python之模块
一、python 模块介绍
1、结构认识:
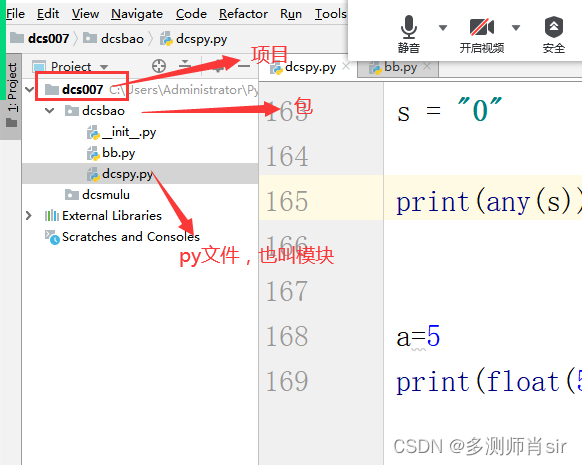
2、模块的定义 Python 模块(Module),是一个Python文件,以.py 结尾,包含了 Python 对象定义和Python语句。
3、 模块能让我们有逻辑地组织Python代码段。 把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
4、 模块能定义函数,类和变量,模块里也能包含可执行的代码
5、创建py文件,也是创建模块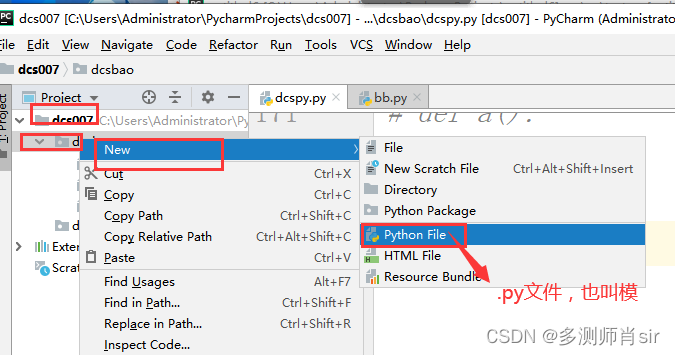
二、模块的导入
(1)注意点:一个模块主要导入一次,不管你执行多少次import ,一次就可以;
(2)模块不被调用时置灰状态
1、import 导入方式
格式:import 模块名
案例:
import time time是模块名
print(1)
time.sleep(5) time模块下有sleep函数 休眠 5表示秒数
print(2)
2、from 包名.模块名 import * (*表示所有)
bb文件:(也叫bb模块)
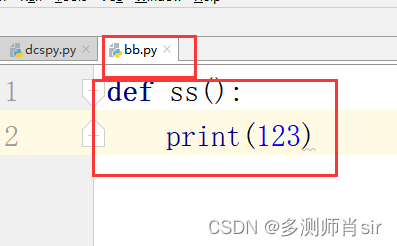
dcspy模块:
from dcsbao.bb import *
ss()

3、
from 包名.模块名 import 函数名
bb文件:
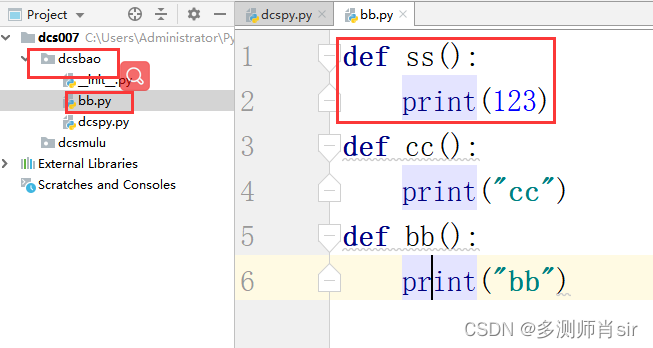
dcspy.py文件:

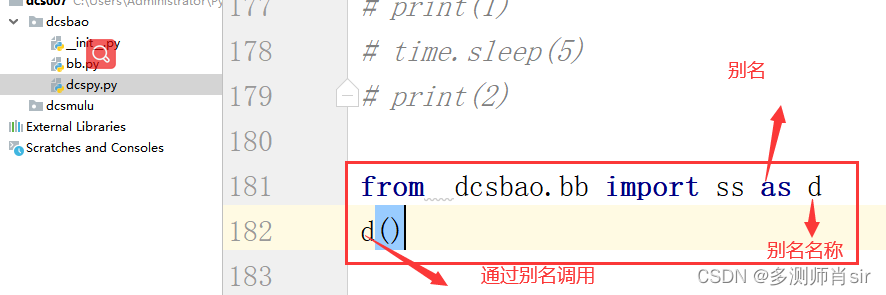
4、通过取别名来调用函数
格式 :from 包名.模块名 import 函数名 as 别名名称
案例:bb文件:
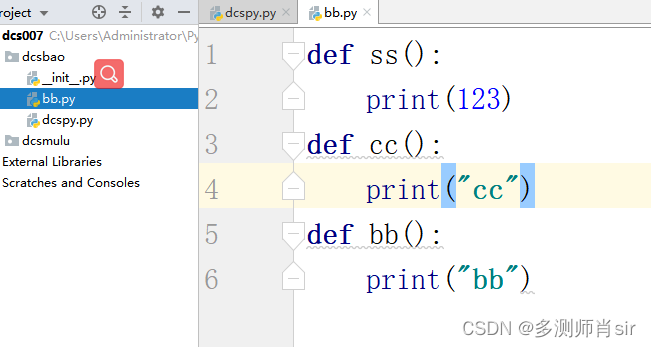
dcspy.py 文件:
==================================================================
模块详解:
一、python中time模块
time模块中常见的方法:
time() #1970到现在的经过的秒数 (1970年开始浮点秒数)
案例1:
print(time.time()) ##1970到现在的经过的秒数
ctime() #固定格式的当前时间
案例2:
print(time.ctime()) #固定格式的当前时间
sleep(3) #休眠 单位是秒
#time.sleep(5)
案例3:
asctime() #转换为asc码显示当前时间
print(time.asctime()) #转换为asc码显示当前时间
案例4:
strftime() #时间格式化
print(time.strftime(“%y-%m-%d %H:%M:%S”))##时间格式化
案例:不写time模块调用
from time import *
print(time())
print(ctime())
sleep(3)
print(asctime())
print(strftime(“%y-%m-%d %H:%M:%S”))
二、
python中random模块 生成随机浮点数、整数、字符串,甚至帮助你随机选择列表序列中的一个元素,打乱 一组数据等
random模块中常见的方法:
(1) random.random() #该方法是生成0-1之间的浮点数,但是能取到0,但是取不到1
案例:
print(random.random()) #该方法是生成0-1之间的浮点数,但是能取到0,但是取不到1
(2) random.randint(x,y) #该方法生成指定范围内整数,包括开始和结束值
案例:
print(random.randint(1,3)) #该方法生成指定范围内整数,包括开始和结束值
(3)random.randrange(x,y,step) #生成指定范围内的奇数,不包括结束值
案例:
#print(random.randrange(1,101))#1-100随机取一个数
(4) random.randrange(x,y,step) #生成指定范围内的偶数,不包括结束值
案例:
print(random.randrange(0,101,2))#1-100随机取一个偶数
(5) random.randrange(x,y,step) #生成指定范围内的奇数,不包括结束值
案例:
print(random.randrange(1,101,2))#1-100随机取一个奇数
(6) random.sample(seq,n) #从序列seq中选择n个随机且独立的元素
案例:
list1=[1,2,5,9,3,8]
