今日内容
目录
-
绝对导入与相对导入
-
包的概念
-
编程思想的转变
-
软件开发目录规范
-
常见内置模块
绝对导入与相对导入
只要有模块的导入,那么sys.path一定是以执行文件为主
-
绝对导入
其实就是以执行文件的sys.path为主,然后一层层往下找 eg: from core import src 如果有多层的话,可以通过点查找。 eg: from aaa.bbb.ccc import d绝对导入的利弊:1.绝对导入是首选,因为它们非常明确和直接。仅仅通过查看语句就可以很容易地确定导入资源的位置,此外,即使导入语句的当前位置发生更改,绝对导入仍然有效。事实上,PEP 8明确建议绝对导入。
2.有时绝对导入会变得相当冗长,这取决于目录结构的复杂性。这个时候可以考虑相对路径如果我们想肯定不报错的话,就是永远从根目录开始往下一层层查找
如果不是pycharm的话,就需要我们自动将项目根目录加到sys.path下面 -
相对导入
from . import b . 表示当前路径 .. 表示上一级路径 ../.. 表示上两级路径相对导入可以不参考执行文件所在的路径 直接以当前模块文件路径为准
相对导入的利弊1.相对导入的一个明显优势是它们相当简练。根据当前位置,它们可以将你之前看到的冗长的可笑的导入语句转换为简单的语句。
2.只能在模块文件中使用 不能在执行文件中使用,相对导入在项目比较复杂的情况下 可能会出错推荐使用绝对导入,少用相对导入
包的概念
思考
-
如何理解包?
专业的角度:内部含有__init__.py的文件夹
直观的角度:就是一个文件夹 -
包的作用
内部存放多个py文件(模块文件) 仅仅是为了更加方便的管理模块文件 -
包的具体使用
import 包名导入包名其实导入的是里面的__init__.py文件(该文件里面有什么你才能用什么)
其实也可以跨过__init__.py直接导入包里面的模块文件
eg:
from bao import name
print(name) # 是找__init__里面的
针对python3解释器 其实文件夹里面有没有__init__.py已经无所谓了 都是包
但是针对Python2解释器 文件夹下面必须要有__init__.py才能被当做包
编程思想的转变
1.基础阶段(单文件)
此阶段写代码就是在一个文件内不停地堆叠代码的行数(面条版本)
2.函数阶段(单文件)
此阶段写代码我们学会了将一些特定功能的代码封装到函数中供后续反复调用
3.模块阶段(多文件)
此阶段不单是将功能代码封装成函数,并且将相似的代码功能拆分到不同的py文件中便于后续的管理
小白阶段相当于将所有的文件全部存储在C盘并且不分类
函数阶段相当于将所有的文件在C盘下分类存储
模块阶段相当于将所有的文件按照功能的不同分门别类到不同的盘中
目的为了更加方便快捷高效的管理资源
软件目录开发规范
我们在以后的工作中,一个项目是由很多的文件和文件夹组成的,而且这些文件都各种有各自的意义和作用
| 文件名 | 作用 |
|---|---|
| bin | 用于存储程序的启动文件 |
| lib | 用于存储程序的公共功能 |
| log | 用于存储程序的日志文件 |
| core | 用于存储程序的核心逻辑 |
| conf | 用来存储配置文件 |
| db | 用来存储数据文件 |
| interface | 用于存储程序的接口文件 |
| readme文件(文本文件) | 用于编写程序的说明、介绍、广告 类似于产品说明书 |
| requirements.txt文件 | 用于存储程序所需的第三方模块名称和版本 |
总结
1.目录的名字可以不一致,但是大致的意思要相近
2.主要作用是为了方便管理,解耦合
常见的内置模块
-
collections模块
这个模块为我们提供了很多数据类型
我们可以通过CTRL+右键点击collections,我们可以看到它具备的一些功能
__all__ = ['deque', 'defaultdict', 'namedtuple', 'UserDict', 'UserList',
'UserString', 'Counter', 'OrderedDict', 'ChainMap']
| 名称 | 功能 |
|---|---|
| namedtuple | 生成可以使用名字来访问元素内容的元组(tuple) |
| deque | 双端队列,可以快速的从另外一侧追加和推出对象 |
| Counter | 计数器,主要用来计数 |
| OrderedDict | 有序字典 |
| defaultdict | 带有默认值的字典 |
eg:
namedtuple
from collections import namedtuple # 导入模块
Point = namedtuple('三维坐标系', ['x', 'y', 'z'])
res1 = Point(1, 3, 6)
res2 = Point(10, 49, 66)
print(res1, res2) # 三维坐标系(x=1, y=3, z=6) 三维坐标系(x=10, y=49, z=66)
print(res1.x) # 1
print(res1.y) # 3
from collections import namedtuple # 导入模块
Point = namedtuple('扑克牌', ['花色', '点数'])
res1 = Point('?', '2')
res2 = Point('?', 'A')
print(res1, res2) # 扑克牌(花色='?', 点数='2') 扑克牌(花色='?', 点数='A')
eg:
deque
from collections import deque # 导入模块
q = deque()
q.append(111) # 添加数据
q.append(222)
q.append(333)
q.append(444)
q.appendleft(555) # 在队列的左边添加数据
print(q) # deque([555, 111, 222, 333, 444])
eg:
OrderedDict
输出有序的字典,本来字典是无序的
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
print(d)
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od)
defaultdict
简介:
默认字典,是内置数据类型dict的一个子类,基本功能与dict一样,只是重写了一个方法missing(key)和
增加了一个可写的对象变量default_factory
语法结构
collections.defaultdict([default_factory[, …]])
eg:
from collections import defaultdict
res = defaultdict(k1=[],k2=[])
print(res) # defaultdict(None, {'k1': [], 'k2': []})
Counter
简介:
计数器,可以支持方便、快速的计数,将元素数量统计,然后计数并返回一个字典,键为元素,值为元素个数。
eg:
from collections import Counter
res = 'abcdeabcdabcaba'
res1 = Counter(res)
print(res1) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
-
时间模块之time模块
和时间有关系的我们就要用到时间模块。在使用模块之前,应该首先导入这个模块。
常用方法
1.time.sleep(secs)
(线程)推迟指定的时间运行。单位为秒。
2.time.time()
获取当前时间戳
时间的三种格式
1.时间戳(timestamp):
通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
2.格式化的时间字符串(Format String):
eg: ‘2022-7-14’
3.元组(struct_time) :
元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
time.gmtime() 以元组方式返回格林威治时间
三种格式之间的转换
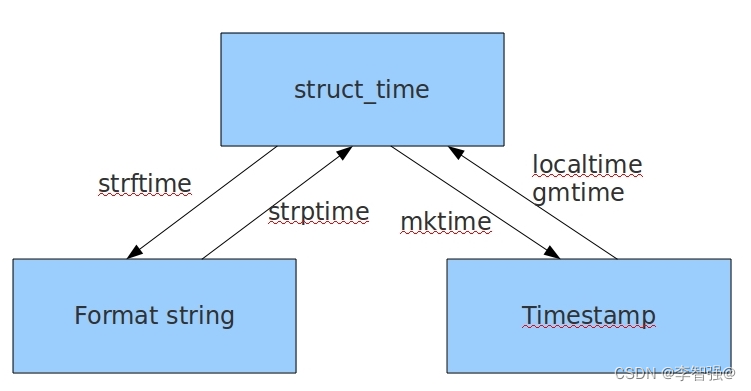
eg:
import time
print(time.strftime("%Y-%m-%d %X")) # 2022-07-14 20:22:27 # 格式化时间
print(time.strftime("%Y-%m-%d %H-%M-%S")) # 2022-07-14 20-54-45
import time
print(time.strptime('2022-07-14 20:22:27', "%Y-%m-%d %H:%M:%S"))
# time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=20, tm_min=22, tm_sec=27, tm_wday=3, tm_yday=195, tm_isdst=-1)
import time
print(time.gmtime()) # 结构化时间
# time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=12, tm_min=28, tm_sec=46, tm_wday=3, tm_yday=195, tm_isdst=0)