?
活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰!
一、python操作PDF的13大库
????????PDF英文Portable Document Format,是一种便携文档格式,便于跨操作系统传播文档,遵循标准格式,存在很多可以操作pdf文档的工具,python自然也存在很多可以操作pdf文档的模块。
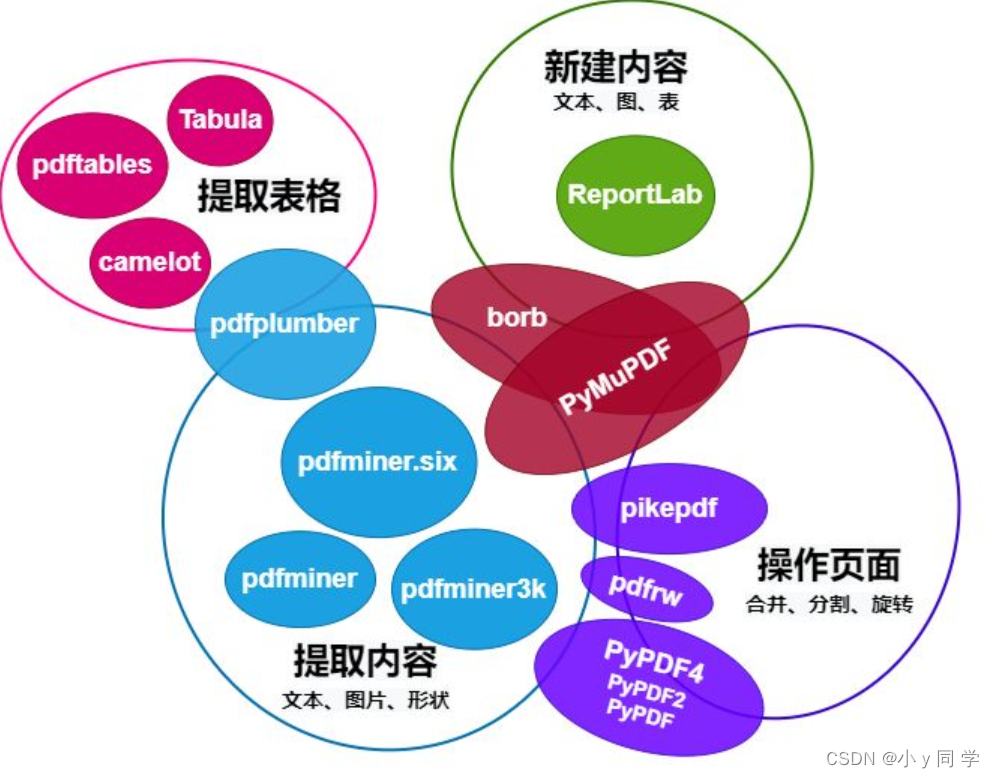
? ? ? ? python操作pdf文档模块对比图:
?本次学习主要学习了使用pdfplumber模块对PDF内容进行提取,包括文本(位置、字体及颜色)和形状(矩形、直线、曲线),以及解析表格。
二、pdfplumber模块
1、pdfplumber与其他PDF处理库的区别:
? ? ? ? ①可以轻松访问有关每个PDF对象的详细信息
? ? ? ? ②用于提取文本和表格的更高级别、可自定义的方法
? ? ? ? ③紧密集成的可视化调试? ? ? ? ④具有其他有用的实际功能,例如通过裁剪框过滤对象
2、安装pdfplumber模块
? ? ? ? 在cmd控制台输入下面命令(小y使用的是国内镜像源下载,可以大幅提升下载速度,还可以提高安装成功率)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pdfplumber? ? ? ? 导包:
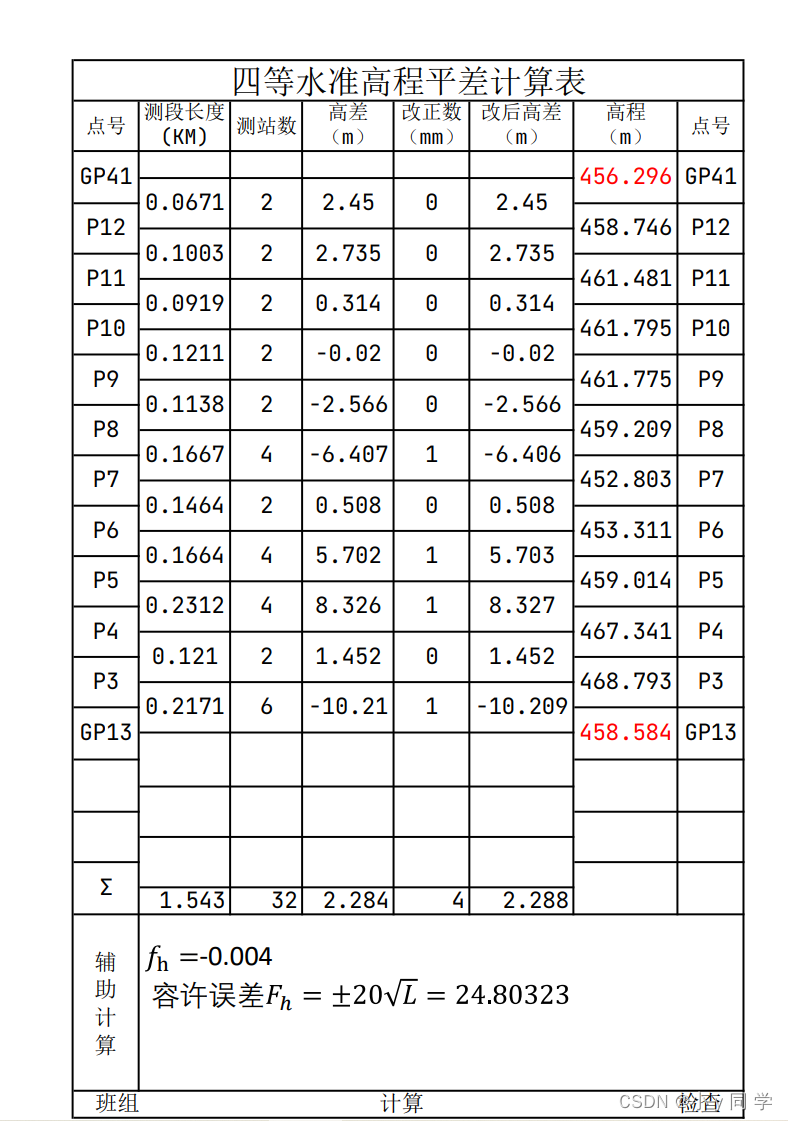
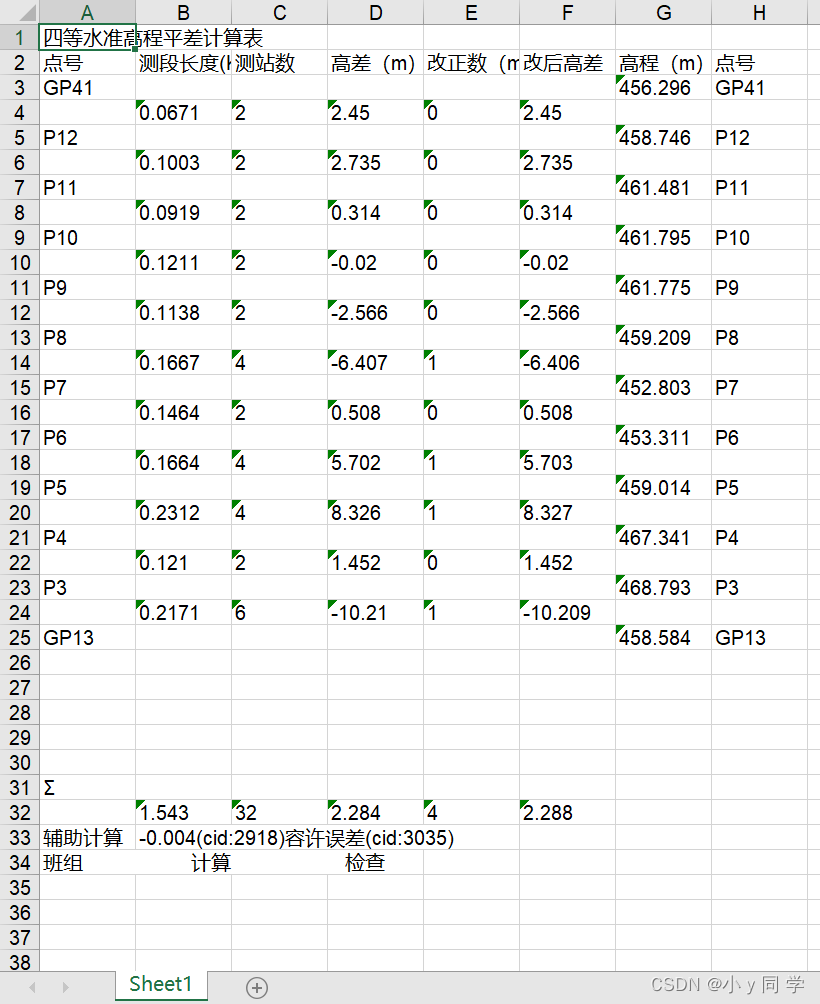
import pdfplumber????????案例pdf截图
案例下载地址:?pdf测试文档―终水准表格.pdf-数据集文档类资源-CSDN下载
3、加载PDF
读取PDF的代码:
pdfplumber.open('路径/文件名.pdf', password='', laparams={})参数:
????????password:如果加载的pdf受到密码保护,就要传递password关键字参数
? ? ? ? laparams:要将布局分析参数设置为pdfminer.six的布局引擎,需要传递laparams关键字参数
