1、seq2seq
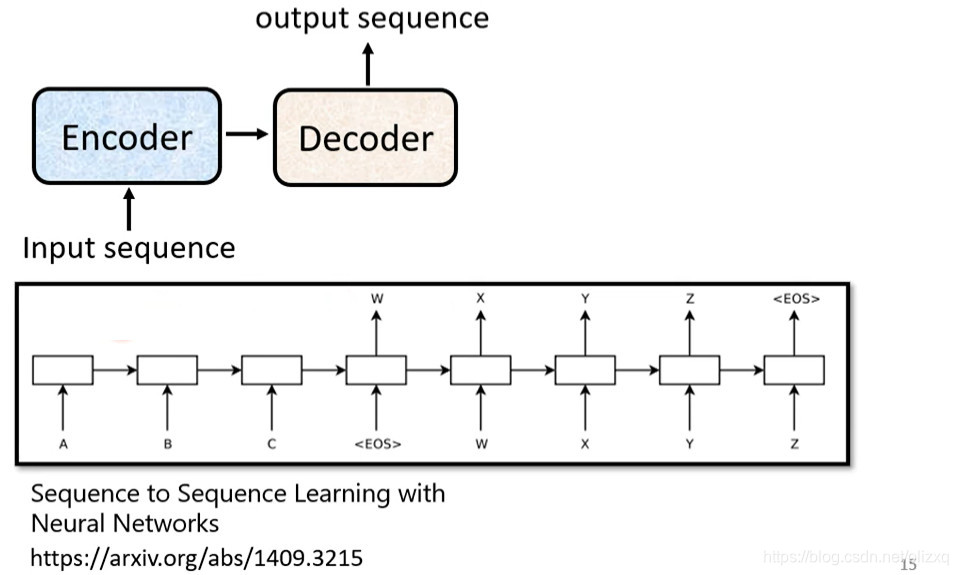
seq2seq 是一个 Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列, Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。
这个结构最重要的地方在于输入序列和输出序列的长度是可变的,可以用于翻译,聊天机器人,句法分析,文本摘要等。
seq2seq的结构如下:
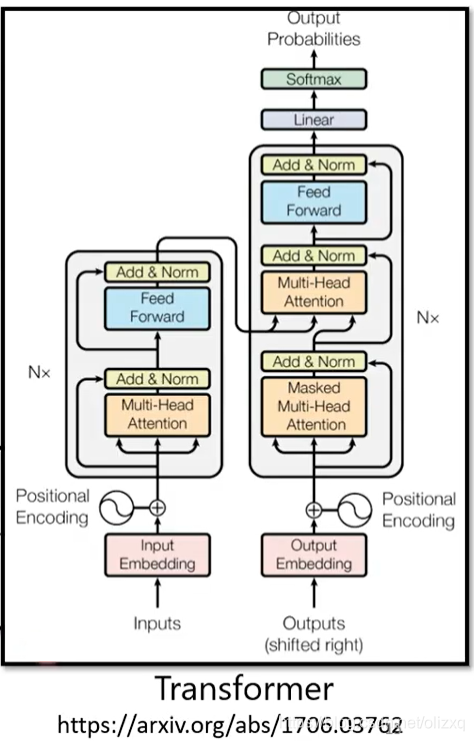
当然,目前说到seq2seq,最为人所熟知的就是Transformer,Transformer的结构如下:
