Essentials for Class Incremental Learning-CVPR2021
Poster link:?https://www.youtube.com/watch?v=B2HJH5HGLPw
Three crucial components of a class-IL algorithm:
1) Memory buffer. 存储少量的范例样本
2) Forgetting constraint. 保持原有旧任务的知识(特征)。
3) Learning system. 平衡新旧任务,避免Overfitting和bais。.
常见的方法会针对以上三点做出改进。
面临的主要挑战:
1) Bias towards to new classes due to class-imbalance.
2) Catastrophic forgetting. Previous weights are overwritten when training new class datas.
研究的目的是为了找到这些挑战(现象)的内在原因,并加以解决。
?Overview
????????这篇文章改进了iCaRL,借鉴了前人改进的一些经验,用简单的方法提出了一个更强有力的base model。此后,在该模型上探索了一些正则化的手段,来缓解模型过拟合,有AutoAug、LabelSmooth / Mixup等。后来发现AutoAug和Self-Distillation是有效的。
- Combine softmax -> Seperate softmax,
- 挑选exemplar的方式由挑选nearest exemplars 改为random select.
- output cosine normalization.
Related Work里给出了一些近期工作改进的方向:
Exemplar selection / Forgetting-constraint / Bias removal methods.
Exemplar Selection.
- Herding heuristics. 选择离类中心最近的样本作为Exemplar set.
- 参数化范例样本,并和模型一起训练。
- 提高范例的存储效率,存储特征描述子而不是存储图片。
Forgetting constraint.(KD)
- Feature-level distillation.
- Embedding network to rectify semantic drift.
- Graph-based approach to retain the topology of the feature space.
Bias removal (class-imbalance / overfit)
- An extra bias-correction layer.
- Rectify the final activations.
- Cosine normalization in the last layer.
- Finetune on a balance task.
方法上:
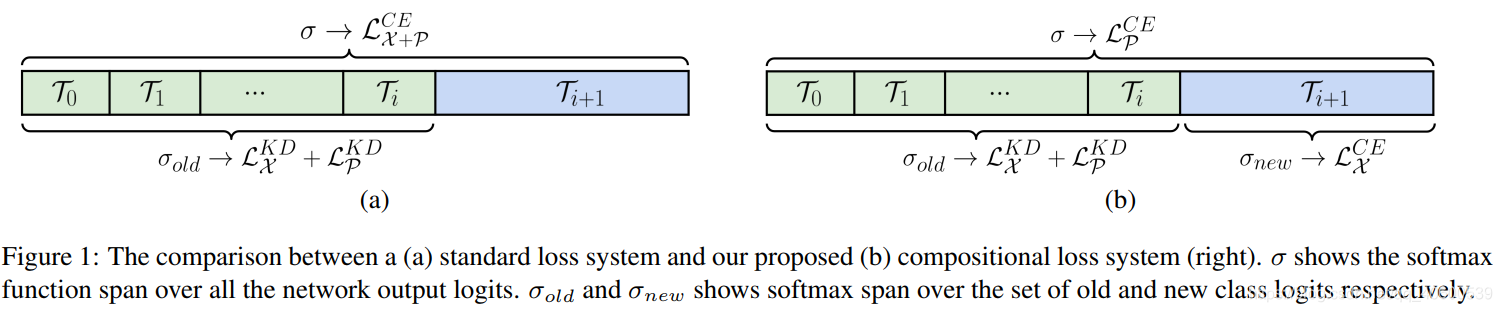
是新样本在旧类别上的蒸馏损失。
是exemplars set(包括新类别和旧类别)的蒸馏损失。
是新样本在新类别上的交叉熵损失。
是exemplars set在全部类别上的交叉熵损失。
1)Inter-task。exemplars set包括新类别和旧类别,相当于一个类均衡操作,有助于减少inter-task bias。
2)Intra-task。使得新类别在计算交叉熵损失时,能够减少对旧类别的干扰,使得各个task间能够更独立地学习分类器,共享特征提取器。
我认为本文的主要改进就是以上两点,非常简单,但是工作扎实,结果可观,写作非常充实,这是我觉得这篇能中顶会的重要原因。
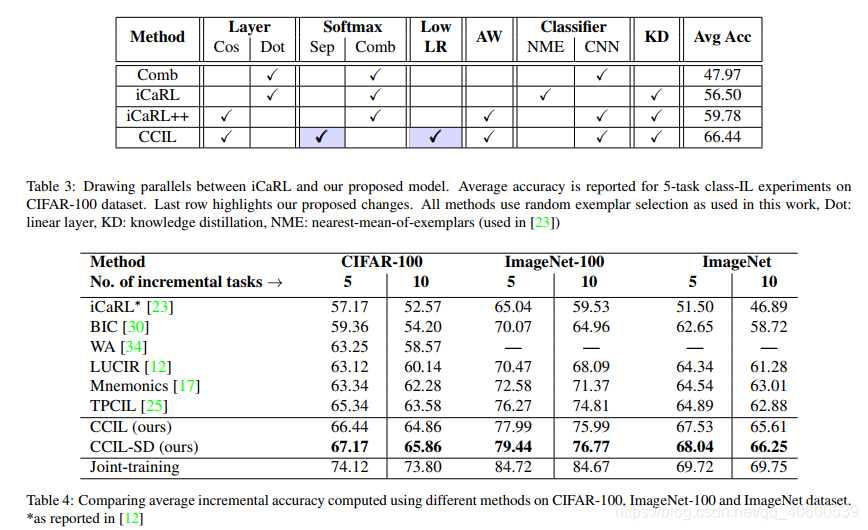
除此之外,本文还有一些贡献:
1)提出Class-IL任务的一些评价指标,用来评价forgetting, feature rentention,secondary information等等。Forgetting的一些指标在IL上是很有必要的,可以Avg Acc由于避免初始任务精度过高带来的不客观评价。
2)对比了一些分类任务常用的trick在IL任务上是否work。
? ? ? ? work: self-distillation / Auto Aug(缓解过拟合)/ small incremental lr
? ? ? ? not work : label smooth / mix up
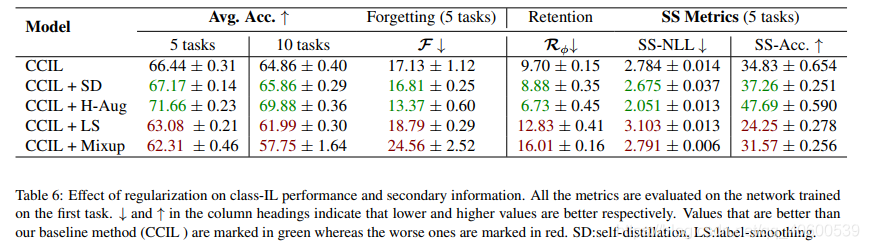
一些思考/疑惑:
1)本文的exemplars set包括新类别和旧类别。相比于此前其他replay-based的方法exemplars set只有旧类别,相当于增加了新类别的图像数量,但其实这样在实际训练中并没有起到类均衡的作用,反而使得新旧类别更加不均衡。
? ? ? ? 如果要解决类不均衡,感觉还是在exemplars set上做fine-tune比较好。
????????不过我觉得这个exemplars set增加新样本进行训练也有一个好处,就是增加模型在新类别训练时候,sample from new class exemplars 的采样频率,这样在下次训练的时候,使用这些样本作为exemplars可以更好地维持原有feature。
2)旧任务样例的Overfitting / 新旧样本的类别不均衡(数据上、模型bias上)是可行的改进方向。