1. 介绍
注意力机制(Attention Mechanism)是机器学习中的一种数据处理方法,广泛应用在自然语言处理(NLP)、图像处理(CV)及语音识别等各种不同类型的机器学习任务中。根据注意力机制应用于域的不同,即注意力权重施加的方式和位置不同,将注意力机制分为空间域、通道域和混合域三种,并且介绍了一些关于这些不同注意力的先进注意力模型,仔细分析了他们的的设计方法和应用领域,给出了实现的代码与实验结果。
https://github.com/ZhugeKongan/Attention-mechanism-implementation
2. 空间域注意力方法
对于卷积神经网络,CNN每一层都会输出一个C x H x W的特征图,C就是通道,同时也代表卷积核的数量,亦为特征的数量,H 和W就是原始图片经过压缩后的图的高度和宽度,而空间注意力就是对于所有的通道,在二维平面上,对H x W尺寸的特征图学习到一个权重矩阵,对应每个像素都会学习到一个权重。而这些权重代表的就是某个空间位置信息的重要程度 ,将该空间注意力矩阵附加在原来的特征图上,增大有用的特征,弱化无用特征,从而起到特征筛选和增强的效果。代表的Self-Attention、Non-local Attention以及Spatial Transformer等。
2.1 自注意力:Self-Attention
自注意力是目前应用最广泛的注意力机制之一,self-attention及其变体广泛应用与自然语言处理、图像处理及语音识别的各个领域,特别是NLP领域,基于self-attention的Transformer结构已经成为NLP技术的基石。CV领域的self-attention也来源于NLP,甚至在某些分割、识别任务上直接套用NLP的Transformer结构并且取得了非常好的结果。
自注意力的结构下图所示,它是从NLP中借鉴过来的思想,因此仍然保留了Query, Key和Value等名称。对应图中自上而下分的三个分支,计算时通常分为三步:
(1) 第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
(2) 第二步一般是使用一个softmax函数对这些权重进行归一化,转换为注意力;
(3) 第三步将权重和相应的键值value进行加权求和得到最后的attention。
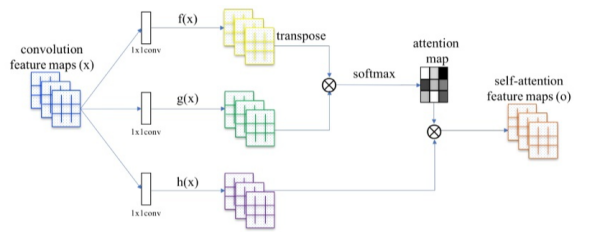
自注意力是基于特征图本身的关注而提取的注意力。对于卷积而言,卷积核的设置限制了感受野的大小,导致网络往往需要多层的堆叠才能关注到整个特征图。而自注意的优势就是它的关注是全局的,它能通过简单的查询与赋值就能获取到特征图的全局空间信息。
2.2 非局部注意力:Non-local Attention
Non-local Attention是研究self-attention在CV领域应用非常重要的文章。主要思想也很简单,CNN中的卷积单元每次只关注邻域kernel size 的区域,就算后期感受野越来越大,终究还是局部区域的运算,这样就忽略了全局其他片区(比如很远的像素)对当前区域的贡献。所以Non-local blocks 要做的是,捕获这种long-range 关系:对于2D图像,就是图像中任何像素对当前像素的关系权值;对于3D视频,就是所有帧中的所有像素,对当前帧的像素的关系权值。
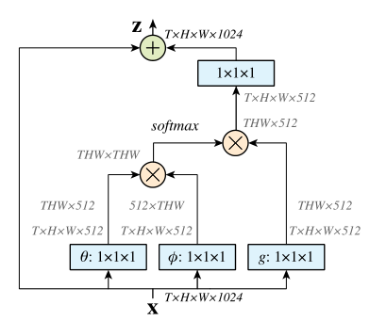
论文中有谈及多种实现方式,在这里简单说说在深度学习框架中最好实现的Matmul 方式,如上所示:
(1) 首先对输入的feature map X 进行线性映射(说白了就是1*1*1 卷积,来压缩通道数),然后得到θ,Φ,g特征;
