����ͼ�������ͼ����ѧϰ����
ǰ�������Ѿ��˽���ͼ�ڵ�ı���ѧϰ,����Ҫ�Ǹ��ݽڵ�����Խ���ѧϰ��Ԥ��,����������Ҫѧϰ����ͼ�������ͼ������ѧϰ������ͼ�������Ǹ���ͼ�Ľڵ����Ժͱ�(���ߵ���������еĻ�)�õ�һ��������Ϊͼ�ı���,����������������ٽ�����һ����ͼԤ�⡣����ͼͬ������How Powerful are Graph Neural Networks? ��ͼ���������ǵ�ǰ����ͼ����ѧϰ����,���Ǿ������Ϊ����ѧϰ��
ͼͬ��������ƵĶ�����:Ŀǰ�µ�ͼ���������ƴ����ھ����Ե�ֱ��������ʽ�ķ�����ʵ���Ե��Դ���Ȼ�����Ƕ�ͼ����������Ժ;������˽�����,��ͼ������ı�������ѧϰ����ʽ����Ҳ�����ޡ�
1 ͼͬ����������
1.1 ����ͼͬ�������ͼ����ѧϰ
��Ҫ����������������:
- ���ȼ���õ��ڵ����;
- ��ζ�ͼ�ϸ����ڵ�ı�����ͼ�ػ�(Graph Pooling),���Ϊͼ����(Graph Readout),�õ�ͼ�ı���(Graph Representation)��
���ͼ��������������͡�����ÿһ��Ľڵ��������������Ҫ��,�����ͼͬ��������,��ͬ��Ľڵ��������ͺ�ƴ��,����ѧ��������,
h G = CONCAT ( READOUT ( { h v ( k ) �O v �� G } ) �O k = 0 , 1 , ? ? , K ) h_{G} = \text{CONCAT}(\text{READOUT}\left(\{h_{v}^{(k)}|v\in G\}\right)|k=0,1,\cdots, K) hG?=CONCAT(READOUT({hv(k)?�Ov��G})�Ok=0,1,?,K)
����ƴ�Ӷ�������ӵ�ԭ�����ڲ�ͬ��ڵ�ı������ڲ�ͬ�������ռ䡣 δ���ϸ��֤��,�����õ���ͼ�ı�ʾ��WL Subtree Kernel�õ���ͼ�ı����ǵȼ۵ġ�
����ڵ������ͨ���ڵ�Ƕ��ģ��ʵ�ֵ�,���ڵ�Ƕ��ģ����ͨ��GINConv����ͼͬ��������ʵ��,��ѧ��������:
x
i
��
=
h
��
(
(
1
+
?
)
?
x
i
+
��
j
��
N
(
i
)
x
j
)
\mathbf{x}^{\prime}_i = h_{\mathbf{\Theta}} \left( (1 + \epsilon) \cdot \mathbf{x}_i + \sum_{j \in \mathcal{N}(i)} \mathbf{x}_j \right)
xi��?=h��????(1+?)?xi?+j��N(i)��?xj????
����
X
��
=
h
��
(
(
A
+
(
1
+
?
)
?
I
)
?
X
)
,
\mathbf{X}^{\prime} = h_{\mathbf{\Theta}} \left( \left( \mathbf{A} + (1 + \epsilon) \cdot \mathbf{I} \right) \cdot \mathbf{X} \right),
X��=h��?((A+(1+?)?I)?X),
PyG���Ѿ�ʵ���˴�ģ��,���ǿ���ͨ��torch_geometric.nn.GINConv��ʹ��PyG����õ�ͼͬ��������,Ȼ����ʵ����֧�ִ��ڱ����Ե�ͼ��
CLASS GINConv(nn: Callable, eps: float = 0.0, train_eps: bool = False, **kwargs)
nn (torch.nn.Module):һ�������� h �� h_{\mathbf{\Theta}} h��?����״Ϊ[-1,in_channels]�Ľڵ�����xӳ��Ϊ��״Ϊ[-1,out_channels],����,��torch.nn.Sequential���塣eps(float):��ʼ�� ? \epsilon ?,Ĭ��Ϊ0��train_eps(bool):�������ΪTrue, ? \epsilon ?����һ����ѵ��������(Ĭ��ֵ:False)��
1.2 ͼͬ����WL Test�㷨
��ôʲô��ͼͬ����?ͼͬ������˵����ͼӵ��һ�������˽ṹ,Ҳ����˵,���ǿ���ͨ�����±�ǽڵ��һ��ͼ�еõ�����һ��ͼ��Weisfeiler-Lehman ͼ��ͬ���Բ����㷨,���WL Test,��һ�����ڲ�������ͼ�Ƿ�ͬ�����㷨��
��ô���ǽ�������һ��WL Test�㷨,��һά��ʽ������ͼ�������е��ڽӽڵ�ۺϡ����� 1) �����ؾۺϽڵ㼰���ڽӽڵ�ı�ǩ,Ȼ��2) ���ۺϵı�ǩɢ�г�Ψһ���±�ǩ,�ù�����ʽ��Ϊ�·��Ĺ�ʽ��
L
u
h
��
hash
?
