Slice 是 dflow 的核心功能之一,但仅限于 PythonOP
如果将一些小的 PythonOP 填到一个 steps 模板里,这些小 OP 就可以共同实现一些复杂的功能,但可惜的是,steps 不支持 slice 这一功能
为了钻这个牛角尖,我决定看一下 PythonOP 的源码。看了一段时间,没有头绪,于是决定写下自己读代码的过程,梳理思路。所以这篇文章可能会比较乱,大家看一乐就好。
PythonOP, OP and Steps
首先复习一下dflow里的一些概念,OP 是最基本的单元,PythonOP是OP的包装,一堆PythonOP线性排列或者循环组合可以组成Steps
下面我们来看一个简单的PythonOP
class Duplicate(OP):
def __init__(self):
pass
@classmethod
def get_input_sign(cls):
return OPIOSign({
'msg': str,
'num': int,
'foo': Artifact(Path),
'idir': Artifact(Path),
})
@classmethod
def get_output_sign(cls):
return OPIOSign({
'msg': str,
'bar': Artifact(Path),
'odir': Artifact(Path),
})
@OP.exec_sign_check
def execute(
self,
op_in: OPIO,
) -> OPIO:
op_out = OPIO({
"msg": op_in["msg"] * op_in["num"],
"bar": Path("output.txt"),
"odir": Path("todir"),
})
content = open(op_in['foo'], "r").read()
open("output.txt", "w").write(content * op_in["num"])
Path(op_out['odir']).mkdir()
for ii in ['f1', 'f2']:
(op_out['odir']/ii).write_text(op_in['num']
* (op_in['idir']/ii).read_text())
return op_out
这是一个简单的OP模板,他直接继承了OP,实现了类似下面的Python函数:
def aaa(in_msg: str, in_artifact: Artifact):
op_in = {"in_msg": in_msg, "in_artifact": in_artifact}
op_out = execute(op_in)
out_msg, out_artifact = op_out["out_msg"], op_out["out_artifact"]
return out_msg, out_artifact
注意到,我们这里尚未涉及PythonOP,但已经默认,这是一个PythonOP了,准确的说,这时候的duplicate还只是一个继承了OP的一个类,还不能直接使用,我们需要套一个壳才能使用:
step = Step(
name="step",
template=PythonOPTemplate(Duplicate, image="python:3.8"),
parameters={"msg": "Hello", "num": 3},
artifacts={"foo": artifact0, "idir": artifact1},
)
因此duplicate严格来说,还只是一个半成品,它继承了OP,但又不是OP,需要套一个壳转化一下才能再次变成OP
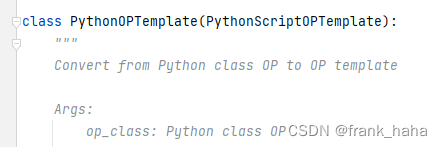
我们点进PythonOPTemplate的定义,里面写着:
花开两朵,各表一枝。
前面小结一下:
我们平时写PythonOP都是按照固定的格式
def aaa(in_msg: str, in_artifact: Artifact):
op_in = {"in_msg": in_msg, "in_artifact": in_artifact}
op_out = execute(op_in)
out_msg, out_artifact = op_out["out_msg"], op_out["out_artifact"]
return out_msg, out_artifact
写一个半成品,套上PythonOP后转化成了真正的OP
那有没有方法绕过八股文格式,直接写“真正的OP”呢?
注意到,big steps那一节有过类似的应用,只不过当时的重点在于,对小OP串联组成大OP。但如果细心观察可以发现,这个大OP的输入输出和平时的PythonOP不一样。
因为这是一个原生的OP
具体来说,他做了如下的变化:
- 输入输出全局声明:
steps = Steps(name="hello-steps")
steps.inputs.parameters["foo"] = InputParameter()
steps.outputs.parameters["foo"] = OutputParameter()
- 整个steps的输入分给各个小OP
step1 = Step(
name="step1",
template=PythonOPTemplate(Duplicate, image="python:3.8"),
parameters={"foo": steps.inputs.parameters["foo"]},
key="step1"
)
steps.add(step1)
- 全局的输出源自小OP的输出
step2 = Step(
name="step2",
template=PythonOPTemplate(Duplicate, image="python:3.8"),
parameters={"foo": step1.outputs.parameters["foo"]},
key="step2"
)
steps.add(step2)
steps.outputs.parameters["foo"].value_from_parameter = \
step2.outputs.parameters["foo"]
- 使用过程中无需PythonOP转换
big_step = Step(name="big-step", template=steps,
parameters={"foo": Hello("hello")})
我们可以得出如下结论:
Steps直接集成了OP,虽然看起来是一群小PythonOP的组合,但不是PythonOP
他的逻辑更直接:拿到输入直接,do something,然后输出
def execute(in_msg: str, in_artifact: Artifact):
# do something
return out_msg, out_artifact
对比一下之前的PythonOP
def aaa(in_msg: str, in_artifact: Artifact):
op_in = {"in_msg": in_msg, "in_artifact": in_artifact}
op_out = execute(op_in)
out_msg, out_artifact = op_out["out_msg"], op_out["out_artifact"]
return out_msg, out_artifact
由此可见,PythonOP虽然更复杂,但写起来按照八股文,还是很轻松的,只需要关注execute逻辑,做好变量检查即可。相比之下,steps需要一个个声明输入输出变量类型(很长),使用的时候也是很长一串。
小结一下:
PythonOP和steps都是OP,只不过实现的方式不同,最终在容器里,二者都是要转化成普通OP的格式的。
具体来说,PythonOP把输入输出变量转换成普通OP的输入输出变量,放入执行逻辑里就可以了。而steps则是等到一个个的PythonOP转换成普通的OP,再给套上整个流的输入输出即可,最终也是变成了OP。
所以,虽然steps是PythonOP的组合,但steps并不是一种PythonOP,而是一种将各OP串起来的大OP
PythonOP 是怎么转化成 OP 的
此时,我们大概已经知道答案了。PythonOP把半成品的输入输出解包变成了OP。
干的事情是这样的,但具体是如何实现的呢?
我写了简单的程序:
import time
from pathlib import Path
from dflow import Step, Workflow, download_artifact, upload_artifact
from dflow.python import (OP, OPIO, Artifact, OPIOSign, PythonOPTemplate,
upload_packages)
class Duplicate(OP):
def __init__(self):
pass
@classmethod
def get_input_sign(cls):
return OPIOSign({
'msg': str,
'num': int,
'foo': Artifact(Path),
'idir': Artifact(Path),
})
@classmethod
def get_output_sign(cls):
return OPIOSign({
'msg': str,
'bar': Artifact(Path),
'odir': Artifact(Path),
})
@OP.exec_sign_check
def execute(
self,
op_in: OPIO,
) -> OPIO:
op_out = OPIO({
"msg": op_in["msg"] * op_in["num"],
"bar": Path("output.txt"),
"odir": Path("todir"),
})
content = open(op_in['foo'], "r").read()
open("output.txt", "w").write(content * op_in["num"])
Path(op_out['odir']).mkdir()
for ii in ['f1', 'f2']:
(op_out['odir']/ii).write_text(op_in['num']
* (op_in['idir']/ii).read_text())
return op_out
a_OP = PythonOPTemplate(op_class=Duplicate, image='python:3.8')
下面我用最笨的方法,打断点进去看看:
进来以后第一块是确认了一下op变量类型,然后把输入输出解包