2、Encoder
我们先看一下Encoder部分,Encoder就是给一排向量然后输出一排向量,其实这个工作很多模型都可以做,比如self-attention,RNN,CNN,这里我们只关注seq2seq的Encoder和Transformer中的Encoder:

我们将Encoder部分拆开看一下,如下图。图中每个Block不只是一层layer,可能是多层layer,一串向量进入Block,经过一系列转换然后输出一串向量,经过多个Block处理后得到最终的输出。

上图只是做个简单的演示,实际上Encoder部分做的事情要更复杂一些,如下:
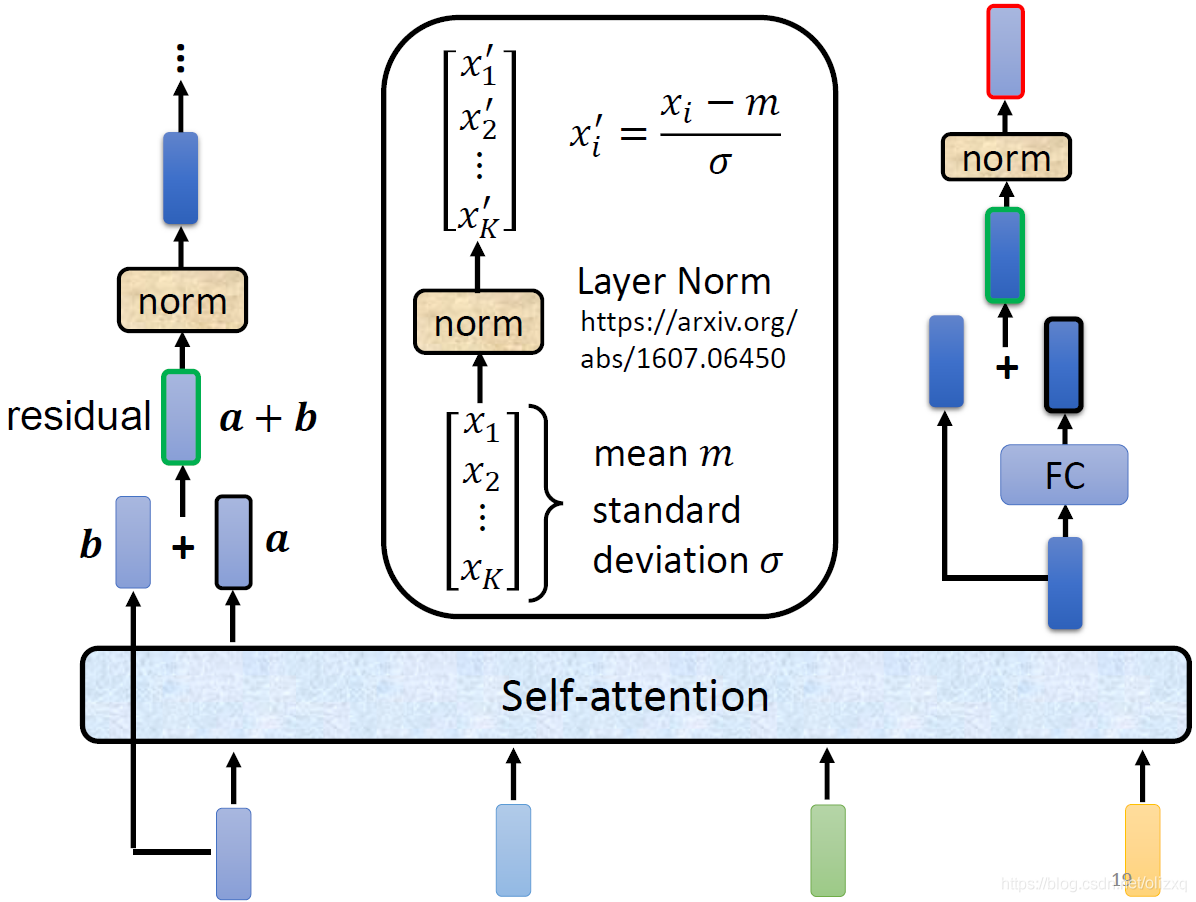
Encoder所做的处理如下:
- 输入向量b经过self-attention处理后得到向量a,a并没有直接作为output,而是与输入向量b加起来得到新的output,这样的网络架构就是residual connection;
- 接下来的output要经过Normalization,不过这里的Norm不是Batch Norm,而是Layer Norm;
- Norm后的输出经过FC network处理后,与输入向量再做residual;
- 上一步residual后的结果还要再做一次norm,得到的输出才是Encoder中一个Block的输出。
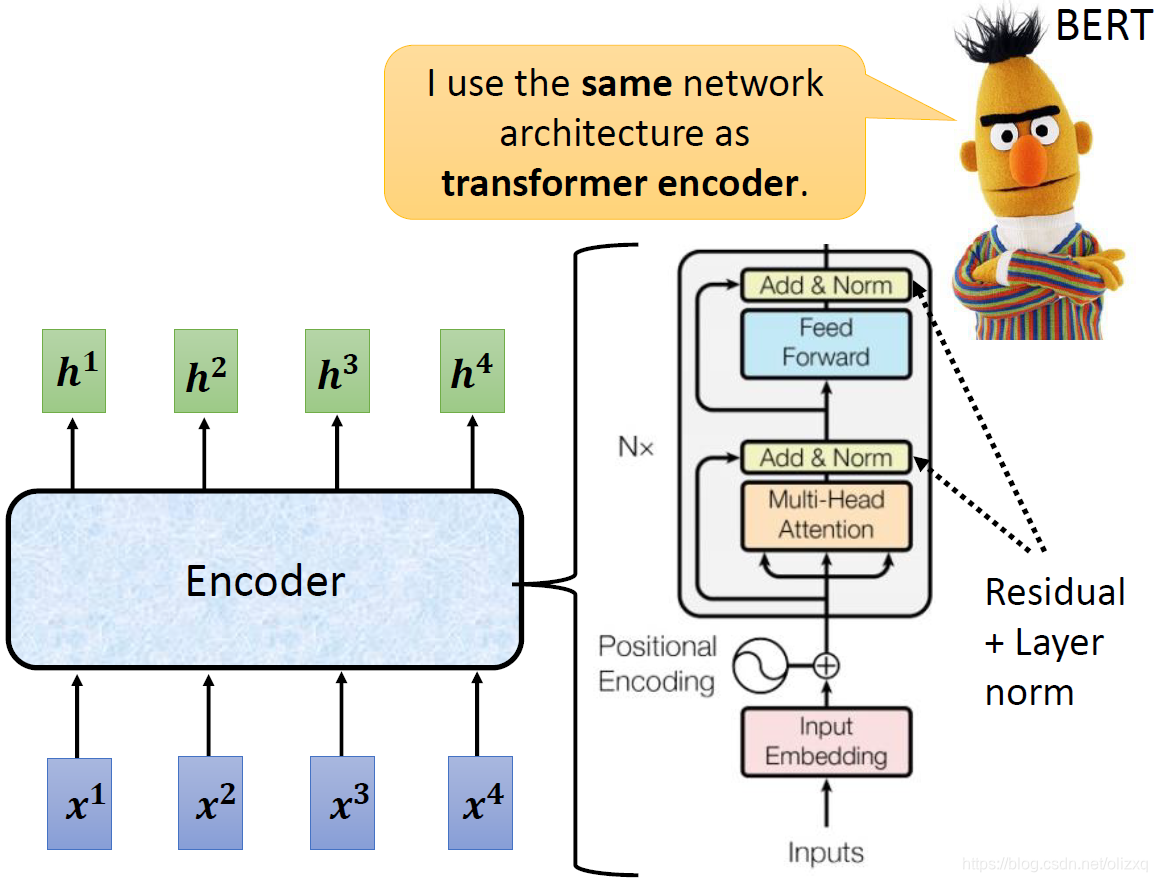
将上述处理与Transformer的Encoder部分做个比较,我们会发现Transformer中的Add&Norm就是上述处理中的Residual+Layer norm,现在最常用的BERT也使用了和Transformer Encoder相同的网络架构。
3、Decoder
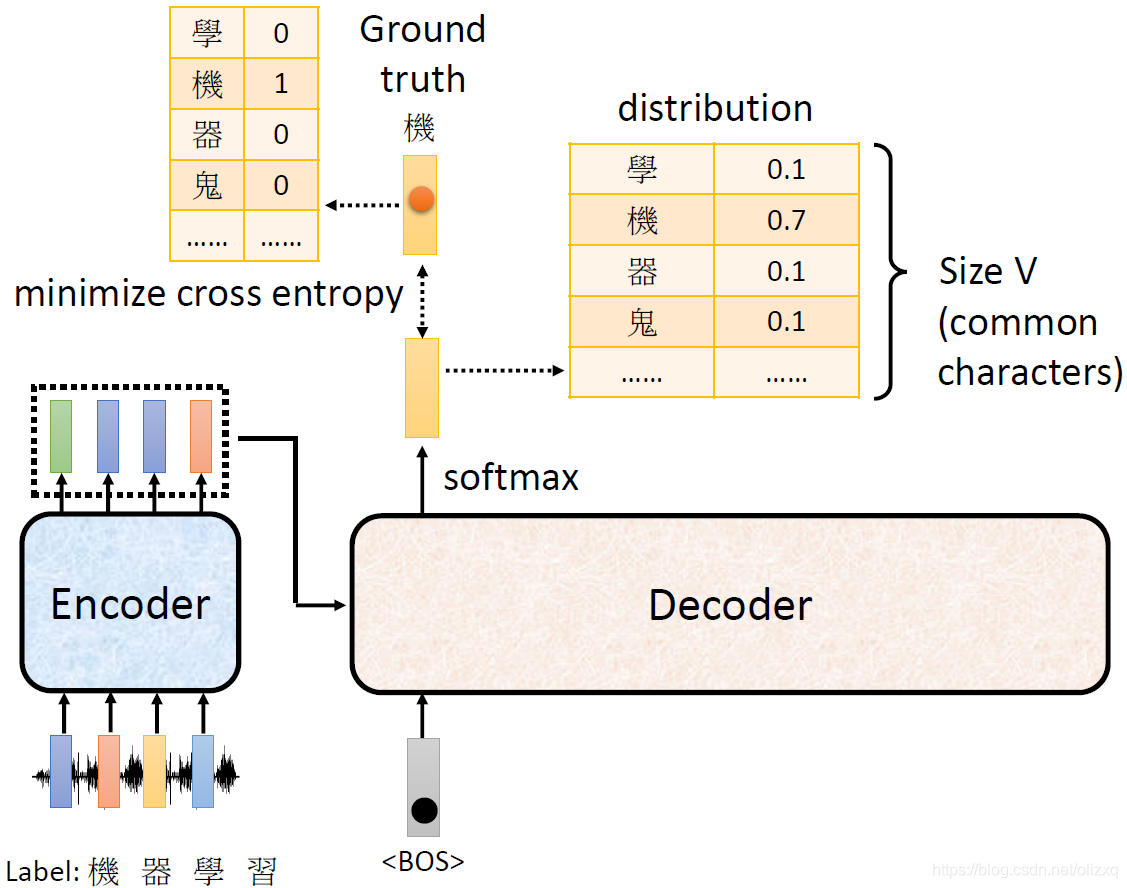
以语音辨识为例,当我们给定一个开始标志,Decoder的输出结果经过softmax,会得到字典中所有字的概率分布,我们选择概率最大的一个字作为输出。
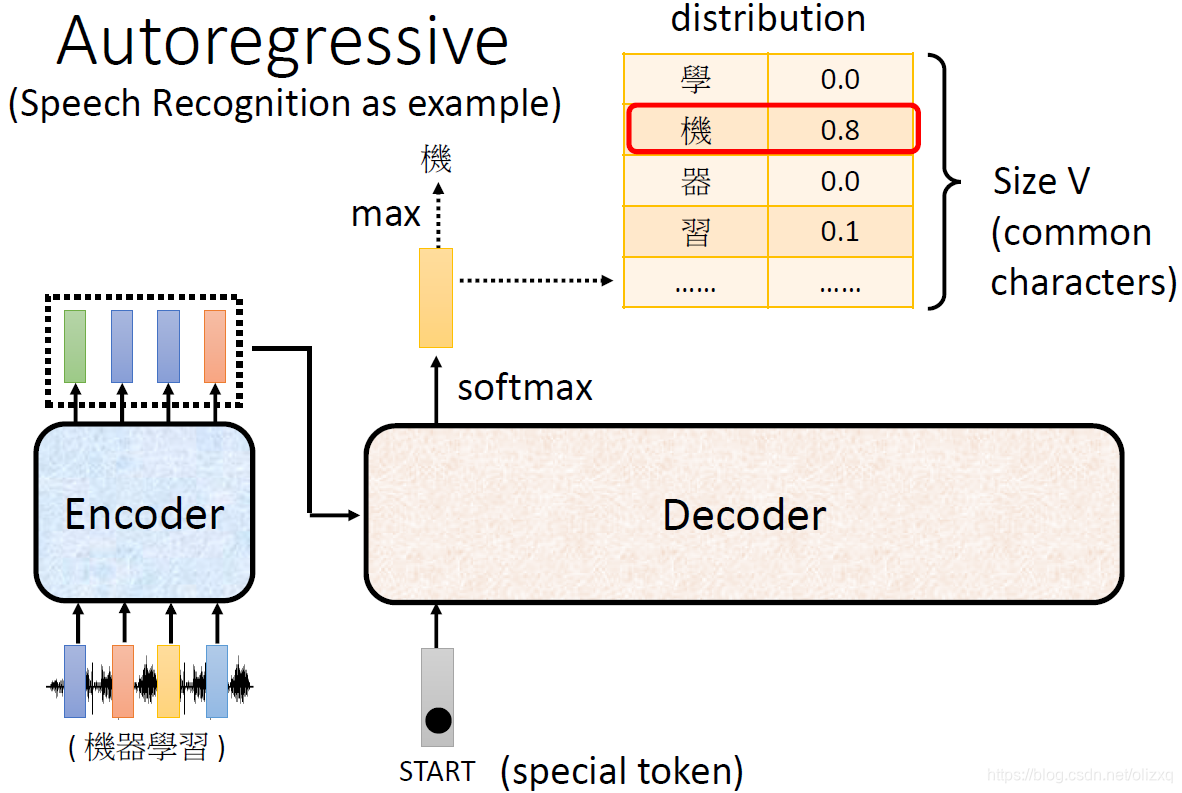
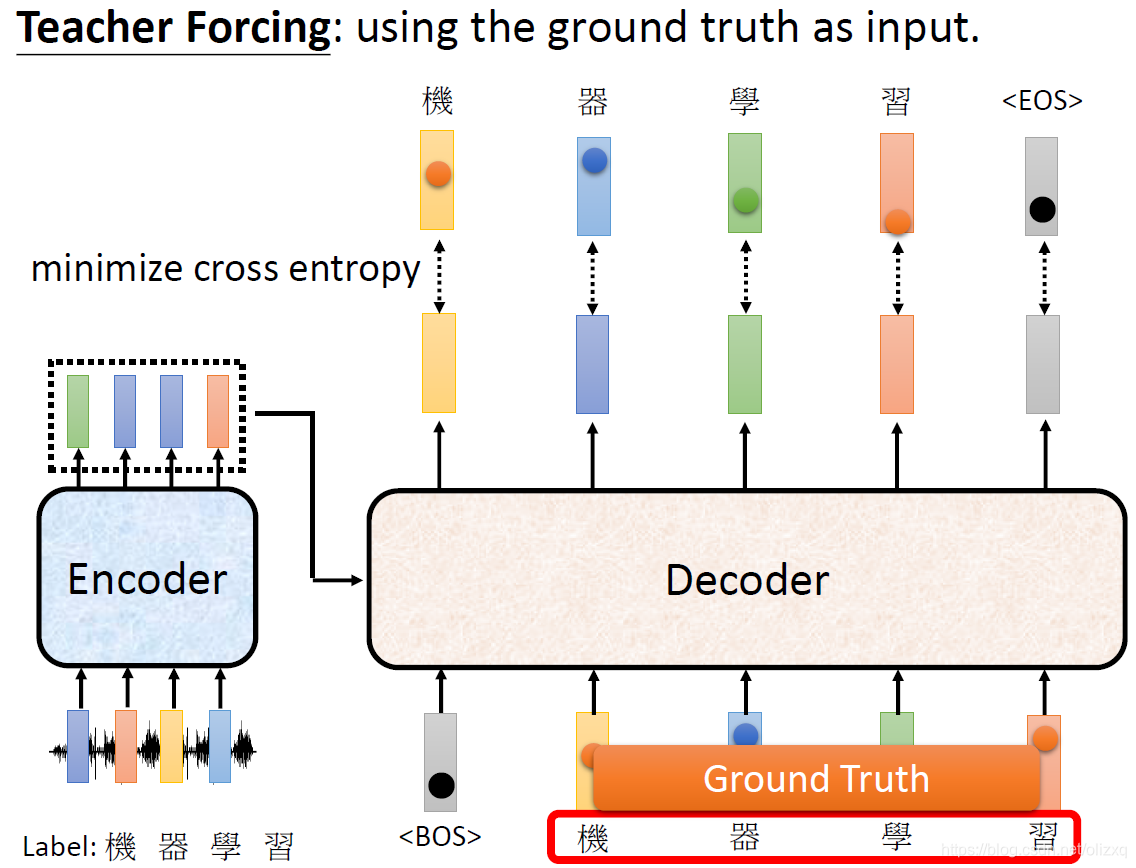