(2) 通过reshape操作,强行合并上述的三个特征除通道数外的维度,然后对θ,Φ进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系);
(3) 然后对自相关特征以列或以行(具体看矩阵g 的形式而定) 进行Softmax 操作,得到0~1的权重,这里就是我们需要的Self-attention 系数;
(4) 最后将attention系数,对应乘回特征矩阵g 中,然后再与原输入的特征图残差一下,获得non-local block的输出。
3. 通道域注意力方法
不同与空间注意力,通道域注意力类似于给每个通道上的特征图都施加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高。在神经网络中,越高的维度特征图尺寸越小,通道数越多,通道就代表了整个图像的特征信息。如此多的通道信息,对于神经网络来说,要甄别筛选有用的通道信息是很难的,这时如果用一个通道注意力告诉该网络哪些是重要的,往往能起到很好的效果,这时CV领域做通道注意力往往比空间好的一个原因。代表的是SENet、SKNet、ECANet等。
3.1 SENet
如果说Self-Attention是NLP领域的神,那么SE注意力就是CV领域的真神。如果你想为你的网络提高精度,那么SE注意力是一个很好的选择。SE注意力在CV领域有很强的普适性,任何网络添加上SE注意力基本都能有一定提升。该论文就是靠着这个模型获得了ImageNet的冠军。
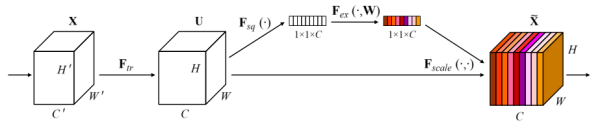
上图是SENet的模型结构,该注意力机制主要分为三个部分:挤压(squeeze),激励(excitation),以及注意(scale )。
首先是 Squeeze 操作,从空间维度来进行特征压缩,将h*w*c的特征变成一个1*1*c的特征,得到向量某种程度上具有全域性的感受野,并且输出的通道数和输入的特征通道数相匹配,它表示在特征通道上响应的全域性分布。算法很简单,就是一个全局平均池化。
其次是 Excitation 操作,通过引入 w 参数来为每个特征通道生成权重,其中 w 就是一个多层感知器,是可学习的,中间经过一个降维,减少参数量。并通过一个 Sigmoid 函数获得 0~1 之间归一化的权重,完成显式地建模特征通道间的相关性。
最后是一个 Scale 的操作,将 Excitation 的输出的权重看做是经过选择后的每个特征通道的重要性,通过通道宽度相乘加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
3.2 SKNet
SKNet是基于SENet的改进,他的思路是在提高精度。而很多网络使用了各种Trick来降低计算量,比如SENet多层感知机间添加了降维。SKNet就是想如果不牺牲那么多计算量,能否精度提高一些呢?因此它设置了一组动态卷积选择来实现精度提升。

上图所示是SKNet的基本结构。主要创新点是设置了一组动态选择的卷积,分为三个部分操作Split、Fuse、Select。
(1)Split:对输入向量X进行不同卷积核大小的完整卷积操作(组卷积),特别地,为了进一步提升效率,将5x5的传统卷积替代为dilation=2,卷积核为3x3的空洞卷积;
(2)Fuse:类似SE模块的处理,两个feature map相加后,进行全局平均池化操作,全连接先降维再升维的为两层全连接层,输出的两个注意力系数向量a和b,其中a+b=1;
(3)Select:Select操作对应于SE模块中的Scale。Select使用a和b两个权重矩阵对之前的两个feature map进行加权操作,它们之间有一个类似于特征挑选的操作。
4. 混合域注意力方法