op = None
if isinstance(op_class, OP):
op = op_class
op_class = op.__class__
class_name = op_class.__name__
input_sign = op_class.get_input_sign()
output_sign = op_class.get_output_sign()
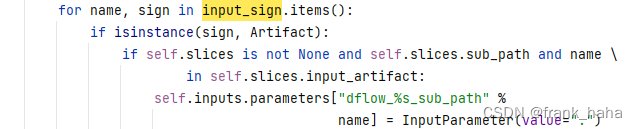
后面涉及 input_sign 就是直接当 dict 使用了
解包完,进行了一些附属功能的检查
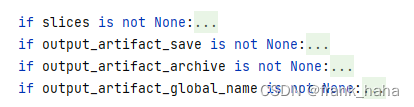
这里我们暂时用不到
后面就是upload一些包,对传进来的变量进行redistribution,看起来很长,主要是因为要检查的类型比较多,架构还是很清晰的
最后通过 render_script 把收进来的变量写成普通的OP脚本
PythonOP是如何实现slice的
上一节的核心结论就是,PythonOP 通过繁琐的变量检查对输入输出变量进行了解包,并将其转化为了普通OP
也就是:
def aaa(in_msg: str, in_artifact: Artifact):
op_in = {"in_msg": in_msg, "in_artifact": in_artifact}
op_out = execute(op_in)
out_msg, out_artifact = op_out["out_msg"], op_out["out_artifact"]
return out_msg, out_artifact
解包,变成了
def execute(in_msg: str, in_artifact: Artifact):
# do something
return out_msg, out_artifact
slice 就是在此基础上添加的一些辅助功能。
dflow的文档里介绍slice时提到,他是通过调用step的with param实现的
step的with param最基础的用法如下:
step = Step(
...
parameters={"msg": "{{item}}"},
with_param=steps.inputs.parameters["msg_list"]
)
step运行时,会从 ["msg_list"] 抽出 msg 赋给 "{{item}}" ,成为 steps 这个 OP 中一个切片过了的变量。
我们需要谨记,PythonOP也是一个普通的OP,因此他实现并行,底层原理也只是调用了这一个可切片的点
那一个可切片的变量,如何影响一群变量的呢?
我们以 input_parameter 为例,其余均差不多
下面是 input_parameter 在 slice 里的部分
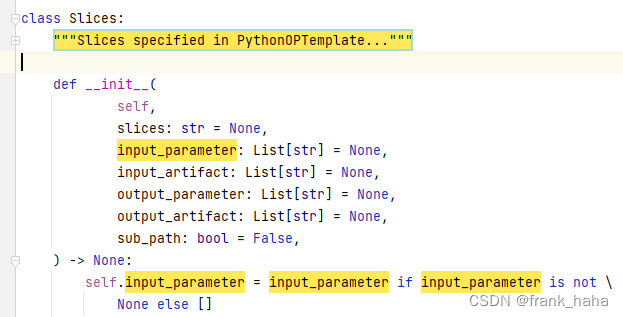
回顾一下 slice 的用法:
hello = Step("hello",
PythonOPTemplate(Hello, image="python:3.8",
slices=Slices("{{item}}",
input_parameter=["filename"],
output_artifact=["foo"]
)
),
parameters={"filename": ["f1.txt", "f2.txt"]},
with_param=argo_range(2))
我们对照 slices 部分
slices=Slices("{{item}}",
input_parameter=["filename"],
output_artifact=["foo"]
)
第一项 "{{item}}" 赋值给了 slices
input_parameter=["filename"] ,进一步赋值给了 self.input_parameter
self.input_parameter 在 template 里就变成了 slices.input_parameter
注意到,初始化的 slices.input_parameter = ["filename"]
我们来看下面做了什么:
if slices.input_parameter:
input_parameter_slices = {
name: slices.slices for name in slices.input_parameter}
input_parameter_slices 变成了一个 dict, key 是 列表里的每一个元素,value 是 slices.slices 也就是 "{{item}}"
这一步之后,有了下面的一个变量:
input_parameter_slices = {"filename": "{{item}}"}
下面这个变量被传入了 render_script 函数
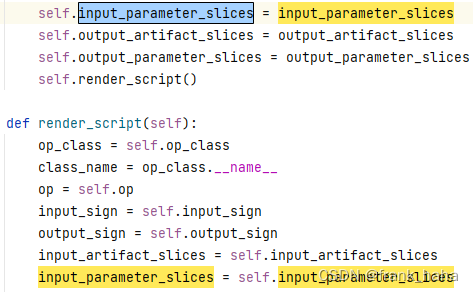
再往后就是这句话了:
for name, sign in input_sign.items():
slices = self.get_slices(input_parameter_slices, name)
检查传入的变量,然后以查表的方式得到 slices
def get_slices(self, slices_dict, name):
slices = None
if slices_dict is not None:
slices = self.render_slices(slices_dict.get(name, None))
return slices
get_slices 接收的是一个 dict 和一个 name
我们注意到,dict 就是 {"filename": "{{item}}"} ,它可以有很多项,这里只涉及了一项
查表就是
for name, sign in input_sign.items():
要遍历每一个输入的 name 嘛
如果这个 name 被 slice 了,查表结果就是 "{{item}}" ,如果没有,就是 None
对于本例,查找到的结果是 "{{item}}"
下面是如何操作这个 "{{item}}" 呢?
