[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (12) �� ����ѵ������ܹ�
����Ŀ¼
0x00 ժҪ
Horovod ��Uber��2017�귢����һ������ʹ�õĸ����ܵķֲ�ʽѵ�����,��ҵ��õ��˹㷺Ӧ�á�
��ϵ�н�ͨ��Դ��������������˽� Horovod��������ϵ�е�ʮ��ƪ,����horovod ���ʵʩ����ѵ����
����ѵ��ʹ��Horovod�߱�����ʱworker������̬����,������Ҫ���� ���� ֻ�ǴӴ洢�е�checkpoint�ָ�ѵ����
��ϵ������������������:
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� Horovod �� (1) ����֪ʶ
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (2) �� ��ʹ���߽Ƕ�����
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (3) �� Horovodrun��������ʲô
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (4) �� ������� & Driver
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (5) �� �ںϿ��
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (6) �� ��̨�̼ܹ߳�
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (7) �� DistributedOptimizer
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (8) �� on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (9) �� ���� on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (10) �� run on spark
[Դ�����] ���ѧϰ�ֲ�ʽѵ����� horovod (11) �� on spark �� GLOO ����
0x01 ����
1.1 �����
����˼����,Horovod Ŀǰ������ʲô����?
- ���Զ���������(Auto Scale)��
- ��Ϊ������ԴҲ�����е��Ե���,����Ӧ�ÿ��ǵ������Ⱥ��������ô��?�����������ô?����״̬Ӧ����:��ѵ�������п����Զ����ӻ�����worker������������worker�����仯ʱ,�����ж�ѵ������,����ƽ�����ɡ�
- ĿǰHorovod������Դ�����������ִ�С�����һ����Ҫ100��GPU,��ʱֻ��40��GPU��λ,�����������,Horovod��ֻ�ܵȴ�,���������е�40��GPU�������������Ͽ�ʼѵ��,�Ӷ������ٿ�ʼģ�͵�����
- ��Դ��ԣʱ,Horovod ���Զ����ӽ��̼���ѵ��������������,������״̬��,HorovoidӦ��������40��GPU����һ����������ѵ��,�������60����GPU��λ�˾��Զ���̬����,�Ӷ�����һ�� epoch ��ʼ����100��GPU�����µĻ���ʼѵ��;
- û���ݴ�����(Fault Tolerance)��Ŀǰ���ijһ���ڵ�ʧ��,����ѵ����ʧ��,�û�ֻ�ܴ�ͷ��ʼѵ�����������֧�� auto scale,����һЩ֮ǰ½������� checkpoint,��Horovod��������ѡȡһ���ýڵ��������worker,������ʣ�µĽڵ㹹��һ��������ѵ����
- ���Ȼ��Ʋ������
- ����ѧϰѵ������һ��ʱ��ϳ�,ռ��������,��Horovod����ȱ�ٵ�������,��֧�ֶ�̬���� worker,��֧�ָ����ȼ���ռʵ������˵���Դ����ʱ,������Ϊ���������ȼ�ҵ���ڳ���Դ, ֻ�ܵȴ������Լ�������ֹ���߳�����ֹ��
Ϊ�˽�����ϼ�������,���ǻ�˼���ܶ���������弼�������ϸ��,�����������г���:
- ��ʱ���� checkpoint?��һ�����Ǻ��ʵ�?ÿһ�� epoch ֮���Զ�����?�������û����п���(���������������õ�)?
- ��δ� checkpoint�ָ�?
- checkpoint��Ҫ�洢��Щ����,��,����horovod��˵,��Щ״̬�DZ����?
- ��μ��� worker �Ĺ������?��ô�жϻ�����������?����ֻ����������ż�����µ���ô��?
- ��Ҫ����һ��֪ͨ����;
- ���֪����Ⱥ�ĸ�����Դ?��η��ֿ��ýڵ�?
- ��ι����µ�ͨ�Ż� ring?
