torchvision 下载的 pretrain 模型路径
- 使用 torchvision 来直接下载 pretrained 模型,有时候服务器的下载速度很慢,不如直接下载到本地之后传上去,但是问题来了,torchvision 模型下载后的存放路径是什么呢?
import torchvision.models as models
model = models.alexnet(pretrained=True)
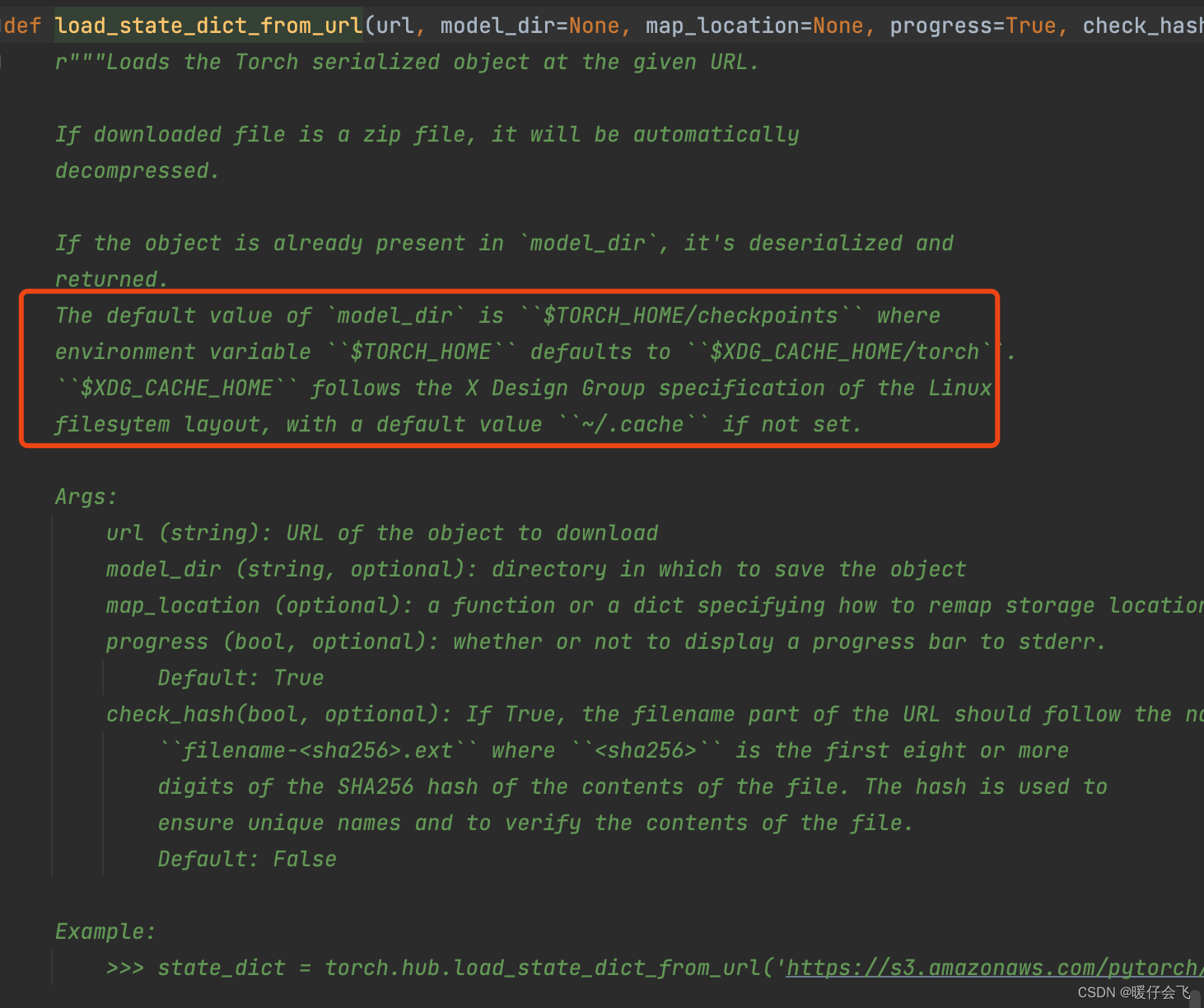
-
可以看到源码中是定义的这个位置,如果是 MAC 系统,那么
$XDG_CACHE_ HOME/这个位置就是cd ~/.cache/ -
所以
$XDG_CACHE_ HOME/ torch位置就是cd ~/.cache/torch -
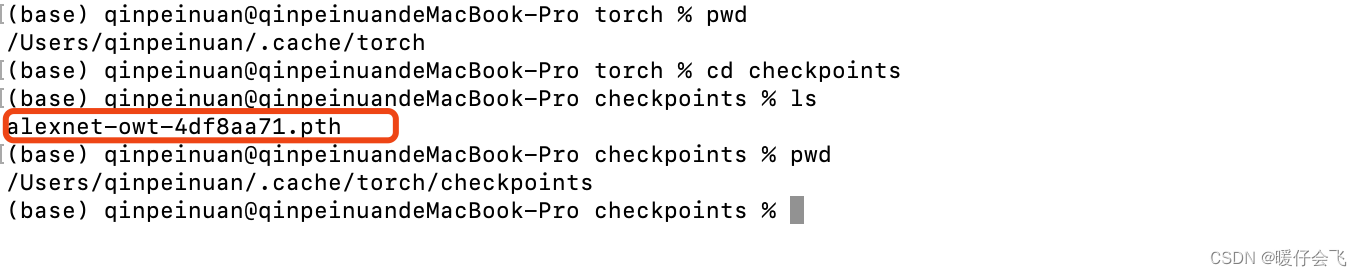
在这里面的
checkpoints下面就是所有下载的模型了