除了前面两章提到的空间域和通道域注意力,在CV领域应用更广的还有它们之间的结合,即空间与通道结合的混合域注意力机制。思想也是很简单,通道和空间对网络都有提升作用,那么它们间的有效结合必定会给网络带来更大的促进作用。根据DL任务的不同,它们结合方式也存在区别,有代表性的是CBAM、DANet、CCNet、Residual Attention等
4.1 CBAM
CBAM来自于 ECCV2018的文章Convolutional Block Attention Module,是如今CV领域注意力食物链顶端的存在。它也是基于SENet的改进,具体来说,论文中把 channel-wise attention 看成是教网络 Look ‘what’;而spatial attention 看成是教网络 Look ‘where’,所以它比 SE Module 的主要优势就多了后者。
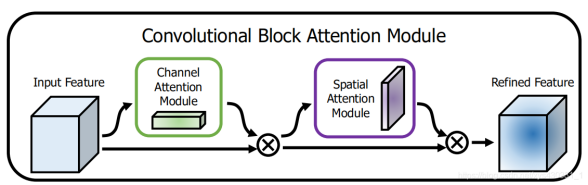
上图所示是CBAM的基本结构,前面是一个使用SENet的通道注意力模块,后面的空间注意力模块设计也参考了SENet,它将全局平均池化用在了通道上,因此作用后就得到了一个二维的空间注意力系数矩阵。值得注意的是,CBAM在空间与通道上同时做全局平均和全局最大的混合pooling,能够提取到更多的有效信息。
4.2 DANet
DANet来自于CVPR 2019的文章Dual Attention Network for Scene Segmentation,注意思想也是参考了上述提到的CBAM 和Non-local 的融合变形。具体来说就是,结构框架使用的是CBAM,具体方法使用的是self-attention。

上图所示是DANet注意力模块的基本结构,主要包括Position Attention Module 和 Channel Attention Module。两个模块使用的方法都是self-attention,只是作用的位置不同,一个是空间域的self-attention,一个是通道域的self-attention。这样做的好处是:在CBAM 分别进行空间和通道self-attention的思想上,直接使用了non-local 的自相关矩阵Matmul 的形式进行运算,避免了CBAM 手工设计pooling,多层感知器等复杂操作。同时,把Self-attention的思想用在图像分割,可通过long-range上下文关系更好地做到精准分割。
5 实验
为了评估各种注意力机制的性能,我们在CIFAR-100上进行了的实验。对每组实验,我们都以Resnet18为Baseline,训练160epoch,初始学习率为0.1,80epoch调整到0.01,160epoch时调整到0.001。Batch size设置为128,实验带momentum的SGD优化器。读取输入时,首先进行随机裁剪和随机翻转的数据增强。特别地,为最大化注意力效果,实验开始时我们都进行1个epoch的warm-up操作,取最好5个epoch的平均作为最后结果。
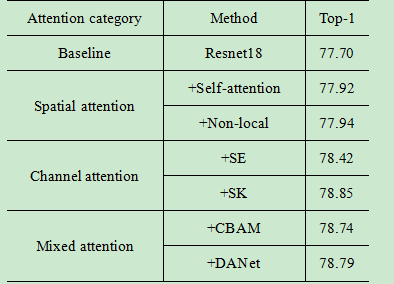
可以看出,综合性能混合域注意力表现出较好的性能,空间域注意力的表现是最差的,其中一个原因是空间注意力应用与空间特征图上,但cifar100图像分辨有限(32*32),因此空间注意力并没有表现出很好的增强效果。通道注意力表现出很好的普适性,其中SKNet在这几组实验中获得了最好表现,这归因与其动态卷积核的设置,但相比其他轻量级的注意力,它需要占据更多的内存和参数量,而且组卷积的并行设置会导致训练速度变慢。
代码附件:
https://github.com/ZhugeKongan/Attention-mechanism-implementation