想要抓取一个视频:
- 找到m3u8 (各种手段)
- 通过m3u8下载到ts文件
- 可以通过各种手段(不仅是编程手段) 把ts文件合并为一个mp4文件
找到一个视频网址打开,查看源码和F12

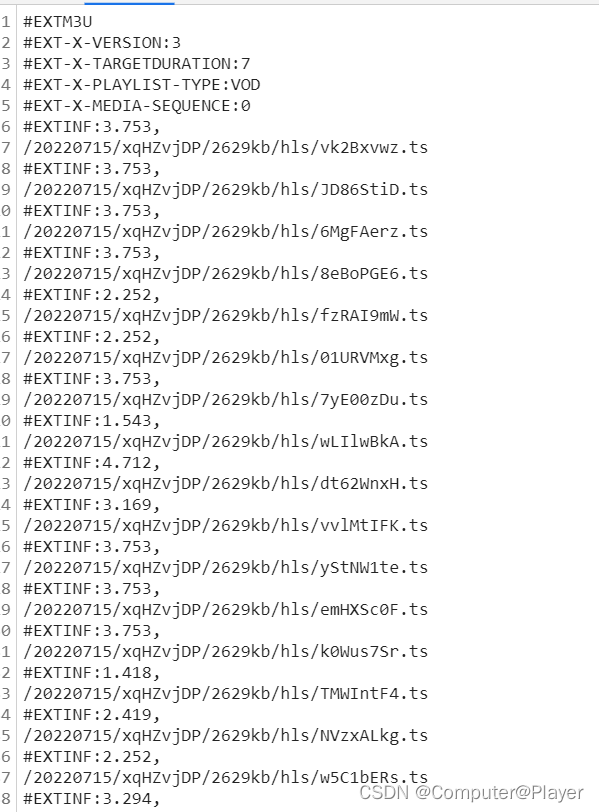
获取该链接,但是发现不是真正的m3u8

真正的m3u8在这个链接里面
从中获取合成真正的m3u8下载地址
先用代码完成这一部分:
url='http://48ys.top/vodplay/cW7JJJJN-1-1.html'
headers = {'User-Agent': str(UserAgent().random)}
resp = requests.get(url,headers=headers)
res=re.compile(r'"link_pre":"","url":"(?P<url>.*?)",', re.S)# re.S: 让.能匹配换行符
m3u8_url = res.search(resp.text).group('url')
m3u8_url = m3u8_url.replace('\\','')
truth_left = m3u8_url.split('/2')[0]
resp1 = requests.get(m3u8_url,headers=headers)
truth_url =truth_left+resp1.text.split('1280x720\n')[1]
print(truth_url)
输出如下:

使用获得的地址下载m3u8文件
resp2 = requests.get(truth_url.replace('\n',''),headers=headers)#去掉尾部的\n
with open('monv2.m3u8', mode="wb") as f:
f.write(resp2.content)
f.close()
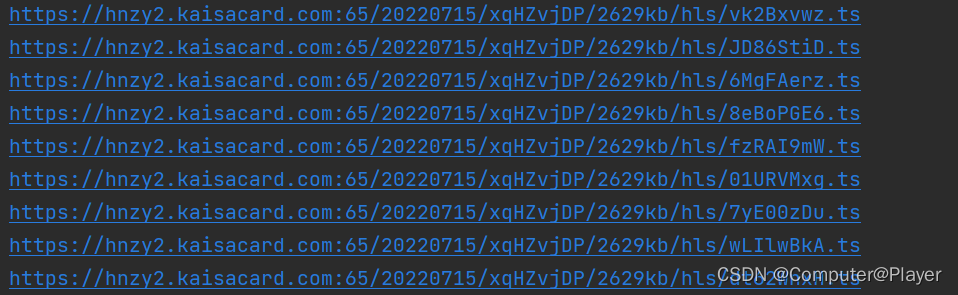
观看一下真是的视频地址:

所以需要我们进行一下处理,变成真正的视频下载地址。
# 3.2 下载第二层m3u8文件
with open("monv2.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
if line.startswith("#"):
continue
else:
line = line.strip() # 去掉空白或者换行符 hls/index.m3u8
# 准备拼接第二层m3u8的下载路径
second_m3u8_url = truth_left + line
print(second_m3u8_url)
f.close()
print('ok')
所以视频地址获取到了,但是如果下载的话太慢了,所以采用协程方法快速下载,完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES # pycryptodome
import os
from fake_useragent import UserAgent
def main():
print('ok')
def m3u8_allurl(name,truth_left):
# 3.2 下载第二层m3u8文件
urls = list()
with open(name, mode="r", encoding="utf-8") as f:
for line in f:
if line.startswith("#"):
continue
else:
line = line.strip() # 去掉空白或者换行符 hls/index.m3u8
# 准备拼接第二层m3u8的下载路径
second_m3u8_url = truth_left + line
urls.append(second_m3u8_url)
f.close()
return urls
def m3u8_download(name,truth_url):
headers = {'User-Agent': str(UserAgent().random)}
resp2 = requests.get(truth_url.replace('\n', ''), headers=headers) # 去掉尾部的\n
with open(name, mode="wb") as f:
f.write(resp2.content)
f.close()
print(name,' download!!!')
def m3u8_get(url):
headers = {'User-Agent': str(UserAgent().random)}
resp = requests.get(url, headers=headers)
res = re.compile(r'"link_pre":"","url":"(?P<url>.*?)",', re.S) # re.S: 让.能匹配换行符
m3u8_url = res.search(resp.text).group('url')
m3u8_url = m3u8_url.replace('\\', '')
truth_left = m3u8_url.split('/2')[0]
resp1 = requests.get(m3u8_url, headers=headers)
truth_url = truth_left + resp1.text.split('1280x720\n')[1]
return truth_left,truth_url.strip()
async def download_ts(url, name, session):
async with session.get(url) as resp:
async with aiofiles.open(name, mode="wb") as f:
await f.write(await resp.content.read()) # 把下载到的内容写入到文件中
f.close()
print(f"{name}下载完毕")
async def aio_download(allurls,name):
tasks = []
n = 1
async with aiohttp.ClientSession() as session: # 提前准备好session
for i_url in allurls:
task = asyncio.create_task(download_ts(i_url, name+f'_{n}.ts',session)) # 创建任务
n += 1
tasks.append(task)
await asyncio.wait(tasks) # 等待任务结束
if __name__ == '__main__':
url = 'http://48ys.top/vodplay/cW7JJJJN-1-1.html'
truth_left,m3u8 = m3u8_get(url)
print(m3u8)
m3u8_download('monv2.m3u8',m3u8)
allurls = m3u8_allurl('monv2.m3u8', truth_left)
print(allurls)
asyncio.run(aio_download(allurls, 'monv2/monv2'))
print(len(allurls))
main()
合成mp4视频的话建议使用一下工具,用代码的话有点慢,我的.py文件必须在这些视频的文件夹内运行才能合成,使用文件夹/文件名不能合成,也不清楚什么原因。还有一个问题就是所有ts文件不能一起合成,我也不清楚什么原因,因为不报错也不生成视频,使用我每100个ts合成一个大的ts,将这些大的ts统一合成一个mp4.
import os
lst = []
n=1
#将所有的文件名放入列表
with open("monv2.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
if line.startswith("#"):
continue
line = line.strip()
lname = line.split('/')[-1]
lst.append(lname)
#每100个ts文件名放入一个列表
k=[[] for i in range(0,100)]
num=-1
for i in range(0, len(lst)):
if(i%100==0):
num+=1
# print(num)
# print(i)
k[num].append(lst[i])
#100个ts先合成一个大的ts
ts=[]
for i in range(0,num+1):
s = "+".join(k[i])
print(s)
os.system(f"copy/b {s} he{i}.ts")
ts.append(f'he{i}.ts')
print(f'{i} is ok')
print(ts)
#将大的ts合成一个mp4
s = "+".join(ts)
os.system(f"copy/b {s} he.mp4")
print('he.mp4 is ok')

这是成功合成好的视频: