Pandas 是 Python 语言的一个扩展程序库,用于数据分析。其中DataFrame,Json,数据筛选的使用频次很高,值得重点将基本用法学习并总结。
版本信息:python 3.7? pandas?1.3.5
一、DataFrame
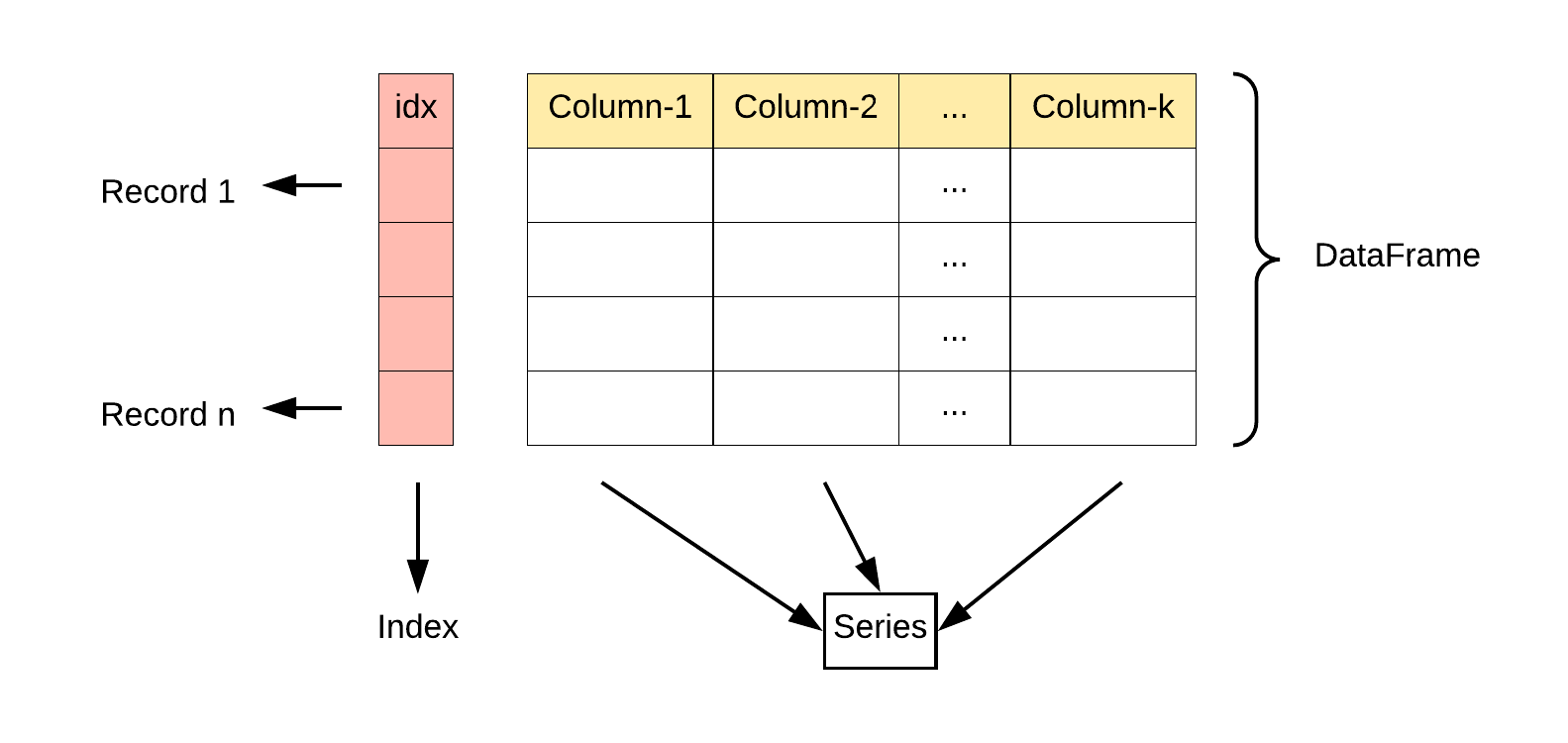
DataFrame 是一个表格型的数据结构,可以被看做由 Series 组成的字典(共同用一个索引)
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data)
#返回第一行和第二行
print(df.loc[0,1])二、JSON截取
nested_list.json 文件内容
{
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}对于以上有嵌套的json格式,如果我只需要读取student中的math字段的所有记录;有两种方式,
1、使用read_json将记录读取出来,再用DataFrame截取;
2、使用json_normalize直接截取。
import pandas as pd
import json
import glom
第一种方式:
#需安装pip3 install glom,glom 模块允许我们使用 . 来访问内嵌对象的属性。
df = pd.read_json('nested_list.json')
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
第二种方式:
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(data, record_path =['students'])
# 还可以使用 meta 参数来显示其他的元数据
df_nested_list = pd.json_normalize(data, record_path =['students'],meta=['class'])
print(df_nested_list)三、数据筛选:
1、清洗空值:DataFrame.dropna
2、替换空值:DataFrame.fillna
3、清洗重复数据:DataFrame.duplicated
其中可使用参数如下:
- axis:默认为?0,表示逢空值剔除整行,如果设置参数?axis=1?表示逢空值去掉整列。
- how:默认为?'any'?如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置?how='all'?一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
应用场景:
#1、某一列ST_NUM,dropna清除空值,inplace = True修改dataframe
df.dropna(subset=['ST_NUM'], inplace = True)
#2、列PID,空值填充123456,inplace = True修改dataframe
df['PID'].fillna(12345, inplace = True)
#3、修改第2行,age列的数据
df.loc[2, 'age'] = 30 #
#4、删除重复数据
df.drop_duplicates(inplace = True)