概念
序列化是服务端返数据给前端的时候,将模型类对象转化成josn,一般用于get请求
反序列化是接收前端json数据后反序列化成后端可操作的数据,一般用于post等从前端获取数据的请求。从前端获取到数据后需要先校验is_valid,验证数据是否是符合规范的,是否可以转化成类模型对象,正确返回true,错误返回false。
delete不需要序列化器
josn和字典的区别:
josn是一种数据类型,键值必须用双引号引
字典是一种数据结构 以键值对的形式存在
-
序列化在计算机科学中通常有以下定义:
在数据储存与传送的部分是指将一个对象)存储至一个储存媒介,例如档案或是记亿体缓冲等,或者透过网络传送资料时进行编码的过程,可以是字节或是XML等格式。而字节的或XML编码格式可以还原完全相等的对象)。这程序被应用在不同应用程序之间传送对象),以及服务器将对象)储存到档案或数据库。相反的过程又称为反序列化。-
简而言之,我们可以将序列化理解为:
将程序中的一个数据结构类型转换为其他格式(字典、JSON、XML等),例如将Django中的模型类对象装换为JSON字符串,这个转换过程我们称为序列化。
queryset = BookInfo.objects.all() book_list = [] # 序列化 for book in queryset: book_list.append({ 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, 'image': book.image.url if book.image else '' }) return JsonResponse(book_list, safe=False)
-
-
反之,将其他格式(字典、JSON、XML等)转换为程序中的数据,例如将JSON字符串转换为Django中的模型类对象,这个过程我们称为反序列化。
json_bytes = request.body json_str = json_bytes.decode() # 反序列化 book_dict = json.loads(json_str) book = BookInfo.objects.create( btitle=book_dict.get('btitle'), bpub_date=datetime.strptime(book_dict.get('bpub_date'), '%Y-%m-%d').date() )
序列化器的目的:
(1)数据的转换,转换分两种:序列化、反序列化
(2)数据的校验,只有反序列化时才会用到
1. 序列化流程图:

2. 反序列化流程图

选项参数用来约束反序列化时前端传递过来的参数是否合法
3. 序列化器中CharField和IntegerField选项参数
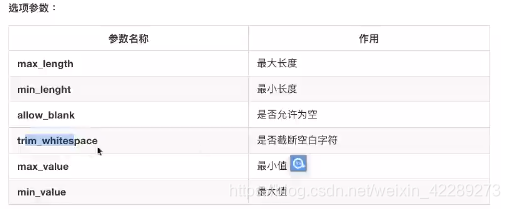
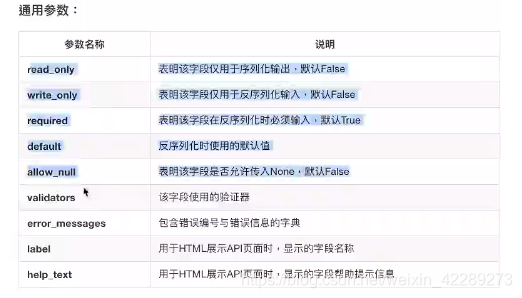
4. 序列化器中字段通用选项参数
5. models.py代码
from django.db import models
class BookInfo(models.Model):
btitle = models.CharField(max_length=50, verbose_name="标题")
bcontent = models.TextField(verbose_name="内容")
bread = models.IntegerField(verbose_name="阅读量", default=0)
bprice = models.DecimalField(verbose_name="价格", max_digits=6, decimal_places=2, default=20)
bpub_date = models.DateTimeField(verbose_name="发布日期", auto_now_add=True)
is_delete = models.BooleanField(verbose_name="删除标记", default=False)
image = models.ImageField(upload_to="books/%Y/%m", verbose_name="图片", max_length=100, null=True, blank=True)
def __str__(self):
return self.btitle
class Meta:
verbose_name = "图书信息"
verbose_name_plural = verbose_name
6. serializers.py代码
from rest_framework import serializers
from .models import BookInfo
# 反序列化有三种自定义校验方法:1. 字段参数校验 2. 单个字段校验 3. 多个字段联合校验
def about_python(value):
if "python" not in value.lower():
raise serializers.ValidationError("图书不是关于python的")
return value
class BookInfoSerializer(serializers.Serializer):
"""书籍的序列化器"""
# 序列化器中的字段可以比模型类多,也可以比模型类少
id = serializers.IntegerField(label="ID", read_only=True)
btitle = serializers.CharField(label="标题", max_length=50, validators=[about_python])
bcontent = serializers.CharField(label="内容", required=True)
bread = serializers.IntegerField(label="阅读量", required=False)
bprice = serializers.DecimalField(label="价格", max_digits=6, decimal_places=2, required=False)
bpub_date = serializers.DateTimeField(label="发布日期", required=False)
image = serializers.ImageField(label="图片", required=False)
def validate_btitle(self, value):
"""对序列化器中单个字段追加额外的校验规则
value: 当前要校验的单个字段的值
"""
if "django" not in value.lower():
raise serializers.ValidationError("图书不是关于django的")
return value
def validate(self, attrs):
"""对多个字段进行联合校验,也可以只校验单个字段,所以实际开发中用这个的比较多
attrs: 里面是前端传递过来的所有数据, 它是一个字典
"""
if attrs["btitle"] != attrs["bcontent"]:
raise serializers.ValidationError("标题和内容不一致") # 此处练习是模仿两次密码不一致
# 此处字典中还可以增加键值对,一般情况下不变
# 此处return 返回的 attrs 就是视图中serializer对象的属性validated_data对应的值
return attrs
def create(self, validated_data):
"""当调用序列化器对象的save方法时,如果当初创建序列化器对象时没有给instance参数,调用create方法"""
book = BookInfo.objects.create(**validated_data)
# 获取创建序列化器对象时传递的属性值--request请求对象
request = self.context
print(request.user)
return book
def update(self, instance, validated_data):
"""当调用序列化器的save方法时,如果当初创建序列化器对象时传递了instance参数,调用update方法"""
# instance是创建序列化器对象是传递进来的 BookInfoSerializer(instance=book, data=data)
# validated_data 是经过反序列化,校验后的,大字典数据
instance.btitle = validated_data["btitle"]
