ЮФеТФПТМ
ЧАбд
СйНќбЇаЃЩчЭХеааТ, ЮЊСЫИјПЈЭлвСЕФбЇЕмбЇУУУЧзМБИвЛаЉаЁРёЮя, ВЉжїКЭЫћЕФКУЭЌжОУЧПЊЪМВпЛЎвЛаЉаЁЛюЖЏжЎвЛ ЈC QQЛњЦїШЫ
е§ЮФ
ВНжшЯъЯИЗжЮі
- ПђМмВПЗж
АДееВЉжїЕФРэНт, QQЛњЦїШЫЕФ
ЭъећЙІФмПђМмгаЮхИіВПЗж,
1 ) PythonФЃПщ(nb-cli) жаЕФ ЛњЦїШЫПђМм (Nonebot2)
2 ) Ч§ЖЏЦї(httpx)
3 ) авщЪЪХфЦї(Onebot)
4 ) ЦєЖЏЦї(cqhttp)
5 ) ЯюФПКЭЦєЖЏЦїЕФХфжУ
- ВхМў(ЙІФм)ВПЗж
1 ) ФкжУВхМў
2 ) здЖЈвхВхМў
вЛ. ЭъећЙІФмПђМм
зЂвт
ЪзЯШЫЕвЛЯТдк
Python3.7МАвдЩЯАцБОЕФМгГжЯТ,ЛњЦїШЫПђМм(nonebot) гаbeta2КЭa16СНИіАцБО,beta2ЪЧзюаТАц
ВЛЭЌЛњЦїШЫПђМмПђМмЕФВхМў(ФуПЩвдРэНтЮЊЛњЦїШЫЕФЙІФм) жЎМфвВашвЊДњТыЕќДњИќаТВХФмЭЈгУ
ЫљвдВЉжїЬсЧАЩљУї,вдЯТЕФФкШнЪЧЛљгкnonebotЕФbeta2АцаДЕФ,ЬцИїЮЛаЁЛяАщЬсЧАХХПг
АяжњЮФЕЕ
ДДНЈаТЯюФПQQ_Robot
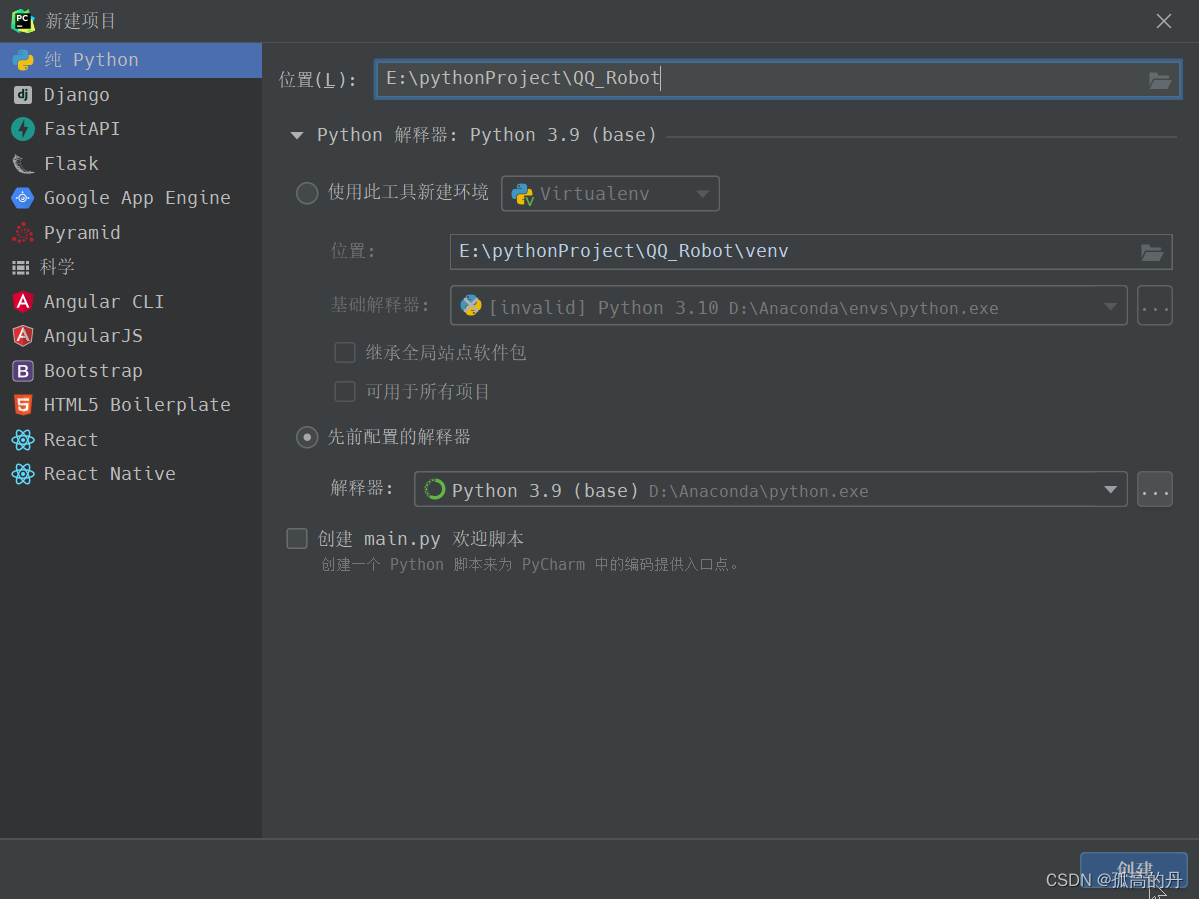
1. ФЃПщ nb-cli ЕФАВзА(ПЊЗЂФЃПщАќКЌNoneBot2)
дкБрвыЦї (ВЉжїЭЦМі
Pycharm)ЕФжеЖЫ(terminal) ЪфШы
pip install nb-cli
ШчЯТЭМЪЧГЩЙІАВзА:
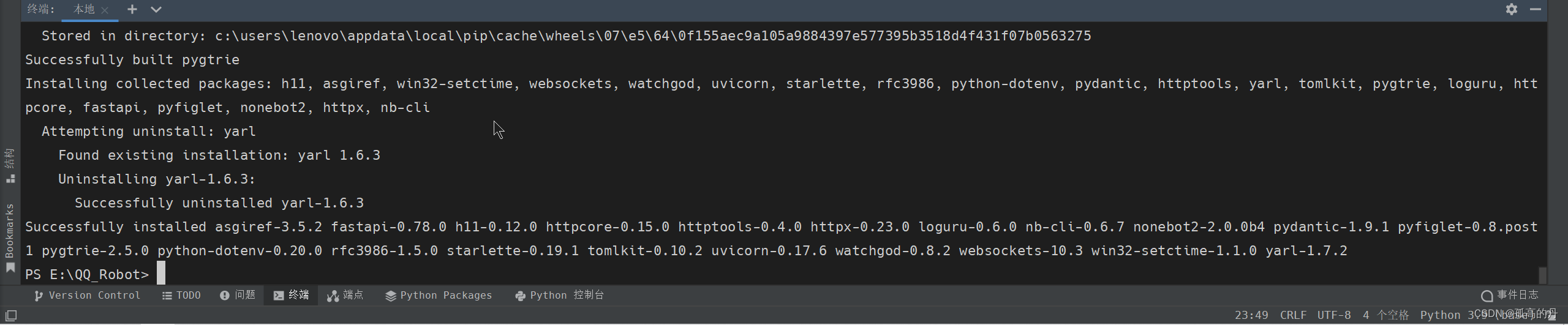
2. Ч§ЖЏЦї httpx ЕФАВзА
ЪфШы
nb driver listВщПДЧ§ЖЏЦїСаБэ
nb driver list
ШчЯТЭМ:
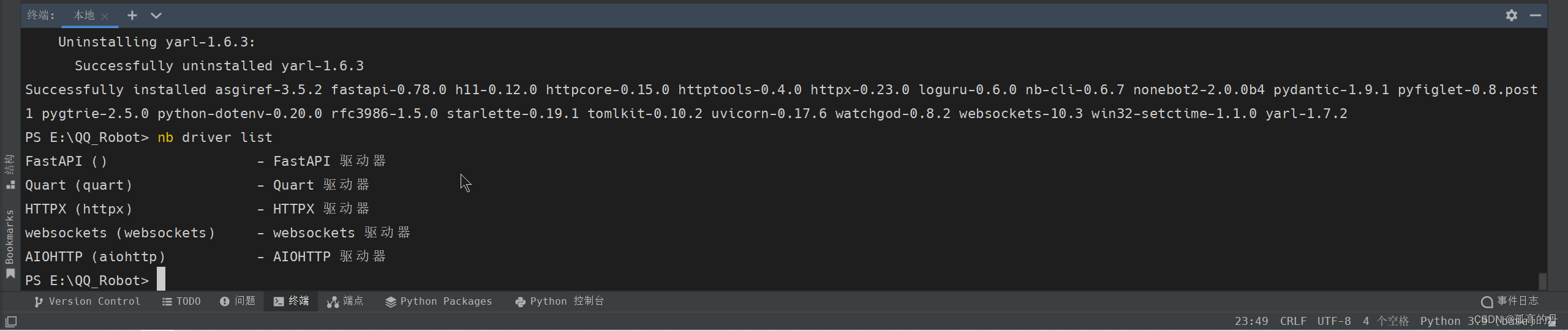
АВзАЧ§ЖЏЦї
1.ЪфШы nb driver ШчЯТЭМ, бЁдёЕкШ§Иі Insatll a Builtin Driver АД ЛиГЕ
nb driver
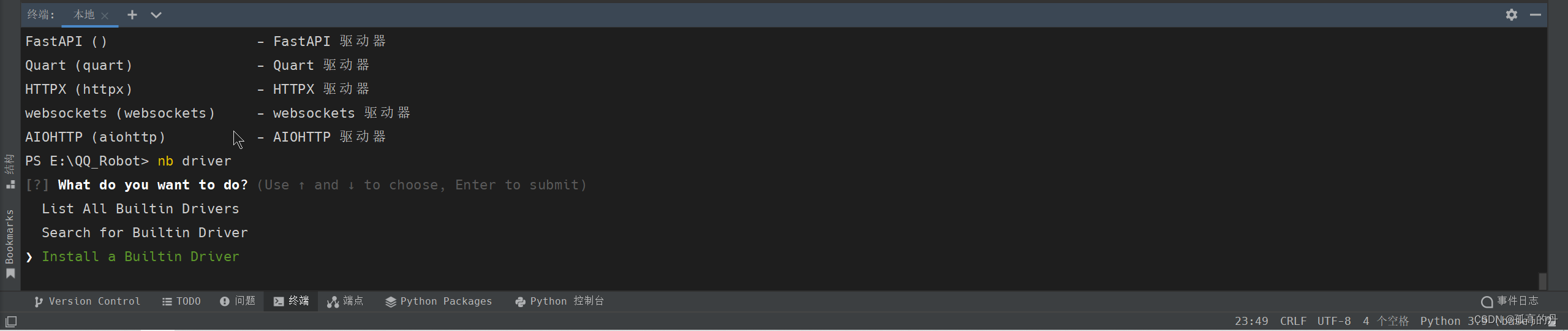
2.ЪфШыhttpx ШчЯТЭМ, ЛиГЕ
httpx
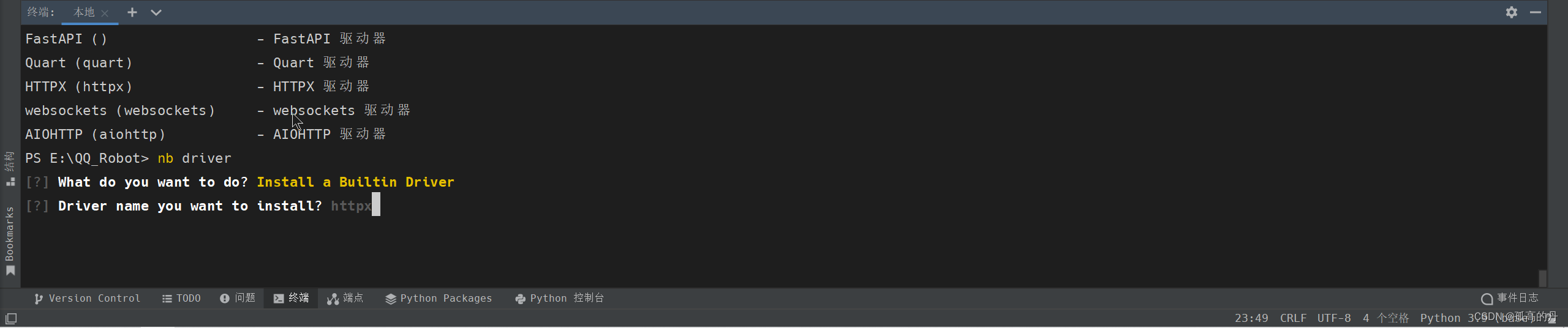
ШчЯТЭМОЭЪЧАВзАГЩЙІ:
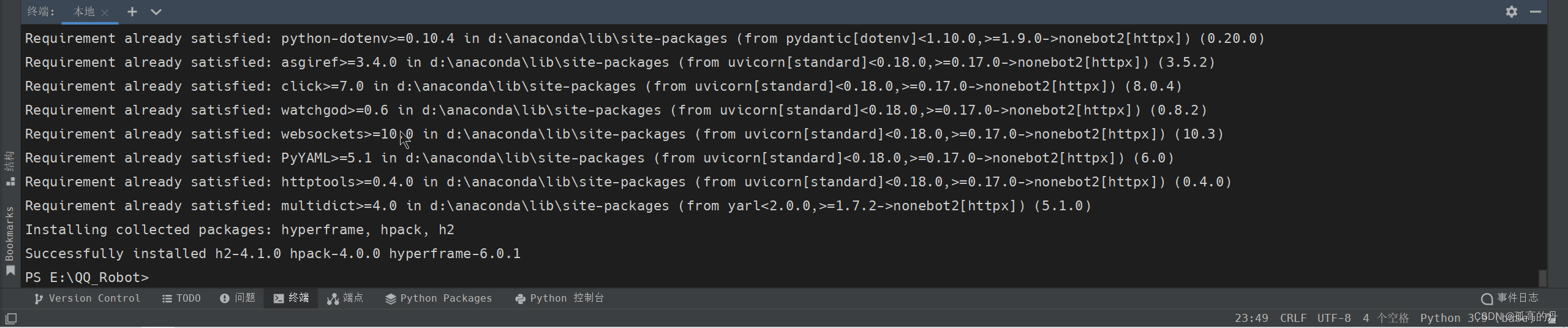
3. авщЪЪХфЦї Onebot ЕФАВзА
ЪфШы
nb adapter listВщПДавщЪЪХфЦїСаБэ
nb adapter list
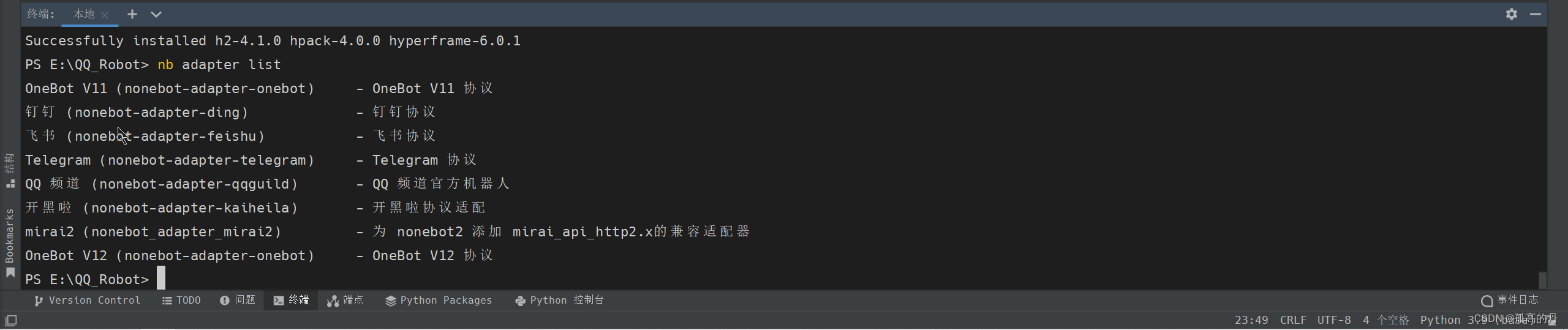
АВзАавщЪЪХфЦї
1.ЪфШы nb adapter , ШчЯТЭМбЁдёЕкШ§Иі Install a Published Adapter , ЛиГЕ
nb adapter
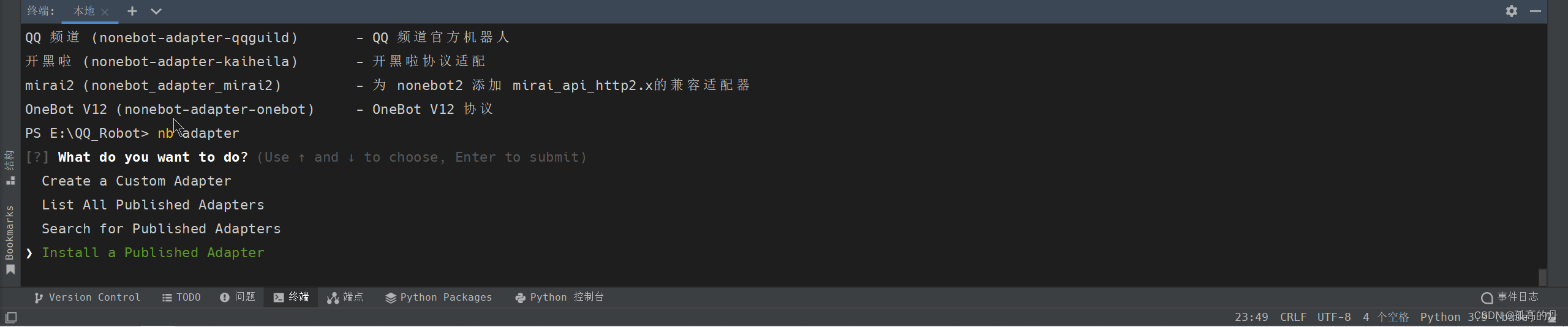
2.ЪфШыOneBot, ШчЯТЭМ, ЛиГЕ
OneBot
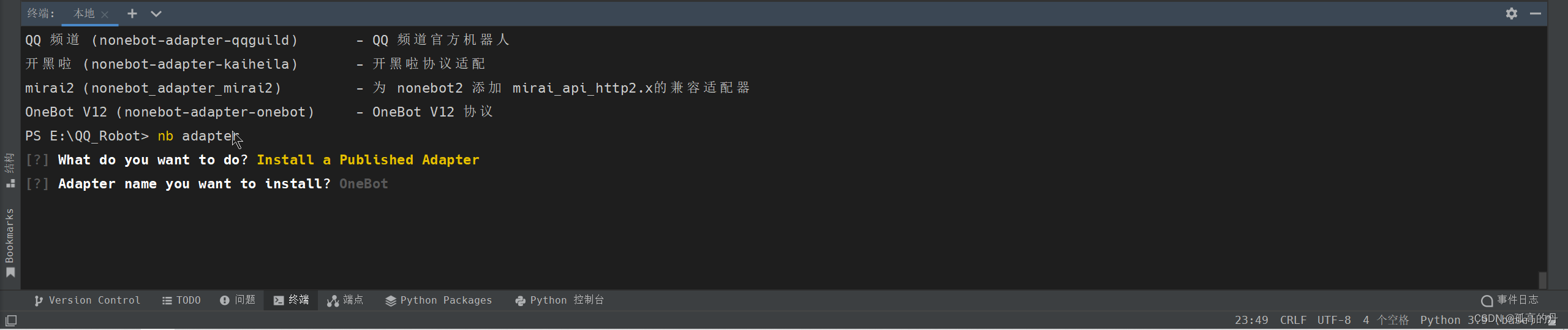
ШчЯТЭМГЩЙІАВзА:
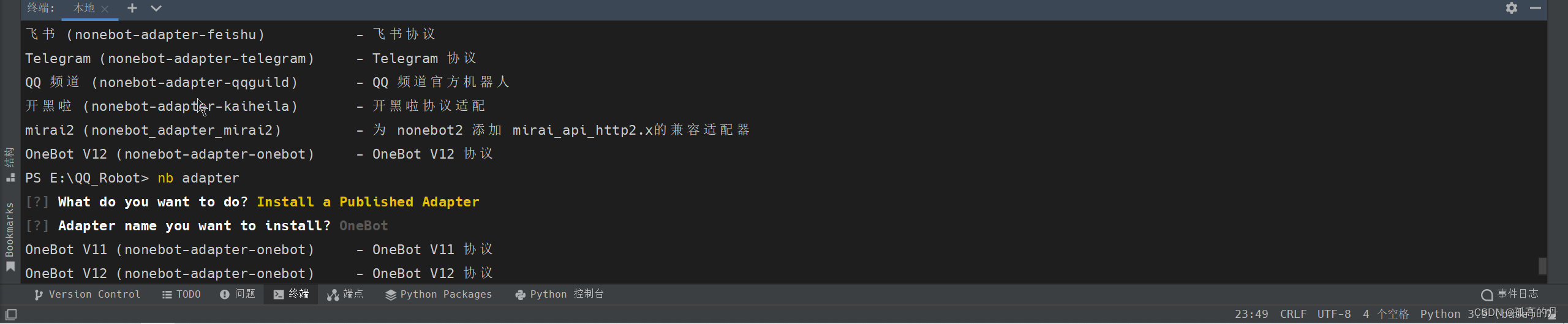
4.ЦєЖЏЦї cqhttp ЕФАВзА
ШчЯТЭМбЁдё
go-cqhttp_windows_amd64.exe, ЕуЛїЯТди
ps:БИгУ!!(ВЉжїНгЯТРДНЬДѓМвШчКЮЪЙгУ)