(
L
u
h
?
1
+
��
v
��
N
(
U
)
L
v
h
?
1
)
L^{h}_{u} \leftarrow \operatorname{hash}\left(L^{h-1}_{u} + \sum_{v \in \mathcal{N}(U)} L^{h-1}_{v}\right)
Luh?��hash???Luh?1?+v��N(U)��?Lvh?1????
����,
L
u
h
L^{h}_{u}
Luh?��ʾ�ڵ�
u
u
u�ĵ�
h
h
h�ε����ı�ǩ,��
0
0
0�ε����ı�ǩΪ�ڵ�ԭʼ��ǩ������ڵ���������,��������ͼ֮��Ľڵ�ı�ǩ��ͬʱ,�Ϳ���ȷ��������ͼ�Ƿ�ͬ���ġ���Ҫע����ǽڵ��ǩ���ܵ�ȡֵֻ������������
��������ͨ������ͼG��G'��ֱ�۵�����һ��WL Test�㷨,����ÿ���ڵ�ӵ�б�ǩ(ʵ����,һЩͼû�нڵ��ǩ,���ǿ����Խڵ�Ķ���Ϊ��ǩ)��
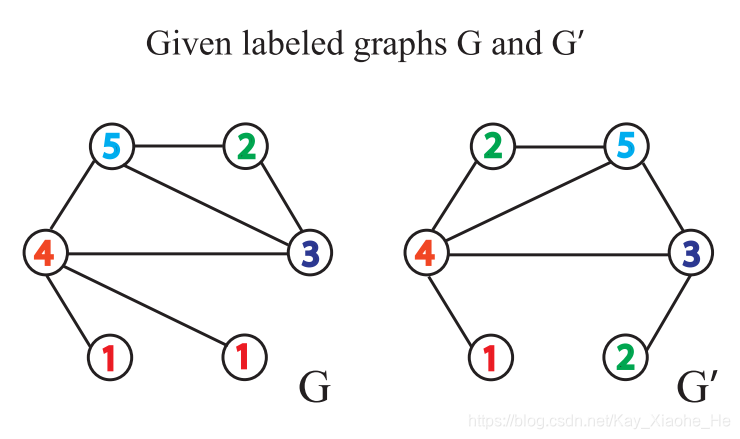
- ����������ͼ,ÿ���ڵ�ۺ������Լ��ڽӽڵ�ı�ǩ�õ�һ���ַ���,�����ַ������ڽӽڵ��ǩ���ַ�����
,����,�ڽӽڵ���ַ���������������(ԭ���DZ�֤������,�����ڽӽڵ��˳��ı�������ı�)��
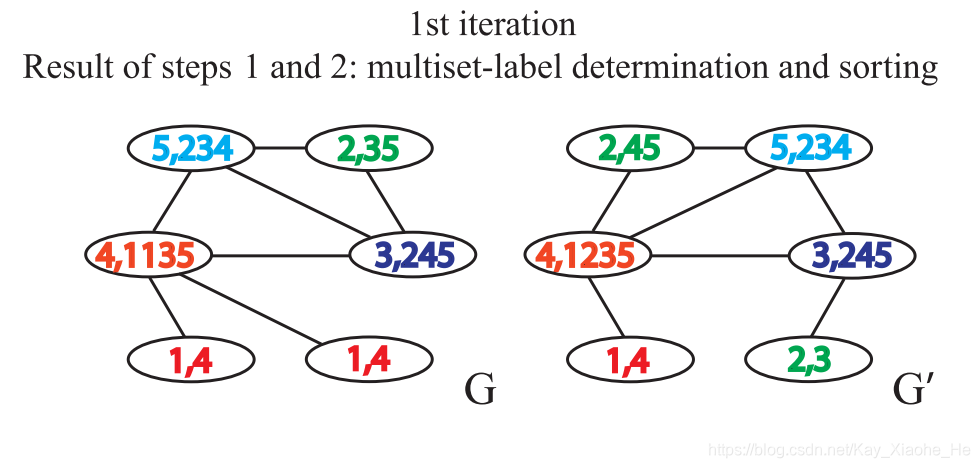
- ����ǩ˳��ɢ��,������ǩ�ַ���ѹ��,�õ�һ����̵ı�ǩ

- ���¸��ڵ�����µĵ��ı�ǩ
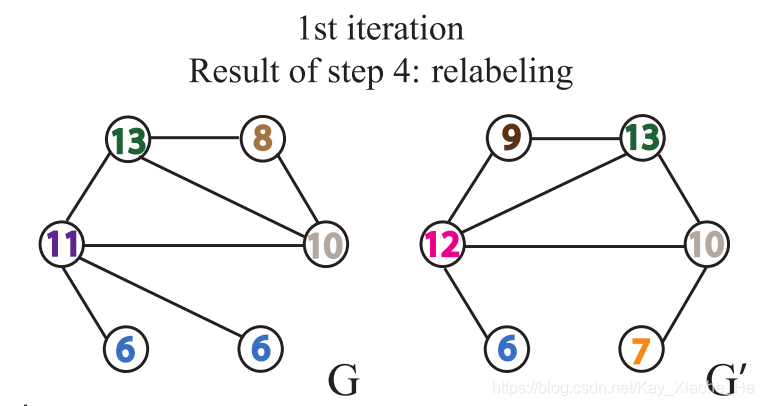
����ظ���������,�Խ��нڵ��ǩ�ĸ��¡���������IJ����ظ�һ���Ĵ�����,û�з�������ͬ�ڵ��ǩ�ij��ִ�����һ�µ����,��ô�������ж�����ͼ�Ƿ�ͬ����������������ͼ��ͬ�ڵ��ǩ�ij��ִ�����һ��ʱ,�����ж�����ͼ��������
�������ڵ��
h
h
h��ı�ǩһ��ʱ,��ʾ�ֱ����������ڵ�Ϊ���ڵ��WL������һ�µġ�WL��������ͨ������ͬ,WL���������ظ��Ľڵ㡣��ͼչʾ��һ����1�ڵ�Ϊ���ڵ��Ϊ2��WL������
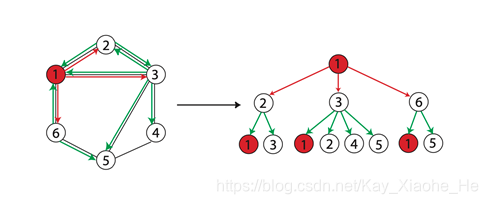
ͼ����������
WL Test �㷨��һ���������,��ֻ���ж�����ͼ��������,������ͼ֮������Ƴ̶ȡ�Ҫ��������ͼ�����Ƴ̶�,������WL Subtree Kernel������
�÷�����˼������WL Test�㷨�õ��ڵ�Ķ��ı�ǩ,Ȼ�����ǿ��Էֱ�ͳ��ͼ�и����ǩ���ֵĴ���,����һ������,�������������Ϊͼ�ı���������ͼ���������������ڻ�,������Ϊ������ͼ�������ԵĹ��ơ�

����ԭʼͼG�ı�ǩΪ[1,2,3,4,5],���ִ����ֱ�Ϊ[2,1,1,1,1],ͬ��G'�ı�ǩ[1,2,3,4,5],���ִ���Ϊ[1,2,1,1,1],�ɴ˹�����������ǰ�벿��(original����)�������ĵڶ�������ѹ����ı�ǩ��8��,�ֱ�Ϊ[6,7,8,9,10,11,12,13],����Gͼ,���ֵĴ����ֱ�Ϊ[2,0,1,0,1,1,0,1],����ͼG'���ֵĴ����ֱ�Ϊ[1,1,0,1,1,0,1,1],�ɴ˹��������ĺ�߲���(compressed����)�������������ڻ�Ϊ11,��������Զ���Ϊ11��
1.3 �ж�ͼͬ���Ե�����
��ʵ���ж�ͼͬ���Ե�ͼ��������Ҫ����:
- ֻ�������ڵ�������ǩһ�������ǵ��ڽӽڵ�һ��ʱ,ͼ�����罫�������ڵ�ӳ�䵽��ͬ�ı���,��ӳ���ǵ����Եġ�
- һ���ڵ�������ڽӽڵ���һ�����ظ�����,һ���ڵ�������ظ����ڽӽڵ�,�ڽӽڵ�û��˳���ϵ�� ���GINģ�������ɽڵ�����ķ�����ѭWL Test�㷨���½ڵ��ǩ�Ĺ��̡�(���ظ�����(Multisets)ָ����Ԫ�ؿ��ظ��ļ���,Ԫ���ڼ�����û��˳���ϵ�� )
1.4 ����ͼͬ��������ܽ�:
- (������)ͼ������������ͼ�ṹ�������ֻ�ܴﵽ��WL Testһ����������
- ȷ�����ڽӵ�ۺϷ�����ͼ�ػ�������Ӧ�߱�������,����Щ������,��������ͼ�������ܴﵽ��WL Testһ����������
- ȷ���˹�ȥ���е�ͼ���������(��GCN��GraphSAGE)�����ֵ�ͼ�ṹ,�����������ֻ���ͼ�������ģ���ܹ������ͼ�ṹ���͡�
- ������һ�����ṹ�Cͼ��ͬ������(GIN),��֤����ֱ�/��ʾ������WL Test�൱��
2 ͼͬ������ʵ��
���ǴӶ����µ���ʵ�ֻ���ͼͬ��ģ��(GIN)��ͼ����ѧϰ������
2.1 ����ͼͬ�������ͼ����ģ��
�������ȹ�ע��λ��ڽڵ��������õ�ͼ�ı���,�����Լ���������ķ�������ģ�����Ȳ���GINNodeEmbeddingģ���ͼ��ÿһ���ڵ����ڵ�Ƕ��(Node Embedding),�õ��ڵ����;Ȼ��Խڵ������ͼ�ػ��õ�ͼ�ı���;�����һ�����Ա任��ͼ����ת��Ϊ��ͼ��Ԥ�⡣
import torch
from torch import nn
from torch_geometric.nn import global_add_pool, global_mean_pool, global_max_pool, GlobalAttention, Set2Set
from gin_node import GINNodeEmbedding
class GINGraphRepr(nn.Module):
def __init__(self, num_tasks=1, num_layers=5, emb_dim=300, residual=False, drop_ratio=0, JK="last", graph_pooling="sum"):
"""GIN Graph Pooling Module
Args:
num_tasks (int, optional): number of labels to be predicted. Defaults to 1 (������ͼ������ά��,dimension of graph representation).
num_layers (int, optional): number of GINConv layers. Defaults to 5.
emb_dim (int, optional): dimension of node embedding. Defaults to 300.
residual (bool, optional): adding residual connection or not. Defaults to False.
drop_ratio (float, optional): dropout rate. Defaults to 0.
JK (str, optional): ��ѡ��ֵΪ"last"��"sum"��ѡ"last",ֻȡ���һ��Ľ���Ƕ��,ѡ"sum"�Ը���Ľ���Ƕ����͡�Defaults to "last".
graph_pooling (str, optional): pooling method of node embedding. ��ѡ��ֵΪ"sum","mean","max","attention"��"set2set"�� Defaults to "sum".
