ЧАбд

????
гіМћФуЪБ,ТўЬьаЧКгНдЮЊИЁГО

ВЛжЊДгЪВУДЪБКђПЊЪМЁЃаЁЫЕПЊЪМЯЦЦ№СЫвЛЙЩРЫГБ,ЫќШУЮвУЧЦНШеРяЕФЩњЛюВЛдкПндяЗІ
ЮЖ,КмЖрЮвУЧзіВЛЕНЕФЪТЧщдкаЁЫЕРяЖМФмЧсвзЪЕЯжЁЃ
ФЧУДЛАВЛЖрЫЕ,ЯТУцЮвУЧОЭРДОпЬхПДПДЫќЪЧШчКЮЪЕЯжЕФАЩ👇

е§ЮФ
етРявдвЛВПаЁЫЕЮЊР§,НЋУПвЛеТЕФФкШнХРШЁЯТРДБЃДцЕНБОЕиЁЃ
👇ЪЧЮвУЧвЊХРЕФаЁЫЕФПТМ
ХРШЁЯТРДЕФЪ§Он:
ЗжЮіЭјвГФУЪ§Он
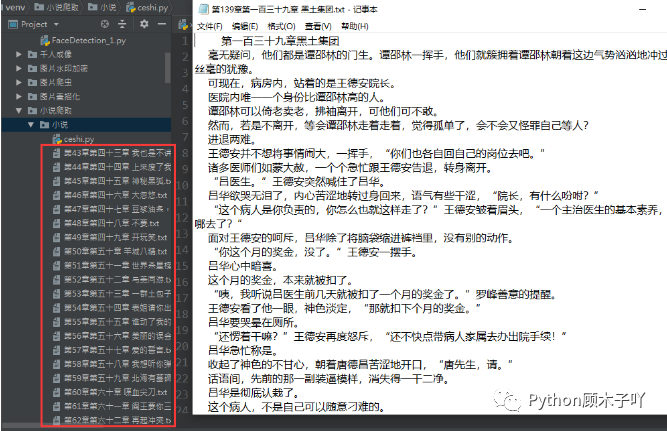
ЪзЯШРћгУrequestsПтЕФЧПДѓФмСІ,ЯђФПБъЗЂЦ№ЧыЧѓ,ФУЕНвГУцжаЕФЫљгаHTMLЪ§ОнЁЃ
url(https://www.biduo.cc/biquge/40_40847/)ашвЊзЂвтЕФЪЧ:ЧыЧѓЬЋЖрДЮКмШнвзБЛЗДХР,зюКУдкЧыЧѓЪБДјЩЯЧыЧѓЭЗ(ФЃФтфЏРРЦїЗЂЧыЧѓ),УПИіШЫ
ЕФфЏРРЦїЕФЧыЧѓЭЗЖМВЛЭЌ,ВЛФмжБНгЪЙгУЮвДњТыжаЕФЧыЧѓЭЗ,дѕУДЛёШЁздМКЕФЧыЧѓЭЗПЩАДШчЯТЭМЗН
ЪНФУЕН:
ФУЕНЫљгаHTMLЪ§ОнКѓ,РћгУе§дђПтНсКЯxpathгяЗЈ(ПЩвдздМКШЅбЇвЛЯТXPath?НЬГЬ)ДгжаГщШЁеТУћКЭ
УПвЛеТЕФСДНг,ШчЯТЭМ?//*[@id=ЁАlistЁБ]/dl/dd/a/text()?КЭ?//*[@id=ЁАlistЁБ]/dl/dd/a/@href?МДПЩФУЕНЮвУЧаш
вЊЕФеТНкУћГЦКЭЖдгІЕФСДНгЕижЗ:
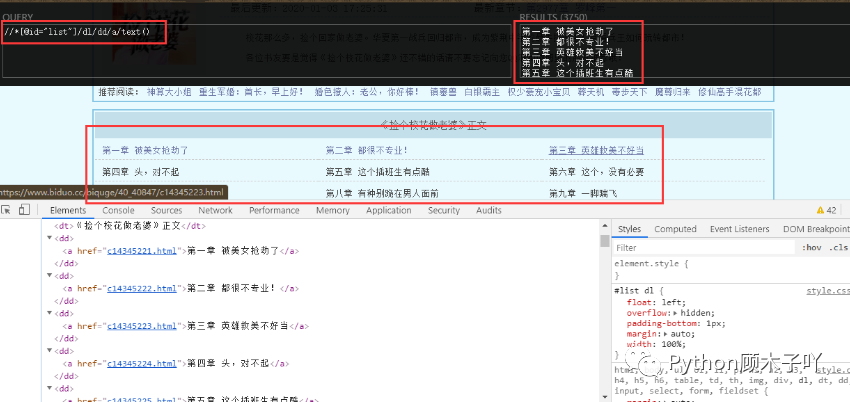
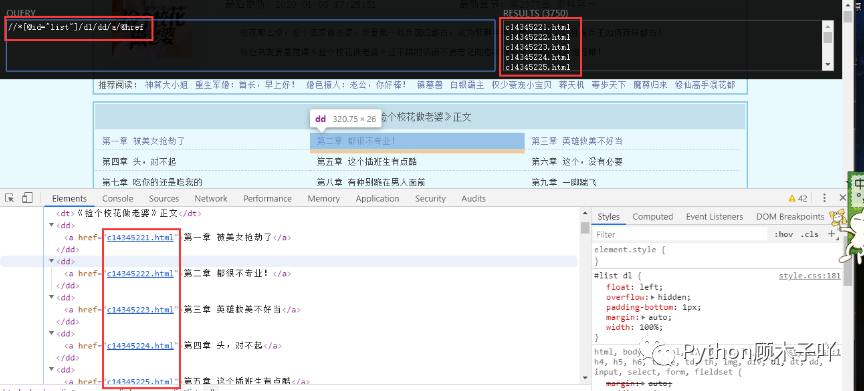
ЯждквбОФУЕНЮвУЧашвЊЕФеТНкУћГЦКЭЖдгІУПвЛеТЕФСДНгЕижЗСЫ,етРяЕУЕНЕФУПвЛеТЕФСДНгЕижЗЛЙВЛ
ЪЧвЛИіЭъећЕФurlЕижЗ,ЗжЮіЕижЗРИПЩжЊФПБъurl(https://www.biduo.cc/biquge/40_40847/)гыУПвЛ
еТЕФСДНгЕижЗЦДНг,МДПЩЕУЕНЮвУЧзюжеЫљашЕФURLЁЃ
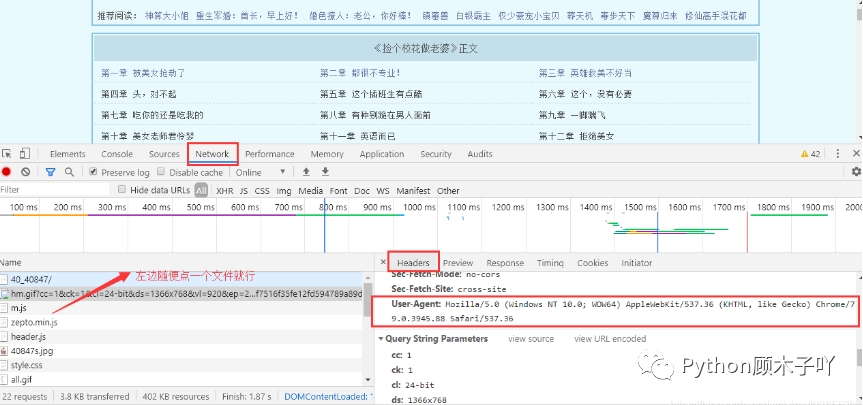