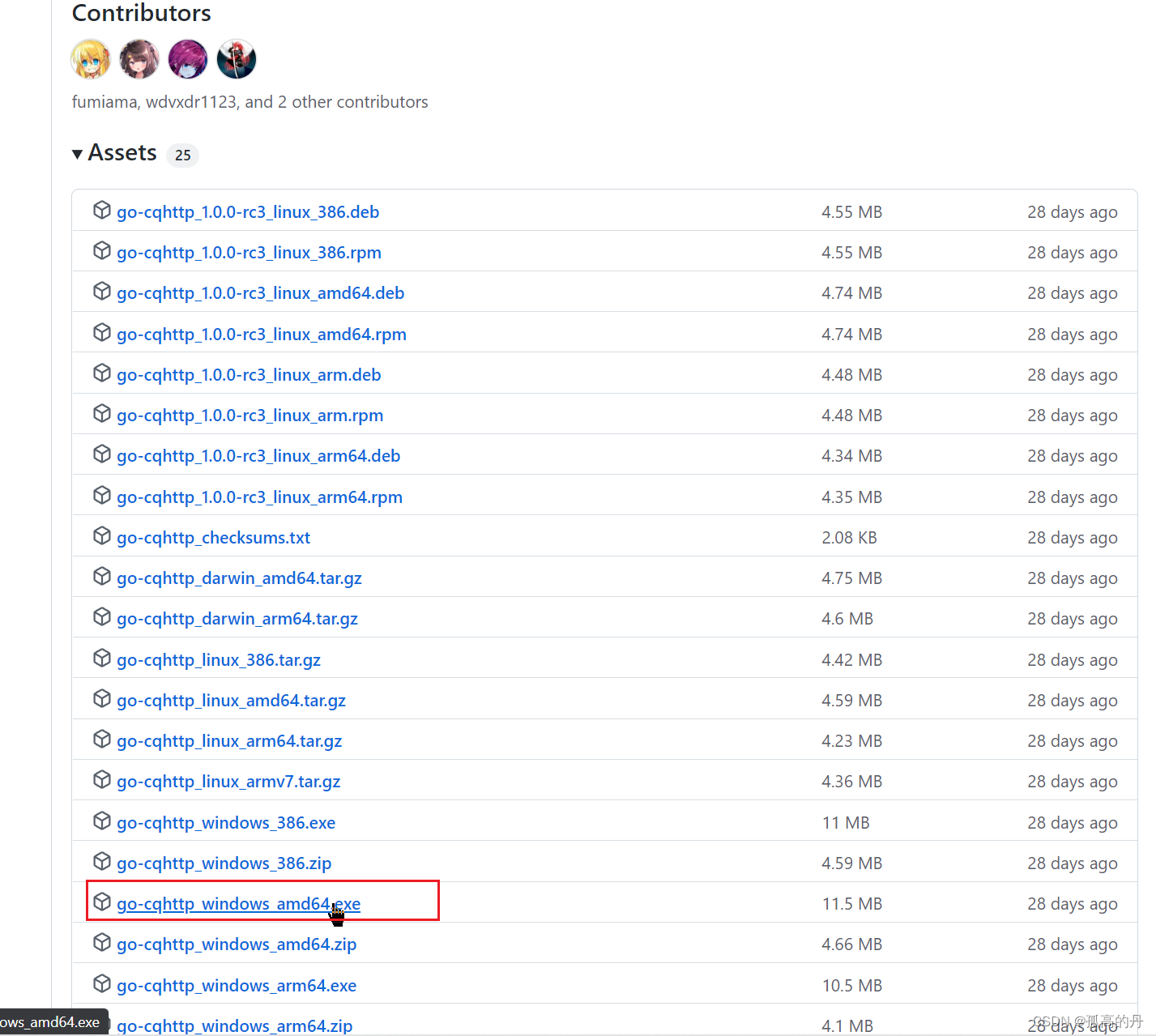
ЯТУцЪЧВЉжїЬцВЛЛсгУ GitHub ЕФаЁЛяАщУЧзМБИЕФ АйЖШдЦзЪдД
СДНг:https://pan.baidu.com/s/1W6Ses_HGygr8lyyNw-b2pQ?pwd=269s
ЬсШЁТы:269s
5.ЯюФПКЭЦєЖЏЦїХфжУ
ЯюФПКЭЮФМўХфжУ
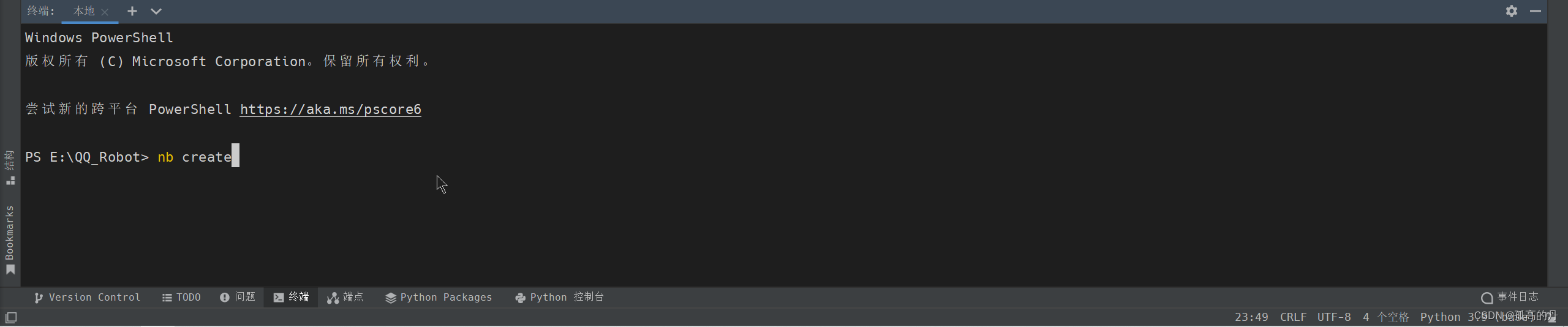
1.дк Pycharm жеЖЫЪфШыnb create , ЛиГЕ
nb create
2.ЪфШыФуЕФЯюФПУћГЦ, (ЫцЛњ) , ЛиГЕ
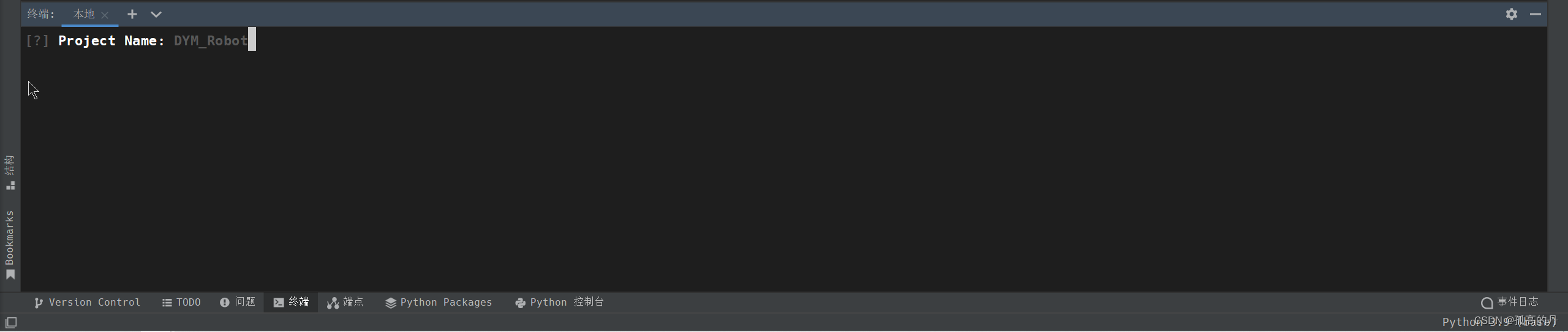
- бЁдё
In a "src" folder,ЛиГЕ
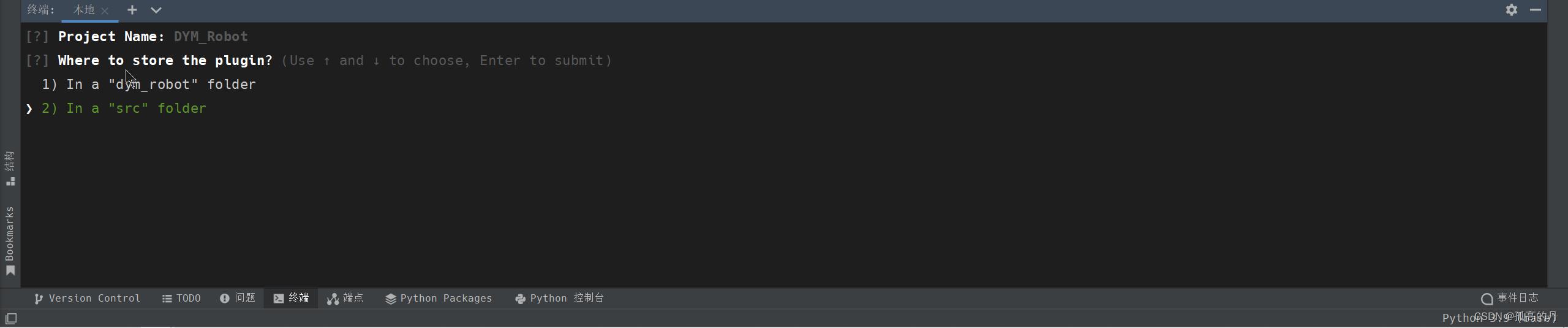
4.ПеИёбЁжаecho, ЛиГЕ
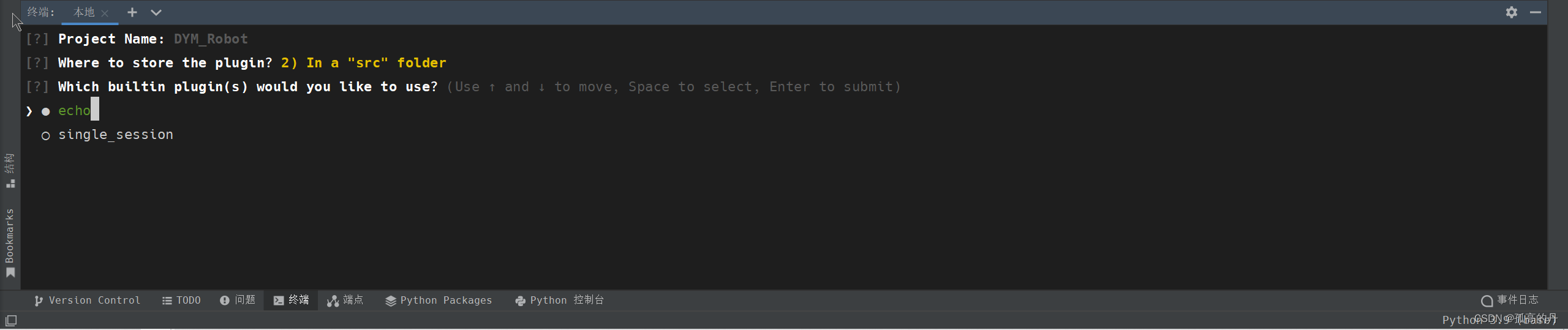
5. ПеИё бЁжа OneBot V11 , ЛиГЕ
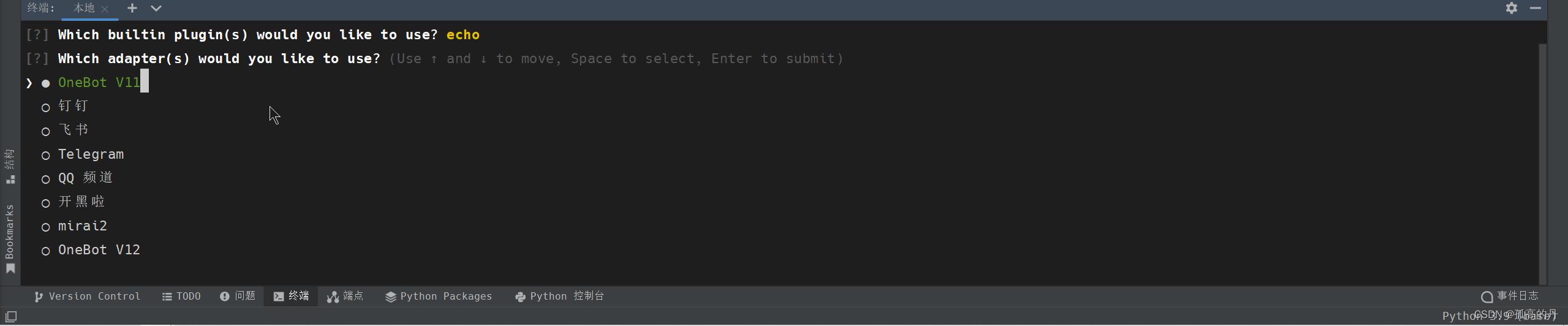
ШчЯТЭМ, ЯюФПДДНЈЭъГЩ
гУЕчФдздДјЕФ
ЮФМўЙмРэЦї(ПьНнМќWIN + E)ДђПЊЯюФПИљФПТМ
ЬсЪОШчЯТ
1.ДЫДІЕуЛї ИДжЦТЗОЖ/в§гУ , ВЂбЁдё ОјЖдТЗОЖ
2.етРя еГЬљ

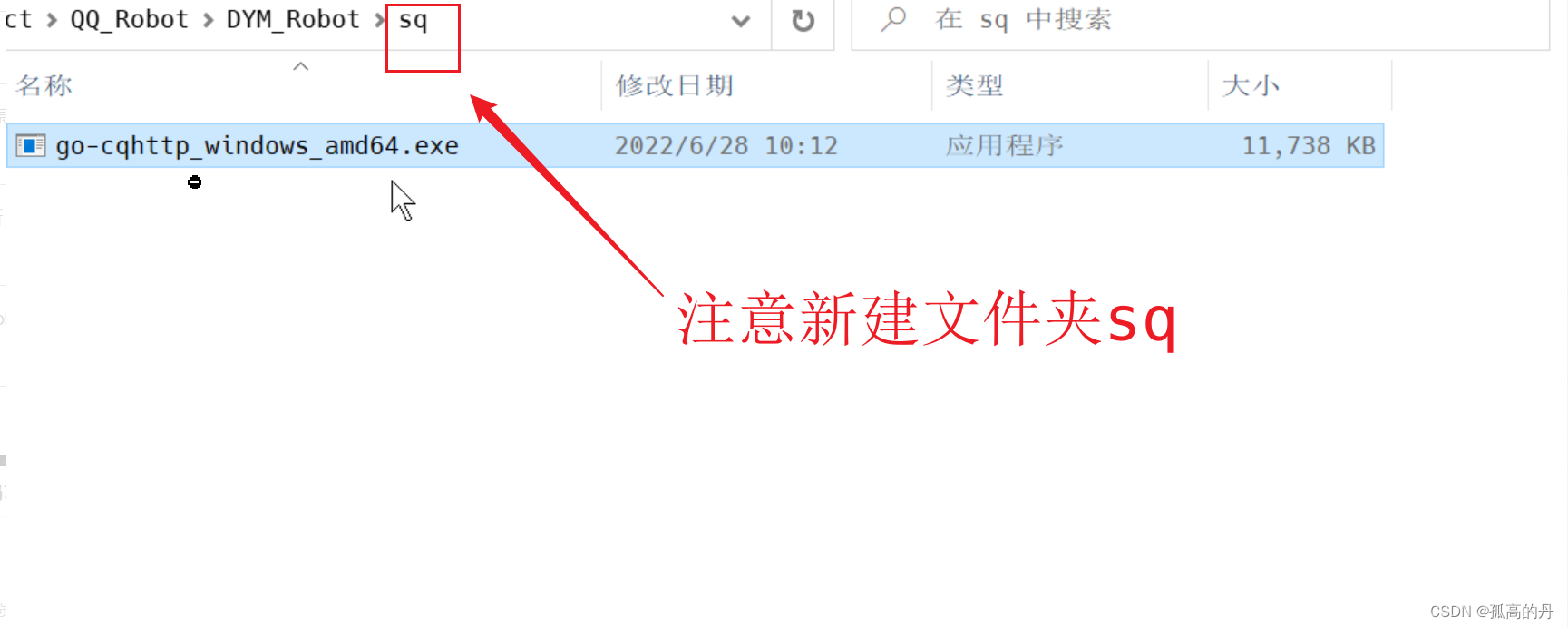
НјШывдЯТФПТМ
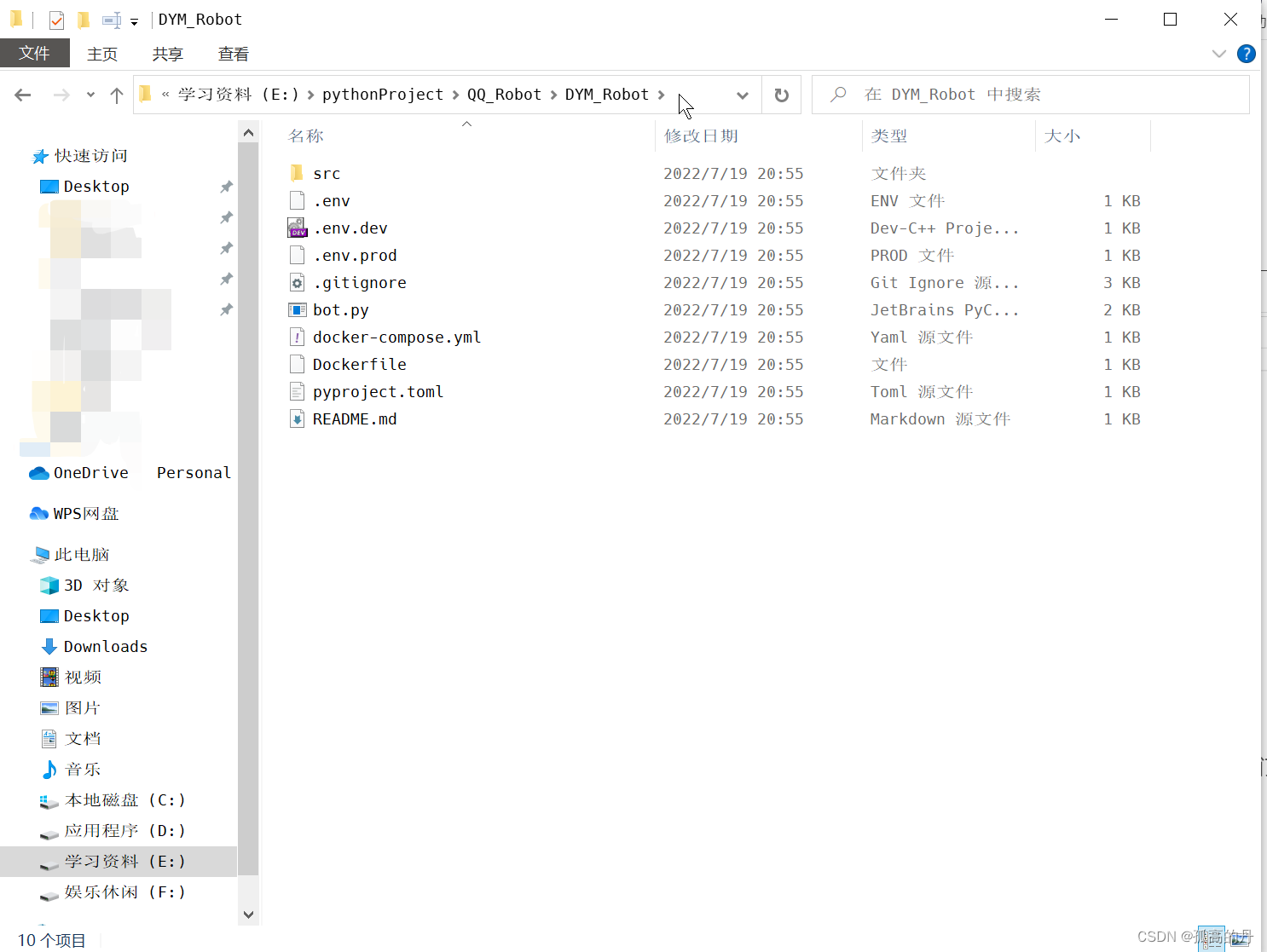
3.аТНЈsqЮФМўМа, НЋжЎЧАЯТдиКУЕФЮФМў go-cqhttp_windows_amd64.exe еГЬљЕН sq ЮФМўМаРя
ps: вђЮЊ ЦєЖЏЦї вЊКЭЯюФПжаЕФ bot.py ЗХдкЭЌМЖЮФМўМа
ЦєЖЏЦїЕФХфжУ
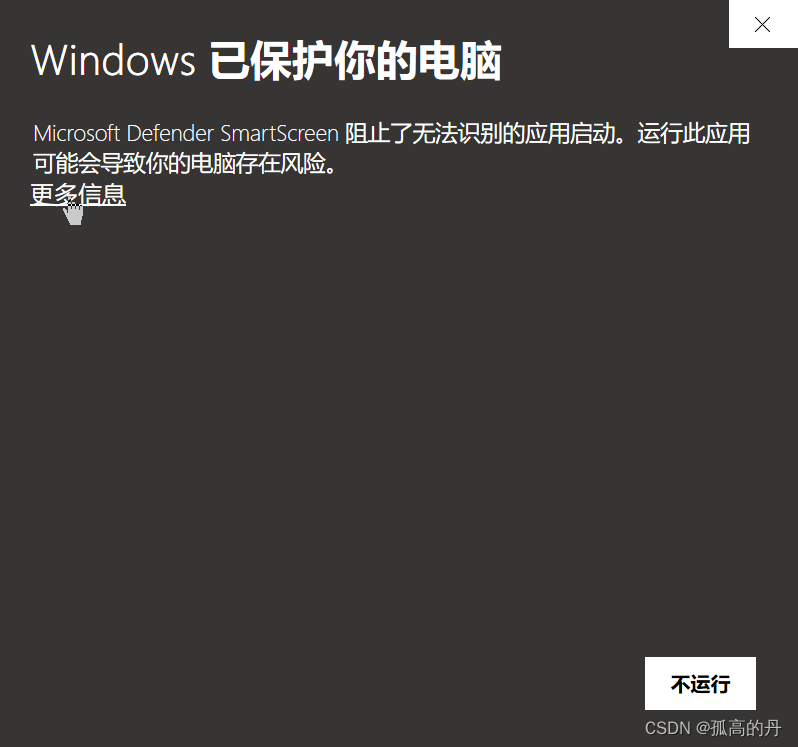
1 . ЫЋЛї EXEЮФМў go-cqhttp_windows_amd64.exe, ЕуЛїИќЖраХЯЂ
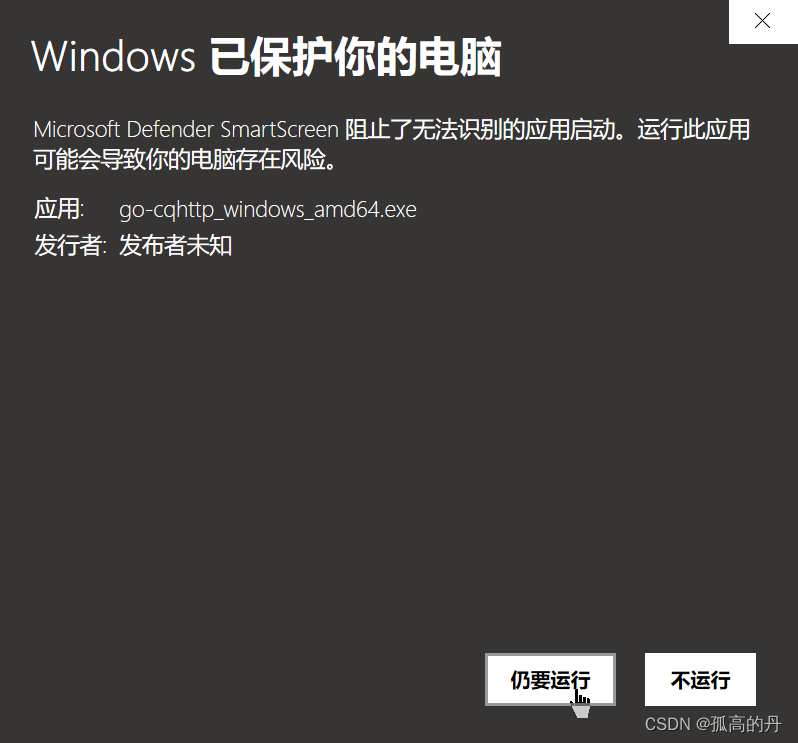
2.ЕуЛїШдвЊдЫаа
ps: WindowsздДјЕФАВШЋДыЪЉ, ЮвУЧгУЕФЪЧТЬЩЋЪЧПЊдДШэМў, ЗХаФЪЙгУ
3.КіТдОЏИц, ЫљгаЕу ШЗЖЈ
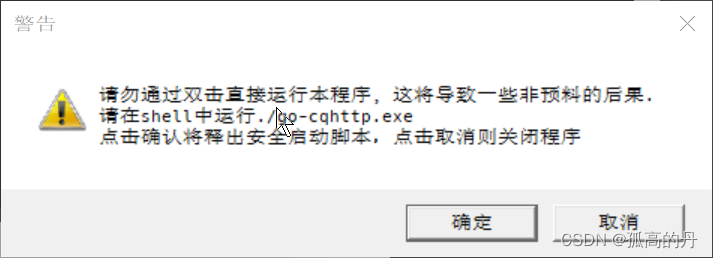
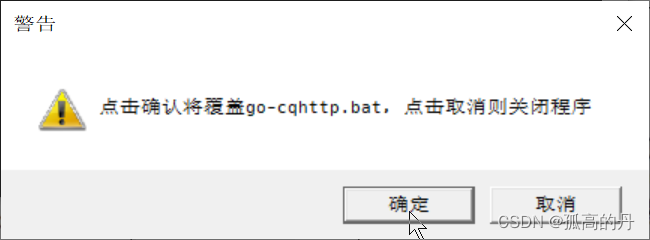
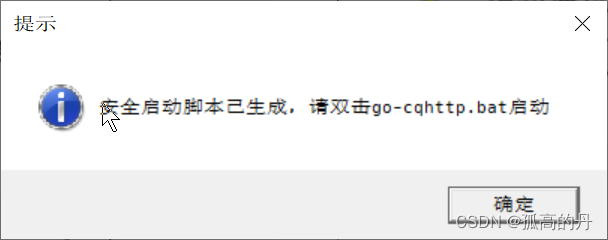
4.ЛиЕНд ЦєЖЏЦї ЫљдкЮЛжУ sq ЮФМўМа, ЫЋЛї дЫаа go-cqhttp.bat ЮФМў
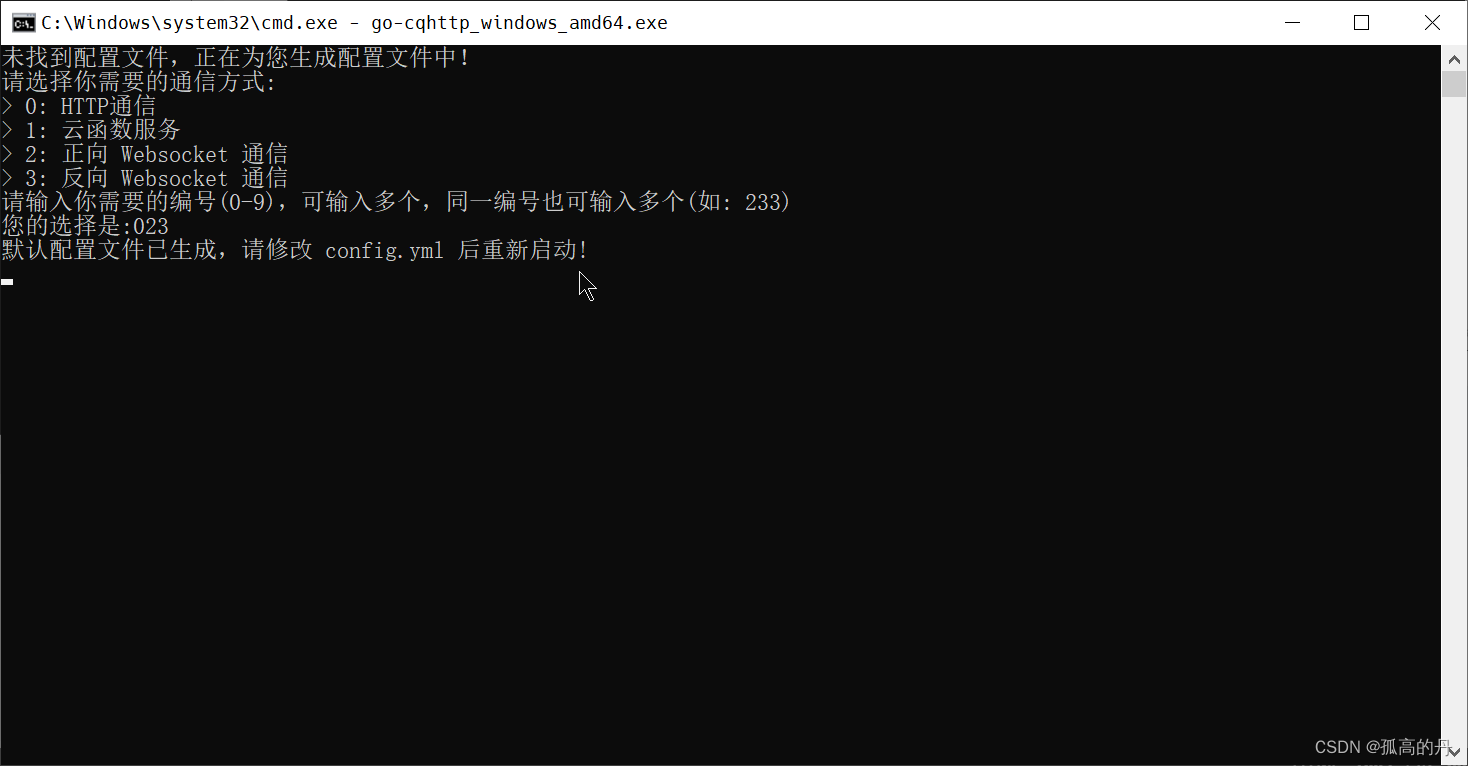
5.дкЕЏГіЕФУќСюааДАПк, ЪфШы 023 , бЁдёЖдгІЕФ HTTPЭЈаХ , е§Яђ Websocket ЭЈаХ , ЗДЯђ Websocket ЭЈаХ, ЛиГЕ
ps:етаЉЪЧЮвУЧЛњЦїШЫПЊЗЂгУЕНЕФДѓВПЗжЧ§ЖЏ
023
ШчЯТЭМЪЧГЩЙІ, ЙиБеДАПк, ЛиЕН sq ЮФМўМа,ГіЯж config.yml
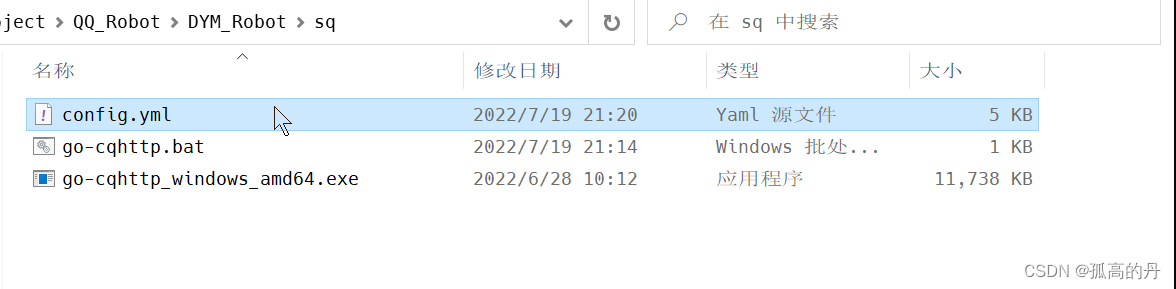
ЛиЕН
PycharmжаФуЕФЯюФПФПТМ, ДђПЊconfig.yml, ХфжУШчЯТФкШн,ШЋбЁCtrl + A,еГЬљCtrl + V
# go-cqhttp ФЌШЯХфжУЮФМў
account: # еЫКХЯрЙи