然后将这个字作为第二个Input给到Decoder,选择输出概率最大的字,这样依次下去就可以得到所有的输出结果:
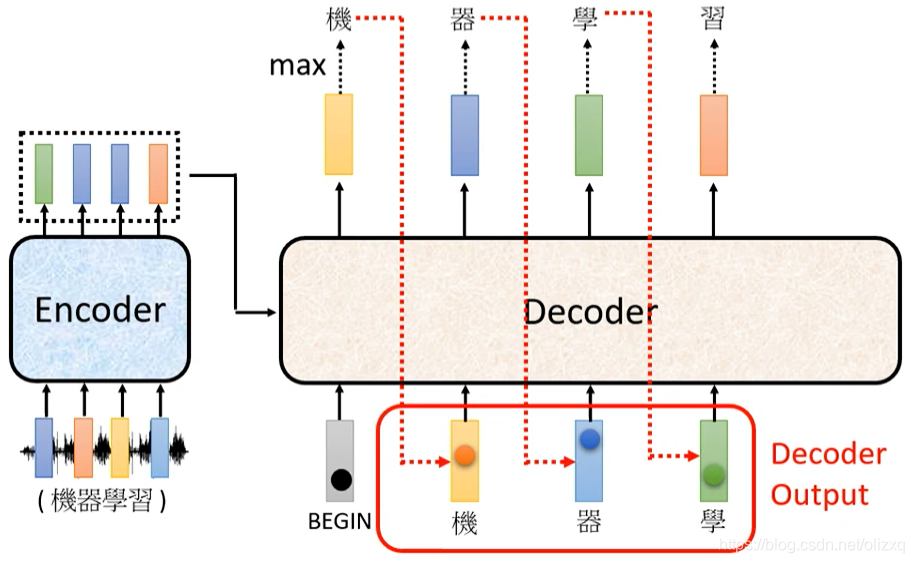
我们先忽略encoder的输入部分,看一下decoder的结构,如下:
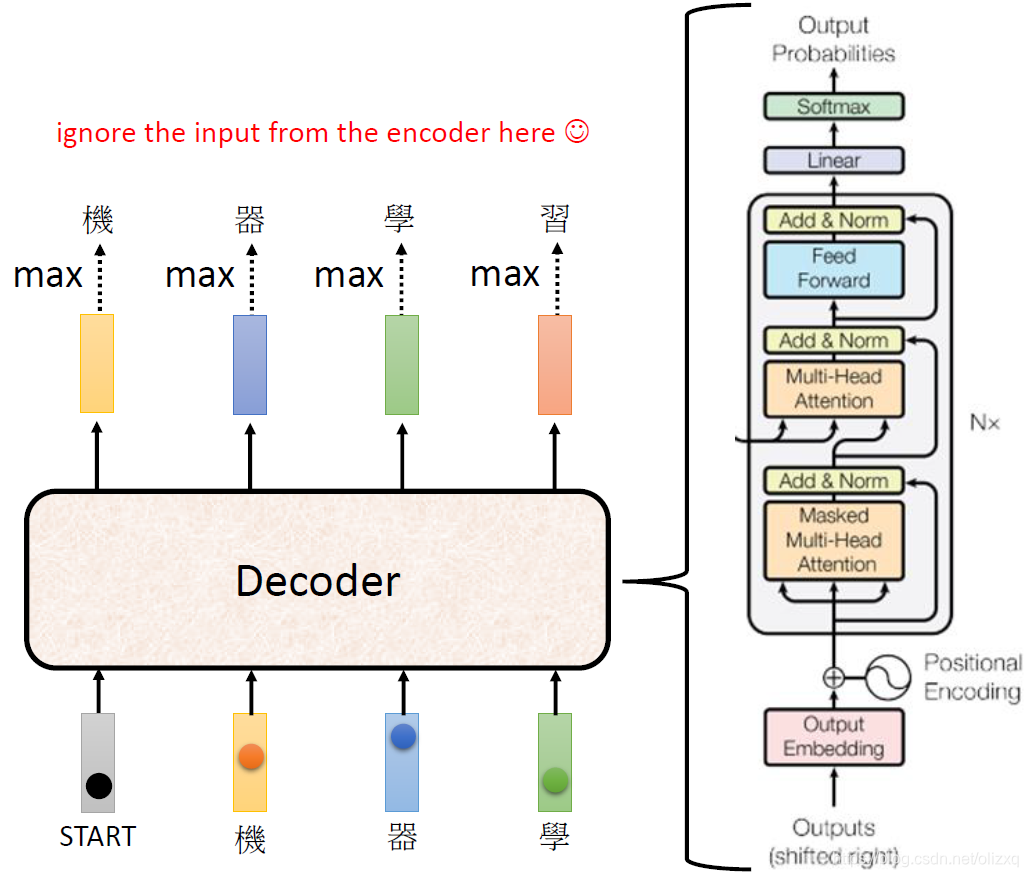
下面我们比较一下encoder和decoder的结构,我们会发现,如果将decoder的中间部分遮起来,encoder和decoder并没有多大差别,只是decoder的Multi-Head Attention部分多了个masked。
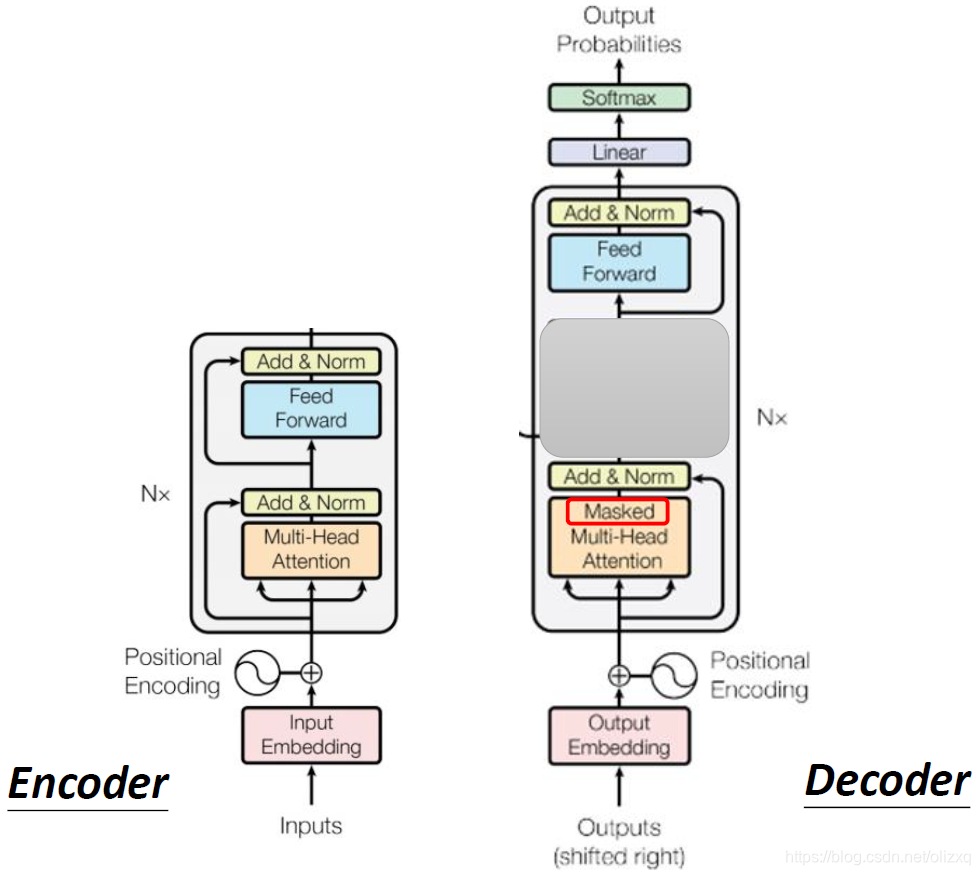
masked是什么含义呢?
