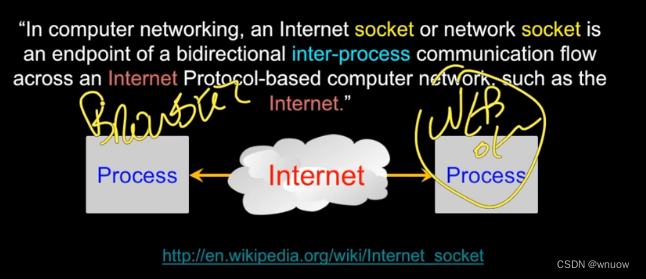
TCP Connection / Sockets
TCP Port Number

In a client-server application on the web using sockets, server must come up first

Sockets in Python
调用socket包创建socket

从网页中获取文件,会返回metadata和网页内容
# open a socket,send a command, retrieve the data
import socket
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #这一步还没有连接socket,是将socket视为file handle
mysock.connect(('data.pr4e.org', 80)) #通过网络连接目的地域名,第二个参数是port number;在cmd中输入telnet命令也可以实现
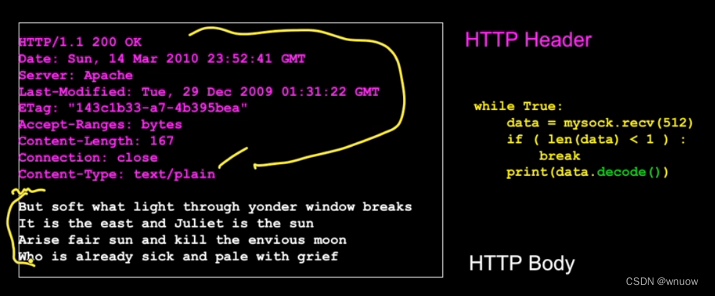
cmd = 'GET http://data.pr4e.org/romeo.txt HTTP/1.0\r\n\r\n'.encode()# 输入url后必须空一行,separates the HTTP headers from the body of the HTTP document;encode()是将网页中的Unicode格式转化为python中默认的utf-8格式
mysock.send(cmd) #发送utf-8 bytes
while True:
data = mysock.recv(512)#请求获得512 characters,像read a file一样
if len(data) < 1:
break #如果没文件就退出
print(data.decode(),end='')
mysock.close()
Application Protocol


HTTP的最重要的方面是规定了 Which application talks first? The client or server?


URL(Uniform Resource Locator)由 Protocol, host, and document三部分组成

when a browser uses the HTTP protocol to load a file or page from a server and display it in the browser, which is called The Request/Response Cycle
Write a Web Browser

Unicode and UTF-8
ASCII
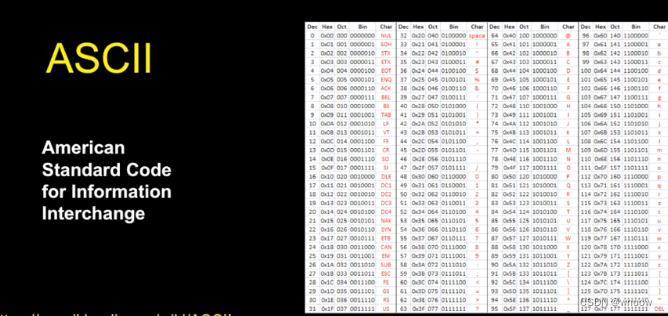

print(ord(‘’))函数查看ASCII码的值
Unicode


python3中string的格式都是Unicode
Python Strings to Bytes

urllib
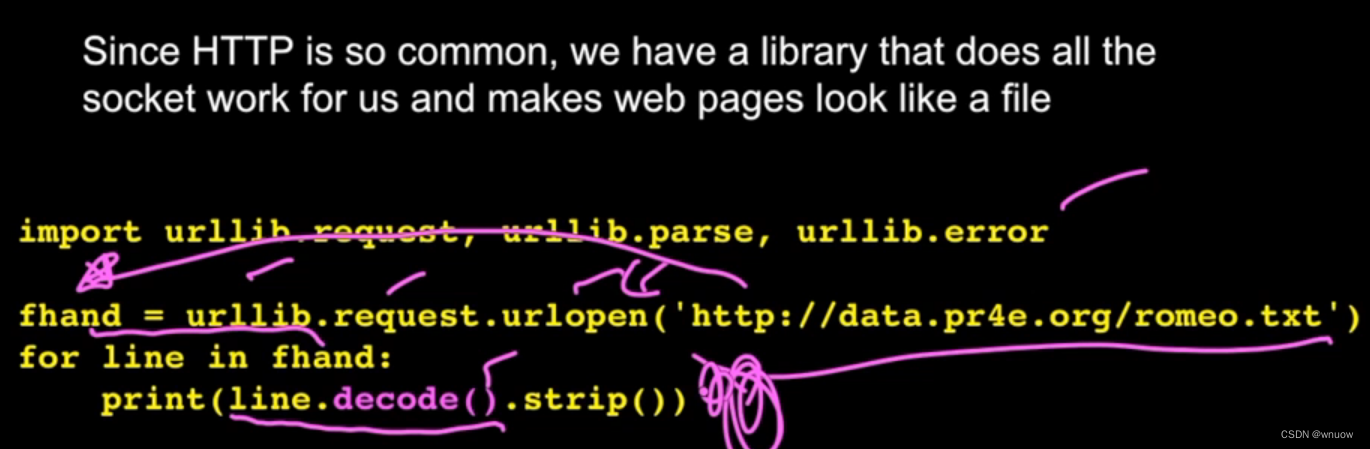
采用urllib可以将网页内容像file一样处理
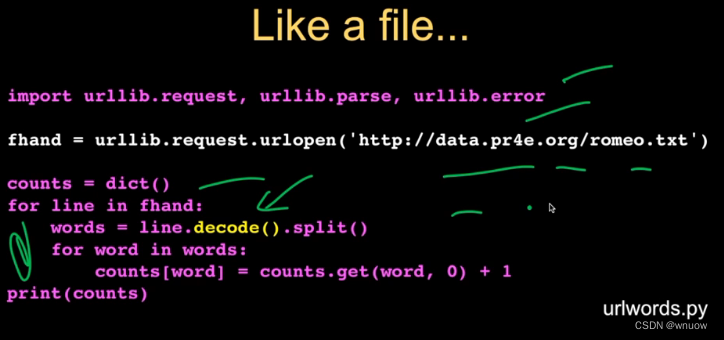
用于阅读网页
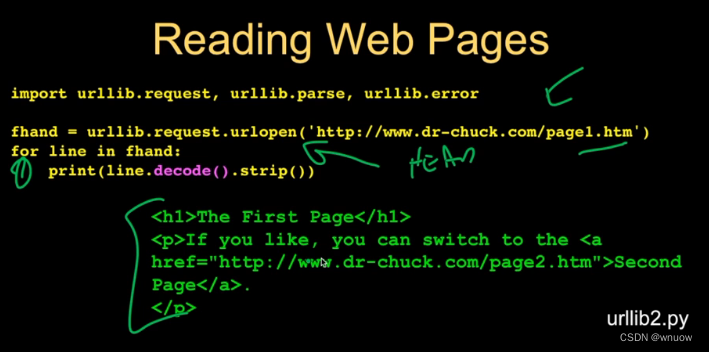
import urllib.request
fhand = urllib.request.urlopen('http://data.pr4e.org/romeo.txt')# make socket calls,输出tring,比较像file handle
for line in fhand:
print(line.decode().strip()) #不会输出headers,只输出contents;记得加decode()去legitimate string
用于获取网页中的链接
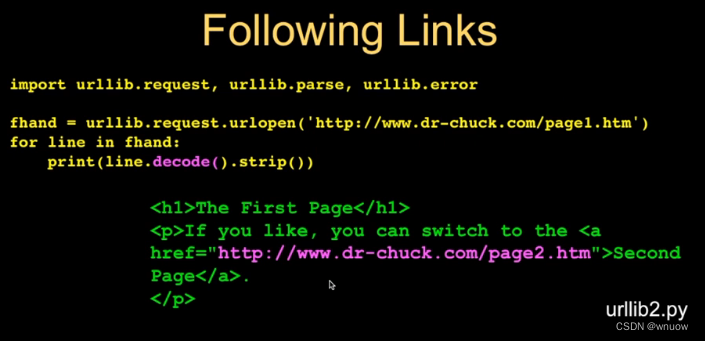
When you click on an anchor tag in a web page like below, what HTTP request is sent to the server?
<p>Please click <a href="page1.htm">here</a>.</p>
==> GET
Web Scraping

有些网站不能爬,得看条款

BeautifulSoup的目的:It repairs and parses HTML to make it easier for a program to understand
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup # 必须把bs4文件放在和code同一个文件夹里
import ssl
# Ignore SSL certificate errors,为了解决HTTPS问题
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urllib.request.urlopen(url, context=ctx).read() #.read()是为了把网页读取return成一个整的文档
soup = BeautifulSoup(html, 'html.parser') # html网页可能存在很多混乱和错误,BeautifulSoup的作用是将其返回为一个clean object
# Retrieve all of the anchor tags
tags = soup('a') # return a list of all the anchor tags (<a..) in the HTML from the URL
for tag in tags:
print(tag.get('href', None))
# Retrieve all of the anchor tags
tags = soup('a')
for tag in tags:
# Look at the parts of a tag
print 'TAG:',tag
print 'URL:',tag.get('href', None)
print 'Contents:',tag.contents[0] #将tag的子节点以list的方式输出
print 'Attrs:',tag.attrs #属性attribute,是一个字典,默认为空