pandas学习(二) Filtering and Sorting Data
- drop_duplicates() 删除数据集中的重复项
- .loc() 只能使用标签索引,不能使用整数索引
- .iloc() 只能使用整数索引,不能使用标签索引
- .isin() 检查 DataFrame 是否包含指定的值
- .startswith() 选择以“”字母开头的数据
1.数据集-1
导入数据
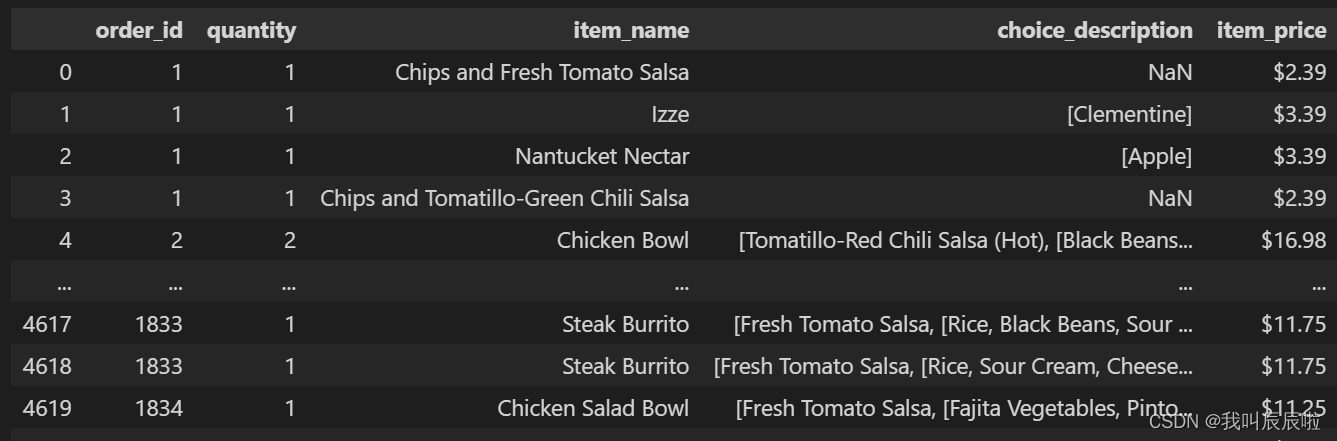
1.1 有多少产品的价格超过 $10.00?
# 将数据类型转化为float
prices = [float(value[1 : -1]) for value in chipo.item_price]
# 将数据放入新的一列
chipo.item_price = prices
# 删除数据中的重复项
chipo_filtered = chipo.drop_duplicates(['item_name','quantity','choice_description'])
# 仅选择quantity等于 1 的产品
chipo_one_prod = chipo_filtered[chipo_filtered.quantity == 1]
chipo_one_prod
# 选择出价格超过10
# chipo_one_prod[chipo_one_prod['item_price']>10].item_name.nunique()
chipo_one_prod[chipo_one_prod['item_price']>10]
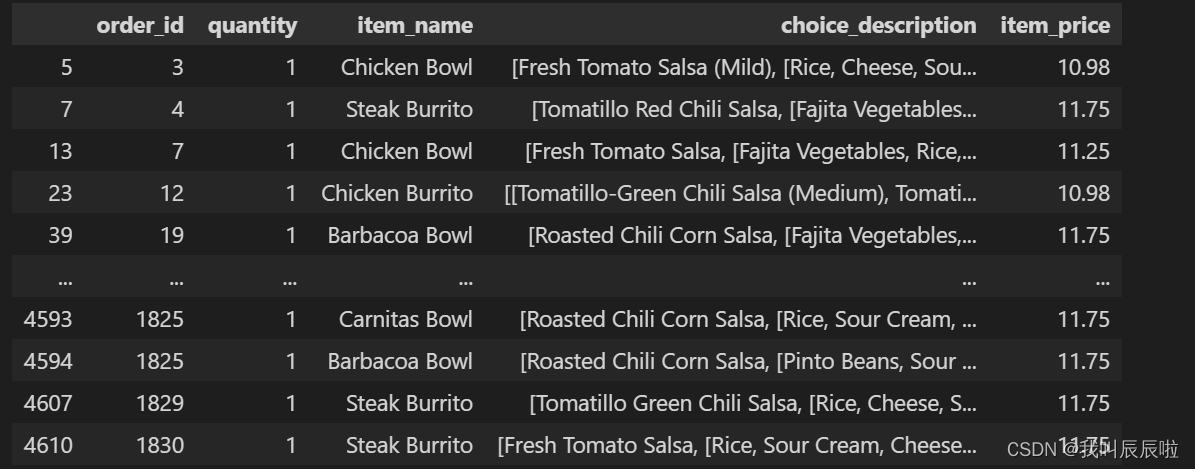
1.2 每件物品的单价是多少?