案例代码:
import pdfplumber with pdfplumber.open('./终水准表格.pdf') as pdf: print(pdf) print(type(pdf))输出结果:
4、pdfplumber.PDF类
pdfplumber.PDF类表示单个PDF,并具有两个主要属性:
属性 说明 .metadata 从PDF的Info中获取元数据键 /值对字典。 通常包括“CreationDate”,“ ModDate”,“ Producer”等。 .pages 返回一个包含pdfplumber.Page实例的列表,每一个实例代表PDF每一页的信息 ①读取PDF文档信息(.metadata):
import pdfplumber with pdfplumber.open('./终水准表格.pdf') as pdf: print(pdf.metadata)运行结果:
{'Author': '86178', 'CreationDate': "D:20220614130104+08'00'", 'ModDate': "D:20220614130104+08'00'", 'Producer': 'Microsoft: Print To PDF', 'Title': 'è4?h<.xlsx'}②输出总页数
import pdfplumber with pdfplumber.open('./终水准表格.pdf') as pdf: print(len(pdf.pages))运行结果:
15、pdfplumber.Page类
pdfplumber.Page类是pdfplumber整个的核心,大多数操作都围绕这个类进行操作,它具有以下几个属性:
属性 说明 .page_number 顺序页码,从1第一页开始,从第二页开始2,依此类推。 .width 页面的宽度。 .height 页面的高度 .objects/.chars/.lines/.curves/.figures/.images 这些属性中每一个都是列表,每一个列表包含一个字典,用于嵌入页面上的每个此类对象。 常用方法:
.extract_text() 用于提取页面中的文本,将页面的所有字符对象整理成字符串 .extract_words() 返回的是所有的单词及其相关信息 .extract_tables() 提取页面表格 .to_image() 用于可视化调试时,返回PageImgae类的一个实例 .close() 默认情况下,Page对象缓存其布局和对象信息,目的是避免重复处理它。但是,在解析大新PDF时,这些缓存属性可能需要大量的内存,此方法可以刷新缓存并且释放内存 ③读取第一页宽度、高度等信息
import pdfplumber with pdfplumber.open('./终水准表格.pdf') as pdf: first_page = pdf.pages[0] # pdfplumber.Page对象的第一页 print('页码:', first_page.page_number) # 查看页码 print('页宽:', first_page.width) # 查看页宽 print('页高:', first_page.height) # 查看页高运行结果:
④读取文本第一页
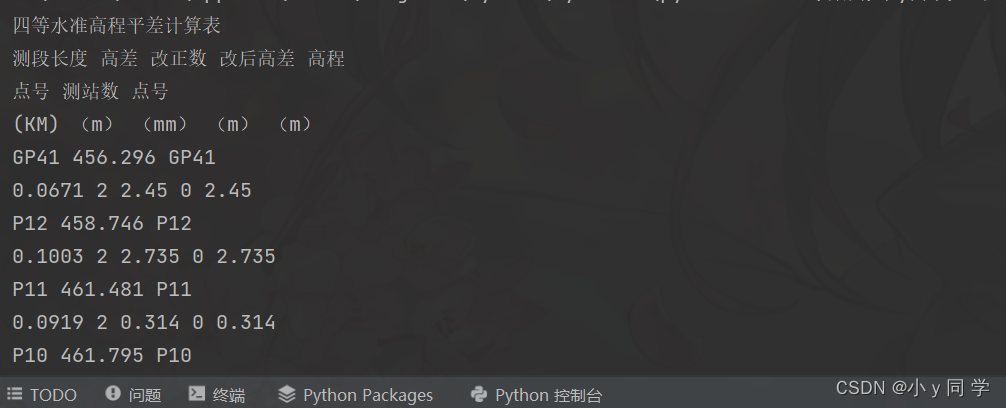
import pdfplumber with pdfplumber.open('./终水准表格.pdf') as pdf: first_page = pdf.pages[0] # pdfplumber.Page对象的第一页 text = first_page.extract_text() print(text)运行结果:
⑤读取表格一页
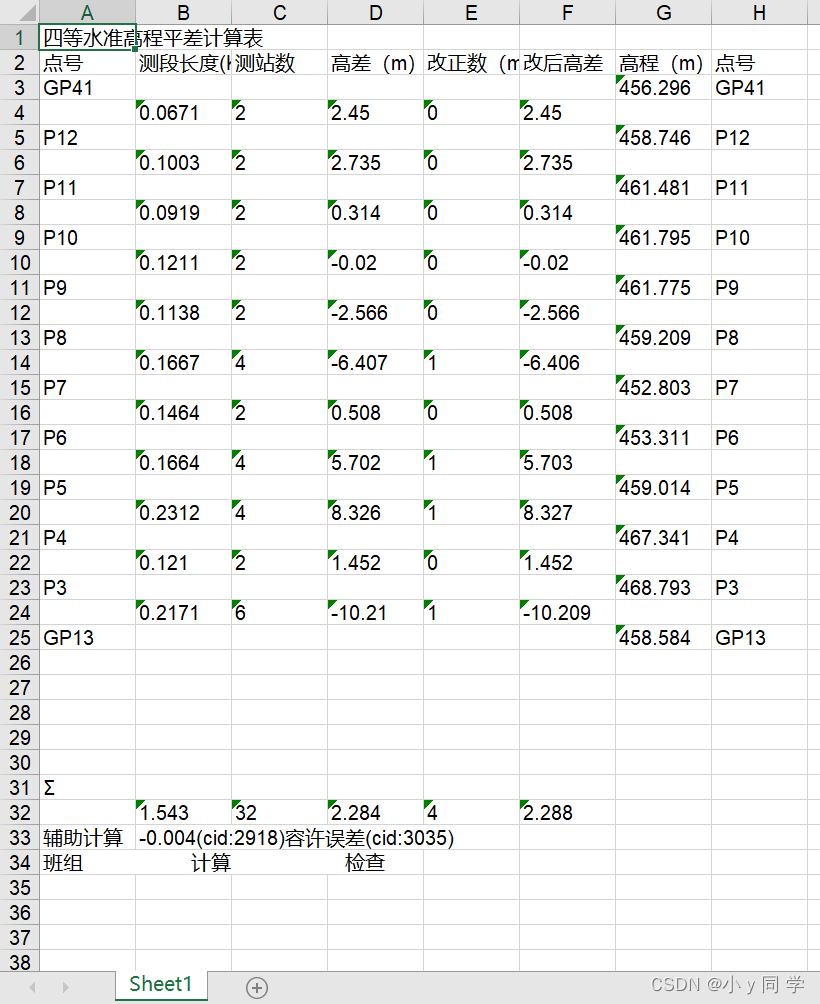
import pdfplumber import xlwt with pdfplumber.open('./终水准表格.pdf') as pdf: page_one = pdf.pages[0] # PDF第一页 table_1 = page_one.extract_table() # 读取表格数据 # 1. 创建Excel表对象 workbook = xlwt.Workbook(encoding='utf8') # 2. 新建sheet表 worksheet = workbook.add_sheet('Sheet1') # 3. 自定义列名 col1 = table_1[0] # print(col1)# ['店铺名', '价格', '销量', '地址'] # 4. 