uin: # QQеЫКХ
password: # УмТыЮЊПеЪБЪЙгУЩЈТыЕЧТМ
encrypt: false # ЪЧЗёПЊЦєУмТыМгУм
status: 0 # дкЯпзДЬЌ ЧыВЮПМ https://github.com/Mrs4s/go-cqhttp/blob/dev/docs/config.md#дкЯпзДЬЌ
relogin: # жиСЌЩшжУ
disabled: false
delay: 3 # жиСЌбгГй, ЕЅЮЛУы
interval: 0 # жиСЌМфИє
max-times: 0 # зюДѓжиСЌДЮЪ§, 0ЮЊЮоЯожЦ
# ЪЧЗёЪЙгУЗўЮёЦїЯТЗЂЕФаТЕижЗНјаажиСЌ
# зЂвт, ДЫЩшжУПЩФмЕМжТдкКЃЭтЗўЮёЦїЩЯСЌНгЧщПіИќВю
use-sso-address: true
heartbeat:
disabled: false # ЪЧЗёПЊЦєаФЬјЪТМўЩЯБЈ
# аФЬјЦЕТЪ, ЕЅЮЛУы
# -1 ЮЊЙиБеаФЬј
interval: 5
message:
# ЩЯБЈЪ§ОнРраЭ
# ПЩбЁ: string,array
post-format: string
# ЪЧЗёКіТдЮоаЇЕФCQТы, ШчЙћЮЊМйНЋдбљЗЂЫЭ
ignore-invalid-cqcode: false
# ЪЧЗёЧПжЦЗжЦЌЗЂЫЭЯћЯЂ
# ЗжЦЌЗЂЫЭНЋЛсДјРДИќПьЕФЫйЖШ
# ЕЋЪЧМцШнадЛсгааЉЮЪЬт
force-fragment: false
# ЪЧЗёНЋurlЗжЦЌЗЂЫЭ
fix-url: false
# ЯТдиЭМЦЌЕШЧыЧѓЭјТчДњРэ
proxy-rewrite: ''
# ЪЧЗёЩЯБЈздЩэЯћЯЂ
report-self-message: false
# вЦГ§ЗўЮёЖЫЕФReplyИНДјЕФAt
remove-reply-at: false
# ЮЊReplyИНМгИќЖраХЯЂ
extra-reply-data: false
output:
# ШежОЕШМЖ trace,debug,info,warn,error
log-level: warn
# ЪЧЗёЦєгУ DEBUG
debug: false # ПЊЦєЕїЪдФЃЪН
# ФЌШЯжаМфМўУЊЕу
default-middlewares: &default
# ЗУЮЪУмдП, ЧПСвЭЦМідкЙЋЭјЕФЗўЮёЦїЩшжУ
access-token: ''
# ЪТМўЙ§ТЫЦїЮФМўФПТМ
filter: ''
# APIЯоЫйЩшжУ
# ИУЩшжУЮЊШЋОжЩњаЇ
# д cqhttp ЫфШЛЦєгУСЫ rate_limit КѓзК, ЕЋЪЧЛљБОУЛВхМўЪЪХф
# ФПЧАИУЯоЫйЩшжУЮЊСюХЦЭАЫуЗЈ, ЧыВЮПМ:
# https://baike.baidu.com/item/%E4%BB%A4%E7%89%8C%E6%A1%B6%E7%AE%97%E6%B3%95/6597000?fr=aladdin
rate-limit:
enabled: false # ЪЧЗёЦєгУЯоЫй
frequency: 1 # СюХЦЛиИДЦЕТЪ, ЕЅЮЛУы
bucket: 1 # СюХЦЭАДѓаЁ
servers:
# HTTP ЭЈаХЩшжУ
- http:
# ЪЧЗёЙиБее§ЯђHTTPЗўЮёЦї
disabled: false
# ЗўЮёЖЫМрЬ§ЕижЗ
host: 127.0.0.1
# ЗўЮёЖЫМрЬ§ЖЫПк
port: 5701
# ЗДЯђHTTPГЌЪБЪБМф, ЕЅЮЛУы
# зюаЁжЕЮЊ5,аЁгк5НЋЛсКіТдБОЯюЩшжУ
timeout: 5
middlewares:
<<: *default # в§гУФЌШЯжаМфМў
# ЗДЯђHTTP POSTЕижЗСаБэ
post:
#- url: '' # ЕижЗ
# secret: '' # УмдП
#- url: 127.0.0.1:5701 # ЕижЗ
# secret: '' # УмдП
# е§ЯђWSЩшжУ
- ws:
# ЪЧЗёНћгУе§ЯђWSЗўЮёЦї
disabled: false
# е§ЯђWSЗўЮёЦїМрЬ§ЕижЗ
host: 127.0.0.1
# е§ЯђWSЗўЮёЦїМрЬ§ЖЫПк
port: 6701
middlewares:
<<: *default # в§гУФЌШЯжаМфМў
- ws-reverse:
# ЪЧЗёНћгУЕБЧАЗДЯђWSЗўЮё
disabled: false
# ЗДЯђWS Universal ЕижЗ
# зЂвт ЩшжУСЫДЫЯюЕижЗКѓЯТУцСНЯюНЋЛсБЛКіТд
universal: ws://127.0.0.1:8080/onebot/v11/ws/
# ЗДЯђWS API ЕижЗ
api: ws://your_websocket_api.server
# ЗДЯђWS Event ЕижЗ
event: ws://your_websocket_event.server
# жиСЌМфИє ЕЅЮЛКСУы
reconnect-interval: 3000
middlewares:
<<: *default # в§гУФЌШЯжаМфМў
# pprof адФмЗжЮіЗўЮёЦї, вЛАуЧщПіЯТВЛашвЊЦєгУ.
# ШчЙћгіЕНадФмЮЪЬтЧыЩЯДЋБЈИцИјПЊЗЂепДІРэ
# зЂвт: pprofЗўЮёВЛжЇГжжаМфМўЁЂВЛжЇГжМјШЈ. ЧыВЛвЊПЊЗХЕНЙЋЭј
- pprof:
# ЪЧЗёНћгУpprofадФмЗжЮіЗўЮёЦї
disabled: true
# pprofЗўЮёЦїМрЬ§ЕижЗ
host: 127.0.0.1
# pprofЗўЮёЦїМрЬ§ЖЫПк
port: 7700
# ПЩЬэМгИќЖр
#- ws-reverse:
#- ws:
#- http:
#- pprof:
database: # Ъ§ОнПтЯрЙиЩшжУ
leveldb:
# ЪЧЗёЦєгУФкжУleveldbЪ§ОнПт
# ЦєгУНЋЛсдіМг10-20MBЕФФкДцеМгУКЭвЛЖЈЕФДХХЬПеМф
# ЙиБеНЋЮоЗЈЪЙгУ ГЗЛи ЛиИД get_msg ЕШЩЯЯТЮФЯрЙиЙІФм
enable: true
ДђПЊ
.env, ХфжУШчЯТФкШн
ENVIRONMENT=prod
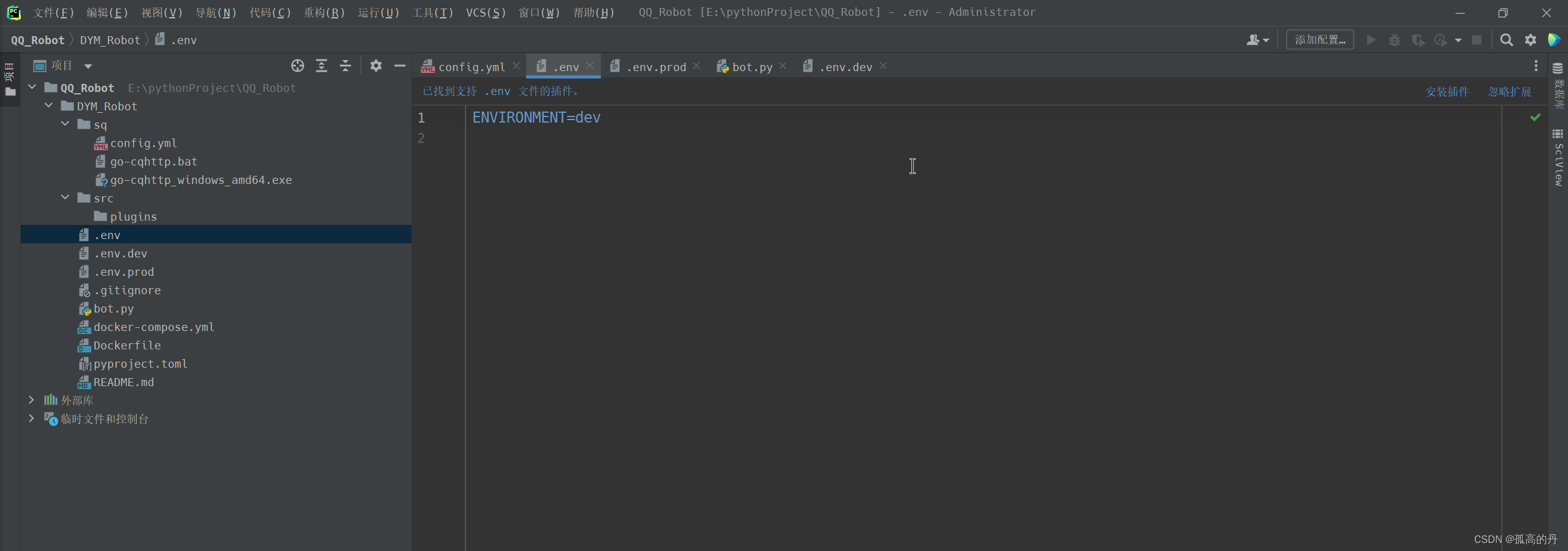
ДђПЊ
bot.py, ХфжУвдЯТФкШн
import nonebot
from nonebot.adapters.onebot.v11 import Adapter as ONEBOT_V11Adapter
nonebot.init()
# МгдиВхМўФПТМ,ИУФПТМЯТЮЊИїВхМў
nonebot.load_from_toml("pyproject.toml")
# ВтЪдВхМў
nonebot.load_builtin_plugin("echo")
app = nonebot.get_asgi()
driver = nonebot.get_driver()
driver.register_adapter(ONEBOT_V11Adapter)
# Мгди nonebot ФкжУВхМў
nonebot.load_builtin_plugins()
if __name__ == "__main__":
nonebot.logger.warning("Always use `nb run` to start the bot instead of manually running!")
nonebot.run(app="__mp_main__:app")
ДђПЊ
pyproject.toml, ХфжУвдЯТФкШн
[tool.poetry]
name = "bot"
version = "0.1.0"
description = "bot"
authors = []
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.7.3"
nonebot2 = "^2.0.0-beta.1"
[tool.poetry.dev-dependencies]
nb-cli = "^0.6.0"
[tool.nonebot]
# ФкжУВхМўШЋУћ
plugins = []
# здЖЈвхВхМўБЃДцЮЛжУ
plugin_dirs = ["src/plugins"]
[tool.black]
line-length = 88
[tool.isort]
profile = "black"
line_length = 88
skip_gitignore = true
[build-system]
build-backend = "poetry.core.masonry.api"
requires = ["poetry-core>=1.0.0"]
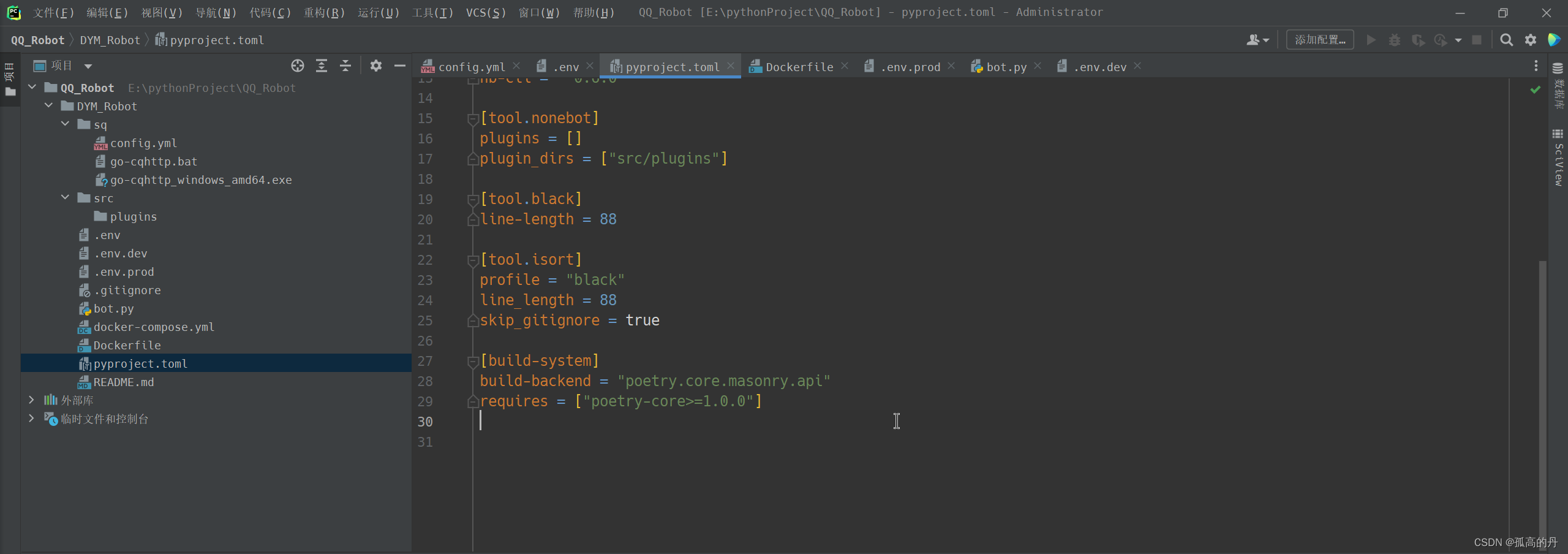
вдЩЯЫљгаХфжУЭъБЯ, ЭъећЕФЯюФПНсЙЙШчЯТ
Жў. дЫааВПЗж
ВтЪддЫаа
bot.py
1., дЫааЯюФПжаЕФbot.py
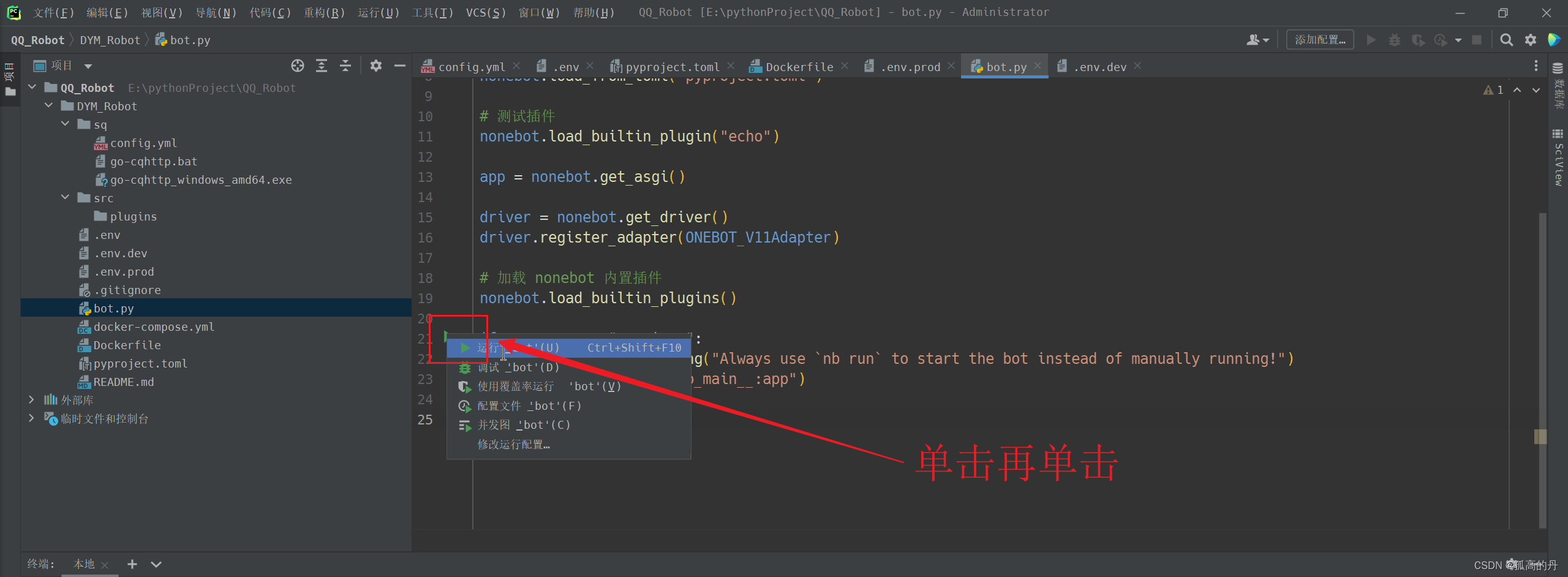
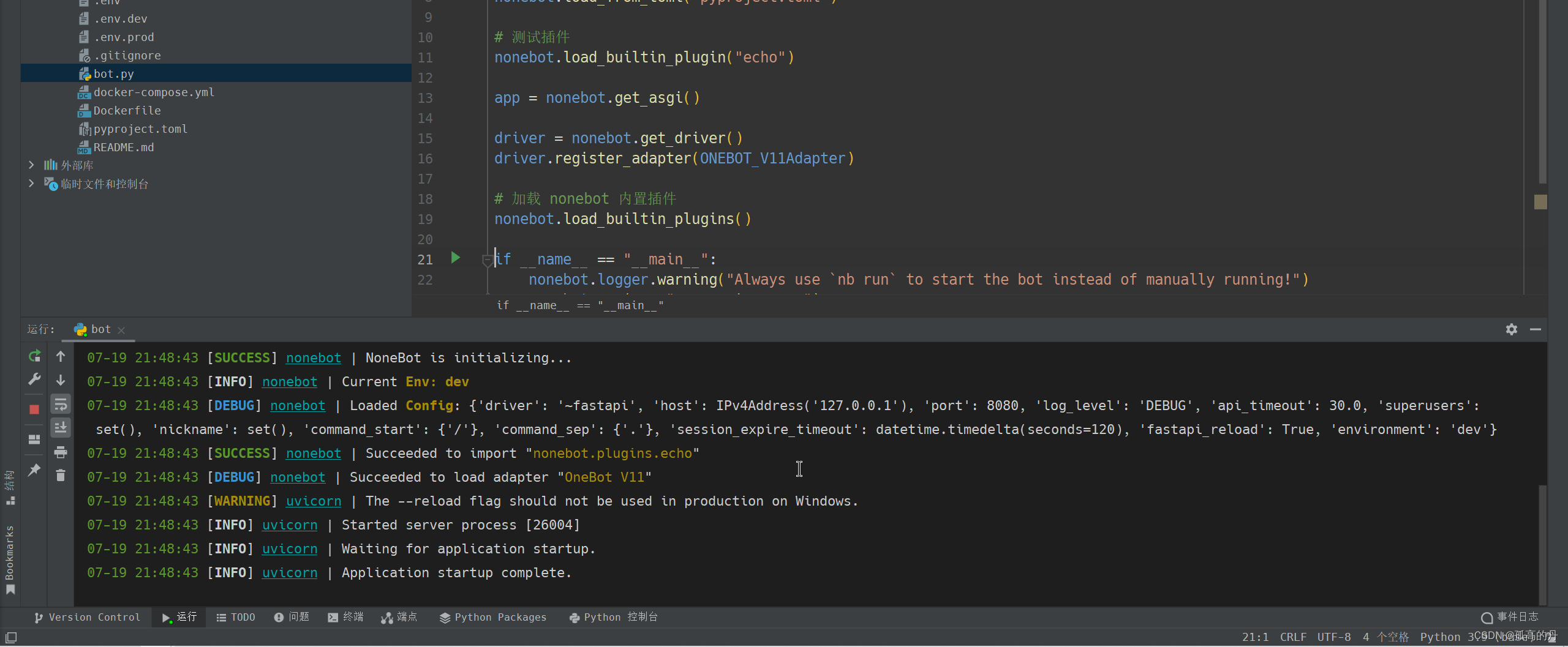
ЕЏГівдЯТ, ОЭЪЧдЫааГЩЙІ
ЛиЕН ЯюФПЯТЕФ
sqЮФМўМа, ЫЋЛїДђПЊgo-cqhttp.batBatЮФМў
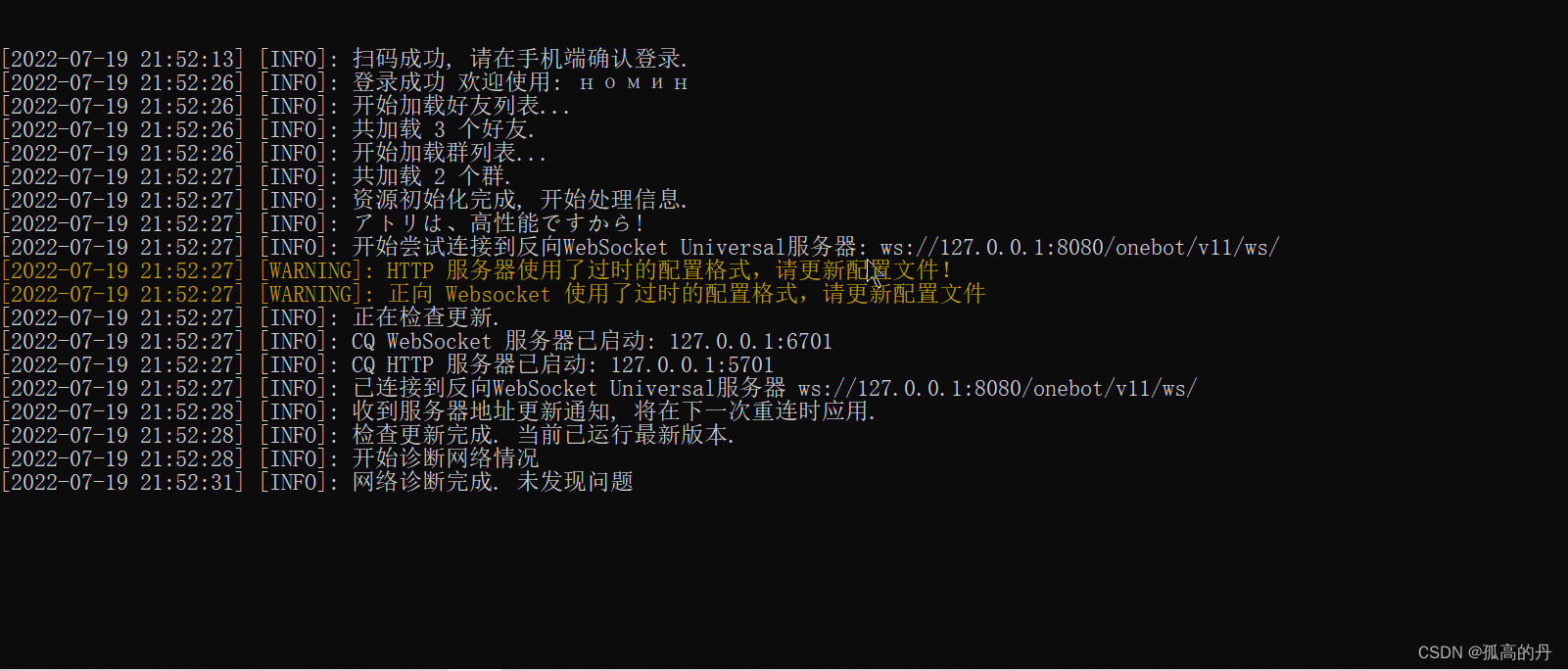
ЪЙгУ
АѓЖЈЮЊQQЛњЦїШЫЕФQQКХЩЈТыЕЧТН, дкЪжЛњЩЯЕуЛїМЬајЕЧТМ
ps:
1. QQЛњЦїШЫвРЭагквбЕЧМЧЙ§ЕФQQеЫКХ
2. ДЫДІзюКУ ШЋЦС , ЖўЮЌТыЕФМгдиЮЪЬт, гааЫШЄЕФаЁЛяАщздааГЂЪд

ГіЯжвдЯТЮЊАѓЖЈГЩЙІ:
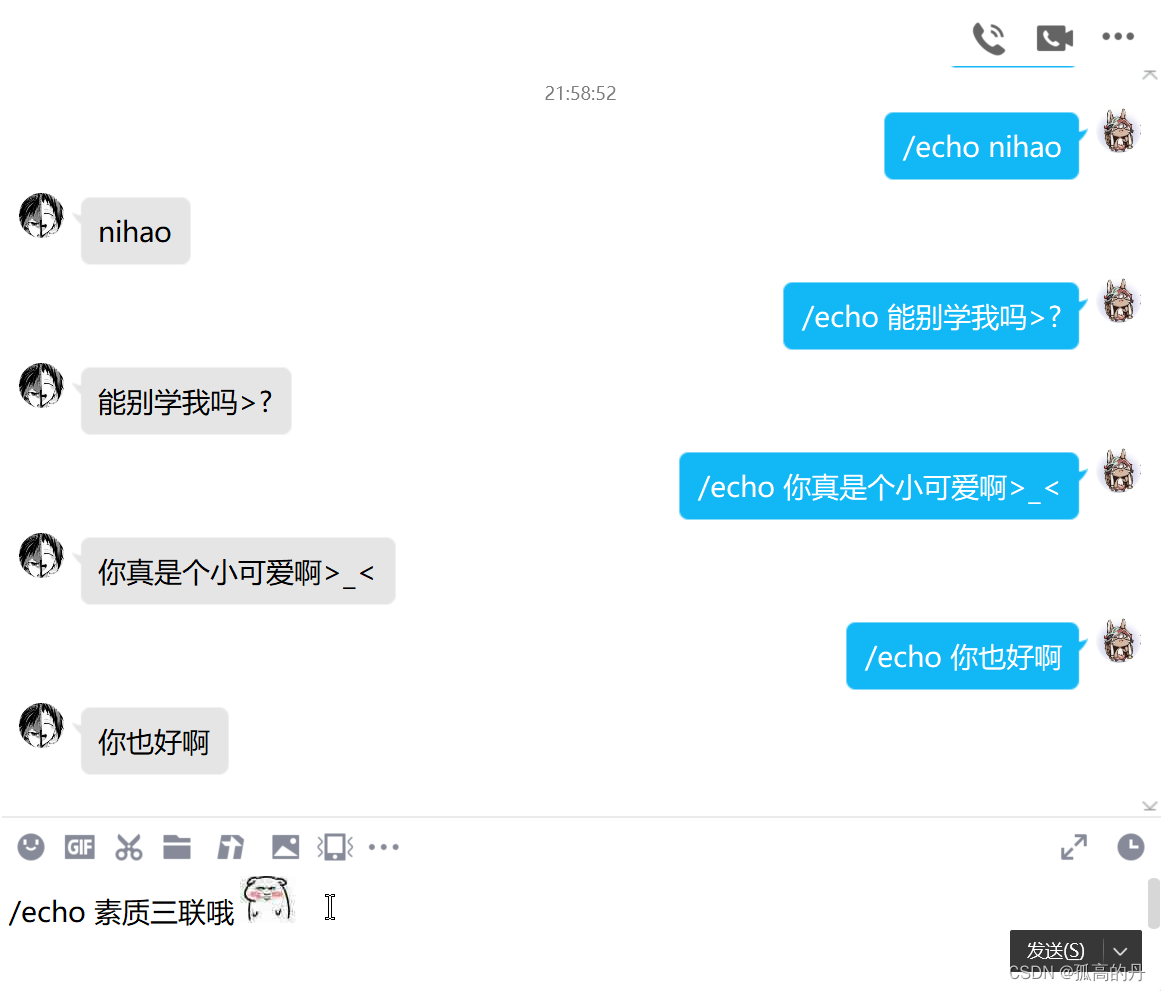
ВтЪдQQЛњЦїШЫ
гУШЮвтвЛИіБ№ЕФQQеЫКХЗЂЫЭаХЯЂЕН QQЛњЦїШЫАѓЖЈЕФQQеЫКХ, ИёЪНЮЊ/echo + ПеИё + ФкШн
Ш§. ВхМў(ЙІФм)ЬэМг
1.ФкжУВхМў
КмЖр
гаШЄЕФВхМў( ЙІФм ) аЁЛяАщУЧздааЯТди, ЧвЙйЗНФкжУВхМўЮЪЬтЧывЦВНжСЙйЗННтОіЮЪЬт
БЯОЙВЉжїжЛЪЧИіММЪѕаЁУШаТ, ВЛЦўЗЙ, ВЛЯТЗЙ


МђЕЅНщЩмвЛаЉЩЬЕъФк
гаШЄЕФФкжУВхМўЕФАВзА
wordle ВТЕЅДЪ
ps: ПЩвдКЭзМБИЫФСљМЖЕФаЁЛяАщУЧвЛЦ№ЭцЫЃ
ЕуЛї
ЕуЛїИДжЦАВзАжИСю
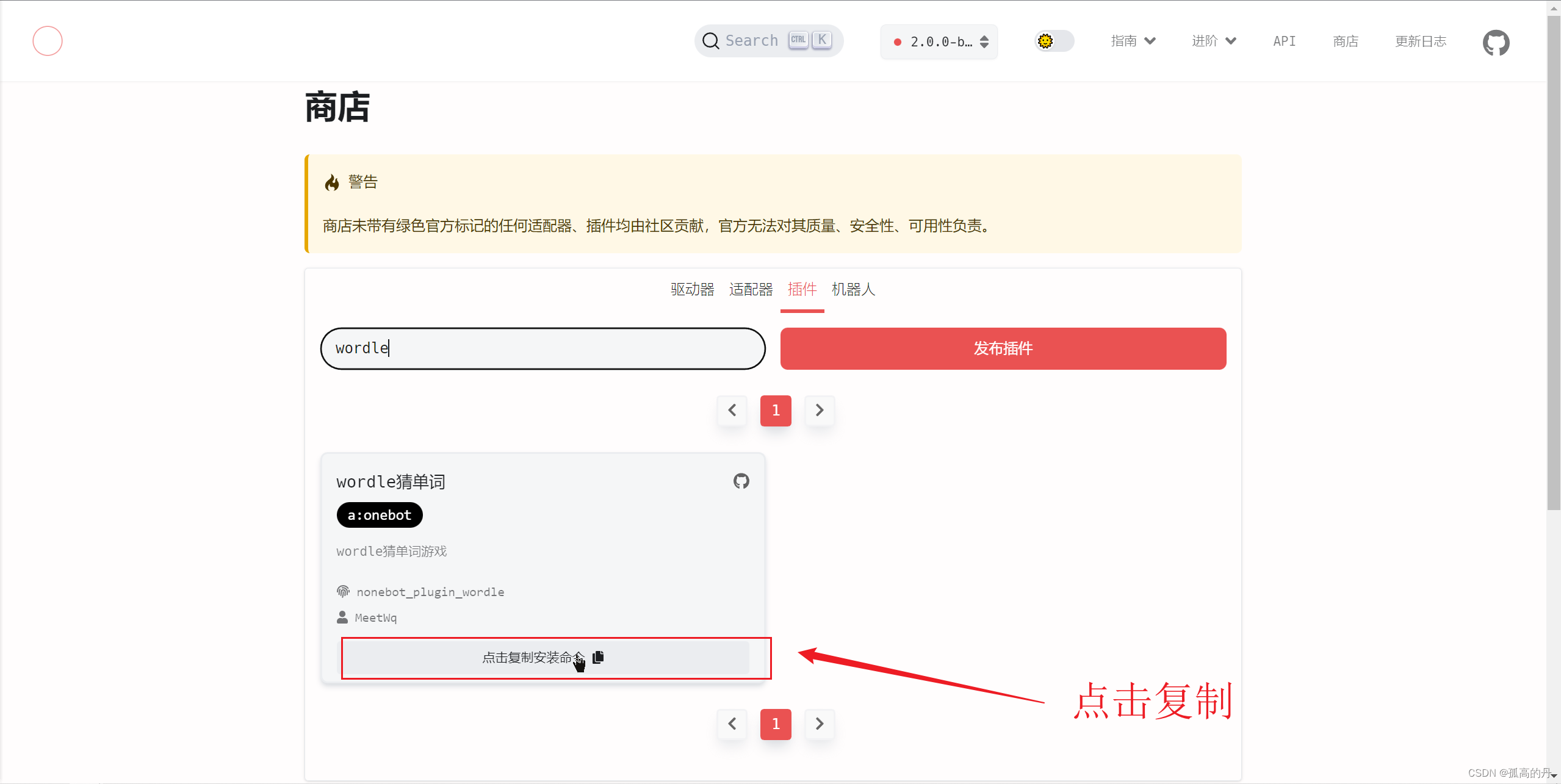
ЛиЕН
PycharmдкжеЖЫЪфШы,ЛиГЕ, жБНгАВзАМДПЩ
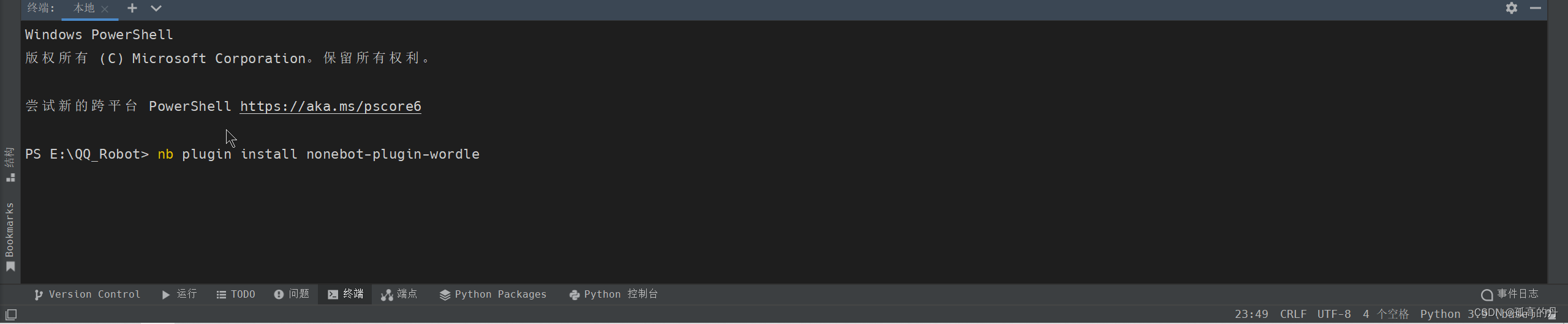
ГіЯжЯТЭМЮЊАВзАГЩЙІ

ШчЙћАВзАВЛГЩЙІ, ГЂЪдЪфШы
pip install+ ВхМўУћШЋГЦ
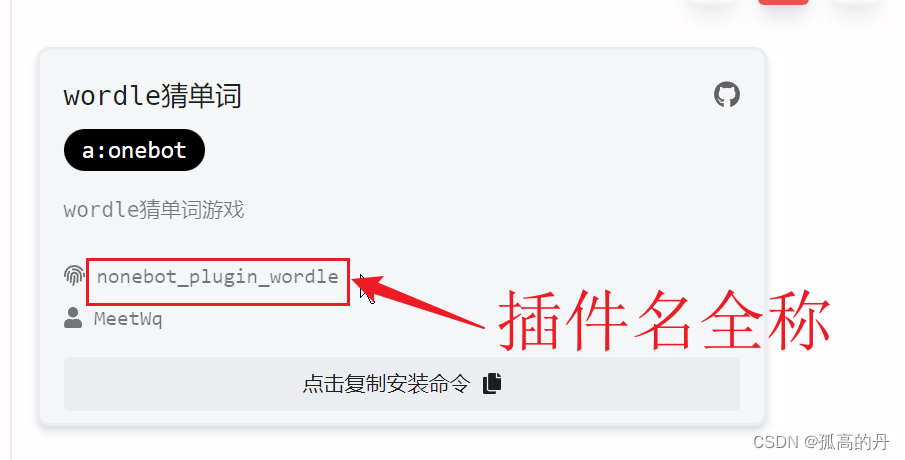
НЋвбАВзА