Out:
graph representation
"""
super(GINGraphPooling, self).__init__()
self.num_layers = num_layers
self.drop_ratio = drop_ratio
self.JK = JK
self.emb_dim = emb_dim
self.num_tasks = num_tasks
if self.num_layers < 2:
raise ValueError("Number of GNN layers must be greater than 1.")
self.gnn_node = GINNodeEmbedding(num_layers, emb_dim, JK=JK, drop_ratio=drop_ratio, residual=residual)
# Pooling function to generate whole-graph embeddings
if graph_pooling == "sum":
self.pool = global_add_pool
elif graph_pooling == "mean":
self.pool = global_mean_pool
elif graph_pooling == "max":
self.pool = global_max_pool
elif graph_pooling == "attention":
self.pool = GlobalAttention(gate_nn=nn.Sequential(
nn.Linear(emb_dim, emb_dim), nn.BatchNorm1d(emb_dim), nn.ReLU(), nn.Linear(emb_dim, 1)))
elif graph_pooling == "set2set":
self.pool = Set2Set(emb_dim, processing_steps=2)
else:
raise ValueError("Invalid graph pooling type.")
if graph_pooling == "set2set":
self.graph_pred_linear = nn.Linear(2*self.emb_dim, self.num_tasks)
else:
self.graph_pred_linear = nn.Linear(self.emb_dim, self.num_tasks)
def forward(self, batched_data):
h_node = self.gnn_node(batched_data)
h_graph = self.pool(h_node, batched_data.batch)
output = self.graph_pred_linear(h_graph)
if self.training:
return output
else:
# At inference time, relu is applied to output to ensure positivity
# ��ΪԤ��Ŀ���ȡֵ��Χ���� (0, 50] ��
return torch.clamp(output, min=0, max=50)
����ͼ�ı����ķ���(��ͼ�ػ��ķ���)�����¼���:
sum:�Խڵ�������;ʹ��ģ��torch_geometric.nn.glob.global_add_pool��mean:�Խڵ������ƽ��;ʹ��ģ��torch_geometric.nn.glob.global_mean_pool��max:ȡ�ڵ���������ֵ;ʹ��ģ��torch_geometric.nn.glob.global_max_pool��attention:����Attention�Խڵ������Ȩ���;ʹ��ģ�� torch_geometric.nn.glob.GlobalAttention��set2set:��һ�ֻ���Attention�Խڵ������Ȩ��͵ķ���;ʹ��ģ�� torch_geometric.nn.glob.Set2Set��
2.2 ����ͼͬ������Ľڵ�Ƕ��ģ��(GINNodeEmbedding Module)
�ϱߵ�ģ�鰴�յ�һ���ֵ������õ���ͼ�ı���,������һ������,ͼ�ijػ��Ѿ�����ĺ����,��ô�ڵ��������μ������?
��ģ����ڶ��GINConvʵ�ֽ��Ƕ��ļ��㡣�˴������Ⱥ���GINConv��ʵ�֡����뵽�˽ڵ�Ƕ��ģ��Ľڵ�����Ϊ���������,����������AtomEncoder������Ƕ��õ���0��ڵ������Ȼ������������ڵ����,�ӵ�1�㿪ʼ����num_layers��,ÿһ��ڵ�����ļ��㶼����һ��Ľڵ����h_list[layer]����edge_index�ͱߵ�����edge_attrΪ��������Ҫע�����,GINConv�IJ���Խ��,�˽ڵ�Ƕ��ģ�������Ұ(receptive field)Խ��,���i�ı�����Զ�ܲ����i�ľ���Ϊnum_layers���ڽӽڵ����Ϣ��
import torch
from mol_encoder import AtomEncoder
from gin_conv import GINConv
import torch.nn.functional as F
# GNN to generate node embedding
class GINNodeEmbedding(torch.nn.Module):
"""
Output:
node representations
"""
def __init__(self, num_layers, emb_dim, drop_ratio=0.5, JK="last", residual=False):
"""GIN Node Embedding Module"""
super(GINNodeEmbedding, self).__init__()
self.num_layers = num_layers
self.drop_ratio = drop_ratio
self.JK = JK
# add residual connection or not
self.residual = residual
if self.num_layers < 2:
raise ValueError("Number of GNN layers must be greater than 1.")