- ���������ring,����һ�� master ���?����ʹ������ gossip ������Э��?
- �Ƿ������ȼ�����,�������Գ�����ù�����Ⱥ��Դ���е���Դ��
- �� worker ��ô�� sync?
- ԭ�е�active worker �ڵ���ô����?
- ������� worker �ڵ���ô����?
- rank 0 ��ô�㲥?
�����ڱ����Լ�������ƪ�ķ��������Ž����Щ���⡣
ע:HorovodĿǰ�ĵ��Ȼ�����Ȼ�����,��֧����ռ��
1.1 ��ɫ
Horovod �ڵ����Ķ�� GPU ֮�ϲ��� NCCL ��ͨ��,�ڶ��(CPU����GPU)֮��ͨ�� Ring AllReduce �㷨����ͨ�š�Horovod �ĵ���ѵ����ָ����ĵ���ѵ����
Horovod ����ѵ����������ɫ:driver�� worker��driver ���������� CPU �ڵ���,worker ���̿��������� CPU �ڵ���� GPU �ڵ�֮�ϡ�
Driver ���̵�������:
- ���� Gloo ���� workers ����һ�� AllReduce ͨ�Ż�,����˵��ͨ����Driver ��������幹��ͨ�Ż�,�����ṩ������Ϣ,�Ӷ�worker���Խ�������
- Driver ������Ҫ�� Gloo ����һ������ KVStore �� RendezvousServer,���� KVStore ���ڴ洢ͨ������ÿ���ڵ�� host �� ������ͨ�Ż��������� rank ����Ϣ��
- ��� RendezvousServer ������ Horovod �� driver �����driver �����õ����� worker ���̽ڵ�ĵ�ַ�� GPU ������Ϣ��,�Ὣ��д��RendezvousServer �� KVStore ��,Ȼ�� worker �Ϳ��Ե��� gloo ������ RendezvousServer ����ͨ�Ż���
- Driver ���� worker �ڵ�������/���� worker ���̡�
- Driver ����ϵͳ����״̬��
worker ����ѵ����ģ�͵�����
- ÿ�� worker �ڵ���� RendezvousServer �����������õ��Լ����ھӽڵ���Ϣ,�Ӷ�����ͨ�Ż���
- �����ͨ�Ż�֮��,ÿ�� worker �ڵ���һ�����ھӺ�һ�����ھ�,��ͨ�Ź�����,ÿ�� worker ֻ�����������ھӷ�������,ֻ������ھӽ������ݡ�
����������������:
+-------------------------------+
| Driver |
| |
| +------------------------+ |
| | RendezvousServer | |
| | | |
| | | |
| | host1, host2, host3 | |
| +------------------------+ |
+-------------------------------+
^ ^ ^
| | |
| | |
+-------------+ | +--------------+
| | |
| | |
| | |
v v v
+--------+----+ +-------+------+ +----+--------+
| Worker | | Worker | | Worker |
+------> | +------> | +---------> | | +------+
| | host1 | | host2 | | host3 | |
| +-------------+ +--------------+ +-------------+ |
| |
| |
| v
<--------------------------------------------------------------------------------+
����������ϸ�����¸������֡�
1.2 �ݴ�����
Horovod ���ݴ������ǻ��� gloo ��ʵ�ֵ�,���ڴ�����˵,����Ա���Ϊ��һ������������
Gloo �����Dz�֧���ݴ��ġ����ڶ�worker֮����������оۺϲ���ʱ��,���ijһ��workerʧ��,��gloo���ᴦ���쳣,�����׳��쳣�����˳�,��������worker���ᱨ�쳣�˳���
Ϊ�˲���ijһ�� worker ��ʧ�ܵ�������ѵ���˳�,Horovod ��Ҫ�������湤��:
- �����쳣Ӱ��������ҵ��Horovod ���벶�� gloo �׳����쳣,���Ǿ�����һ��python�����쳣���ơ�
- Worker �ڲ����쳣֮��Ὣ�쳣���ݸ���Ӧ�� Python API ����,API ͨ���ж��쳣���;����Ƿ����ѵ����
- ����쳣��Ϣ�а��� ��HorovodAllreduce������HorovodAllgather�� ���� ��HorovodBroadcast�� �ȹؼ���,˵���������ij��worker�������µ�ͨ��ʧ��,�����쳣��Horovod��Ϊ�ǿ��Իָ��ġ�
- ����ʧ�ܵ�worker,ʹ��ʣ�����worker����ѵ����
- �������� worker ֹͣ��ǰ��ѵ��,��¼��ǰģ�͵����IJ�����
- ��ʱgloo��runtime�Ѿ���������,ͨ�Ż��Ѿ�����,����ʣ��� worker ֮��������� AllReduce ������
- Ϊ�˿��Լ���ѵ��,Horovod Driver �����³�ʼ�� gloo,����һ���µ� rendezvous server,Ȼ���ȡ���� worker ����Ϣ,������Щworker����µ�ͨ�Ż���
- ���µ�ͨ�Ż�����ɹ���,rank 0 worker ����Լ���ģ�㲥������������worker,������ҾͿ�����һ��������,�����ϴ�ֹͣ�ĵ�����ʼѵ����
1.4 ��ػ���
�ݴ������DZ�������,��ػ��ƾ�������������
���Ծ���ζ�ŷֲ�ʽ��Ⱥ��״̬����ʱ�����仯,�� Horovod �����ͷֲ�ʽ��Ⱥ��û�й���,������Ҫ��һ���ⲿ;������ Horovod ��ʱ���ռ�Ⱥ״̬��
����ⲿ;�������û���Ҫ�� Horovod �����������ṩһ�����ֽű� discovery_host��discovery_host ���û���д,�����ֿ��õ� worker �ڵ�������Ϣ��
Driver������֮��ᶨ�ڵ������ bash �ű����Լ�Ⱥ���,��worker�����仯ʱ,discover_host �ű��᷵�����µ�worker״̬,Driver ���� discover_host �ķ���ֵ�õ� worker �ڵ���Ϣ:
- ���Driver������workerʧ��,�Ͳ����쳣,���ݴ���worker��Ϣ������ RendezvousServer KVStore �Ľڵ���Ϣ,���ٴ�����½���ͨ�Ż�����ѵ����
- ���Driver��������worker�ڵ���뼯Ⱥ,����Ŀǰ����worker��Ϣ������ RendezvousServer KVStore �Ľڵ���Ϣ,���ٴ�����½���ͨ�Ż�����ѵ��������worker �ڵ��յ�֪ͨ��,����ͣ��ǰѵ��,��¼Ŀǰ��������,����
shutdown��init���¹���ͨ�Ż���DriverҲ�����½ڵ�������worker,���������Ŀ�� - ���µ�ͨ�Ż�����ɹ�֮��,rank 0 worker ����Լ���ģ�㲥������������worker,������ҾͿ�����һ��������,�����ϴ�ֹͣ�ĵ�����ʼѵ����
������ѵ��������,�� worker �����б仯ʱ,ѵ����Ȼ�������С�
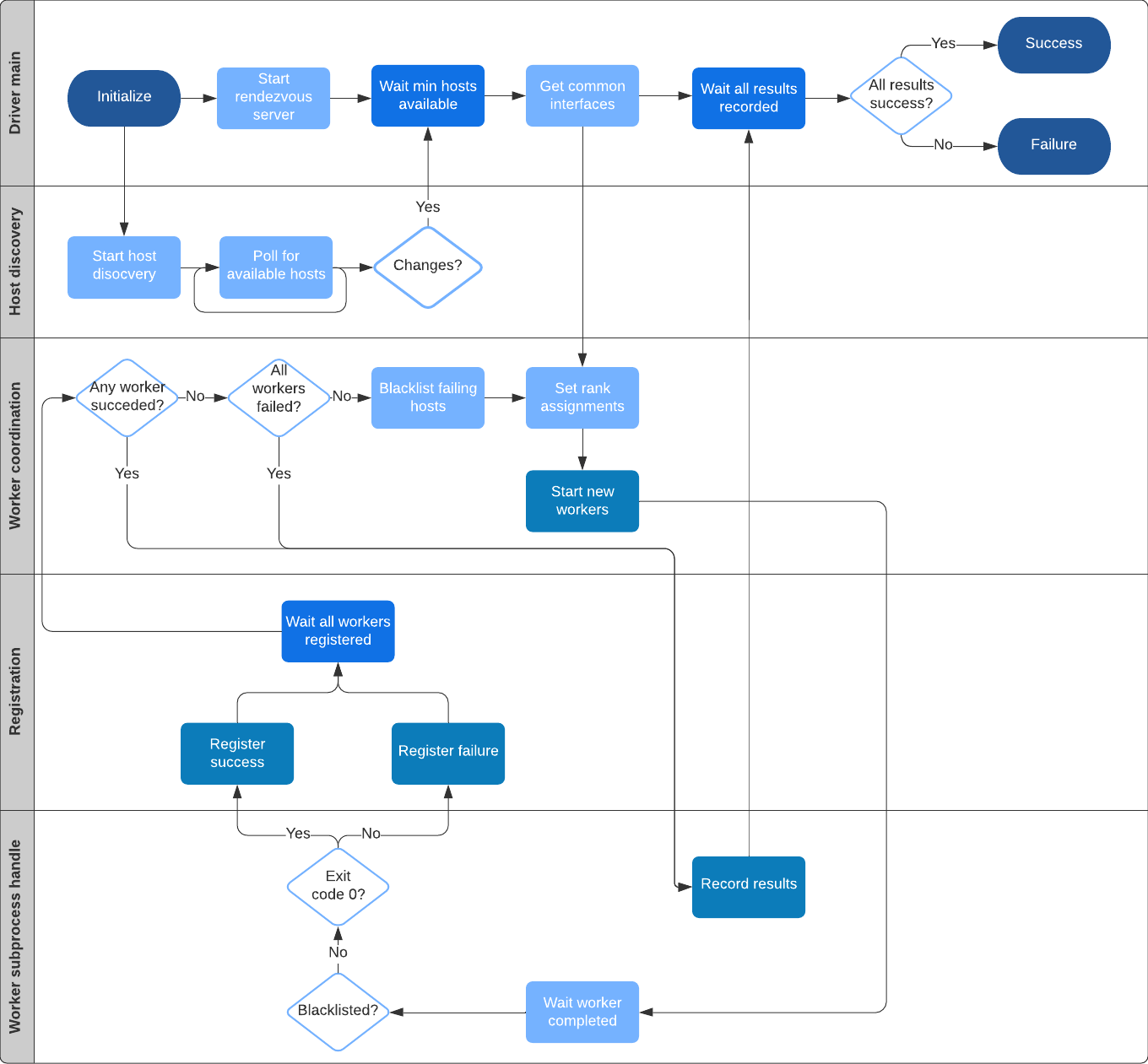
1.5 �ٷ��ܹ�ͼ
�ٷ���һ���ܹ�ͼ����,���ǻ��ں�������������ͼ�в���:
0x02 ʾ������
2.1 python����
���Ǵӹٷ��ĵ����ҳ� TF v2 ��ʾ�����뿴��,��ؼ�֮����ʹ�� @hvd.elastic.run �� train ����һ����װ,���Ҵ�����һ�� TensorFlowKerasState��
import tensorflow as tf
import horovod.tensorflow as hvd
hvd.init()
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if gpus:
tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
dataset = ...
model = ...