cuda 版本一定要适配
- 我最近在自己重写
rcnn的代码,然后默认torch的版本是1.4, 然后我的设备gpu的cuda版本是11.1 - 我在进行训练的时候,
model.to(device)好久都没反应,不报错。
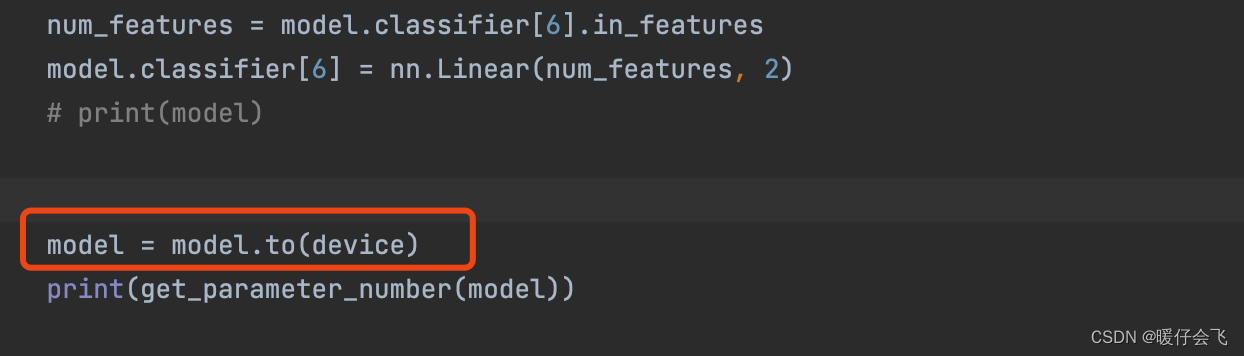
- 经过一步步 debug,发现这个版本上掉以轻心了,重新安装
pytorch的10.1版本,cuda 11.1就可以了
多 cuda 训练 DataParallel 使用须知
- 很多人都会使用
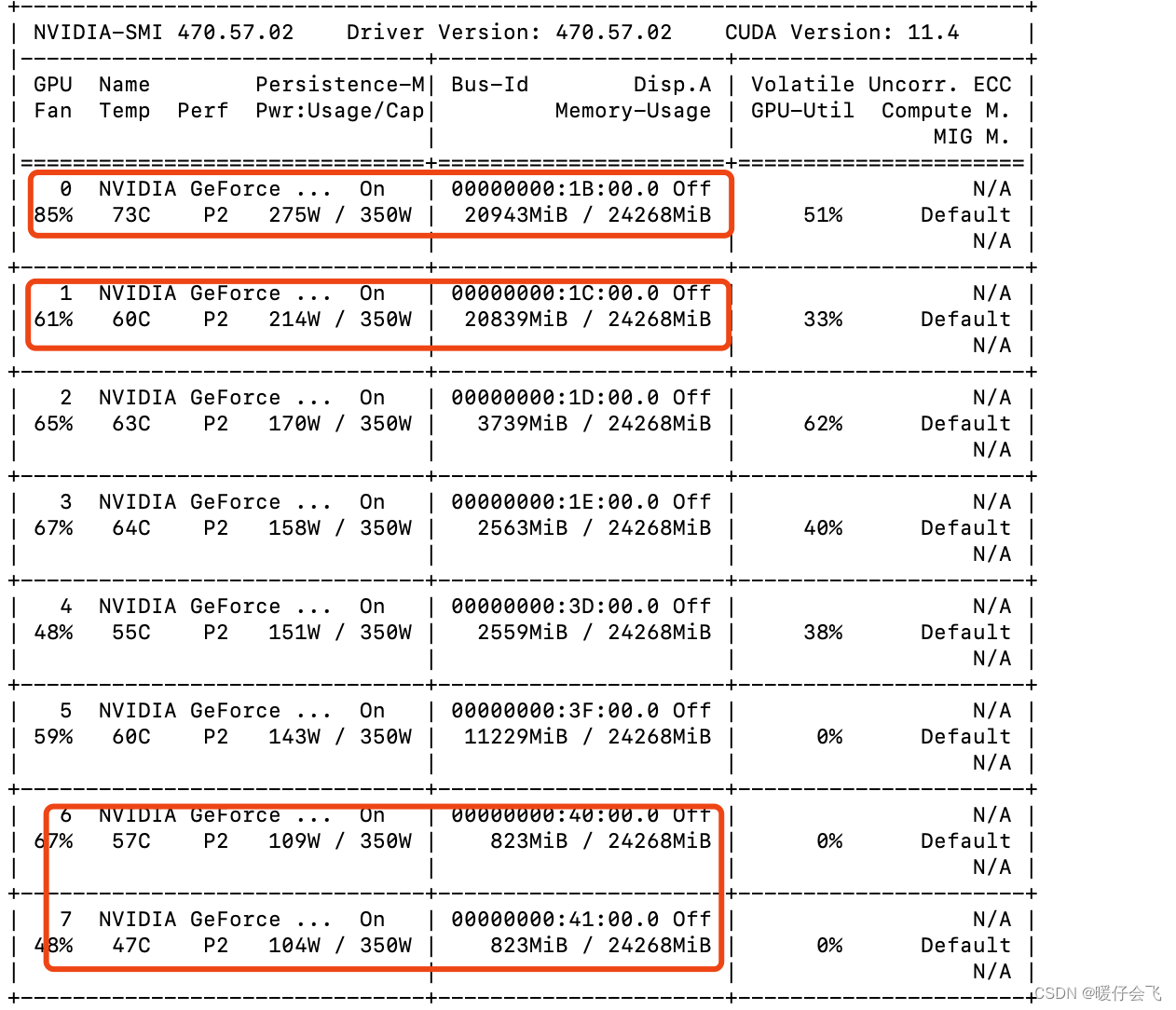
torch.nn.DataParallel进行多卡联合训练 - 但是今天我在设置多卡训练的时候报错:
AssertionError: Invalid device id - 我运行的时候
0,1,6,7卡被占用。所以我的 device 设置如下:
os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = DataParallel(model
, device_ids=[int(i) for i in args.device.split(',')]
)
AssertionError: Invalid device id
- 经过查阅资料 发现:
- 设置
os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5"相当于告诉机器,我现在使用这四个设备,那么这四个设备的 device_id 就分别变成了0, 1, 2, 3所以代码应该写成下面这样:因为使用DataParallel的时候要求必须从设备0开始,所以我们需要想办法将我们调用的设备设置成从0编号开始
os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = DataParallel(model
, device_ids=[0,1,2,3]
)