# 删除item_name和quantity完全重复的
chipo_filtered = chipo.drop_duplicates(['item_name','quantity'])
# 筛选出'item_name'是'Chicken Bowl'的,且数量为1的
chipo[(chipo['item_name'] == 'Chicken Bowl') & (chipo['quantity'] == 1)]
# select only the products with quantity equals to 1
# chipo_one_prod = chipo_filtered[chipo_filtered.quantity == 1]
# select only the item_name and item_price columns
# price_per_item = chipo_one_prod[['item_name', 'item_price']]
# sort the values from the most to less expensive
# price_per_item.sort_values(by = "item_price", ascending = False).head(20)
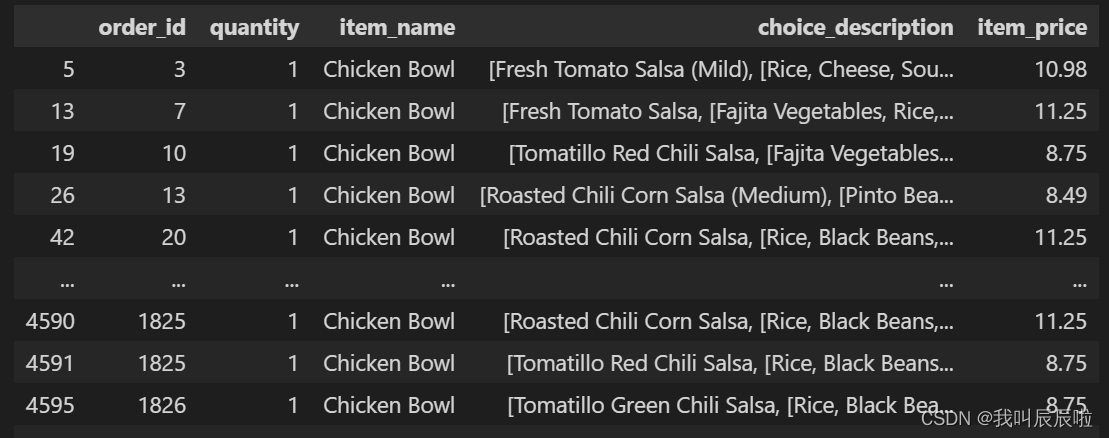
1.3 根据item_name排序
chipo.item_name.sort_values()
# OR
chipo.sort_values(by = "item_name")
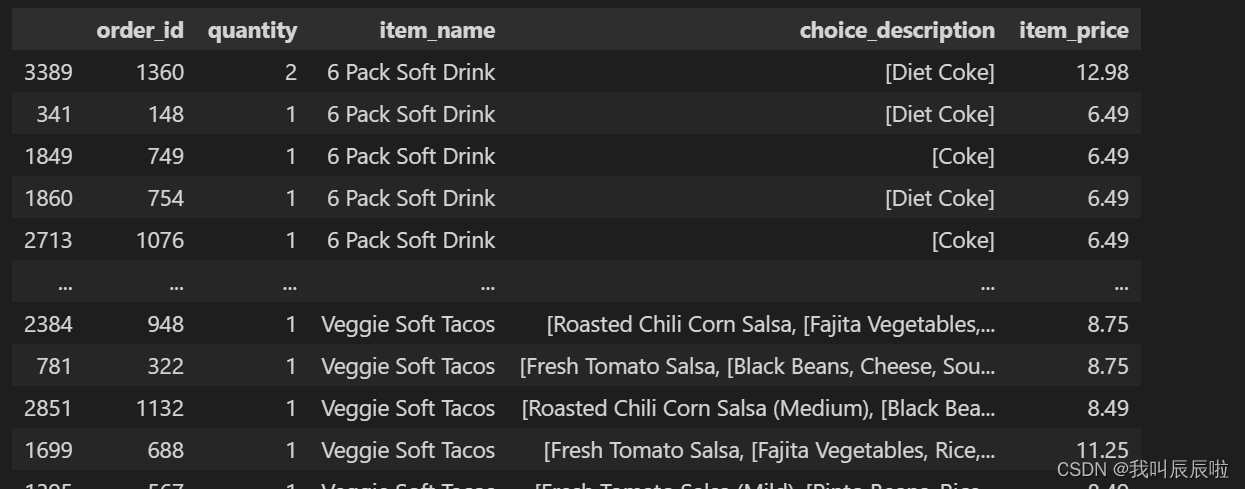
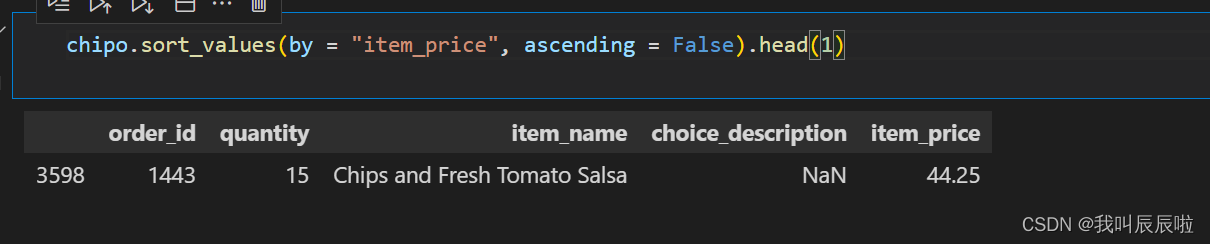
1.4 订购的最贵商品的数量是多少?
chipo.sort_values(by = "item_price", ascending = False).head(1)
1.5 通过len()统计Veggie Salad Bowl 被点了多少次
chipo_salad = chipo[chipo.item_name == "Veggie Salad Bowl"]
len(chipo_salad)
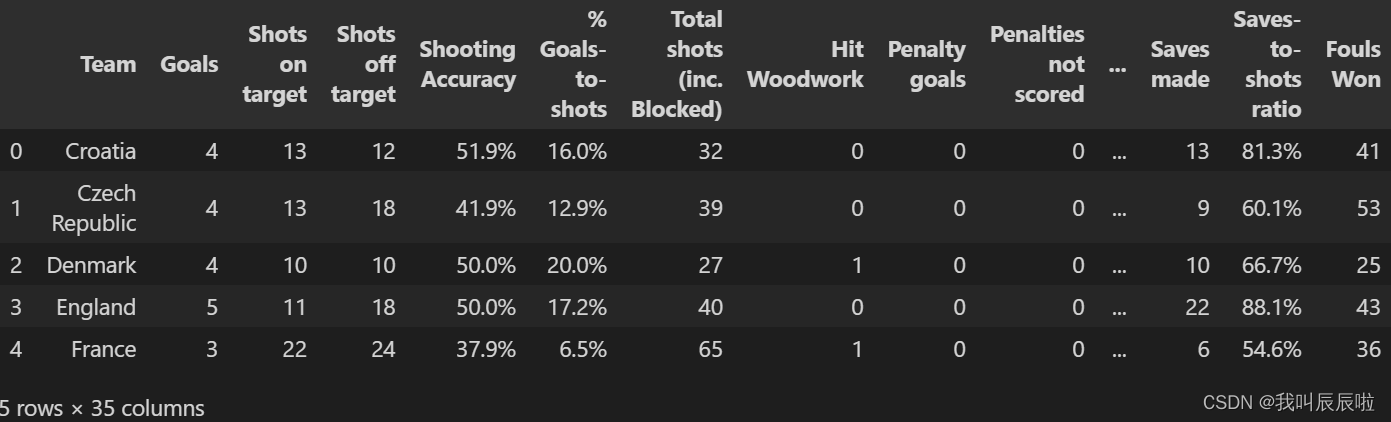
2.数据集・2
导入数据
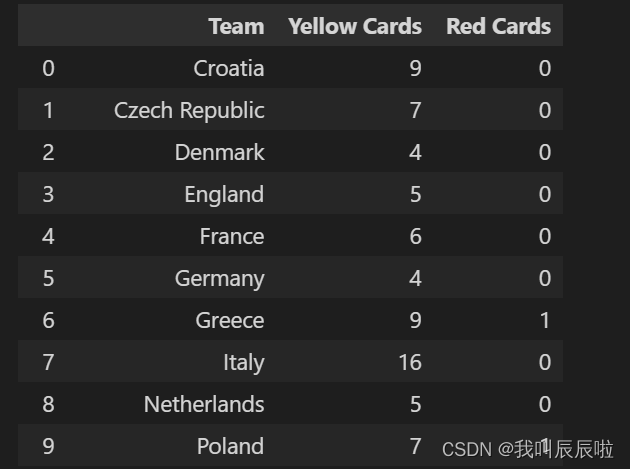
