MAPPO训练过程
本文主要是结合文章Joint Optimization of Handover Control and Power Allocation Based on Multi-Agent Deep Reinforcement Learning对MAPPO算法进行解析。
该文章详细地介绍了作者应用MAPPO时如何定义奖励、动作等,目前该文章没有在git-hub开放代码,如果想配合代码学习MAPPO,可以参考MAPPO算法详解该博客有对MAPPO代码详细的解释。
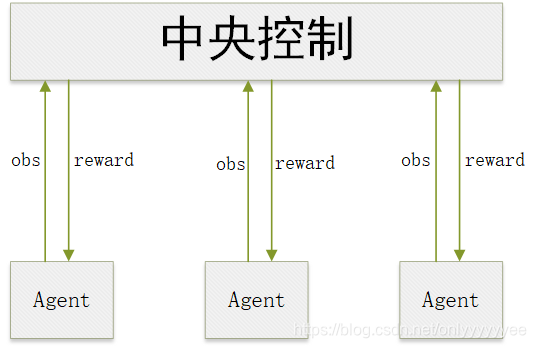
在应用MAPPO算法时,应该先明确算法框架,MAPPO有中心使和分散式两种框架,用的最多是两者结合的框架,即中心化训练、去中心化执行的框架。每个智能体将自己的状态观测数据传递给中心控制器,由中央控制器对模型进行训练,训练完后智能体就可以不再与中心控制器通信,可以基于自己的局部观测状态通过自己的动作策略函数来产生最优动作。
智能体动作策略函数的训练基于不同场景,在Fully cooperative场景中不同的agent可以共用一个策略函数。
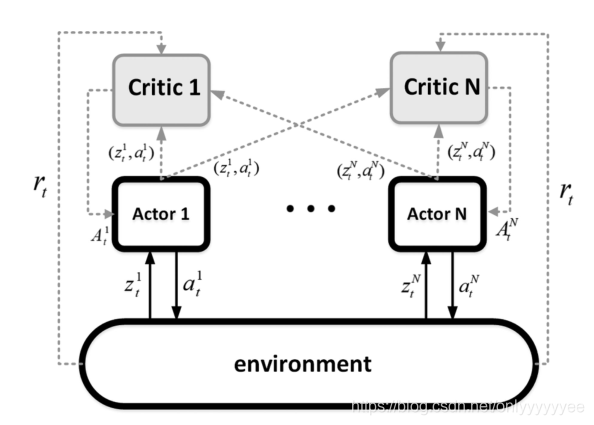
值得注意的是,在这种框架中每个智能体有单独的actor-critic网络,训练时智能体自己的actor网络要接受每个critic的打分。
对于多智能体任务,我们的目标是确定最优分散策略π来最大化折扣回报η(π),它等于状态价值函数的期望值
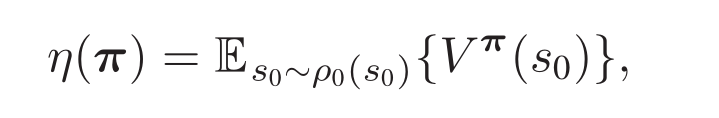
那么找到最优分散策略(也即每个智能体的策略函数)使回报最大,成为模型训练的最终目的。
参数更新
跟单智能体通过迭代训练更新网络参数一样,MAPPO算法也是用一些策略梯度算法(不同文章可能采用不同的粗略梯度)来更新神经网络参数ω、θ,因此训练的核心就成为了更新参数ω、θ。
算法伪代码:

基本流程是:
1 初始化Q和π,神经网络参数ω、θ为超参数(这里不太清楚,但是这里不用管)
2 初试化relay buffer D
3 在一个定义步长内,arent u执行策略函数π(old)产生的动作,得到reward r(t)和下一个状态s(t+1)
4 通过计算得到矩形框内数据
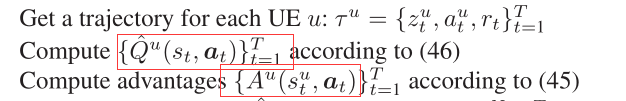
5 储存数据到buffer D中去
6 打乱D中的数据顺序,并从新编号(从而打破数据之间的相关性,从而稳定训练过程)
7 这里基本意思就是抽取数据并更新ω、θ,然后用更新后的参数去更新Q和π。

具体细节请参考原文。
参考文献:
[1]MAPPO-Joint Optimization of Handover Control and Power Allocation Based on Multi-Agent Deep Reinforcement Learning.(有定义动作、状态等,无开源代码)
[2]The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games.(总结了MAPPO的改进及特点,并与其它算法进行对比,文章内容干货不多,主要还是结合其开源代码去理解MAPPO)
[3]Multi-task Deep Reinforcement Learning with PopArt