instance.bcontent = validated_data["bcontent"]
# 切记,修改了实例属性后不要忘记保存进数据库
instance.save()
return instance
# heroinfo_set = serializers.PrimaryKeyRelatedField(label="英雄", many=True, read_only=True)
# heroinfo_set = serializers.StringRelatedField(label="英雄", many=True, read_only=True)
# 注意: 关联属性进行序列化时,只能在一方写,两方都写会报错
# heroinfo_set = HeroInfoSerializer(many=True)
7. views.py代码
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from .serializers import BookInfoSerializer
from .models import BookInfo
class BookInfoList(APIView):
"""图书列表类视图"""
def get(self, request):
books = BookInfo.objects.all()
serializers = BookInfoSerializer(instance=books, many=True)
return Response(data=serializers.data, status=status.HTTP_200_OK)
def post(self, request):
# 创建序列化器对象时可以把request请求对象传递给序列化器对象的属性
serializer = BookInfoSerializer(data=request.data, context=request)
if serializer.is_valid():
# 此处调用save方法时,会自动调用序列化器中的create方法
serializer.save()
return Response(data=serializer.data, status=status.HTTP_201_CREATED)
else:
return Response(data=serializer.errors, status=status.HTTP_400_BAD_REQUEST)
class BookInfoDetail(APIView):
"""图书详情类视图"""
@staticmethod
def get_book(pk):
# 查询图书
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
book = ""
return book
else:
return book
def get(self, request, pk):
book = self.get_book(pk)
if not book:
return Response({"err": "所查图书不存在"}, status=status.HTTP_404_NOT_FOUND)
# 序列化
serializer = BookInfoSerializer(book)
# 响应
return Response(data=serializer.data)
def put(self, request, pk):
# 查看图书是否存在
book = self.get_book(pk)
if not book:
return Response({"err": "图书不存在,无法更新"}, status=status.HTTP_404_NOT_FOUND)
# 接收数据并校验数据
serializer = BookInfoSerializer(instance=book, data=request.data)
if serializer.is_valid():
# 此处调用save方法时会自动调用序列化器中的update方法
serializer.save()
# 响应
return Response(serializer.data)
else:
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
def delete(self, request, pk):
book = self.get_book(pk)
if not book:
return Response({"err": "所查图书不存在, 无法删除"}, status=status.HTTP_404_NOT_FOUND)
book.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
8. urls.py代码
from django.urls import path, re_path
from django.views.decorators.csrf import csrf_exempt
from . import views
urlpatterns = [
# 图书类视图对应的路由
path("books/", csrf_exempt(views.BookInfoList.as_view()), name="booklist"),
re_path("^books/(?P<pk>d+)/$", csrf_exempt(views.BookInfoDetail.as_view()), name="bookdetail"),
]
9. ModelSerializer类使用详解
ModelSerializer与常规的Serializer相同,但提供了:
(1)基于模型类自动生成一系列字段
(2)包含默认的create和update方法的实现
当然如果自动生成的字段或create、update方法不能满足我们的需求,我们就可以修改属性或重新定义create、update方法
from rest_framework import serializers
from .models import BookInfo, HeroInfo
class BookInfoSerializer(serializers.ModelSerializer):
"""图书序列化器"""
class Meta:
model = BookInfo
fields = "__all__" # 映射模型类中存在的所有字段
class HeroInfoSerializer(serializers.ModelSerializer):
"""英雄序列化器"""
hbook = BookInfoSerializer(read_only=True)
class Meta:
model = HeroInfo # 指定序列化器字段从哪个模型去映射
# fields类属性需要把hbook单独加上,而exclude不需要, __all__也不需要
fields = ["id", "hname", "hcommon", "hgender", "hbook"] # 映射指定的字段
# exclude = ["hgender"] # 排除的字段,其它字段都要
# 如果想对字段中的某些选项做修改,可以加个类属性extra_kwargs
# extra_kwargs = {
# "hname": {"max_length": 10, "write_only": True}
# }
# 序列化单独定义属性,反序列化要在extra_kwargs中设置
# read_only_fields属性设置只能序列化字段
read_only_fields = ["hgender"]
def create(self, validated_data):
"""新增一个英雄"""
# 创建序列化区对象时,context参数传递过来的前端数据hbook: int类型
book_id = self.context
hero = HeroInfo()
hero.hname = validated_data["hname"]
hero.hcommon = validated_data["hcommon"]
hero.hbook_id = book_id
hero.save()
return hero
def validate(self, attrs):
"""联合校验"""
if "蜀" not in attrs["hcommon"]:
raise serializers.ValidationError({"err": "不包含蜀字"})
return attrs