def render_slices(self, slices=None):
if slices is None:
return None
i = slices.find("{{item")
while i >= 0:
j = slices.find("}}", i+2)
var = slices[i:j+2]
if var not in self.dflow_vars:
var_name = "dflow_var_%s" % len(self.dflow_vars)
self.inputs.parameters[var_name] = InputParameter(value=var)
self.dflow_vars[var] = var_name
else:
var_name = self.dflow_vars[var]
slices = slices.replace(var, "{{inputs.parameters.%s}}" % var_name)
i = slices.find("{{item")
return slices
i = 0,后进入 while 循环,j=6
var = "{{item}}"
slices = slices.replace(var, "{{inputs.parameters.%s}}" % var_name)
随后把 slices 中的 "{{item}}" 替换成了 "{{inputs.parameters.%s}}" % var_name
while 循环的意思就是支持多处替换
dflow_vars 是什么呢?
if var not in self.dflow_vars:
var_name = "dflow_var_%s" % len(self.dflow_vars)
self.inputs.parameters[var_name] = InputParameter(value=var)
self.dflow_vars[var] = var_name
else:
var_name = self.dflow_vars[var]
往上看,发现他初始化是一个空的 dict
var_name = "dflow_var_%s" % len(self.dflow_vars)
“var_name = dflow_var_0”
slices = slices.replace(var, "{{inputs.parameters.%s}}" % var_name)
返回值就变成了 "{{inputs.parameters.dflow_var_0}}"
我们回到 374 行
slices = self.get_slices(input_parameter_slices, name)
查表结果是:
slices = "{{inputs.parameters.dflow_var_0}}"
第二次查表,由于上一次查表后已经给 self.dflow_vars 填充了一个 dict ,所以第二次查表所得值为:
slices = "{{inputs.parameters.dflow_var_1}}"
这个str是怎么用的呢?
script += "input['%s'] = handle_input_parameter('%s', "\
"r'''{{inputs.parameters.%s}}''', input_sign['%s'], "\
"%s, '/tmp')\n" % (name, name, name, name, slices)
这段话用到了 handle_input_parameter,是这样定义的:
def handle_input_parameter(name, value, sign, slices=None, data_root="/tmp"):
if "dflow_list_item" in value:
dflow_list = []
for item in jsonpickle.loads(value):
dflow_list += jsonpickle.loads(item)
obj = convert_dflow_list(dflow_list)
elif isinstance(sign, BigParameter):
with open(data_root + "/inputs/parameters/" + name, "r") as f:
content = jsonpickle.loads(f.read())
if sign.type == str:
obj = content["value"]
else:
obj = jsonpickle.loads(content["value"])
else:
if isinstance(sign, Parameter):
sign = sign.type
if sign == str and slices is None:
obj = value
else:
obj = jsonpickle.loads(value)
if slices is not None:
assert isinstance(
obj, list), "Only parameters of type list can be sliced, while %s"\
" is not list" % obj
if isinstance(slices, list):
obj = [obj[i] for i in slices]
else:
obj = obj[slices]
return obj
这段话就是把变量按照切片切好再返回。
一堆细节,就先这样吧,有空再补