print(random.sample(list1,2)) ##从序列中选择n个随机且独立的
(7)random.choice(test) #生成随机字符
案例:
list1=[1,2,5,9,3,8]
print(random.choice(list1)) #生成随机一个字符
(8) random.shuffle(list) #洗牌(随机数列)
案例:
list1=[1,2,5,9,3,8]
random.shuffle(list1)
print(list1)
==================================================================
import string
print(string.digits) #0123456789
print(string.hexdigits) #0123456789abcdefABCDEF
print(string.ascii_uppercase)#ABCDEFGHIJKLMNOPQRSTUVWXYZ
print(string.ascii_lowercase)#abcdefghijklmnopqrstuvwxyz
==================================================================
作业;
1、随机生成手机号,手机的开头1,
方法1:
from random import *
phoneNum=“1”
for i in range(10):
j = str(randint(0, 9))
phoneNum += j
print(phoneNum)
方法2:
sj=[“1”,]
for i in range(10):
s=random.choice(string.digits)
sj.append(s)
print(“”.join(sj))
方法3:备注下,有相同的号码数字,不会显示,只显示规定0-9
import random
import string
sj=[“1”,]
a=random.sample(string.digits,10)
print(“”.join(sj+a))
2、随机生成验证码(大写26个字母,小写26个字母,数字0-9)
方法1:
import string
s=string.digits+string.ascii_lowercase+string.ascii_uppercase
codeNm=" "
for i in range(6):
j=choice(s)
codeNm+=j
print(codeNm)
方法2:
from random import *
import string
s=string.digits+string.ascii_lowercase+string.ascii_uppercase
a=sample(s,6)
print(“”.join(a))
==============================================================
加密模块
import hashlib (哈希)
一、加密算法
md5 、rsa、AES.DES.BASE
(1)basa64 加密
案例
import base64
#加密
a=base64.b64encode(b"123456")
print(a) #b’MTIzNDU2’
#解密
b=base64.b64decode(b"MTIzNDU2")
print(b) #b’123456’
(2)http://encode.chahuo.com/ 在线加解密

(3)md5 加密
a、定义:md5是一种算法,可以将一个字符串或文件,通过MD5后可以生成一个固定为128bit 的串,这个串,基本上唯一;
b、python3将md5 归纳到hash模块,译作“散列”,直译“哈希”
c、md5可以将任意长度的输入,通过hash孙发,变成固定长度的输出,该输出就是散列值,也称摘要值。
d、md5是最常见的摘要算法,速度快,生成结果是固定16字节,通常用32位的16进制字符显示。
e、hash 模块中包含md5、sha526、sha256 等
f、 hash.diget() 返回摘要,作为一个二进制的数据字符串
(4)MD5案例
import hashlib
m=hashlib.md5() #创建一个MD5的对象
m.update(b"123456")
print(m.hexdigest()) #e10adc3949ba59abbe56e057f20f883e

(5)sha256
import hashlib
m=hashlib.sha256() #创建一个MD5的对象
m.update(b"123456")
print(m.hexdigest())#8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
(6)sha512
import hashlib
m=hashlib.sha512() #创建一个MD5的对象
m.update(b"123456")
print(m.hexdigest()) #ba3253876aed6bc22d4a6ff53d8406c6ad864195ed144ab5c87621b6c233b548baeae6956df346ec8c17f5ea10f35ee3cbc514797ed7ddd3145464e2a0bab413
==============================
面试题:
如果在工作中有很多数据,如果数据改动,或者传递被修改,比如(100亿条),你如何检测?
a、通加密方式对数据加密处理,生成加密字符;
b、传输后在进行加密,对比加密字符是否一致
c、比对字符一致,说明数据没有修改,如果字符不一致,说明 被修改
作业:
将随机:6位验证码,进行加密
方法1:
from random import *
import string
import hashlib
s=string.digits+string.ascii_lowercase+string.ascii_uppercase
a=sample(s,6)
c=“”.join(a)
print?
m=hashlib.md5()
m.update(c.encode(“utf-8”))
print(m.hexdigest())
===========================================
os模块
os模块提供了多数操作系统的功能接口函数。
当os模块被导入后,它会自适 应于不同的操作系统平台,根据不同的平台进行相应的操作,在python编 程时,经常和文件、目录打交道,所以离不了os模块。
os模块中常见的方法:
(1) os.getcwd()获取当前执行命令所在目录
案例:
import os
print(os.getcwd()) #获取当前执行命令所在目结果:C:\Users\Administrator\PycharmProjects\dcs007\dcsbao
(2) os.path.isfile()判断是否文件
案例
#情况1判断是文件的返回ture
url=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsbao\bb.py"
print(os.path.isfile(url)) #True
#情况2判断不是文件的返回FALSH
url2=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsmulu"
print(os.path.isfile(url2)) #False
#情况3判断不是文件的不存在,则返回false
url3=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsmulu222"
print(os.path.isfile(url3)) #False
(3) os.path.isdir() #判断是否是目录
案例:
#情况1判断不是目录的返回FALSE
url=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsbao\bb.py"
print(os.path.isdir(url)) #False
#情况2判断是目录的返回Ftrue
url2=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsmulu"
print(os.path.isdir(url2)) #True
(4) os.path.exists() #判断文件或目录是否存在
案例:
#情况1判断文件存在则返回true
url=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsbao\bb.py"
print(os.path.exists(url))#True
#情况2判断不存文件在则返回falsh
url2=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsbao\aa.py"
print(os.path.exists(url2)) #False
(5) os.listdir(dirname) #列出指定目录下的目录或文件
案例:
url=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsbao"
print(os.listdir(url)) #[‘aa.py’, ‘bb.py’, ‘dcspy.py’, ‘init.py’, ‘pycache’]
(6) os.path.split(name)#分割文件名与目录
案例:
url=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsbao\bb.py"
print(os.path.split(url))
结果:(‘C:\Users\Administrator\PycharmProjects\dcs007\dcsbao’, ‘bb.py’)
(7) os.path.join(path,name) #连接目录与文件名或目录
案例:
url=r"C:\Users\Administrator\PycharmProjects\dcs007\dcsbao"
print(os.path.join(url,“bb.py”))
(8) os.mkdir(dir) #创建一个目录
案例:情况不存在文件,在添加
url=r"D:\ls\cb\aa"
os.mkdir(url)
案例2:判断是否存在文件,不存在则添加,存在则不添加
url=r"D:\ls\cb\bb"
if not os.path.exists(url):
os.mkdir(url)
(9)os.rename(old,new) #更改目录名称
案例:
old_url=r"D:\ls\cb\bb"
new_url=“D:\ls\cb\cc”
os.rename(old_url,new_url)
(10)os.path.abspath(__file__) #获取当前执行命令所在绝对路径
案例:
print(os.path.abspath(__file__))结果: C:\Users\Administrator\PycharmProjects\dcs007\dcsbao\dcspy.py
===============================================
os中固定语句格式
#获取项目路径
print(os.path.abspath(os.path.dirname(os.getcwd())))
#获取当前文件绝对路径,通过split对目录和文件名进行分割
print(os.path.split(os.path.realpath(file)))
#结果(‘C:\Users\Administrator\PycharmProjects\dcs007\dcsbao’, ‘dcspy.py’)
#或取当前文件绝对路径,使用split分割后通过索引0获取目录
print(os.path.split(os.path.realpath(file))[0])
#或取当前文件绝对路径,使用split分割后通过索引1获取文件名
print(os.path.split(os.path.realpath(file))[1])
#获取项目路径
print(os.path.dirname(os.path.dirname(file)))
#结果:C:/Users/Administrator/PycharmProjects/dcs007
===============================================
python中re正则模块
(1)正则匹配:使用re模块实现
(2)实现一个编译查找,一般在日志处理或者文件处理时用的比较多 正则表达式主要用于模式匹配和替换工作。
(3)re表达式作用:
a.快速查找和分析字符比对也叫模式匹配:比如:查看、比对、匹配、替换、插入,删除等功能
b、实现一个编译查看,一般在处理文件时用的多
(4)re模块 使python语言有全部的表达式功能
(5)预定义字符集匹配:
\d:数字0-9
\D:非数字
\s:空白字符
\n:换行符
\r:回车符
案例:
(1) \d:数字0-9
案例:
import re
s=“12309abce”
c=re.findall(“\d”,s)
print?
(2) \D:非数字
案例:
import re
import re
s=“12309abce”
c=re.findall(“\D”,s)
print?
(3) \s:空白字符
案例:
import re
s=“123 09 abce”
c=re.findall(“\s”,s)
print? #[’ ‘, ’ ‘]
\n:换行符
案例:
import re
s=“123 \n09 \nabce”
c=re.findall(“\n”,s)
print? #[’\n’, ‘\n’]
案例2读取本地文件:
import re
f=r"D:\ls\cb\aa.txt"
#s=“12\n3”
a=open(f,“r”)
b=a.read()
c=re.findall(“\n”,b)
print?
\r:回车符 表示将光标回退到开始位置
案例:
import time
s=“abcd\rcd”
for i in s:
time.sleep(1)
print(i,end=“”)
\t "制表符:(制表符默认为4位)
print(“dcs\txian”)
(4)re模块数量词匹配:
符号
^:表示的匹配字符以什么开头 符号
KaTeX parse error: Expected 'EOF', got '#' at position 241: …dall("^ab",s)) #?['ab'] 如果开头不存在就…:表示的匹配字符以什么结尾 符号
案例:
s=“abcdefabb123aab4bbbb5abc”
print(re.findall(“c$”,s)) #[‘c’]
如果结尾不存在就返回[]空列表
(3):匹配前面的字符0次或n次 eg:ab* 能匹配a 匹配ab 匹配abb 符号
案例:
s=“abcdefbcccccccaabb1c23aab4abbbbccc5abbbbbbbc”
print(re.findall(“c*”,s))
结果:[‘’, ‘’, ‘cc’, ‘’, ‘’, ‘’, ‘’, ‘cccccc’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘c’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘ccc’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘c’, ‘’]
+:匹配+前面的字符1次或n次 符号
案例:
s=“abccdefbccccccaabb1c23aab4abbbbccc5abbbbbbbc”
print(re.findall(“ab+”,s))
[‘ab’, ‘abb’, ‘ab’, ‘abbbb’, ‘abbbbbbb’]
?:匹配?前面的字符0次或1次 符号
案例:
s=“abccdefbccccccaabb1c23aab4abbbbccc5abbbbbbbc”
print(re.findall(“ab?”,s))
结果:[‘ab’, ‘a’, ‘ab’, ‘a’, ‘ab’, ‘ab’, ‘ab’]
{m}:匹配前一个字符m次 符号
案例:
s=“abccdefbccccccaabb1c23aab4abbbbccc5abbbbbbbc”
print(re.findall(“b{2}”,s))
结果:
[‘bb’, ‘bb’, ‘bb’, ‘bb’, ‘bb’, ‘bb’]
{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是 正整数
案例:
s=“abccdefbccccccaabb1c23aab4abbbbccc5abbbbbbbc”
print(re.findall(“b{1,4}”,s))
结果:[‘b’, ‘b’, ‘bb’, ‘b’, ‘bbbb’, ‘bbbb’, ‘bbb’]
(6)re模块相关函数
1、match 从第一个字符开始匹配,如果第一个字符不是要匹配的类型、则匹配失败并none ,如果是从第一个字符开始匹配显示索引位
案例:
s=“ni,hao”
c=re.match(“ni”,s)
print? #None
2、search 从第一个字符开始查找、一找到就返回第一个字符串存在的位置,找到就不往下找,找不到则报错
案例1:查找存在数据,显示字符存在索引位
import re
s=“bcdhkalp12a31”
c=re.search(“a”,s)
print(c.span()) #(5, 6)
案例2:查找不存在数据
import re
s=“abcdhkalp12a31”
c=re.search(“z”,s)
print? #None
3、findall 从第一个字符开始查找,找到全部相关匹配为止,找不到返回一个列表[]
案例1:
情况1查找存在数据
import re
s=“abcdhkalp12a31”
c=re.findall(“a”,s)
print? #[‘a’, ‘a’, ‘a’]
案例2:情况2查找不存在数据
import re
s=“abcdhkalp12a31”
c=re.findall(“z”,s)
print? #[]
4、compile 编译正则表达式模式,返回一个对象,可以把常用的正则表达式编译成正则表达式对象,方便后续调用和提高效率
格式:re.compile( pattern[flags])
案例:
import re
s=“1ab2ni abha1bcoc”
#编译作用
c=re.compile(“\s”)#要匹配的内容,对应match里面的string
#使用
d=c.match(s)
print(d)
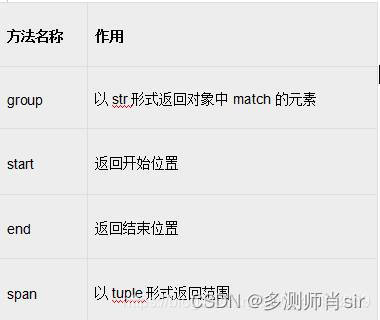
match和search区别
(1)match ()函数只检查re是不是string 的开始位置匹配
(2)search ()会扫描整个string 查找匹配
(3)match 只有在0位置匹配成功的化才有返回值,如果不是开始位置匹配成功的话就是none
==============================
sub 替换
s=“ab12”
print(re.sub(“\D”,“多测师”,s))
结果:
多测师多测师12
==============================
xlrd模块
(1)定义:xlrd是用于读取excel表格数据(不支持写操作,写操作xlwt模块实现)
(2)支持xlsx和xls 格式的excel 表格(不支持csv文件,csv文件用python自带csv模块操作)
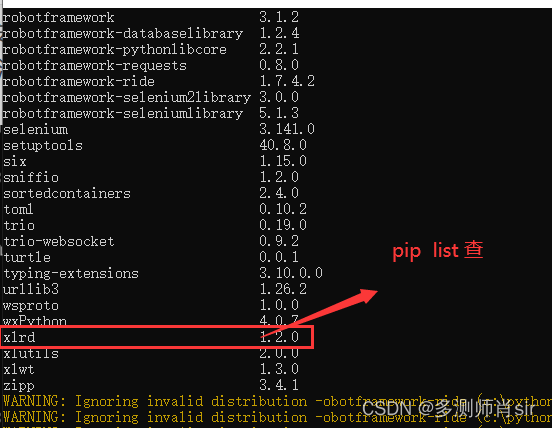
(3)模块安装:dos中 pip install xlrd==1.2.0
一、安装方法1:
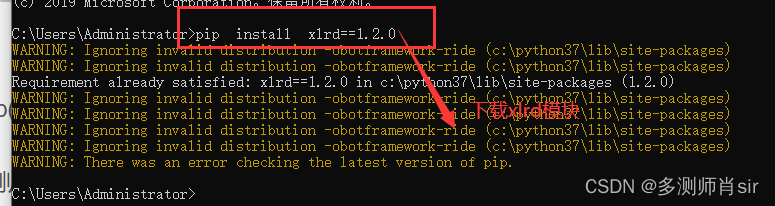
查看是否安装成功:pip list
方法2:
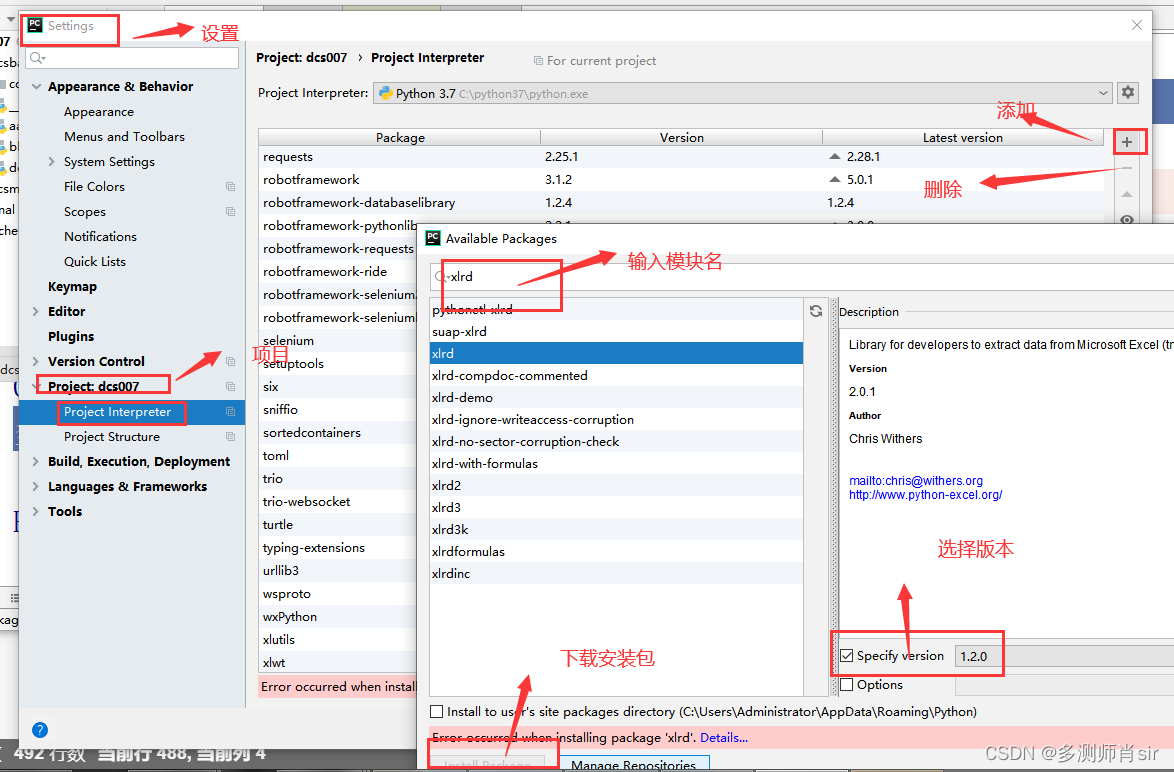
(4)导入模块:import xlrd
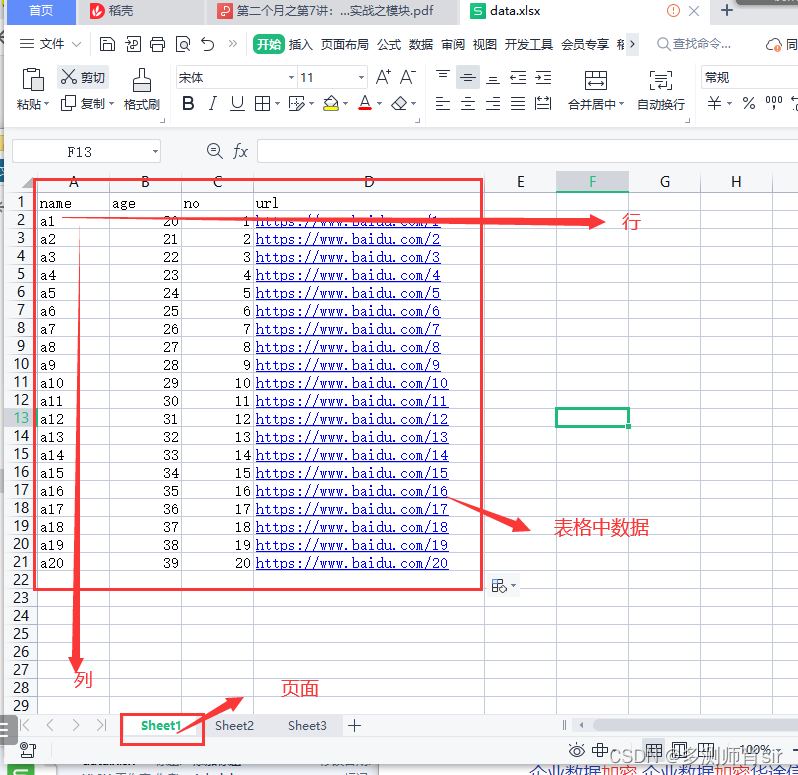
(5)新建一个data.xlsx 文件
(6)xlrd运用
import xlrd
sj=xlrd.open_workbook(“D:\ls\cb\data.xlsx”)
ym=sj.sheets()[0]#获取第一页
print(ym.name)#或取sheet名
print(ym.nrows)#总行数
print(ym.ncols)#总列数
print(ym.row_values(0)) #获取第一行所有的内容 0是索引,第一行的索引是0#[‘name’, ‘age’, ‘no’, ‘url’]
print(ym.row_values(0,1,3)) #0表示行数, 1表示开始列,索引从0开始,3表示结束列,不包含结束列
print(ym.col_values(0)) #获取第一列所有的内容,0表示第一列,0表示索引
print(ym.col_values(0,9,15))#0表示第一列,9表示开始行9表示第10行,15结束行
print(ym.row_values(11,1,2)) #[30.0]
print(ym.col_values(1,11,12)) #[30.0]
print(sj.sheets())#显示页面所有的对象
print(sj.sheet_names()) #返回表格中的所有页面名称
=========================
JSO模块
一、dunps 将python中的数据类型转换成json格式字符串
import json
zd={“name”:“wm”,“age”:18,“isonly”:True,“sex”:“男”}
print(type(zd)) #<class ‘dict’>
print(zd) #{‘name’: ‘wm’, ‘age’: 18}
jsongs=json.dumps(zd,ensure_ascii=False)
print(type(jsongs)) #<class ‘str’>
print(jsongs)#{“name”: “wm”, “age”: 18}
备注:
(1)python 的字典是单引号,json格式字符的双引号
(2)字典中有大写,json中字符都是小写
二、dump 将python中的数据类型转换成json格式文件内
import json
zd={“name”:“wm”,“age”:18,“isonly”:True,“sex”:“男”}
print(type(zd)) #<class ‘dict’>
json.dump(zd,open(“data.json”,“a”,encoding=“utf-8”),ensure_ascii=False)
三、loads 将json格式字符转换成python类型
案例1:将json格式转换成字典
import json
json1=‘{“name”:“wm”, “age”: 18, “isonly”: true, “sex”: “男”}’
print(json1)#{“name”:“wm”, “age”: 18, “isonly”: true, “sex”: “男”}
print(type(json1)) #<class ‘str’>
zddx=json.loads(json1)
print(zddx)##{‘name’: ‘wm’, ‘age’: 18, ‘isonly’: True, ‘sex’: ‘男’}
print(type(zddx)) #<class ‘dict’>
案例2:将json格式转换成元组
import json
json1=‘[{“name”:“wm”, “age”: 18, “isonly”: true, “sex”: “男”}]’
print(json1)#{“name”:“wm”, “age”: 18, “isonly”: true, “sex”: “男”}
print(type(json1))#<class ‘str’>
listdx=json.loads(json1)
print(listdx)
print(type(listdx))
四、load
load 从json格式文件中读取数据并转换为python的类型
1、文件中写好json格式
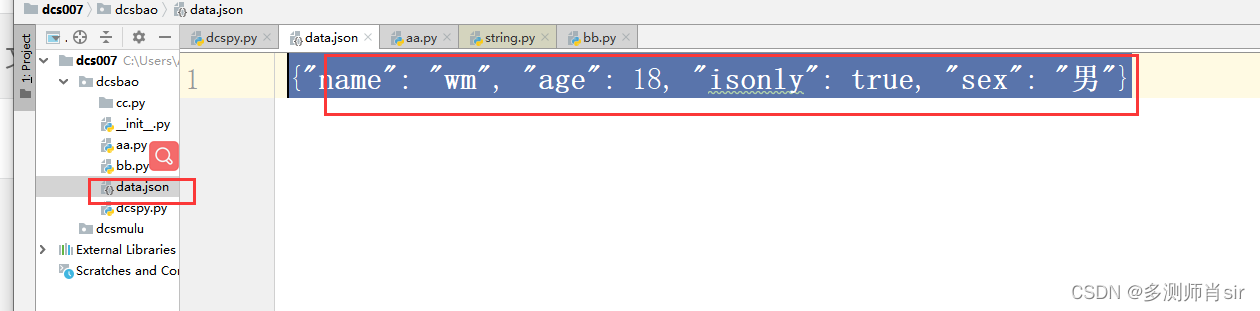
2、将文件中的json转换成字典格式
import json
zddx=json.load(open(“data.json”,“r”,encoding=“utf-8”))
print(zddx) #{‘name’: ‘wm’, ‘age’: 18, ‘isonly’: True, ‘sex’: ‘男’}
print(type(zddx)) #<class ‘dict’>
3、将文件中json转换成元组格式:
import json
json1=‘{“name”:“wm”, “age”: 18, “isonly”: true, “sex”: “男”}’
print(json1)#{“name”:“wm”, “age”: 18, “isonly”: true, “sex”: “男”}
print(type(json1)) #<class ‘str’>
zddx=json.loads(json1)
print(zddx)##{‘name’: ‘wm’, ‘age’: 18, ‘isonly’: True, ‘sex’: ‘男’}
print(tuple(zddx))
print(tuple(zddx.items()))
五、实际案例中的json
(1)查看json格式
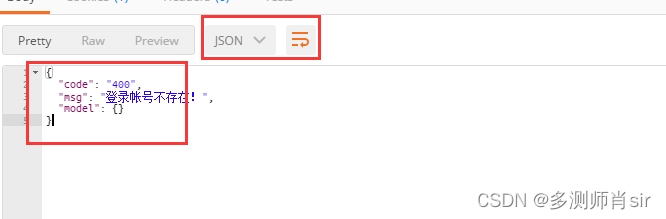
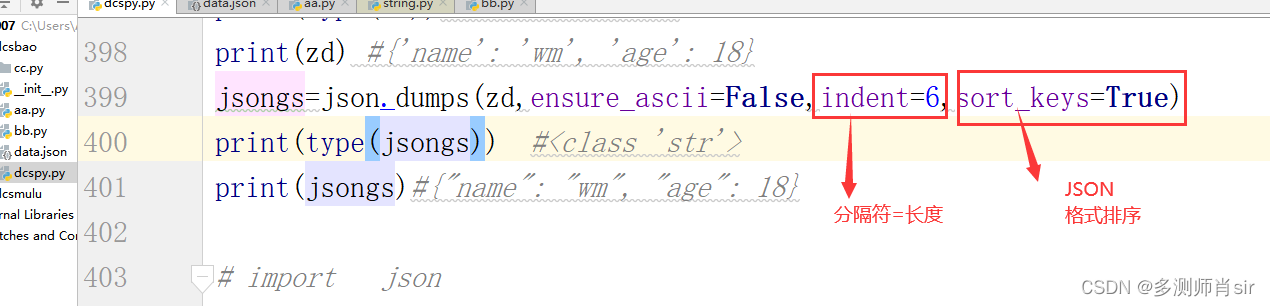
(2)分隔符:indent=长度; 排序:sort_keys=True
======================
sys模块
import sys
print(sys.version) #获取python解释程序的版本信息
print(sys.maxsize) #表示最大的int值
print(sys.path) #返回模块的搜索路径,初始化使用pythonpath环境变量
print(sys.platform)#返回操作平台的名称
print(sys.executable) #python解释程序路径
print(sys.getwindowsversion()) #获取windows版本
print(sys.getfilesystemencoding()) #默认编码格式 utf-8
print(sys.copyright)#获取版权信息