2.1 仅查看“Team”、“Yellow Cards”和“Red Cards”列,并将它们分配给称为“discipline”的数据
# filter only giving the column names
discipline = euro12[['Team', 'Yellow Cards', 'Red Cards']]
discipline
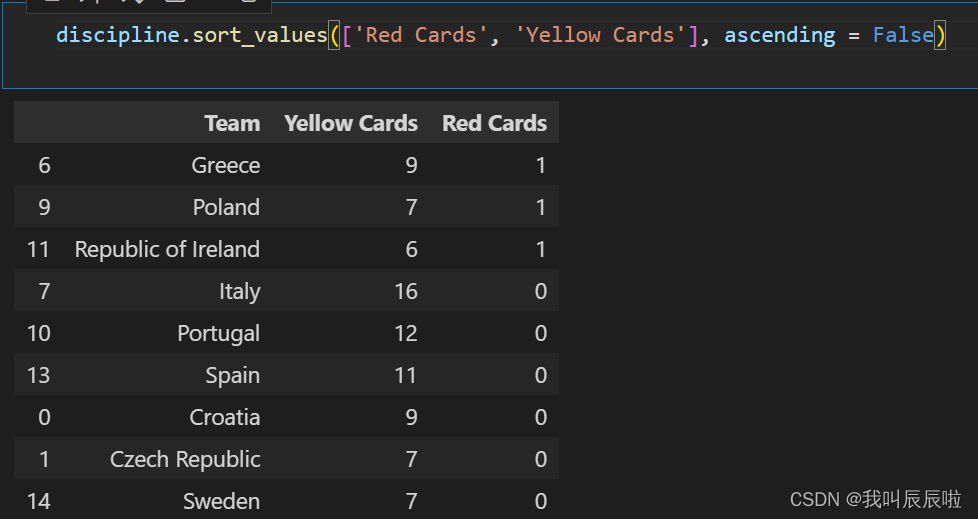
2.2 按Red Cards和Yellow Cards排序
discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending = False)
2.3 计算每支球队的平均黄牌
round(discipline['Yellow Cards'].mean())
2.4 选择出进球数高于6的球队
euro12[euro12.Goals > 6]
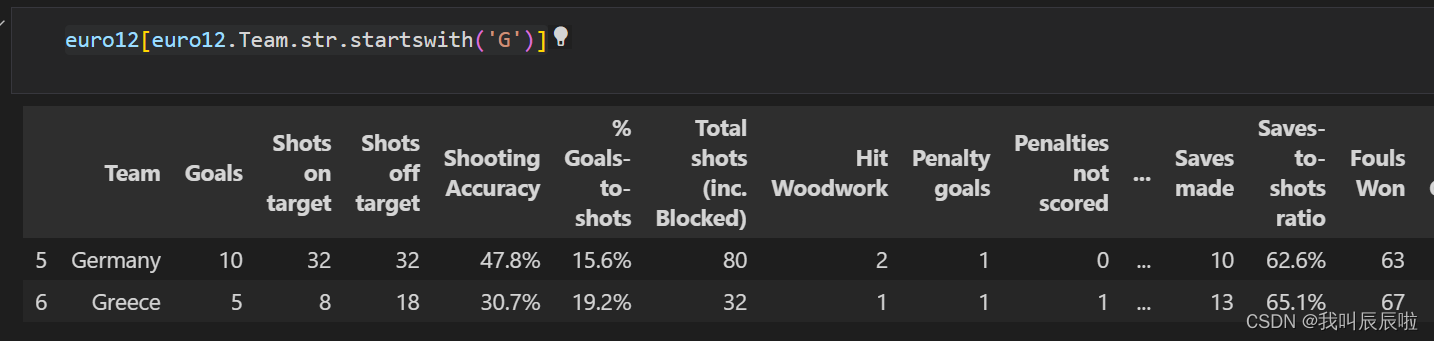
2.5 选择以 G 开头的团队
euro12[euro12.Team.str.startswith('G')]
2.6 选择前7行