ФкжУВхМўаДШыpyproject.tomlжаЕФpluginsжа, зЂвтв§КХРЈзЁ, ЖрИіВхМўжЎМфгЂЮФЖККХИєПЊ
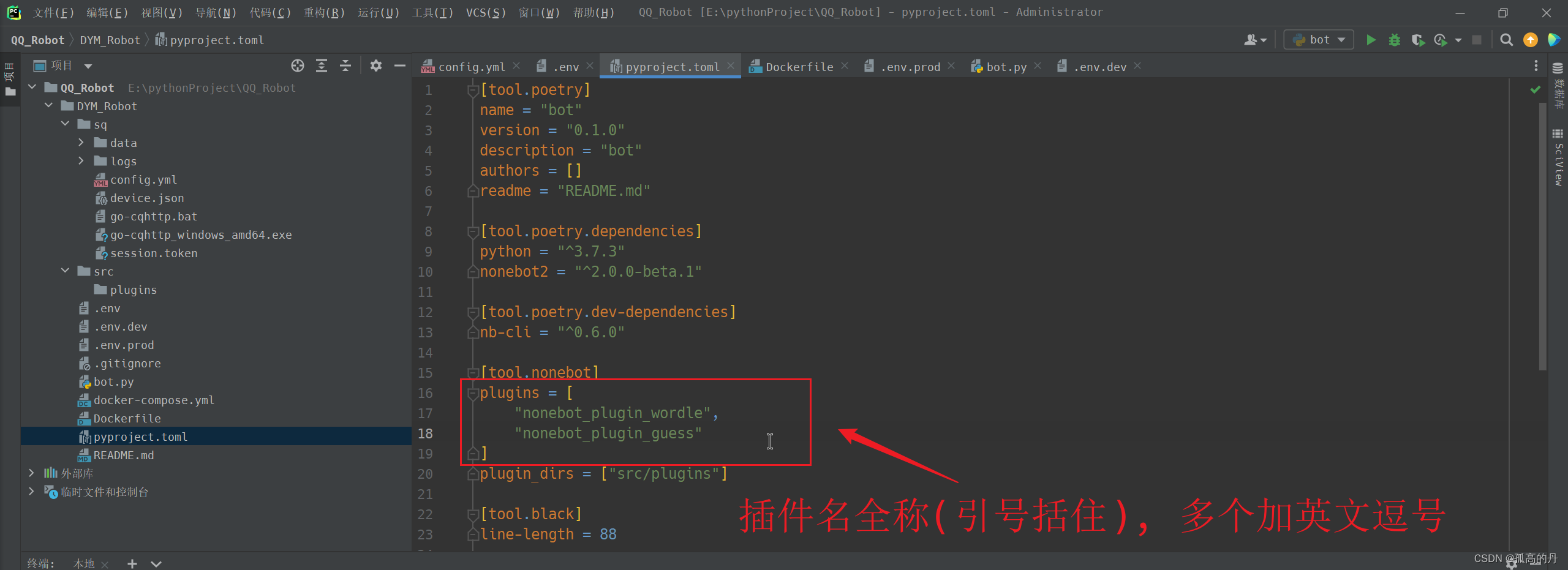
аЇЙћЭМШчЯТ:

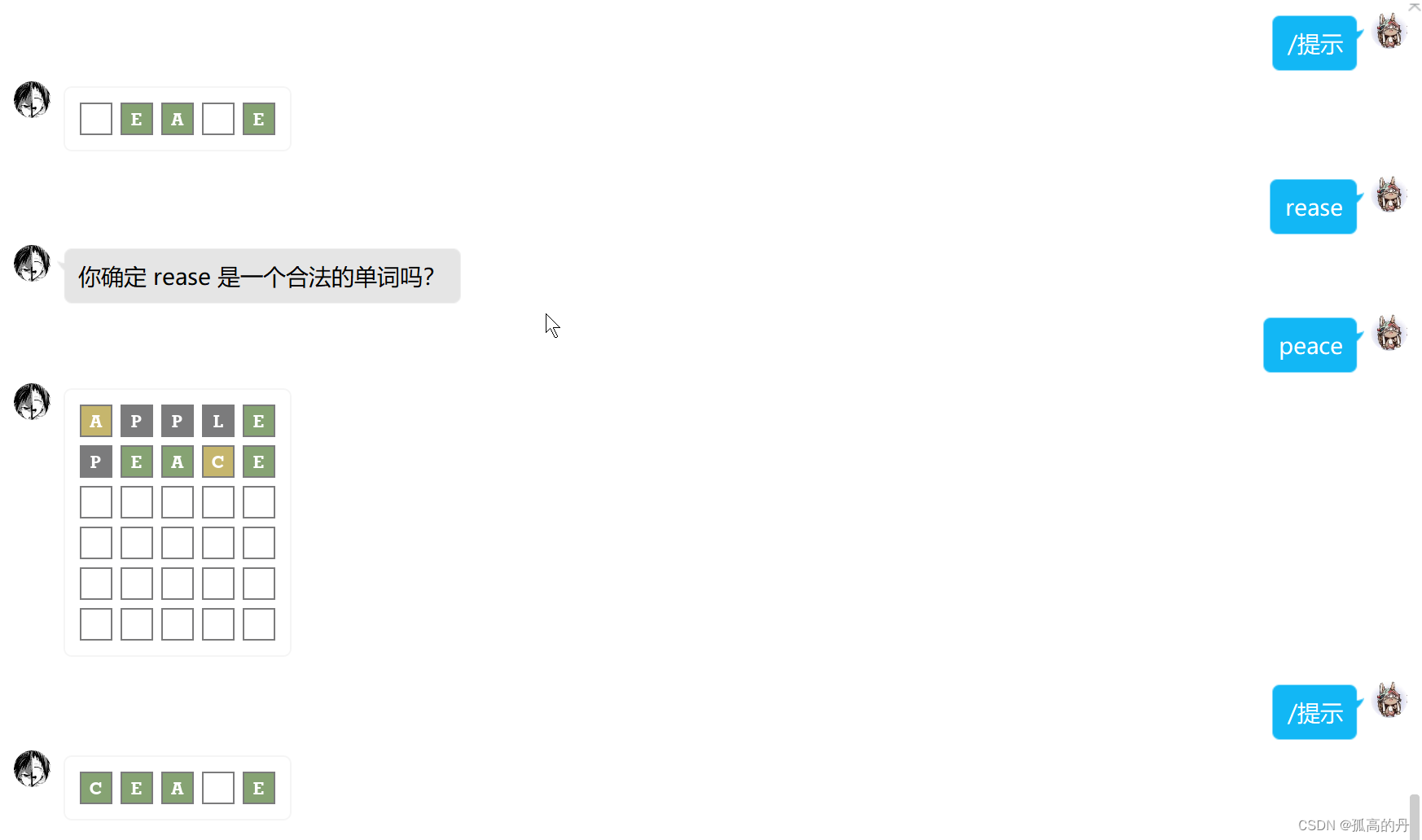

Nonebot2 ВхМўЧсСПАяжњСаБэ
ps:ЪЕгУВхМўЙмРэжњЪж
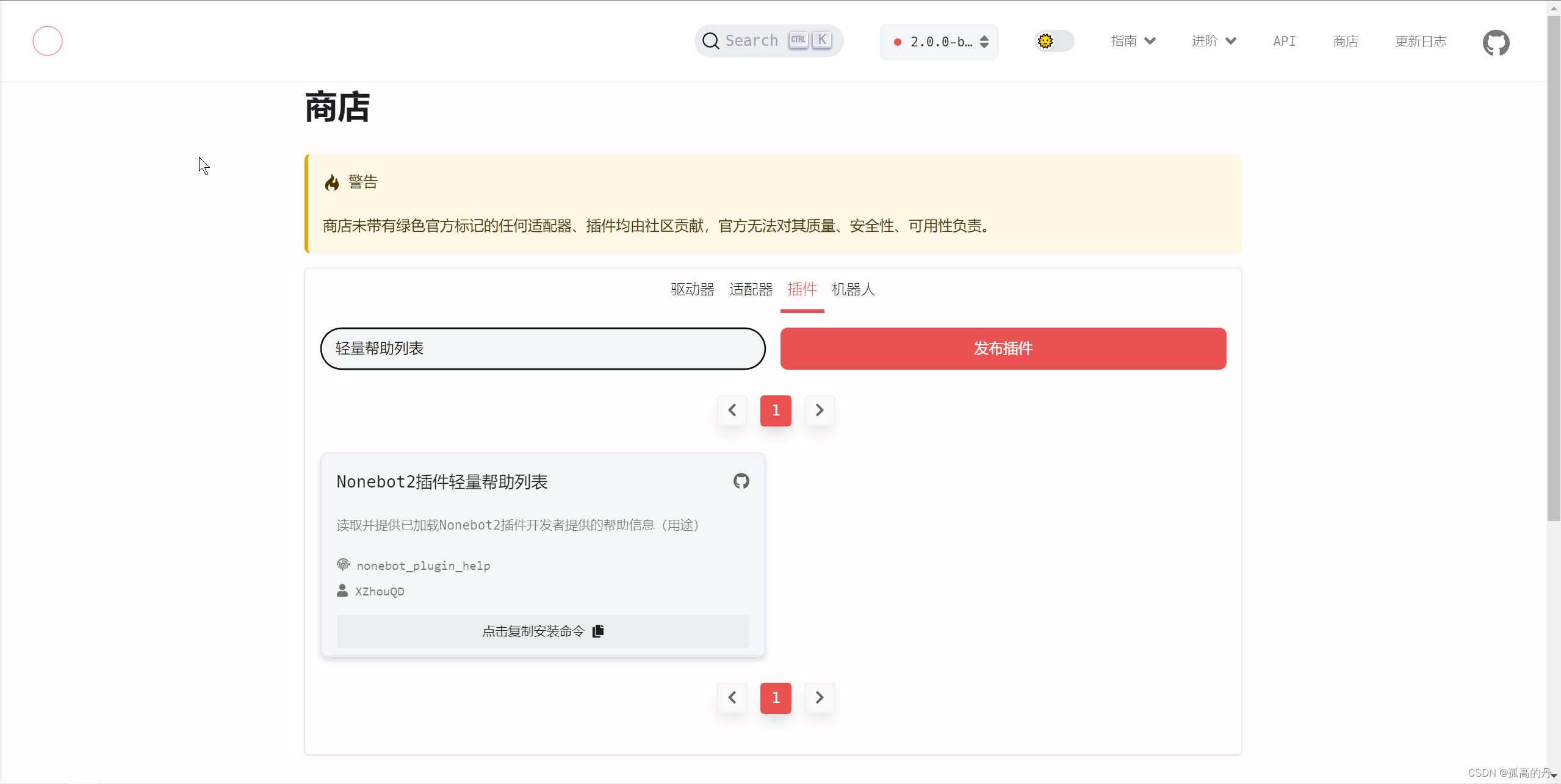
АВзАВНжшЭЌЩЯ
аЇЙћШчЯТ
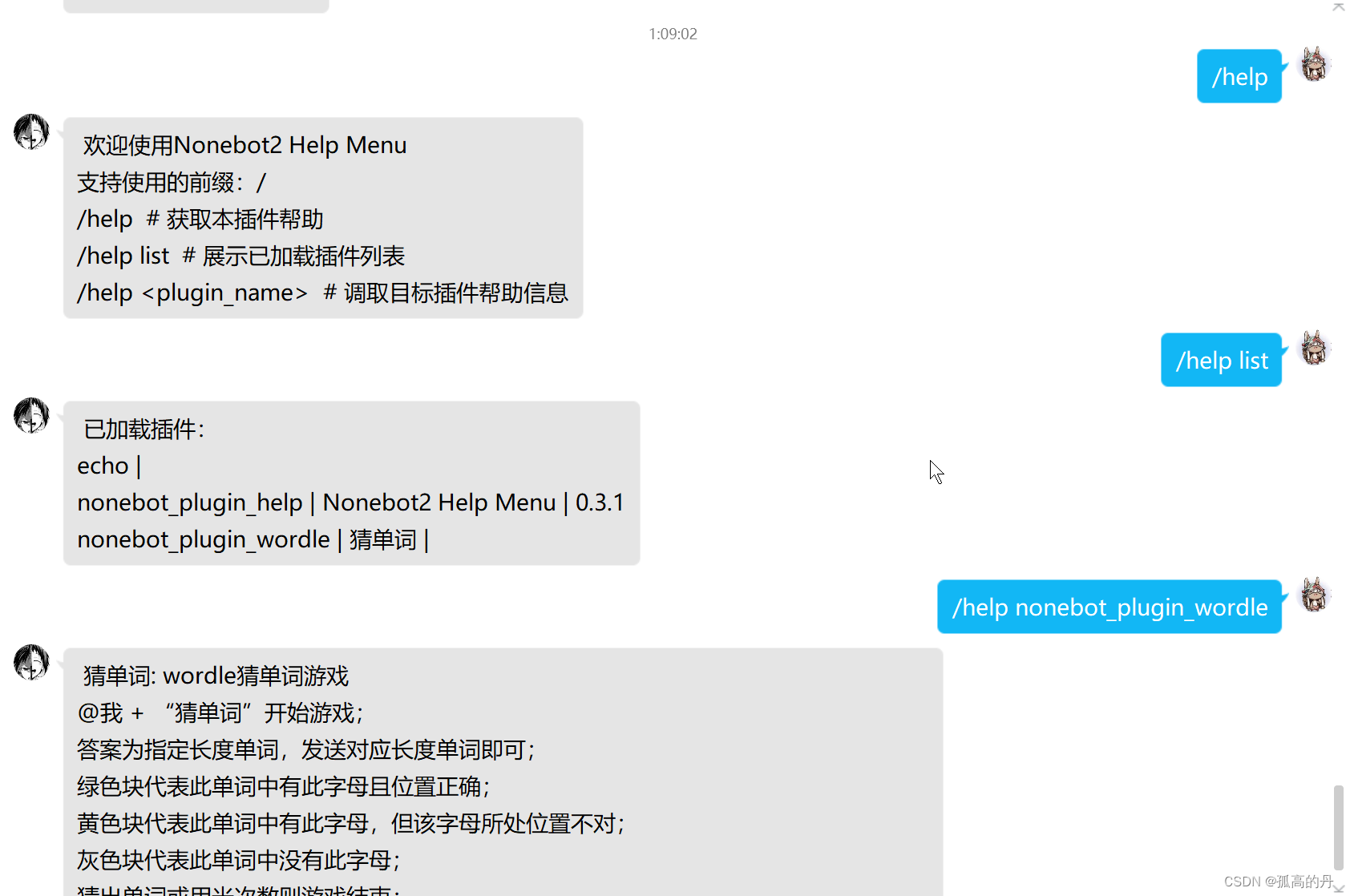
2. здЖЈвхВхМў
МђЕЅЕФЗжЯэвЛИіДѓДѓЕФNonebot2ЕФВхМў
codeforce ВщбЏВхМў
import requests
from nonebot import on_command
from nonebot.adapters.onebot.v11 import Bot, Event, Message
import random
from nonebot.adapters.onebot.v11 import MessageSegment
import json
import re
from lxml import etree
from nonebot.matcher import Matcher
from nonebot.adapters import Message
from nonebot.params import Arg, CommandArg, ArgPlainText
import nonebot
def recent_contest():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
url = "http://algcontest.rainng.com"
val = requests.get(url, headers=headers)
res = json.loads(val.content)
sum = ""
i = 0
for it in res:
i = i + 1
sum = sum + '[БШШќУћГЦ]: '
sum = sum + it['name']
sum = sum + '\n[БШШќЪБМф]: '
sum = sum + it['startTime']
sum = sum + '\n[БШШќСДНг]: '
sum = sum + it['link']
sum = sum + '\n'
if i == 3:
break
return sum
Rcontest = on_command("зюНќБШШќ", priority=2, block=True)
@Rcontest.handle()
async def Rcontest_(bot: Bot, event: Event):
try:
if int(event.get_user_id()) != event.self_id:
await bot.send(
event=event,
message=str(recent_contest())
)
except Exception as e:
await Rcontest.send("зюНќБШШќВхМўГіЯжЙЪеЯ,ЧыСЊЯЕMangata")
def get_least_cf():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
url = "http://algcontest.rainng.com"
val = requests.get(url, headers=headers)
res = json.loads(val.content)
sum = ""
i = 0
for it in res:
if it['oj'] == 'CodeForces':
sum = 'евЕНзюНќвЛГЁCodeForcesБШШќ:\n'
