rb"))
cookie_dict={}
for cookie in cookies:
cookie_dict[cookie["name"]] = cookie["value"]
return [scrapy.Request(url=self.start_urls[0],dont_filter=True,cookies=cookie_dict)]保存的cookies路径?
二、提取知乎question页面url
????????如果提取到question相关的url则下载后交由parse_question函数进行提取
def parse(self, response):
"""
提取出html页面中的所有url 并跟踪url进一步爬取
如果提取的url格式为 /question/xxx 下载之后直接进入解析函数
"""
all_urls = response.css("a::attr(href)").extract()
all_urls = [parse.urljoin(response.url, url) for url in all_urls]
all_urls = filter(lambda x: True if x.startswith("https") else False, all_urls)
for url in all_urls:
match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", url) # 提取url以'/'或者结束符结尾的内容
if match_obj:
# 如果提取到question相关的也url则下载后交由提取函数进行提取
request_url = match_obj.group(1) # question_url
# scrapy通过yield提交到下载器
yield scrapy.Request(request_url, headers=self.headers, callback=self.parse_question)
# break
else:
# 如果不是question页面则直接进一步跟踪
yield scrapy.Request(url, headers=self.headers, callback=self.parse) # 不符合继续提取
# pass三、提取question页面具体数据
????????通过items.py编写ZhihuQuestionItem(),定义item_loader对象加载想要提取的question页面各个具体数据,然后提交到下载器进行数据保存。同时将页面answer(json数据)提交格式输出到parse_answer函数进行提取相关回答数据。
# question的第一页answer的请求url
start_answer_url = 'https://www.zhihu.com//api/v4/questions/{}/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Creaction_instruction%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cvip_info%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset=3&limit=5&sort_by=default&platform=desktop/api/v4/questions/39684414/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Creaction_instruction%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cvip_info%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset={}&limit={}'
def parse_question(self, response):
# 处理question页面,从页面中提取具体的question item
match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", response.url) # 提取question_id
if match_obj:
question_id = match_obj.group(2) # question_url-Id
item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response)
item_loader.add_css("title", "h1.QuestionHeader-title::text")
item_loader.add_css("content", ".QuestionRichText")
item_loader.add_value("url", response.url)
item_loader.add_value("zhihu_id", question_id)
item_loader.add_css("answer_num", ".List-headerText span::text")
item_loader.add_css("comments_num", ".QuestionHeader-Comment button::text")
item_loader.add_css("watch_user_num", ".NumberBoard-itemValue::text")
item_loader.add_css("click_num",".NumberBoard-itemValue::text")
item_loader.add_css("topics", '.QuestionHeader-topics .Popover div::text')
item_loader.add_value("crawl_time", datetime.datetime.now().strftime(SQL_DATETIME_FORMAT))
question_item = item_loader.load_item()
# 起始0 每页20个数据
yield scrapy.Request(self.start_answer_url.format(question_id, 0, 20), headers=self.headers,
callback=self.parse_answer)
# 提交到下载器
yield question_item四、提取answer页面具体数据
????????加载由parse_question函数提交的json数据,提取出具体字段后提交到下载器进行数据保存。
def parse_answer(self, response):
ans_json = json.loads(response.text)
is_end = ans_json["paging"]["is_end"]
next_url = ans_json["paging"]["next"]
# 提取answer的具体字段
for answer in ans_json["data"]:
answer_item = ZhihuAnswerItem()
answer_item["zhihu_id"] = answer["id"]
answer_item["url"] = answer["url"]
answer_item["question_id"] = answer["question"]["id"]
answer_item["author_id"] = answer["author"]["id"] if "id" in answer["author"] else None