# df.loc[] 只能使用标签索引,不能使用整数索引
# df.iloc[] 只能使用整数索引,不能使用标签索引
euro12.iloc[: , 0:7]
2.7 选择除最后 3 列之外的所有列。
# use negative to exclude the last 3 columns
euro12.iloc[: , :-3]
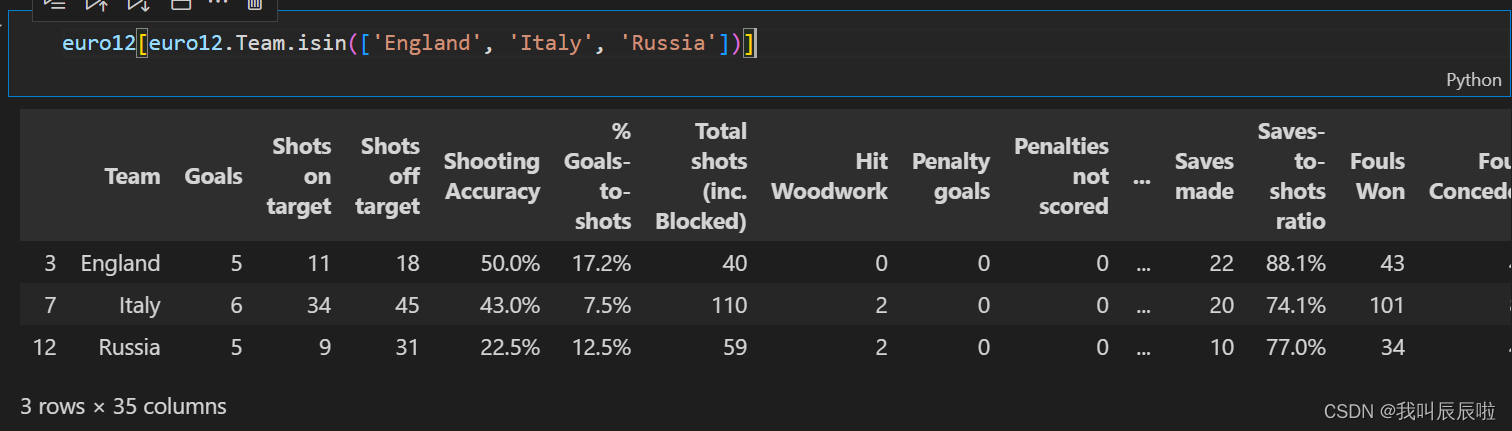
2.8 只展示 England, Italy and Russia 的 Shooting Accuracy
# isin()方法检查 DataFrame 是否包含指定的值。
# 它返回与原始 DataFrame 类似的 DataFrame,但如果该值是指定值之一,则原始值已替换为 True,否则为 False
euro12.Team.isin(['England', 'Italy', 'Russia'])

euro12[euro12.Team.isin(['England', 'Italy', 'Russia'])]
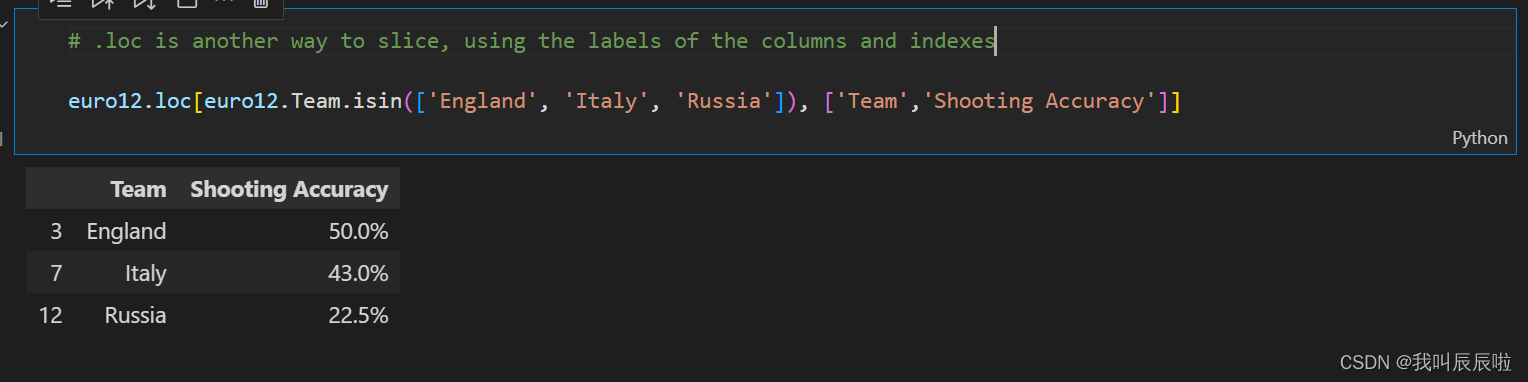