sum = sum + '[БШШќУћГЦ]: '
sum = sum + it['name']
sum = sum + '\n[БШШќЪБМф]: '
sum = sum + it['startTime']
sum = sum + '\n[БШШќСДНг]: '
sum = sum + it['link']
sum = sum + '\n'
break
if sum == "":
sum = "зюНќУЛгаCodeforcesБШШќро,ПЊЪМАкРУАЩ!"
return sum
codeforces = on_command(cmd="cf", priority=2, block=True)
@codeforces.handle()
async def codeforces_():
try:
await codeforces.send(get_least_cf())
except Exception as e:
await codeforces.send("зюНќCFВхМўГіЯжЙЪеЯ,ЧыСЊЯЕMangata")
def honor(num: int):
if num <= 50:
return "МсШЭКкЬњ"
elif num <= 150:
return "гЂгТЛЦЭ"
elif num <= 300:
return "ВЛЧќАзвј"
elif num <= 500:
return "ШйвЋЛЦН№"
elif num <= 650:
return "ЛЊЙѓВЌН№"
elif num <= 800:
return "шшВзъЪЏ"
elif num <= 1000:
return "ГЌЗВДѓЪІ"
elif num <= 1500:
return "АСЪРзкЪІ"
else:
return "зюЧПЭѕеп"
def get_usr(id: int):
url = "http://acm.mangata.ltd/user/" + str(id)
ua_headers = {"User-Agent": 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'}
# ЭјвГДњТы
response = requests.get(url=url, headers=ua_headers).text
# зЊЛЛЮЊetreeЖдЯѓ
tree = etree.HTML(response)
img_lst = tree.xpath('//*[@id="panel"]/div[3]/div/div[1]/div[1]/div[1]/div/div/div[2]/p[2]/text()')
message = img_lst[0].split(',')
slove_problem = int(re.findall("\d+", message[0])[0])
return "\n[ЕБЧАЖЮЮЛ]: [" + honor(slove_problem) + "]"
# Dream OJ ВщбЏгУЛЇ
DOJ_USER = on_command("DOJ", aliases={'find', 'Вщев', 'ВщевгУЛЇ'}, priority=2, block=True)
@DOJ_USER.handle()
async def DOJ_USER_(matcher: Matcher, args: Message = CommandArg()):
plain_text = args.extract_plain_text() # ЪзДЮЗЂЫЭУќСюЪБИњЫцЕФВЮЪ§,Р§:/ЬьЦј ЩЯКЃ,дђargsЮЊЩЯКЃ
if plain_text:
matcher.set_arg("name", args) # ШчЙћгУЛЇЗЂЫЭСЫВЮЪ§дђжБНгИГжЕ
@DOJ_USER.got("name", prompt="ЧыЪфШыФуЯыВщбЏЕФгУЛЇУћ...")