answer_item["content"] = answer["content"] if "content" in answer else None
answer_item["parise_num"] = answer["voteup_count"]
answer_item["comments_num"] = answer["comment_count"]
answer_item["create_time"] = answer["created_time"]
answer_item["update_time"] = answer["updated_time"]
# answer_item["crawl_time"] = datetime.datetime.now()
yield answer_item
pass
if not is_end:
yield scrapy.Request(next_url, headers=self.headers, callback=self.parse_answer)
五、items.py的编写
????????编写question_item和answer_item类,并定义插入数据库函数,将Mysql插入语句及提取的数据params返回到pipelines进行数据库保存。
class ZhihuQuestionItem(scrapy.Item):
# 知乎的问题 item
zhihu_id = scrapy.Field()
topics = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
answer_num = scrapy.Field()
comments_num = scrapy.Field()
watch_user_num = scrapy.Field()
click_num = scrapy.Field()
crawl_time = scrapy.Field()
def get_insert_sql(self):
insert_sql="""
insert into zhihu_question(zhihu_id,topics,url,title,content,answer_num,
comments_num,watch_user_num,crawl_time,click_num)
values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)ON DUPLICATE KEY UPDATE title=VALUES(title)
"""
zhihu_id=self["zhihu_id"][0]
topics=",".join(self["topics"])
url=self["url"][0]
title="".join(self["title"])
content="".join(self["content"])
answer_num=extract_num("".join(self["answer_num"]))
comments_num=extract_num("".join(self["comments_num"]))
watch_user_num="".join(self["watch_user_num"][0])
click_num="".join(self["click_num"][1])
crawl_time=datetime.datetime.now().strftime(SQL_DATETIME_FORMAT)
params = (zhihu_id,topics,url,title,content,answer_num,comments_num,watch_user_num,crawl_time,click_num)
return insert_sql,params
class ZhihuAnswerItem(scrapy.Item):
# 知乎的回答 item
zhihu_id = scrapy.Field()
url = scrapy.Field()
question_id = scrapy.Field()
author_id = scrapy.Field()
content = scrapy.Field()
parise_num = scrapy.Field()
comments_num = scrapy.Field()
create_time = scrapy.Field()
update_time =scrapy.Field()
# crawl_time = scrapy.Field()
def get_insert_sql(self):
# 插入知乎question表的sql语句
insert_sql="""
insert into zhihu_answer(zhihu_id,url,question_id,author_id,content,praise_num,
comments_num,create_time,update_time)
values(%s,%s,%s,%s,%s,%s,%s,%s,%s)ON DUPLICATE KEY UPDATE zhihu_id=VALUES(zhihu_id)
"""
create_time=datetime.datetime.fromtimestamp(self['create_time'])
update_time=datetime.datetime.fromtimestamp(self['update_time'])
params = (
self["zhihu_id"],self["url"],self['question_id'],
self['author_id'],self['content'],self['parise_num'],
self['comments_num'],create_time,update_time,
# self['crawl_time']
)
return insert_sql,params六、pipelines的编写
????????由items中的get_insert_sql函数返回的两个参数inset_sql、params,在Mysql异步入库中的do_insert函数中提取两个参数,执行SQL语句,将数据存储到数据库。
# 异步入Mysql库
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,settings):
# 登录参数在settings中
dbparms = dict(
host = settings['MYSQL_HOST'],
db = settings['MYSQL_DBNAME'],
user = settings['MYSQL_USER'],
passwd = settings['MYSQL_PASSWORD'],
charset = 'utf8',
cursorclass = DictCursor,
use_unicode = True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider)
def handle_error(self,failure,item,spider):
print(failure)
def do_insert(self,cursor,item):
insert_sql,params = item.get_insert_sql()
cursor.execute(insert_sql, params) # 执行数据库语句,将数据存入SQL数据库中
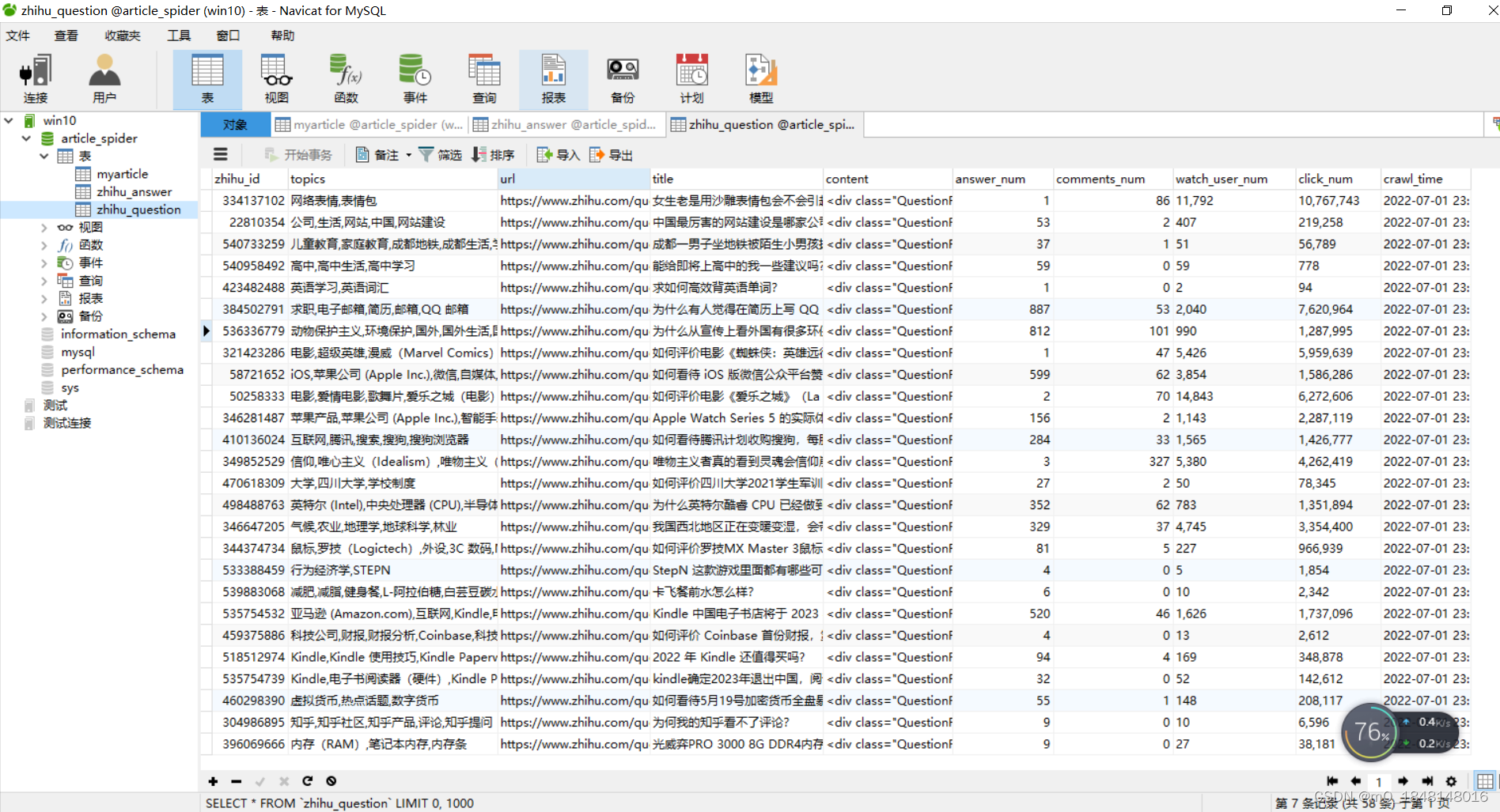
pass七、Mysql数据库存储结果
question表
?answer表