self.atom_encoder = AtomEncoder(emb_dim)
# List of GNNs
self.convs = torch.nn.ModuleList()
self.batch_norms = torch.nn.ModuleList()
for layer in range(num_layers):
self.convs.append(GINConv(emb_dim))
self.batch_norms.append(torch.nn.BatchNorm1d(emb_dim))
def forward(self, batched_data):
x, edge_index, edge_attr = batched_data.x, batched_data.edge_index, batched_data.edge_attr
# computing input node embedding
h_list = [self.atom_encoder(x)] # �Ƚ������ԭ������ת��Ϊԭ�ӱ���
for layer in range(self.num_layers):
h = self.convs[layer](h_list[layer], edge_index, edge_attr)
h = self.batch_norms[layer](h)
if layer == self.num_layers - 1:
# remove relu for the last layer
h = F.dropout(h, self.drop_ratio, training=self.training)
else:
h = F.dropout(F.relu(h), self.drop_ratio, training=self.training)
if self.residual:
h += h_list[layer]
h_list.append(h)
# Different implementations of Jk-concat
if self.JK == "last":
node_representation = h_list[-1]
elif self.JK == "sum":
node_representation = 0
for layer in range(self.num_layers + 1):
node_representation += h_list[layer]
return node_representation
����������ģ���еĹؼ����GINConv��
2.3 GINConv�Cͼͬ��������
��ԭ������ѧ����ʽ��ǰ���Ѿ����ܹ�,����ֱ������ʵ��:
import torch
from torch import nn
from torch_geometric.nn import MessagePassing
import torch.nn.functional as F
from ogb.graphproppred.mol_encoder import BondEncoder
### GIN convolution along the graph structure
class GINConv(MessagePassing):
def __init__(self, emb_dim):
'''
emb_dim (int): node embedding dimensionality
'''
super(GINConv, self).__init__(aggr = "add")
self.mlp = nn.Sequential(nn.Linear(emb_dim, emb_dim), nn.BatchNorm1d(emb_dim), nn.ReLU(), nn.Linear(emb_dim, emb_dim))
self.eps = nn.Parameter(torch.Tensor([0]))
self.bond_encoder = BondEncoder(emb_dim = emb_dim)
def forward(self, x, edge_index, edge_attr):
edge_embedding = self.bond_encoder(edge_attr) # �Ƚ�����ͱ�����ת��Ϊ�߱���
out = self.mlp((1 + self.eps) *x + self.propagate(edge_index, x=x, edge_attr=edge_embedding))
return out
def message(self, x_j, edge_attr):
return F.relu(x_j + edge_attr)
def update(self, aggr_out):
return aggr_out
��������ı�����Ϊ�����,���������Ҫ�Ƚ�����ͱ�����ת��Ϊ�߱��������Ƕ����GINConvģ����ѭ����Ϣ���ݡ���Ϣ�ۺϡ���Ϣ���¡���һ������
- ��һ��������
self.propagate()�����ĵ��ÿ�ʼִ��,�ú�������edge_index,x,edge_attr������������edge_index����״Ϊ[2,num_edges]������(tensor)�� - ����Ϣ���ݹ�����,���������ȱ����в��Ϊ
x_i��x_j����,x_j��ʾ����Ϣ���ݵ�Դ�ڵ�,x_i��ʾ����Ϣ���ݵ�Ŀ��ڵ㡣 - ����
message()����������,�˺��������˴�Դ�ڵ㴫�뵽Ŀ��ڵ����Ϣ,������Ҫ���ݵ���Ϣ��Դ�ڵ������߱���֮�͵�relu()�������������super(GINConv, self).__init__(aggr = "add")�ж�������Ϣ�ۺϷ�ʽΪadd,��ô�������һ��Ŀ��ڵ��������Ϣ����͵õ�aggr_out,������Ŀ��ڵ���м���̵���Ϣ�� - ����ִ����Ϣ���¹���,���ǵ���
GINConv�̳���MessagePassing��,���update()���������á�Ȼ������ϣ���Խڵ�����Ϣ�����м���Ŀ��ڵ���������Ϣ,�����update����������ֻ���������aggr_out�� - Ȼ����
forward����������ִ��out = self.mlp((1 + self.eps) *x + self.propagate(edge_index, x=x, edge_attr=edge_embedding))ʵ����Ϣ�ĸ��¡�
��ʵ����GINConvģ������Ƿ��ֻ����������AtomEncoder ��BondEncoder�ֱ������GINNodeEmbedding Moduleģ���GINConvģ����,��������������������
2.4 AtomEncoder�� BondEncoder
AtomEncoder ���ڵõ��ڵ�����ĵ�0��,Ҳ���ǽ��ڵ������������ת��,BondEncoder���ڽ�����ͱ�����ת��Ϊ�߱���,Ҳ�ǽ�����һ��ת��,�ɼ����������Ƶ����á��ڵ�ǰ��������,�ڵ�ͱߵ����Զ�Ϊ��ɢֵ,�������ڲ�ͬ�Ŀռ�,��ֱ�ӽ������ں���һ��ͨ��Ƕ��(Embedding),���ǿ��Խ��ڵ����Ժͱ����Էֱ�ӳ�䵽һ���µĿռ�,������µĿռ���,���ǾͿ��ԶԽڵ�ͱ߽�����Ϣ�ں���
import torch
from ogb.utils.features import get_atom_feature_dims, get_bond_feature_dims
full_atom_feature_dims = get_atom_feature_dims()
full_bond_feature_dims = get_bond_feature_dims()
class AtomEncoder(torch.nn.Module):
def __init__(self, emb_dim):
super(AtomEncoder, self).__init__()
self.atom_embedding_list = torch.nn.ModuleList()
for i, dim in enumerate(full_atom_feature_dims):
emb = torch.nn.Embedding(dim, emb_dim)
torch.nn.init.xavier_uniform_(emb.weight.data)
self.atom_embedding_list.append(emb)
def forward(self, x):
x_embedding = 0
for i in range(x.shape[1]):
x_embedding += self.atom_embedding_list[i](x[:,i])
return x_embedding
class BondEncoder(torch.nn.Module):
def __init__(self, emb_dim):
super(BondEncoder, self).__init__()
self.bond_embedding_list = torch.nn.ModuleList()
for i, dim in enumerate(full_bond_feature_dims):
emb = torch.nn.Embedding(dim, emb_dim)
torch.nn.init.xavier_uniform_(emb.weight.data)
self.bond_embedding_list.append(emb)
def forward(self, edge_attr):
bond_embedding = 0
for i in range(edge_attr.shape[1]):
bond_embedding += self.bond_embedding_list[i](edge_attr[:,i])
return bond_embedding
if __name__ == '__main__':
from loader import GraphClassificationPygDataset
dataset = GraphClassificationPygDataset(name = 'tox21')
atom_enc = AtomEncoder(100)
bond_enc = BondEncoder(100)
print(atom_enc(dataset[0].x))
print(bond_enc(dataset[0].edge_attr))
�����е�AtomEncoder��,���ڵ�����ӳ�䵽һ���µĿռ�:
full_atom_feature_dims��һ������list,�洢�˽ڵ���������ÿһά����ȡֵ������,��X[i]���ܵ�ȡֵһ����full_atom_feature_dims[i]�����,XΪ�ڵ�����;- �ڵ������ж���ά,��ô����Ҫ�ж��ٸ�Ƕ�뺯��,ͨ������
torch.nn.Embedding(dim, emb_dim)����ʵ����һ��Ƕ�뺯��; torch.nn.Embedding(dim, emb_dim),��һ������dimΪ��Ƕ�����ݿ���ȡֵ������,��һ������emb_dimΪҪӳ�䵽�Ŀռ��ά�ȡ��õ���Ƕ�뺯������һ������0С��dim����,���һ��ά��Ϊemb_dim��������Ƕ�뺯��Ҳ������ѵ������,ͨ�����������ѵ��,Ƕ�뺯�������ֵ�ܹ����ﲻͬ����ֵ֮��������ԡ�- ��
forward()������,���ǶԲ�ͬ����ֵ�õ��IJ�ͬǶ��������������Ӳ���,ʵ�������ڵ�ĵIJ�ͬ�����ں���һ����