async def handle_DOJ_USER(name: Message = Arg(), sname: str = ArgPlainText("name")):
try:
url = "http://acm.mangata.ltd/api/?"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
query = "query {user(uname: \"" + sname + "\") {uname,mail,loginat,regat,role,avatarUrl,_id}}"
url = url + query
val = requests.get(url, headers=headers)
res = json.loads(val.content)
it = res['data']['user']
ans = ""
if res['data']['user'] == None:
ans = ans + "ВщЮоДЫШЫ"
await DOJ_USER.send(ans)
else:
id = it['_id']
ans = "\n[гУЛЇъЧГЦ]: [" + it['uname'] + "]"
ans = ans + str(get_usr(id))
ans = ans + "\n[ЩЯДЮЕЧТН]: [" + it['loginat'] + "]"
ans = ans + "\n[зЂВсЪБМф]: [" + it['regat'] + "]"
ans = ans + "\n[гУЛЇЩэЗн]: [" + it['role'] + "]"
qq = str(it['mail'])
ava = "https://q1.qlogo.cn/g?b=qq&nk="
if qq.find("@qq.com") == -1:
ava = "http://acm.mangata.ltd/file/2/12.jpg"
else:
qq = qq.strip('@qq.com')
ava = ava + qq + "&s=160"
await DOJ_USER.send(MessageSegment.image(ava) + ans)
except Exception as e:
await DOJ_USER.send("DOJгУЛЇВхМўГіЯжЙЪеЯ,ЧыСЊЯЕMangata")
# ЛёШЁЫцЛњЬтФП
def get_problem():
url = "http://acm.mangata.ltd/api/?"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
id = str(random.randint(1, 1786))
query = "query{problem(id:" + id + "){pid,title,nSubmit,nAccept,difficulty,tag}}"
url = url + query
print(url)
val = requests.get(url, headers=headers)
res = json.loads(val.content)
print(res)
it = res["data"]["problem"]
if it == None:
return str("ЬтФПвбБЛвўВиЧыдйДЮЪфШы!")
else:
link = "http://acm.mangata.ltd/p/" + it['pid']
tag = ""
l = len(it['tag'])
j = 1
for i in it['tag']:
if j < l:
tag = tag + i + "ЁЂ"
else:
tag = tag + i
j = j + 1
ans = "[ЬтФПУћГЦ]: " + it['title']
ans = ans + "\n[ЬтФПСЌНг]: " + link
ans = ans + "\n[ЫуЗЈБъЧЉ]: " + tag
ans = ans + "\n[змЬсНЛЪ§]: " + str(it['nSubmit'])
ans = ans + "\n[змЭЈЙ§Ъ§]: " + str(it['nAccept'])
ans = ans + "\n[дЄЙРФбЖШ]: " + str(it['difficulty'])
ans = ans + "\nЩЇФъПьРДЬєеНАЩ!Б№ЭќСЫаДЬтНтро!"
return ans
# УПШевЛЬт
DOJ_PROBLEM = on_command("ЫцЛњЬтФП", aliases={'УПШевЛЬт'}, priority=2, block=True)
@DOJ_PROBLEM.handle()
async def DOJ_PROBLEM_(bot: Bot, event: Event):
if int(event.get_user_id()) != event.self_id:
ans = get_problem()
await bot.send(
event=event,
message=ans
)
здЖЈвхВхМўЕМШыЗНЪН
1.дк plugins ФПТМжааТНЈЮФМўМа, УќУћЮЊВхМўЕФУћГЦ
ps:УћГЦзюКУШЋгЂ, жаЮФПЩФмЛсГіЯжФЊУћЦцУюЕФБЈДэ
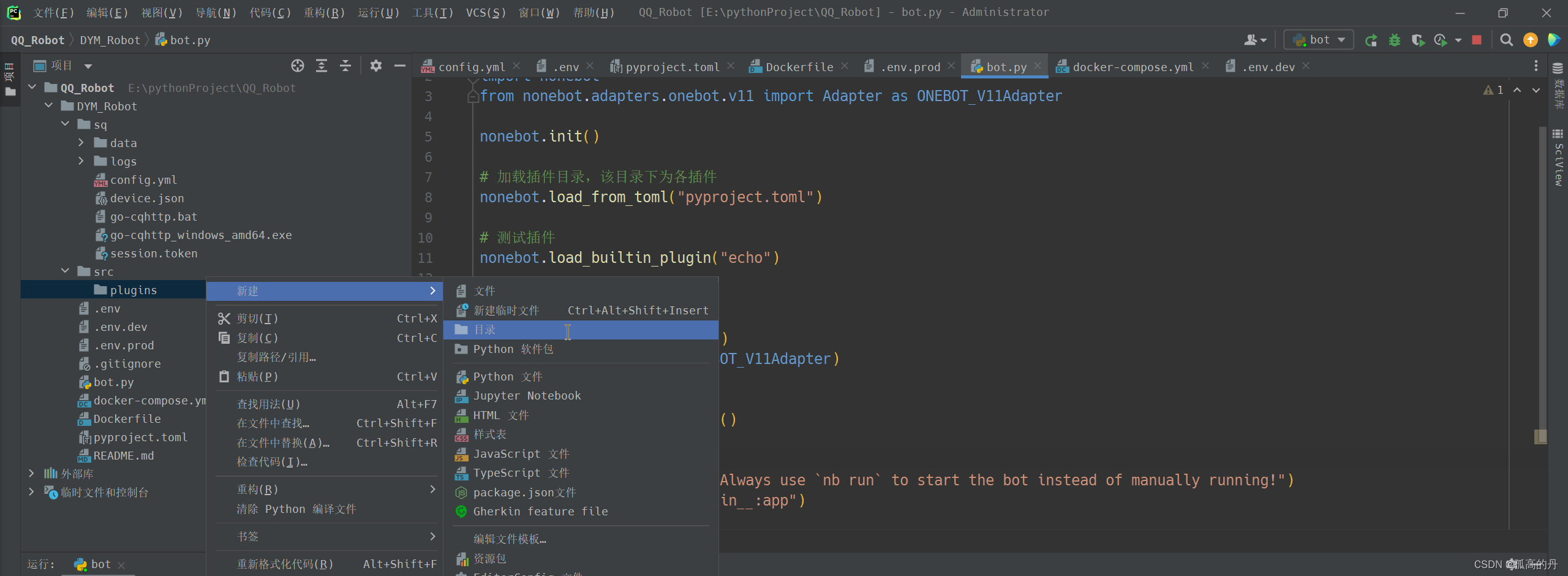
2.дкаТНЈЕФЮФМўМаРяДДНЈpythonЮФМў __init__
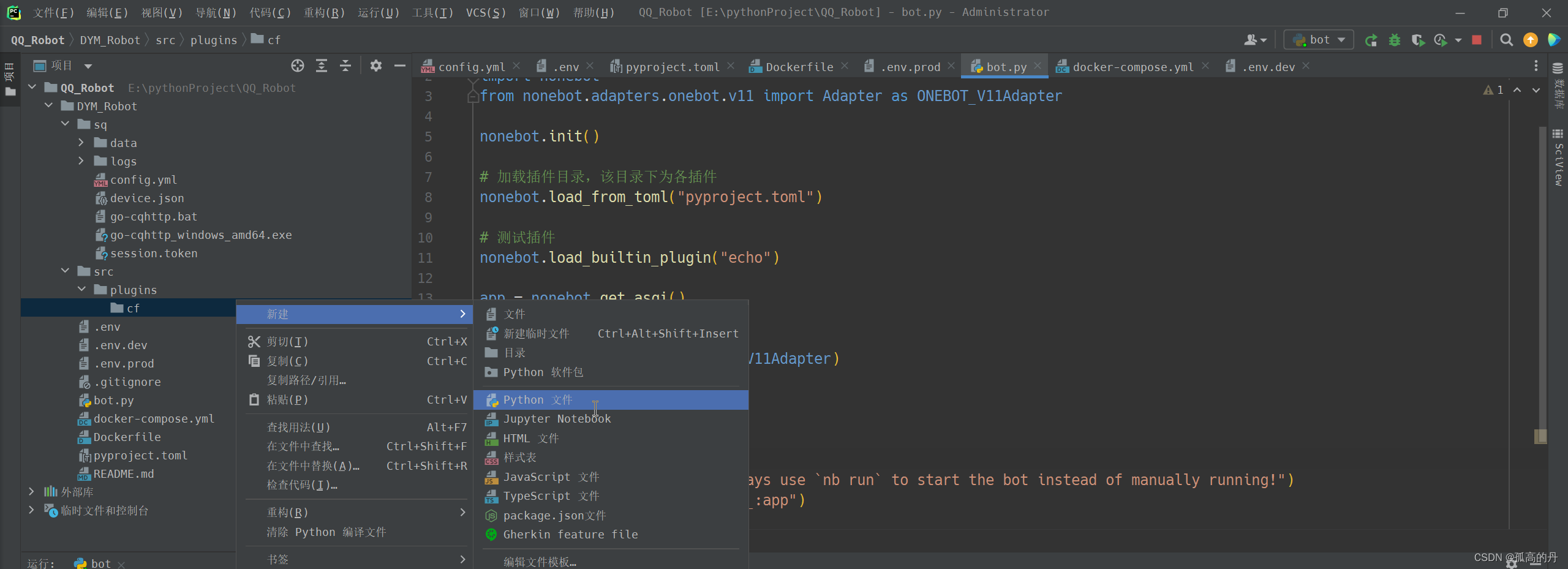
ЩЯЮФжаЕФ
АяжњНчУцПЩвдздМКаДХЖ, ФЃАхШчЯТШчЫљЪО, ЬэМгЕНФПБъВхМў__init__.pyЕФДњТыЖЮРя
from nonebot.plugin import PluginMetadata
__plugin_meta__ = PluginMetadata(
name="ВхМўУћГЦ",
description="УшЪі",
usage=(
"ЬсЪОФкШн"
),
extra={
# ЖюЭтаХЯЂ
"unique_name": "",
"example": "ВйзїАяжњ",
"author": "зїеп",
"version": "АцБО",
},
)
3.дк __init__.py ЮФМўжаеГЬљЯШааМьбщЙ§ЕФДњТы
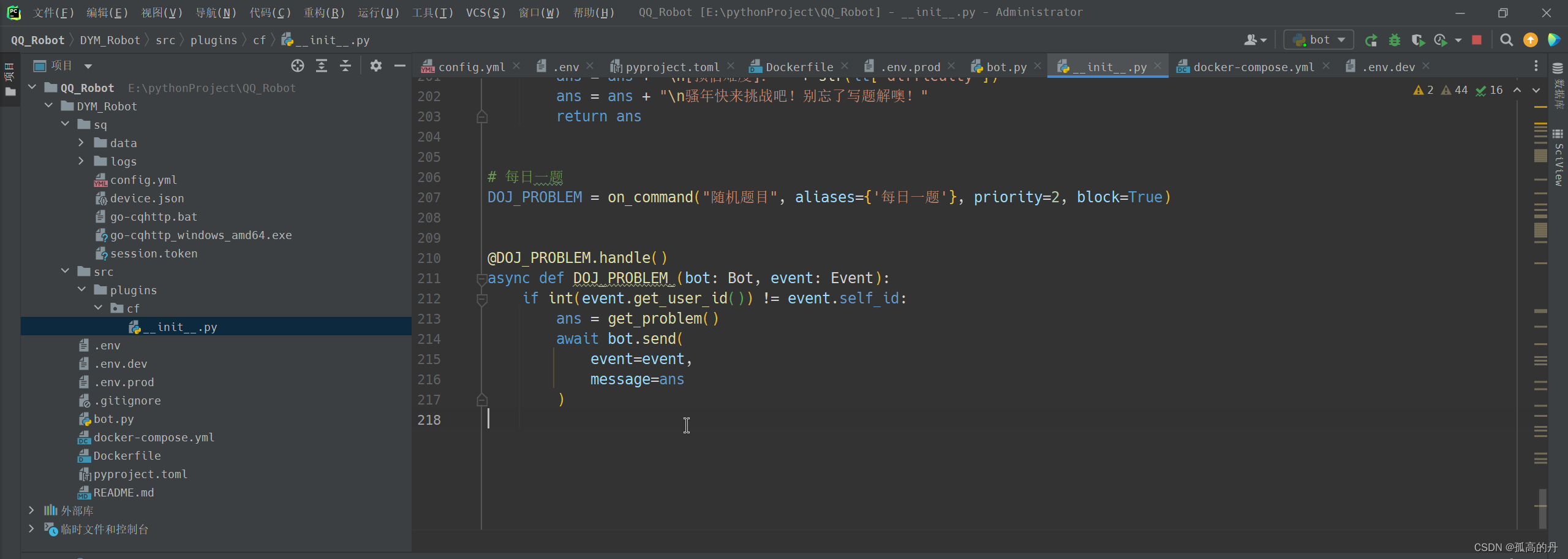
ШчЭМОЭЪЧздЖЈвхВхМўе§ГЃдЫаа SUCCESS

аЇЙћШчЯТ

ХРГцДѓРаПЩвдздаааоИФДњТы, БфГЩХРШЁШЮвтЭјеОЕФБШШќаХЯЂ, ЛђепЪЧЬтФПаХЯЂ
ЫљЮНздЖЈвхВхМў, ПЯЖЈЪЧвЊгавЛаЉЛљДЁВХФмздМКзіГіРДЕФ,бЇЯАДѓДѓУЧЕФВхМў, зЊЛЏГЩздМКЕФжЊЪЖ,
вВЪЧзЗЧѓжЊЪЖКЭЮДжЊЕФЩйФъУЧгІИУЮЊжЎЗмЖЗЕФ. ЫљвдВЉжїетИіаЁУШаТОЭВЛдйЫЕЛАСЫ, БЯОЙаЁЛяАщУЧгаФЅэТВХФмдНзпдНдЖ
НсЮВ
1.змНс
ЪюМйЗХМйЪТЧщБШНЯЖр, ВЉжїЮЊСЫЩњМЦБМВЈРЭРл, ЮЊСЫОКШќЫуЗЈВйЫщСЫаФ, ЮЊаФАЎЕФбЇЕмбЇУУУЧЕФАООЁаФбЊ, ЖдДѓбЇКУХѓгбУЧШевЙЫМФю, ЯЪгаЪБМфОВЯТаФРДЫМПМКЭзмНсЁ етИіЪЧВЉжїдкСљдТГіОЭЦєЖЏЕФ
ПеЭЗМЦЛЎ, КѓРДгаСЫВЉжїКУЭЌжОЕФвЛаЉЦєЗЂ, еце§ЭъЩЦСЫвЛЯТФкШн, жаМфВПЗжшІДУЧыИїЮЛаЁЛяАщУЧЦРТлЧјЬИТл
2.ЯТЦкФПБъ
ЭјеОКѓЖЫ + Ъ§ОнПтЕФвЛаЉЮЪЬт, Лђеп, БШШчЬсЫйАйЖШЭјХЬ, зюЧПЕФНиЭМШэМў, CodeforcesБШШќжњЪжБ№ЕФИЩЛѕНЬбЇ , ПЩФмАЩ, БЯОЙВЉжїЛЙЕУСєзХИЮШЂРЯЦХФи, Ыљвд, ецЕФВЛЪЧВЉжїЭаИќАЁ! етОЭЪЧдзЬдЮЖЕФ
ПеЭЗМЦЛЎ