# .loc is another way to slice, using the labels of the columns and indexes
euro12.loc[euro12.Team.isin(['England', 'Italy', 'Russia']), ['Team','Shooting Accuracy']]
3.数据集-3
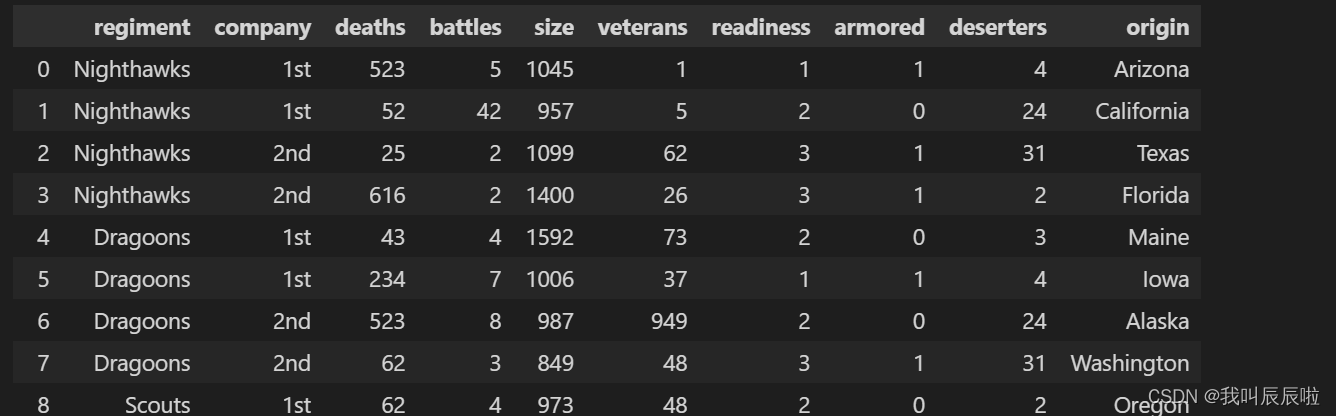
3.1 将origin设置为dataframe的index
army.set_index('origin', inplace=True)
army.head()
3.2 选择3到7行和3到6列
army.iloc[2:7, 2:6]
3.3 选择 deaths 大于 50
army[army["deaths"] > 50]
3.4 选择所有 regiments 名字不为 “Dragoons” 的
army[army["regiment"] != "Dragoons"]
3.5 选择叫 Texas 和 Arizona 的
army.loc[["Texas", "Arizona"], :]
3.6 选择名为 death 的列中的第三个单元格
army.loc[:, ["deaths"]].iloc[2]