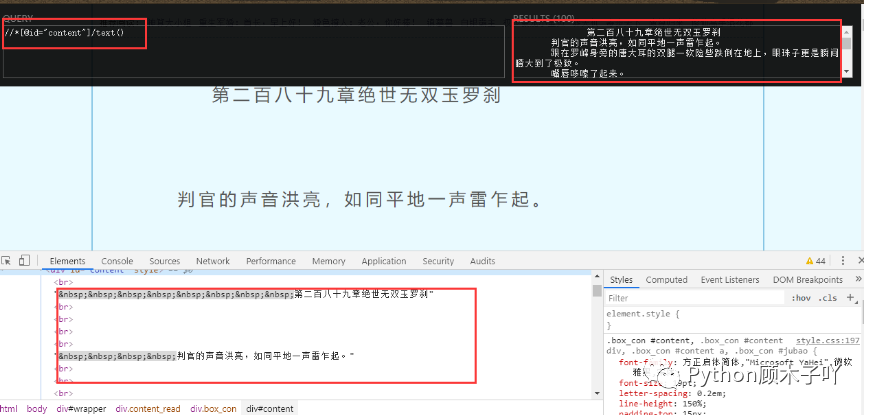
# 2. ЧыЧѓЮФеТФУЕНHTMLЪ§Он,ГщШЁЮФеТФкШнВЂБЃДцresponse = requests.get(url + src,headers=headers)
ЕУЕНзюжеURLКѓ,ВуВуЕнНј,ЯрЭЌЕФЗНЗЈ:ЯђзюжеЕФURLЕижЗЗЂЦ№ЧыЧѓЕУЕНаЁЫЕФкШнвГЕФЫљга
HTMLЪ§Он,дйДгжаГщШЁЮвУЧашвЊЕФаЁЫЕЮФзжФкШн,ВЂБЃДцЕНБОЕивдЮвУЧГщШЁЕНЕФеТУћРДУќУћЮФ
Мў:
# 2. ЧыЧѓЮФеТФУЕНHTMLЪ§Он,ГщШЁЮФеТФкШнВЂБЃДцresponse = requests.get(url + src,headers=headers)html = etree.HTML(response.content.decode('gbk')) # ећРэЮФЕЕЖдЯѓcontent = "\n".join(html.xpath('//*[@id="content"]/text()'))file_name = tit + ".txt"print("е§дкБЃДцЮФМў:{}".format(file_name))with open(file_name, "a", encoding="utf-8") as f:????f.write(content)
аЇЙћеЙЪОЁЊЁЊ
ДњТыеЙЪОЁЊЁЊ
import requests
from lxml import etree
url = "https://www.biduo.cc/biquge/40_40847/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
class Spider(object):
def detail_request(self):
# 1. ЧыЧѓФПТМФУЕНHTMLЪ§Он,ГщШЁеТУћЁЂеТСДНг
response = requests.get(url,headers=headers)
# print(response.content.decode('gbk'))
html = etree.HTML(response.content.decode('gbk')) # ећРэЮФЕЕЖдЯѓ
# print(html)
tit_list = html.xpath('//*[@id="list"]/dl/dd/a/text()')
url_list = html.xpath('//*[@id="list"]/dl/dd/a/@href')
print(tit_list,url_list)
for tit, src in zip(tit_list, url_list):
self.content_request(tit, src)
def content_request(self, tit, src):
# 2. ЧыЧѓЮФеТФУЕНHTMLЪ§Он,ГщШЁЮФеТФкШнВЂБЃДц
response = requests.get(url + src,headers=headers)
html = etree.HTML(response.content.decode('gbk')) # ећРэЮФЕЕЖдЯѓ
content = "\n".join(html.xpath('//*[@id="content"]/text()'))
file_name = tit + ".txt"
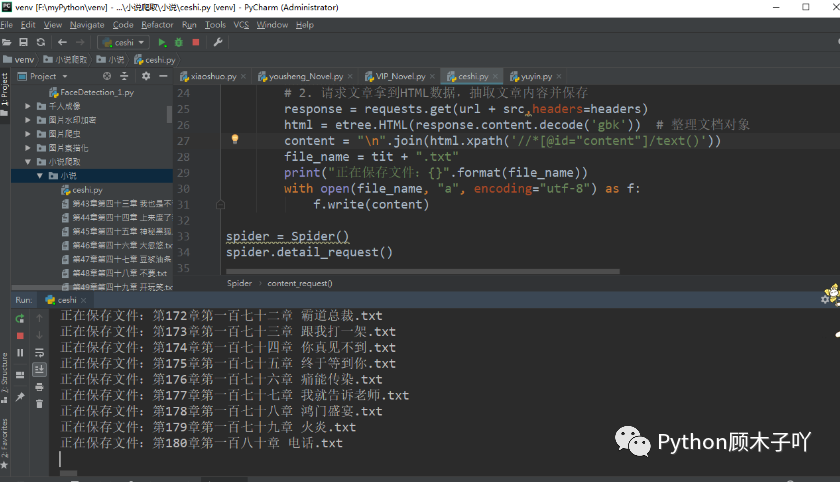
print("е§дкБЃДцЮФМў:{}".format(file_name))
with open(file_name, "a", encoding="utf-8") as f:
f.write(content)
spider = Spider()
spider.detail_request()змНс
КУРВ!ЮФеТЕНетРяОЭе§ЪННсЪј,БШЦ№Ь§ИшЮвЛЙЪЧИќЯВЛЖПДаЁЫЕЕФРВ!
ДѓМвЯВЛЖЪВУДЯюФППЩвдЦРТлЧјСєбдХЖ~
гаЮЪЬтЛђепашвЊЪгЦЕбЇЯАЕФПЩвдевЮвЙЕЭЈЙў👇
?ЭъећЕФЫиВФдДТыЕШ:ПЩвдЕЮЕЮЮвпЙ!ЛђепЕуЛїЮФФЉhaoздШЁУтЗбФУЕФЙў~
😘ЭљЦкЭЦМідФЖСЁЊЁЊ
ЯюФП0.1??ЁОPythonХРГцЯЕСаЁПPythonХРГцШыУХВЂВЛФб,ЩѕжСШыУХвВКмМђЕЅ(в§бд)ЯюФП0.2
ЯюФП0.3???PythonХРГцШыУХЭЦМіАИР§:бЇЛсХРГц_БэЧщАќЪжЕНЧмРД~
ЯюФП0.4?ЁОTkinterНчУцЛЏаЁГЬађЁПгУPythonзівЛПюУтЗбвєРжЯТдиЦїЁЂЮоЙуИцЮоЕЏДАЁЂЧхЫЌГЌСїГЉХЖ
ЯюФП0.5??ЁОPythonХРГцЯЕСаЁПЧГГЂвЛЯТХРГц40Р§ЪЕеННЬГЬ+дДДњТыЁОЛљДЁ+НјНзЁП
ЯюФП0.6??ЁОPythonХРГцЪЕеНЁПЪЙгУSeleniumХРФГвєРжИшЧњМАЦРТлаХЯЂРВ~
🎁ЮФеТЛузмЁЊЁЊ
PythonЮФеТКЯМЏ | (ШыУХЕНЪЕеНЁЂгЮЯЗЁЂTurtleЁЂАИР§ЕШ)
(ЮФеТЛузмЛЙгаИќЖрФуАИР§ЕШФуРДбЇЯАРВ~дДТыевЮвМДПЩУтЗб!)