对于self-attention,每一排输出向量都要看过完整的输入之后才做决定,当我们把self-attention转为Masked self-attention之后,那么我们就不能再看右边的部分了,比如产生 b 1 b^1 b1的时候,我们只能考虑 a 1 a^1 a1的信息,不能再考虑 a 2 , a 3 , a 4 a^2,a^3,a^4 a2,a3,a4。

更具体一点,当我们要产生 b 2 b^2 b2的时候,我们只拿第二个位置的query去跟第一个位置的key和第二个位置的key去计算attention,第三个位置和第四个位置就不用管。为什么我们要去做masked呢?这是因为在Decoder的时候,我们是没有后面的信息的,所以我们只能考虑左边输入的信息。
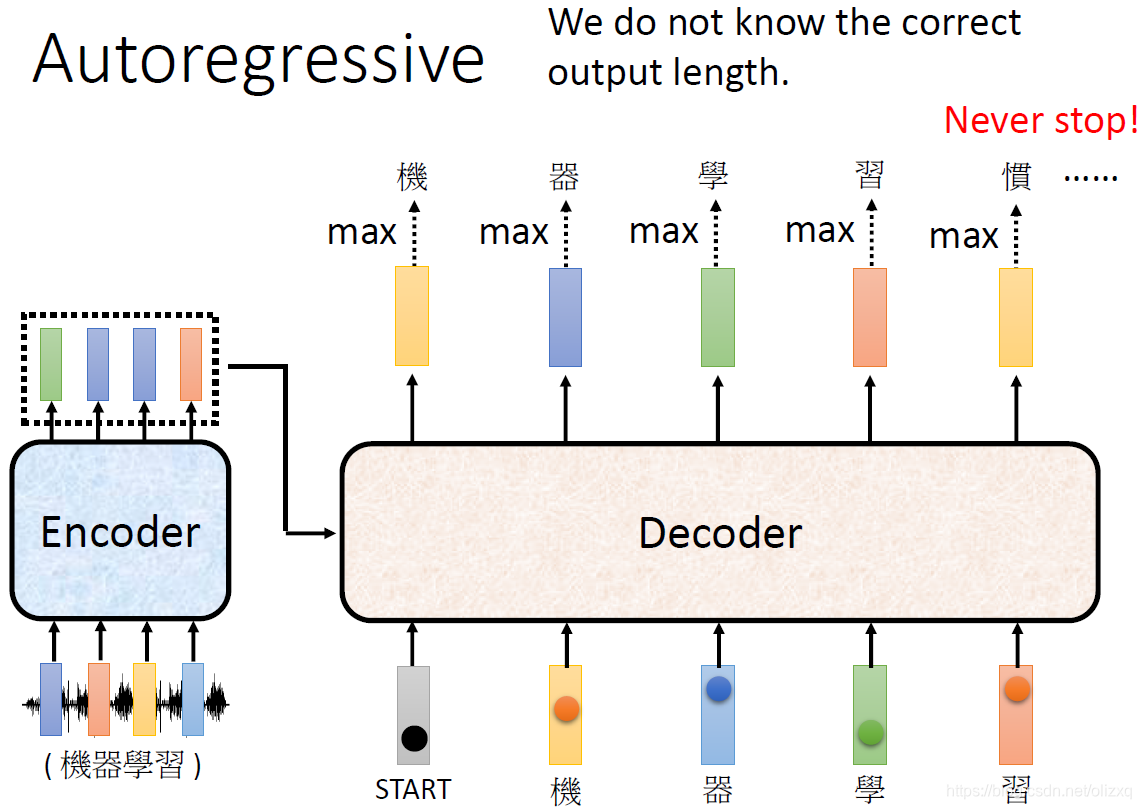
接下来,还有一个非常关键的问题,Decoder必须自己决定输出的Sequence的长度,实际我们没有办法知道输出的Sequence的长度,如果按照之前的处理,这个Decoder的过程会一直持续下去,没有办法停止。
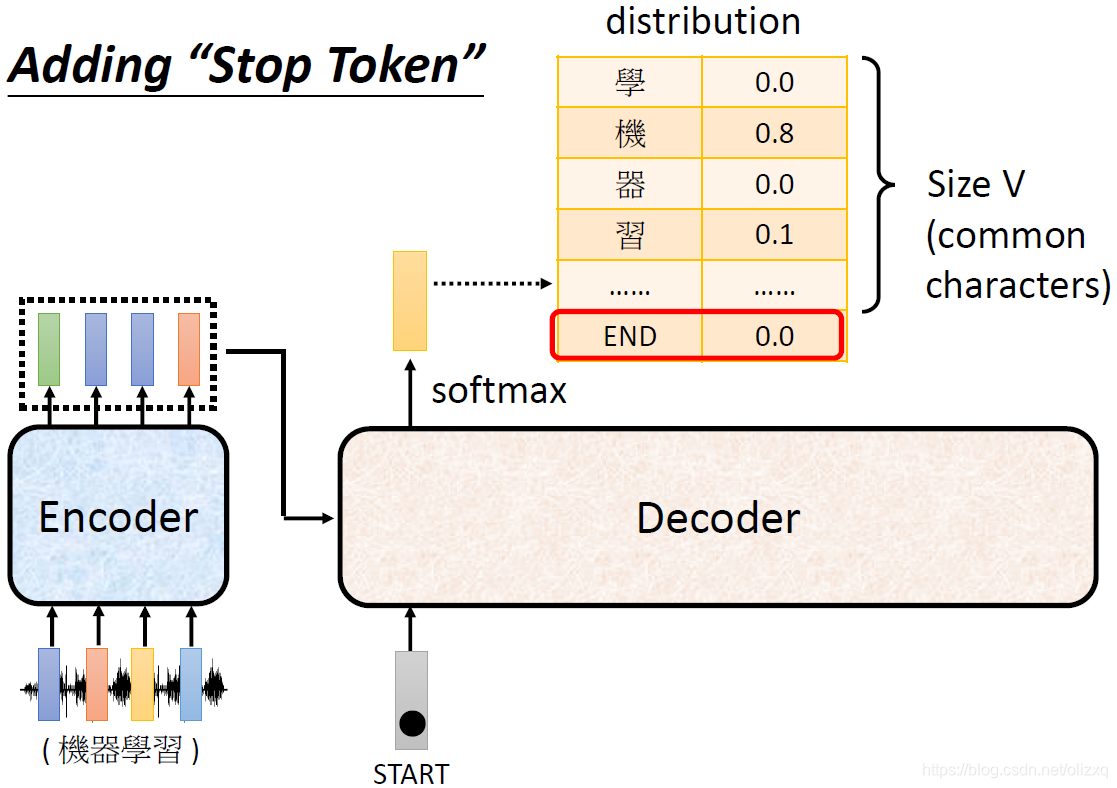
因此,我们需要在字典中加入一个特殊的符号,作为“结束”符:
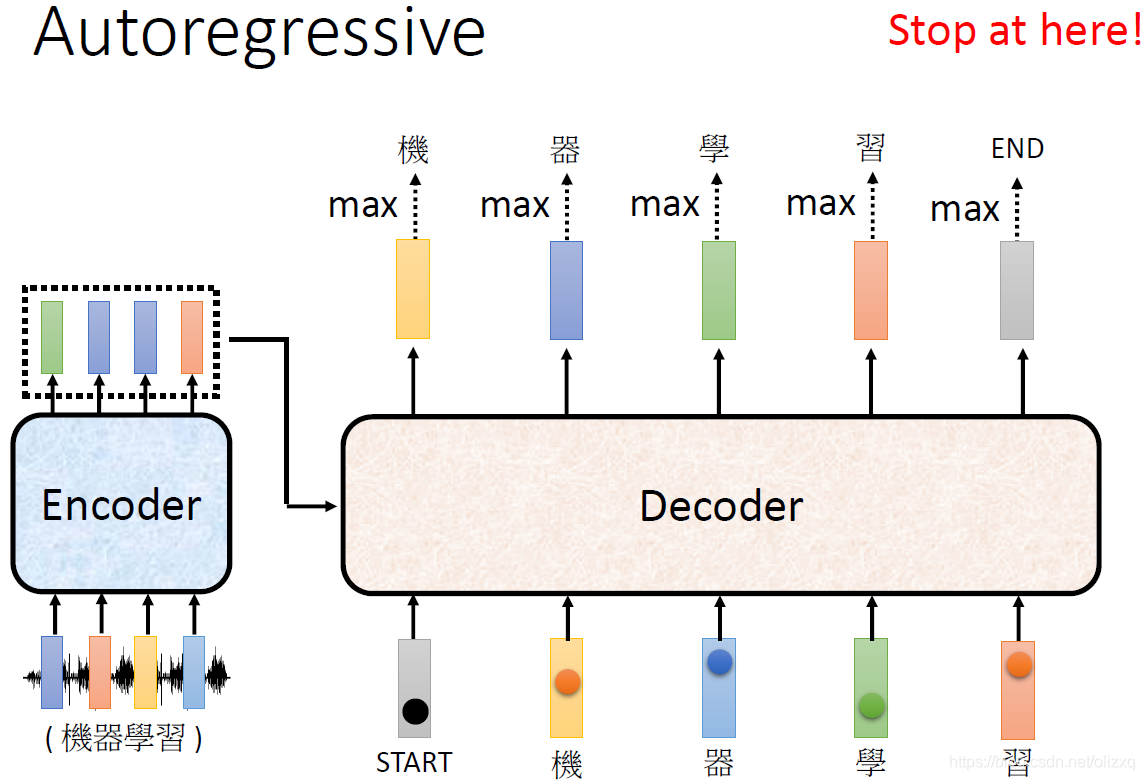
这样的话,在Decoder接收“机器学习”四个输入后,会输出一个结束符,标志着语音识别结束。
4、Encoder-Decoder
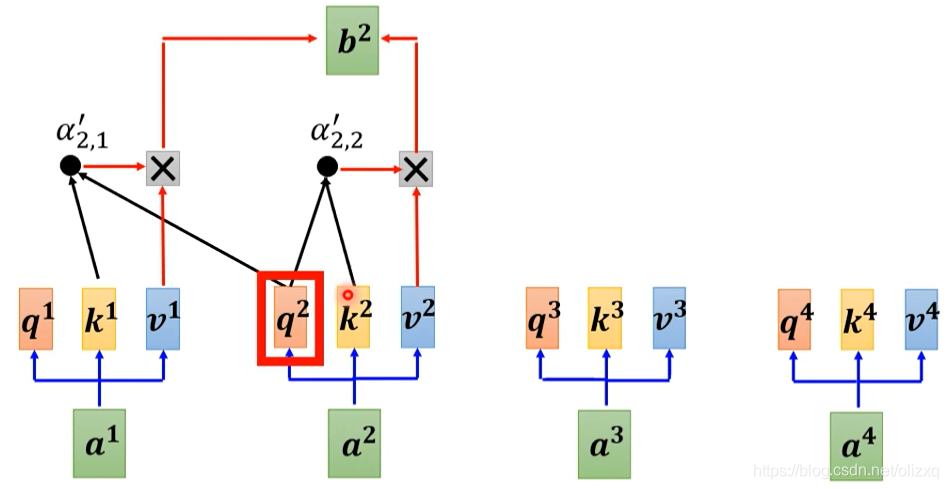
下面我们来研究encoder和decoder连接的部分cross attention:
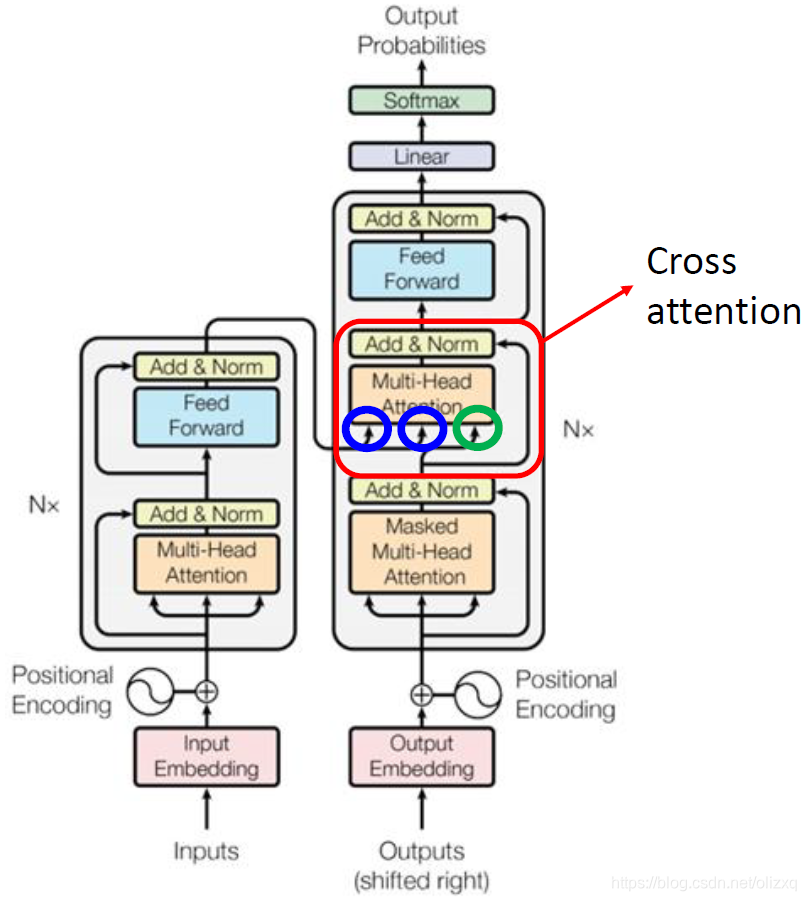
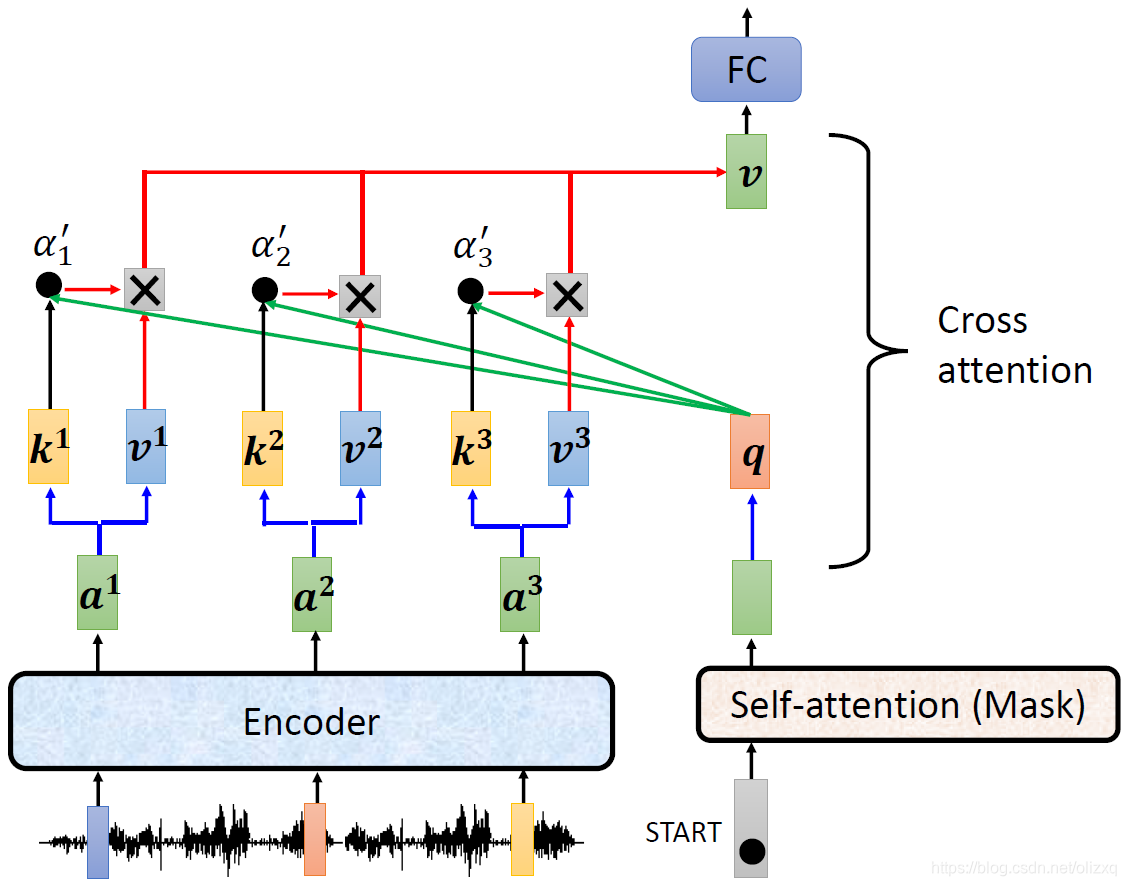
cross attention的处理如下,其实decoder就是凭借着产生一个q,去encoder那边抽取信息出来,当做接下来decoder的FC network的input。
5、train
在训练的时候,我们希望每一个输入的预测结果与实际结果之间的cross entropy越小越好,其实就是分类问题,使预测结果与实际结果的cross entropy尽可能小。
以上为李宏毅老师讲解Transformer的过程,比较通俗易懂,并且这篇英文博客对Transformer介绍得非常详细,配合食用更佳。