optimizer = tf.optimizers.Adam(lr * hvd.size())
@tf.function
def train_one_batch(data, target, allreduce=True):
with tf.GradientTape() as tape:
probs = model(data, training=True)
loss = tf.losses.categorical_crossentropy(target, probs)
if allreduce:
tape = hvd.DistributedGradientTape(tape)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# Initialize model and optimizer state so we can synchronize across workers
data, target = get_random_batch()
train_one_batch(data, target, allreduce=False)
# ʹ�� @hvd.elastic.run �� train ����һ����װ
@hvd.elastic.run
def train(state):
for state.epoch in range(state.epoch, epochs):
for state.batch in range(state.batch, batches_per_epoch):
data, target = get_random_batch()
train_one_batch(data, target)
if state.batch % batches_per_commit == 0:
state.commit()
state.batch = 0
def on_state_reset():
optimizer.lr.assign(lr * hvd.size())
# ���������Ĵ�,������һ�� TensorFlowKerasState
state = hvd.elastic.TensorFlowKerasState(model, optimizer, batch=0, epoch=0)
state.register_reset_callbacks([on_state_reset])
train(state)
2.2 �ű�ִ��
����ѵ����Ȼʹ�� horovodrun ��������й�����,����ͨ�ֲ�ʽѵ����ͬ����,����ѵ��������������������ȷָ���ڵ��б�,������ʹ��һ�� ���ֻ��� ��������ʱ���ֽڵ㡣ͨ�õ������������� Job ʱ���ṩһ�����ֽű�:
horovodrun -np 18 --host-discovery-script discover_hosts.sh python train.py
�˽ű�����ʵʱ������ǰ���õ� hosts �Լ�ÿ�� hosts �ϵ� slots(����ʹ�� discover_hosts.sh ָ���ýű�,������������Ϊ discover_hosts.sh)��
discover_hosts.sh �ű������п�ִ��Ȩ��,�ڱ�ִ��ʱ���ؿ��ýڵ��б�,һ��һ���ڵ���Ϣ,�ṹΪ: ,����:
$ sh ./discover_hosts.sh # ���нű�,����ڵ���Ϣ
host-1:4
host-2:4
host-3:4
���������ֽű�����ʧ��(û�п�ִ��Ȩ��)��������ʱ���ط�0������,��ѵ�����̻�����ʧ��,�����һֱ����ֱ����ʱ(���ص�slot�б���������С��������)��
����ѵ����һֱ�ȵ�������Сslots��(-np)����֮��,�ŻῪʼ����ѵ������,�û�����ͨ�� �Cmin-np �� �Cmax-np ָ����С������slots��,��:
horovodrun -np 8 --min-np 4 --max-np 12 --host-discovery-script discover_hosts.sh python train.py
�������slots��С�� �Cmin-np ָ��������ʱ(����ijЩ�ڵ����,������ռ��),����ᱻ��ͣ�ȴ�,ֱ������Ľڵ��Ϊ��Ծ,���߳�ʱʱ�� HOROVOD_ELASTIC_TIMEOUT(Ĭ������Ϊ600��)�ﵽ������,�����ָ�� �Cmin-np ,����Сslots���ᱻĬ��Ϊ -np �����õ���Ŀ��
��Ҫ �Cmax-np ��ԭ����Ϊ�����ƽ�����Ŀ(��ֹ����ʹ�ÿ�����Դ),������ѧϰ�ʺ����ݷ�������Ҳ������Ϊ�ο���(����Щ�������Ҫ��һ���̶��IJο�����)��ͬ��,�����ָ���˲���,Ҳ��Ĭ��Ϊ �Cnp ��
0x03 ������
3.1 ������
�����Ƚ����µ���ѵ����������(Ϊ��ʵ�ֵ���ѵ��������,Horovod Elastic �� Horovod �ļܹ���ʵ�ֽ�����һ������),���IJ�����:����ѵ����Ҫ����ɾworkerʱ����Ը��ٺ�ͬ��worker��״̬,���������¡�
- �ۺϲ�����Ҫ��������
hvd.elastic.run����֮����- �������ѵ�����̴���(��ʼ��֮������д���)��һ������(������ʱ����Ϊ train_func)��װ����,Ȼ��ʹ��װ���� hvd.elastic.run װ�����������
- �������װ�������ε� train_func ����,����һ������,������ hvd.elastic.State ��ʵ������ΪijЩ�¼����worker���ܻᴦ��ijЩ��ȷ����״̬֮��,���������������װ�κ��� train_func ֮ǰ,���״̬������Ҫ������worker�н���ͬ��,�Դ�ȷ�����е�worker���ﵽһ��״̬��
- ��Ϊͬ���������õ�����ͨ�Ų���,��������worker��,��Ծworker�����ڴ˺���֮ǰ����,���Բ�Ҫ��ͬ������֮ǰʹ��Horovod�ļ��ϲ���(����broadcast, allreduce, allgather)��
- ÿ�� worker �����Լ���״̬(state)��
- ��������Ҫ��workers֮��ͬ���ı������Ž� hvd.elastic.State (����model parameters,optimizer state,��ǰepoch��batch���ȵȵ�)����֮�С�
- ����TensorFlow,Keras��PyTorch,�Ѿ��ṩĬ�ϵı�״̬ʵ�֡�Ȼ��,����û���Ҫ��ijЩ�����㲥��������,�������ض��� hvd.elastic.State �������
- ������
hvd.elastic.run����ǰ,��״̬����������workers��ͬ��һ��,���ڱ���һ���ԡ�
- �����Ե��� state.commit() ����״̬(state)���ݵ��ڴ���
- ���ڱ��ݷdz����á���ijЩworker�����������ʱ,���ڱ��ݿ��Ա�����Ϊ״̬����������ѵ��ʱ�����ָ��ֳ�������,���һ��worker�պ��ڸ��²���������ͻȻ����,��ʱ�����ݶȸ������,�����ݶȿ���ֻ���µ�һ��,���״̬�Dz�����ת���������������,����״̬����ʱ,���׳�һ�� HorovodInternalError �쳣,�� hvd.elastic.run ��������쳣��,����������һ��commit�лָ�����״̬��
- ��Ϊcommit״̬���۸߰�(�����������̫��ᵼ�º�ʱ����),������Ҫ��"ÿ��batch�Ĵ���ʱ��"��"�������,ѵ����Ҫ�Ӷ��ǰ��״̬�ָ�"֮��ѡȡһ��ƽ��㡣����,�����ÿѵ��10��batches��commitһ��,��ͰѸ���ʱ�併����10�������ǵ���������ʱ,����Ҫ�ع���10��batchesǰ��״̬��
- Elastic Horowod����ͨ��ִ�����dz�֮Ϊ�����ŵ��Ƴ�worker��������������Щ�ع������driver���̷��������ѿ��û���Ϊɾ��,����������workers����һ��֪ͨ���������´ε���
state.commit()�����������state.check_host_updates()ʱ,һ��HostsUpdatedInterrupt�쳣�����׳������쳣�Ĵ�����ʽ�롰HorovodInternalError������,ֻ�Dz���״̬���ỹԭ���ϴ�commit,���Ǵӵ�ǰʵʱ�����лָ��� - һ����˵,������Ӳ����ʩ�ǿɿ����ȶ���,������ı���ϵͳ��������ڵ��Ƴ�ʱ�ṩ�㹻�ĸ澯,��Ϳɵ�Ƶ�ε��� state.commit() ����,ͬʱֻ��ÿ��batch����ʱ������Բ���ʱ�� state.check_host_updates() �����ڵ��������
- �� hvd.elastic.State ������ע��һЩ�ص�����,�Ա㵱worker��Ա�����仯ʱ������Ӧ
- ����ص��������Դ����������:
- ��worker���������ı�ʱ,ѧϰ����Ҫ�����µ�world size������Ӧ�ı䡣
- �����ݼ��������·�����
- ��Щ�ص���������"Horovod������֮��"��"״̬�ڽڵ��ͬ��֮ǰ"���������м䱻���á�
- ����ص��������Դ����������:
- worker �������ᴥ������ worker �ϵ�����(reset)�¼�,�����¼��ἤ�����¼�������(����ִ�������������,��һ��ȫ��ִ��):
- �жϸ� worker �Ƿ���Լ������С�
- ��ʧЧ�� worker host ���뵽������,��һ����������ʹ��blacklist�е�host��
- ���µ� hosts ������ worker ���̡�
- ����ÿ�� worker �� rank ��Ϣ��
- ������֮��,ÿ�� worker ��״̬�ᱻͬ��
3.2 ��ڵ�
�����´����֪ hvd.elastic.run ���� horovod/tensorflow/elastic.py ֮�е� run ������
import horovod.tensorflow as hvd
@hvd.elastic.run
��������ȥ����ļ���̽Ѱ��
def run(func):
from tensorflow.python.framework.errors_impl import UnknownError
def wrapper(state, *args, **kwargs):
try:
return func(state, *args, **kwargs)
except UnknownError as e:
if 'HorovodAllreduce' in e.message or \
'HorovodAllgather' in e.message or \
'HorovodBroadcast' in e.message:
raise HorovodInternalError(e)
return run_fn(wrapper, _reset)
3.3 ����
run_fn �����ǹ����û��������Ҫ������,λ�� horovod/common/elastic.py��
����Ҫ����:
- ��ʼ�� notification_manager;
- �� notification_manager ע�� state;
- ���� func ����,�����û���ѵ������ train;
- ��worker���̳��� HorvodInternalError ������� HostsUpdateInterrupt �ڵ���ɾʱ,�Ჶ������������,���� reset �������ݴ�����;
def run_fn(func, reset):
@functools.wraps(func)
def wrapper(state, *args, **kwargs):
notification_manager.init()
notification_manager.register_listener(state)
skip_sync = False
try:
while True:
if not skip_sync:
state.sync()
try:
return func(state, *args, **kwargs)
except HorovodInternalError:
state.restore()
skip_sync = False
except HostsUpdatedInterrupt as e:
skip_sync = e.skip_sync
reset()
state.on_reset()
finally:
notification_manager.remove_listener(state)
return wrapper
3.4 ��������
�ڳ���״̬��,��worker���̳��� HorvodInternalError (�������ִ���)���� HostsUpdateInterrupt (�����нڵ���ɾ)ʱ,Horovod ��ִ����������:
- �� hvd.elastic.run װ�����в���������������;
- ����׳����� HorvodInternalError ����,��������һ�� commit ״̬�лָ�;
- ���³�ʼ�� Horovod context,Ȼ�������µ�һ�ֵ�rendezvous,��rendezvous������,�ɵ�worker�ᱻ���ȱ�ѡ��Ϊ�µ�rank-0,��Ϊ�ɵ�worker�����ϴ�ѵ���е����״̬;
- �µ� rank-0 worker ���״̬ͬ��������workers;
- ����ѵ��;
����,�����Ѿ�������horovod ����ѵ�������ܹ�,��һƪ���Ƿ�������Ҫ�IJ���:Driver��
0xEE ������Ϣ
��������������ͼ�����˼���������
�Ź����˺�:������˼��
������뼰ʱ�õ�����д���µ���Ϣ����,�����뿴�������Ƽ��ļ�������,�����ע��

0xFF �ο�
ElasticDL���� Horovod ��Kubernetes��ʵ�ֵ��� AllReduce(һ)
kubernetes ��ѵ_��Kubernetes��ʹ��horovod���зֲ�ʽ���ѧϰ��ѵ
�� Kubernetes �ϵ������ѧϰѵ������ �C Elastic Training Operator