将列属性元组col写进sheet表单中第一行 for i in range(0, len(col1)): worksheet.write(0, i, col1[i]) # 5. 将数据写进sheet表单中 for i in range(0, len(table_1[1:])): data = table_1[1:][i] for j in range(0, len(col1)): worksheet.write(i + 1, j, data[j]) # 6. 保存文件分两种格式 workbook.save('test.xls')运行结果:


三、实战操作
1、提取单个PDF全部页数(这里小y准备资源不足,所以只有一页)
测试代码:
import pdfplumber import xlwt with pdfplumber.open("./终水准表格.pdf") as pdf: # 1. 把所有页的数据存在一个临时列表中 item = [] for page in pdf.pages: text = page.extract_table() for i in text: item.append(i) # 2. 创建Excel表对象 workbook = xlwt.Workbook(encoding='utf8') # 3. 新建sheet表 worksheet = workbook.add_sheet('Sheet1') # 4. 自定义列名 col1 = item[0] # print(col1)# ['店铺名', '价格', '销量', '地址'] # 5. 将列属性元组col写进sheet表单中第一行 for i in range(0, len(col1)): worksheet.write(0, i, col1[i]) # 6. 将数据写进sheet表单中 for i in range(0, len(item[1:])): data = item[1:][i] for j in range(0, len(col1)): worksheet.write(i + 1, j, data[j]) # 7. 保存文件分两种格式 workbook.save('test1.xls')运行结果:
?
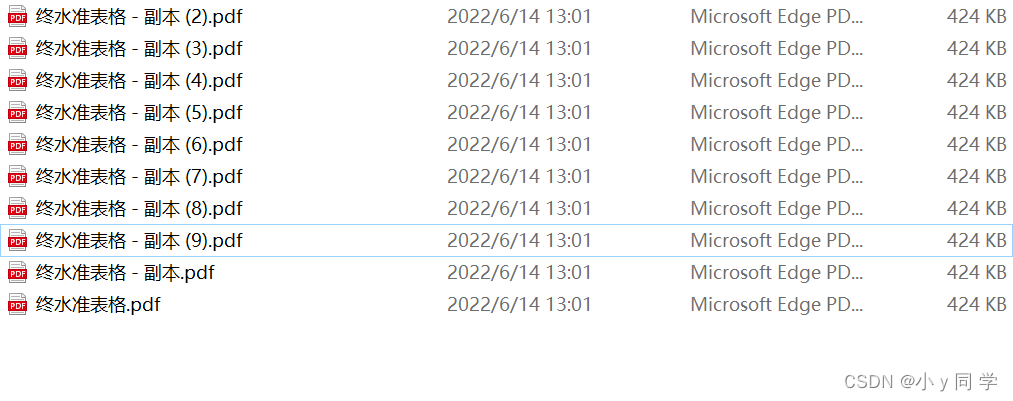
2、批量提取多个PDF(此段代码值得细品,对以后批量处理文件有一定作用)
import pdfplumber import xlwt import os # 一、获取文件下所有pdf文件路径 file_dir = os.getcwd() file_list = [] for files in os.walk(file_dir): # print(files) # ('E:\\Python学习\\pdf文件', [], # ['1.pdf', '1的副本.pdf', '1的副本10.pdf', '1的副本11.pdf', '1的副本2.pdf', '1的副本3.pdf', '1的副本4.pdf', '1的副本5.pdf', '1的副本6.pdf', # '1的副本7.pdf', '1的副本8.pdf', '1的副本9.pdf']) for file in files[2]: # 以. 进行分割如果后缀为PDF或pdf就拼接地址存入file_list if file.split(".")[1] == 'pdf' or file.split(".")[1] == 'PDF': file_list.append(file_dir + '\\' + file) # 二、存入Excel # 1. 把所有PDF文件的所有页的数据存在一个临时列表中 item = [] for file_path in file_list: with pdfplumber.open(file_path) as pdf: for page in pdf.pages: text = page.extract_table() for i in text: item.append(i) # 2. 创建Excel表对象 workbook = xlwt.Workbook(encoding='utf8') # 3. 新建sheet表 worksheet = workbook.add_sheet('Sheet1') # 4. 自定义列名 col1 = item[0] # print(col1)# ['店铺名', '价格', '销量', '地址'] # 5. 将列属性元组col写进sheet表单中第一行 for i in range(0, len(col1)): worksheet.write(0, i, col1[i]) # 6. 将数据写进sheet表单中 for i in range(0, len(item[1:])): data = item[1:][i] for j in range(0, len(col1)): worksheet.write(i + 1, j, data[j]) # 7. 保存文件分两种格式 workbook.save('test2.xls')运行结果:
以上便是小y的学习笔记,小y希望和大家共同进步!
欢迎点赞+收藏+关注!