背景与问题
在神经网络编程中,需要将数据集处理成神经网络能够处理的格式。常见的以csv、xls等结构化表格文件表示的数据集,需要通过pandas进行读取才能在Python中使用。
在一个安装有Keras(包括Tensorflow)的Python环境中,笔者运行下列命令安装pandas:
pip install pandas结果尽管安装成功,但弹出了这样一条错误信息:
……
Installing collected packages: pytz, numpy, pandas
? Attempting uninstall: numpy
? ? Found existing installation: numpy 1.19.5
? ? Uninstalling numpy-1.19.5:
? ? ? Successfully uninstalled numpy-1.19.5
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorflow 2.6.0 requires numpy~=1.19.2, but you have numpy 1.23.4 which is incompatible.
Successfully installed numpy-1.23.4 pandas-1.5.1 pytz-2022.5
如果再安装错误信息中要求的numpy版本(只要求接近,不是必须相等,如1.19.5也是可以的),覆盖原先的版本,又会报下面的错误:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
pandas 1.5.1 requires numpy>=1.20.3; python_version < "3.10", but you have numpy 1.19.5 which is incompatible.
即使按照Pandas要求的最低版本安装numpy,TensorFlow还是会报错。
原因
TensorFlow和pandas都依赖于特定版本的numpy。pip如不指定版本,将默认安装最新版本。在安装Pandas时,如果没有检测到numpy,将自动安装最新版本的numpy。
最新版本的pandas依赖于较高版本的numpy,但TensorFlow不兼容高版本numpy。这里,笔者是参照Kaggle的配置安装的TensorFlow和Keras,如下图。
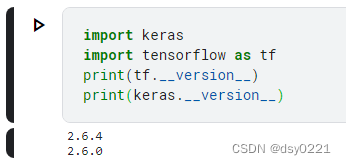
?(注意:笔者用pip install tensorflow==99999查到目前TensorFlow的最新正式版本是2.10.0,但TensorFlow并不是版本越高越好。尤其是GPU版本,依赖于特定的CUDA)
解决
笔者参照?https://blog.csdn.net/popboy29/article/details/126122865?的做法,在装有tensorflow的环境下输入下列命令:
pip install pandas==10000显示下列信息:
Looking in indexes: <指定下载源>
ERROR: Could not find a version that satisfies the requirement pandas==10000 (from versions: 0.1, 0.2, 0.3.0, 0.4.0, 0.4.1, 0.4.2, 0.4.3, 0.5.0, 0.6.0, 0.6.1, 0.7.0, 0.7.1, 0.7.2, 0.7.3, 0.8.0, 0.8.1, 0.9.0, 0.9.1, 0.10.0, 0.10.1, 0.11.0, 0.12.0, 0.13.0, 0.13.1, 0.14.0, 0.14.1, 0.15.0, 0.15.1, 0.15.2, 0.16.0, 0.16.1, 0.16.2, 0.17.0, 0.17.1, 0.18.0, 0.18.1, 0.19.0, 0.19.1, 0.19.2, 0.20.0, 0.20.1, 0.20.2, 0.20.3, 0.21.0, 0.21.1, 0.22.0, 0.23.0, 0.23.1, 0.23.2, 0.23.3, 0.23.4, 0.24.0, 0.24.1, 0.24.2, 0.25.0, 0.25.1, 0.25.2, 0.25.3, 1.0.0, 1.0.1, 1.0.2, 1.0.3, 1.0.4, 1.0.5, 1.1.0, 1.1.1, 1.1.2, 1.1.3, 1.1.4, 1.1.5, 1.2.0, 1.2.1, 1.2.2, 1.2.3, 1.2.4, 1.2.5, 1.3.0, 1.3.1, 1.3.2, 1.3.3, 1.3.4, 1.3.5, 1.4.0rc0, 1.4.0, 1.4.1, 1.4.2, 1.4.3, 1.4.4, 1.5.0rc0, 1.5.0, 1.5.1)
ERROR: No matching distribution found for pandas==10000
然后conda create了一个临时环境,在这个环境上用下列命令依次安装从1.0.0到1.5.1不同的版本(不包括rc版本):
pip install pandas==x.x.x ::x.x.x为pandas的版本安装时注意观察下面的信息(可能是下面两种中的一种),这是pandas所依赖的版本要求:
Collecting numpy>=1.17.3
或者
Requirement already satisfied: numpy>=1.18.5 in <路径,这里不用管是什么>?(from pandas==<pandas的版本>) (<numpy的当前版本>)
其中“numpy>=”后面的版本号就是pandas所依赖的最低numpy版本。整理如下表:
| pandas版本 | 依赖的最低numpy版本 |
|---|---|
| 1.0.x | 1.13.3 |
| 1.1.x | 1.15.4 |
| 1.2.x | 1.16.5 |
| 1.3.x | 1.17.3 |
| 1.4.x | 1.18.5 |
| 1.5.x | 1.20.3 |
因此,解决办法如下:
- 先安装TensorFlow错误信息中要求的numpy版本(也可以是略高的版本,如提示要1.19.2,安装1.19.5也是可以的),覆盖原先的版本。
- 按照上表安装符合numpy版本要求的pandas(当然最好是最接近的版本)。
至于各种Tensorflow版本对numpy版本的要求,因为安装包较大且安装时间长,我就不做试验了,可以参考一下下面这篇博客: