目录
知识点
1. sigmoid函数
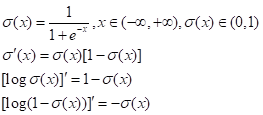
2. 逻辑回归

3. 统计语言模型
统计语言模型是用来计算一个句子的概率的概率模型。

条件概率的计算

4. 考虑总体语料库的语言模型
综合所有语料库,利用最大似然,目标函数为:

下面讨论两种方法来计算上面的条件概率参数:n-gram模型和神经概率语言模型。
- n-gram模型
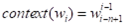
- 神经概率语言模型
实际应用中常采用最大对数似然,即目标函数为:
为了求解(3.4),用神经网络构造F函数: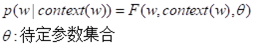
下面阐述一下怎么获取F函数


总结
总结:
1. n-gram需要数出语料库的词组的个数,计算量大,每个词语组合出现的次数都要数,F函数的方法只要求出参数,即得出F的函数表达式,便可直接计算。
2.神经概率语言模型,词语之间的相似性可以通过向量体现,n-gram计算不了词向量。
3.函数的方式可以使得相似位置的词对应的词向量相同,而相似位置的词的词义一般是相似的。
4.词向量自带平滑功能,不像n-gram还需要额外处理:
,这里需要平滑技术处理。
5.函数时,对于语料库中一个给定的句子,词个数不足n-1时,此时可以人为的添加1个或者几个填充向量,他们也参与训练过程。
5. 词向量的理解
词向量在整个神经概率语言模型中扮演的角色:
训练时是用来帮助构造目标函数的辅助参数,训练完成后,只是语言模型的一个副产品。
词向量分类:one-hot表示,分布式表示
分布式表示:通过训练将某种语言中的每一个词映射成一个固定长度的短向量,向量中有大量非0分量,把词的信息分布到各个分量中去了。
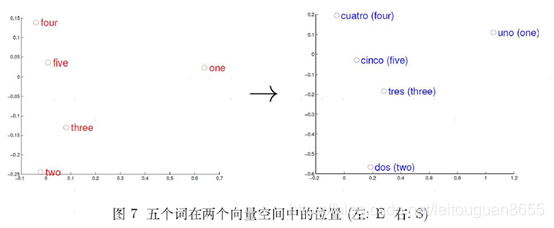
- 举例:在向量空间内,不同的语言享有许多共性,只要实现一个向量空间向另一个向量空间的映射和转换,语言翻译即可实现,英语和西语间转换后,用主成分分析降维,使每个词只含有两个维度,然后分别在二维平面上描出这五个点,五个词在两个向量空间中的相对位置差不多,说明两种不同语言对应向量空间结构之间具有相似性,也说明了用距离刻画词之间相似性的合理性。
word2vec数学原理
两种训练方法和两个算法可以组合成四种方式。

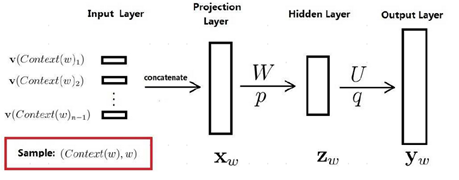
1. CBOW模型的网络结构示意图
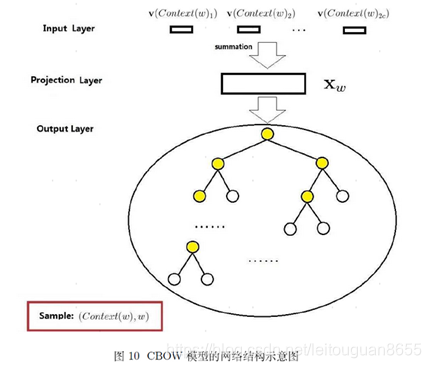
符号说明:

2. 基于HS的CBOW目标函数及求解
这一块主要讲的是构造目标函数,求解输出层中哈夫曼树中结点的向量,在求出最优向量时,词向量作为副产品也被求出。


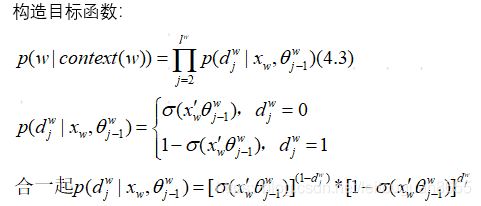

总结

举例子:


3. skip-gram模型的网络结构示意图
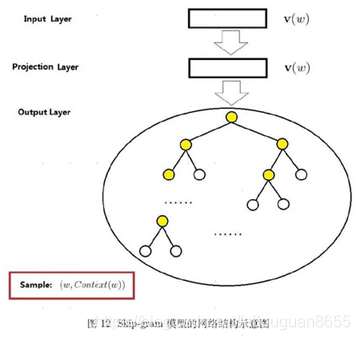
4. 基于HS的skip-gram目标函数及求解
