Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight
论文地址: https://arxiv.org/pdf/2106.04263.pdf
- 本文并非是技术性非常强的文章,没有“直接”利用的价值。
- 但是在文中提出了不少可以研究的方向,并揭示了 transformer,特别是其中的 local attention,与其它之前比较常用的技术,如 convoluation, depth-wise convolution 等,之间的一些联系。
- 其中又更主要地介绍了稀疏连接,权重共享,及动态权重三者,在以上各种技术之间的联系。
- 如果想深入地研究 transformer 的结构与之前提出的一些结构的区别及共性,包括提出一些如何更进一步的改进,这篇文章,特别是 appendix 部分,值得好好看一看。
摘要
- local attention 是分别在每个小的 local windown 上进行的 attention
- 作者将 local attention 重新表述为:通道方向上的局部连接层,并从两种网络正则化的方向,即稀疏连接和权重共享上,来分析它
- 稀疏连接:通道之间没有连接,且每个位置仅与一个小的窗口中的其它位置相关联;
- 权重共享:一个位置的连接权重,是在各通道间,或者每组通道间共享的;
- 动态权重:连接权重是动态地根据每张图片预测出来的;
- 作者指出,local attention 其实是深度卷积加上它的稀疏连接的动态版本,主要区别在于权重共享,深度卷积是在空间方向上共享连接权重(也即kernel weights)
简介
作者从这几个方面来研究 local attention 的机制,首先是稀疏连接,它是用来控制模型的复杂度的;然后是权重共享,是用来降低训练中对数据量的要求的;最后是动态权重预测,是用来提高模型能力的。
作者将 local attention 重新表达为一个在通道方向上的(channel-wise),空间上局部连接的(spatially-locally),且有着动态连接权重(dynamic connection weights)的层。
主要的特点总结如下:
- 稀疏连接:通道之间没有连接,且每个输出位置仅与输入位置及附近的一个窗口中的位置相连接;
- 权重共享:一个位置的连接权重,是在各通道间,或者每组通道间共享的;
- 动态权重:连接权重是动态地根据每张图片预测出来的;
作者将 local attention 与 depth-wise convolution 进行对比,因为它也是个通道方向上的,局部空间连接的层,且在稀疏连接上比较相似。主要的区别在于权重共享的模式:depth-wise convolution 是在空间方向上共享权重(即长宽方向),而不是在通道方向上。此外,depth-wise convolution 也能从动态连接权重上获益。
当作者将 Swin Transformer 中的 local attention 换成带有动态权重共享的 depth-wise convolution 后,发现它达到了与 Swin Transformer 相同甚至更好的结果,且动态深度卷积有着更低的计算复杂度。
主要的几点总结如下,直接搬上原文,但意思和上面的差不多:
- Local attention adopted by local Vision Transformer takes advantage of existing regularization schemes, sparse connectivity and weight sharing, as well as dynamic weight prediction, for increasing the capability without requiring a corresponding increase in model complexity and training data.
- Local attention and (dynamic) depth-wise convolution are similar in sparse connectivity and differ in weight sharing and dynamic weight prediction forms. The empirical results on visual recognition imply that the regularization forms and the dynamic weight prediction scheme exploited by local attention and (dynamic) depth-wise convolution perform similarly.
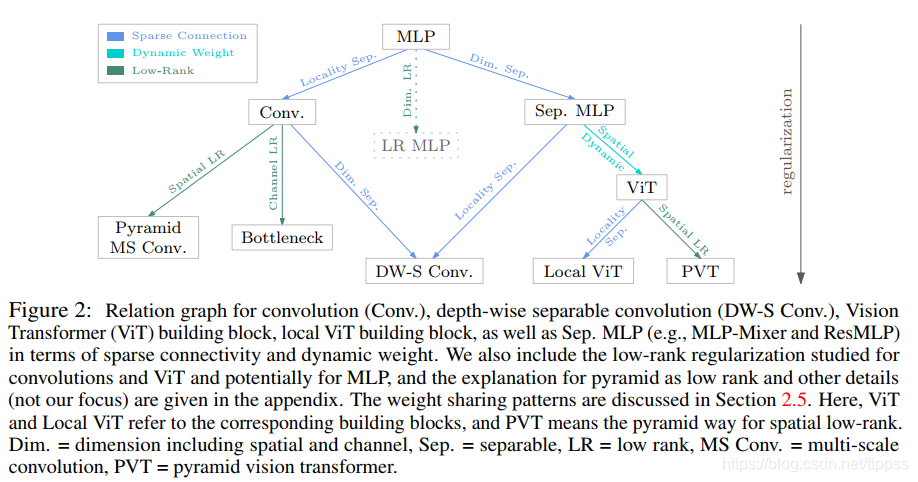
- In addition, we present a relation graph to connect convolution and attention, as well as the concurrently-developed MLP-based methods, e.g., ResMLP [50] and MLP-Mixer [49]. The relation graph shows that these methods essentially take advantage of different sparse connectivity and weight sharing patterns for model regularization optionally with dynamic weight prediction.
理解局部注意力
稀疏连接,权重共享,及动态权重
稀疏连接意思是在有的输出神经元及输入神经元之间没有连接,它在没有减少神经元的同时,降低了模型的复杂度。
权重共享的意思是有些连接的权重是相等的,它在没有增加训练数据量的情况下,减少了模型的参数量,并增加了网络的尺寸。
动态权重是指针对每个实例,都学习了一套特定的连接权重。它提高了模型的能力。
局部注意力的性质
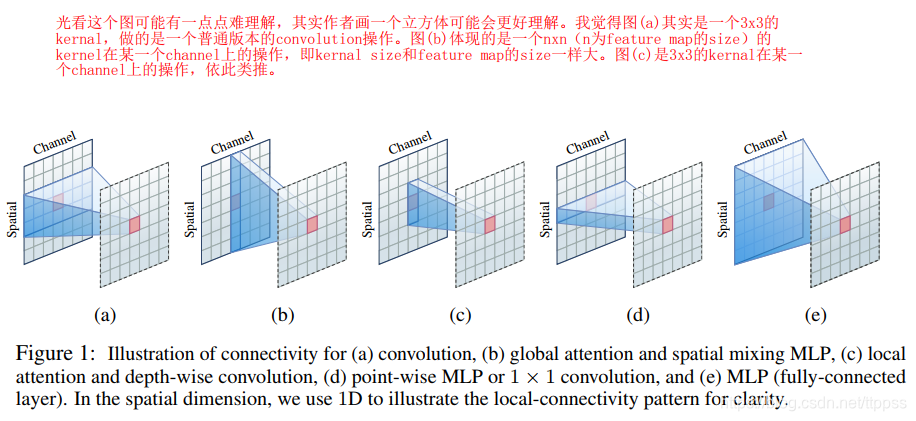
(光看这个图可能有一点点难理解,其实作者画一个立方体可能会更好理解。我觉得图(a)其实是一个3x3的kernal,做的是一个普通版本的convolution操作。图(b)体现的是一个nxn(n为feature map的size)的kernel在某一个channel上的操作,即kernal size和feature map的size一样大。图?是3x3的kernal在某一个channel上的操作,依此类推。)
局部注意力的聚合过程其实可以表达如下:
y i = ∑ j = 1 N k w i j ⊙ x i j \mathbf{y}_{i}=\sum_{j=1}^{N_{k}} \mathbf{w}_{i j} \odot \mathbf{x}_{i j} yi?=j=1∑Nk??wij?⊙xij?
其中 w i j ∈ R D \mathbf{w}_{i j} \in \mathbb{R}^{D} wij?∈RD 是由注意力权重 a i j ?or? { a i j 1 , a i j 2 , … , a i j M } a_{i j} \text { or }\left\{a_{i j 1}, a_{i j 2}, \ldots, a_{i j M}\right\} aij??or?{aij1?,aij2?,…,aijM?} 组成的权重向量,上面讲到的三个点,直接截图如下,即体现了 local attention 中的那几个特点。


与 depth-weise convolution 的关系
它用一个单独的 filter 对每个通道做卷积: X  ̄ d = C d ? X d \overline{\mathbf{X}}_{d}=\mathbf{C}_{d} \otimes \mathbf{X}_{d} Xd?=Cd??Xd? ,其中 X ˉ d \bar X_d Xˉd? 和 X d X_d Xd? 分别是第d个通道的输出及输入特征图, C d C_d Cd? 是对应的 kernel weight。
相似点:都是稀疏连接,在通道间没有连接,且每个位置只与某一通道的一个小窗口中的位置连接;
不同点:首先是权重共享,depth-wise convolution 是在空间方向上共享(即长宽方向上),而 local attention 是在通道间或者每组通道间共享;其次,depth-wise convolution 的连接权重是静态的,并学习成为模型的参数,而 local attention 的是动态的,是根据每个实例预测出来的,且 depth-wise convolution 也能从动态权重中获益,比如使用 SENet 中的权重预测机制;最后是窗口的表示方式,local attention 用一个集合来表示位置,会造成空间顺序信息的丢失,因此它用位置嵌入来隐式地探索空间信息,而 depth-wise 卷积是用一个向量来表示,它使用有相对位置索引的权重(the weights indexed by the relative position),将局部窗口中的信息聚合起来。
Relation Graph
这张图没太看明白,粘贴在下面
其它
剩下的内容其实还挺多,特别是 Appendix 中的内容,也很值得看。