? ? ?? 7月9号-10号,对于图像分割方面的最终效果感觉有些不太理想,因此我试试用U-NET神经网络处理图像分割问题。
目录
参考论文:U-Net: Convolutional Networks for Biomedical Image Segmentation
参考知乎:https://zhuanlan.zhihu.com/p/43927696
? ? ?? U-Net是比较早的使用全卷积网络进行语义分割的算法之一,论文中使用包含压缩路径和扩展路径的对称U形结构在当时非常具有创新性,且一定程度上影响了后面若干个分割网络的设计,该网络的名字也是取自其U形形状。U-Net的实验是一个比较简单的ISBI cell tracking数据集,由于本身的任务比较简单,U-Net紧紧通过30张图片并辅以数据扩充策略便达到非常低的错误率,拿了当届比赛的冠军。
结构:
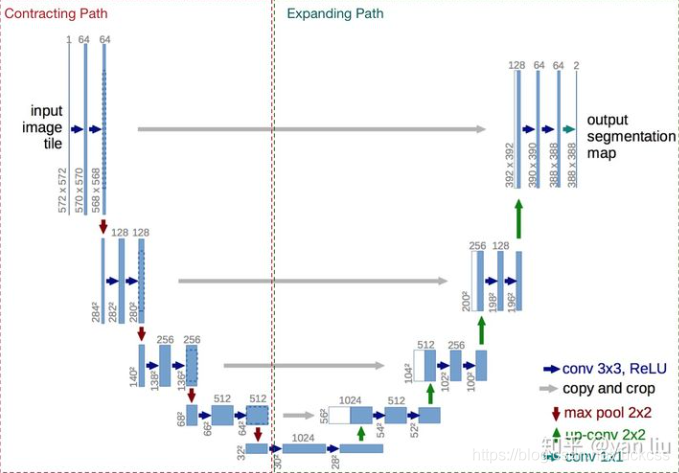
参考视频:https://www.bilibili.com/video/BV1J64y1m7s1&from=search&seid=15515898182409249700
一.根据视频复现代码:
model.py:
import torch
import torch.nn as nn
import torchvision.transforms.functional as TF
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.conv(x)
class UNET(nn.Module):
def __init__(
self, in_channels=3, out_channels=1, features=[64, 128, 256,512],
):
super(UNET, self).__init__()
self.ups = nn.ModuleList()
self.downs = nn.ModuleList()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
#Down part of UNET
for feature in features:
self.downs.append(DoubleConv(in_channels, feature))
in_channels = feature
#Up part of UNET
for feature in reversed(features):
self.ups.append(
nn.ConvTranspose2d(
feature*2, feature, kernel_size=2, stride=2,
)
)
self.ups.append(DoubleConv(feature*2, feature))
self.bottleneck = DoubleConv(features[-1], features[-1]*2)
self.final_conv = nn.Conv2d(features[0], out_channels, kernel_size=1)
def forward(self, x):
skip_connections = []
for down in self.downs:
x = down(x)
skip_connections.append(x)
x = self.pool(x)
x = self.bottleneck(x)
skip_connections = skip_connections[::-1]
for idx in range(0, len(self.ups), 2):
x = self.ups[idx](x)
skip_connection = skip_connections[idx//2]
if x.shape != skip_connection.shape:
x = TF.resize(x, size=skip_connection.shape[2:])
concat_skip = torch.cat((skip_connection, x), dim=1)
x = self.ups[idx+1](concat_skip)
return self.final_conv(x)
def test():
x = torch.randn((3, 1, 161,161))
model = UNET(in_channels=1, out_channels=1)
preds = model(x)
print(preds.shape)
print(x.shape)
assert preds.shape == x.shape
if __name__ == "__main__":
test()dataset.py:
import os
from PIL import Image
from torch.utils.data import Dataset
import numpy as np
class CarvanaDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_path = os.path.join(self.image_dir, self.images[index])
mask_path = os.path.join(self.mask_dir, self.images[index])
image = np.array(Image.open(img_path).convert("RGB"))
mask = np.array(Image.open(mask_path).convert("L"), dtype=np.float32)
mask[mask == 255.0] = 1.0
if self.transform is not None:
augmentations = self.transform(image=image, mask=mask)
image = augmentations["image"]
mask = augmentations["mask"]
return image, masktrain.py:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
import albumentations as A
from albumentations.pytorch import ToTensorV2
from tqdm import tqdm
import torch.nn as nn
import torch.optim as optim
from model import UNET
from utils import (
load_checkpoint,
save_checkpoint,
get_loaders,
check_accuracy,
save_predictions_as_imgs,
)
#Hyperparameters etc.
LEARNING_RATE = 1e-4
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
BATCH_SIZE = 16
NUM_EPOCHS = 3
NUM_WORKERS = 2
IMAGE_HEIGHT = 160
IMAGE_WIDTH = 240
PIN_MEMORY = True
LOAD_MODEL = True
TRAIN_IMG_DIR = "data/train_images/"
TRAIN_MASK_DIR = "data/train_masks/"
VAL_IMG_DIR = "data/val_images/"
VAL_MASK_DIR = "data/val_masks/"
def train_fn(loader, model, optimizer, loss_fn, scaler):
loop = tqdm(loader)
for batch_idx, (data,targets) in enumerate(loop):
data = data.to(device=DEVICE)
targets = targets.float().unsqueeze(1).to(device=DEVICE)
#forward
with torch.cuda.amp.autocast():
predictions = model(data)
loss = loss_fn(predictions, targets)
#backward
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
#update tqdm loop
loop.set_postfix(loss=loss.item())
def main():
train_transform = A.Compose(
[
A.Resize(height=IMAGE_HEIGHT, width=IMAGE_WIDTH),
A.Rotate(limit=35, p=1.0),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.1),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
],
)
val_transforms = A.Compose(
[
A.Resize(height=IMAGE_HEIGHT, width=IMAGE_WIDTH),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
],
)
model = UNET(in_channels=3, out_channels=1).to(DEVICE)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
train_loader, val_loader = get_loaders(
TRAIN_IMG_DIR,
TRAIN_MASK_DIR,
VAL_IMG_DIR,
VAL_MASK_DIR,
BATCH_SIZE,
train_transform,
val_transforms,
NUM_WORKERS,
PIN_MEMORY,
)
'''
先训练,训练好后进行更改,直接加载模型.
'''
if LOAD_MODEL:
load_checkpoint(torch.load("my_checkpoint.pth.tar"), model)
check_accuracy(val_loader, model, device=DEVICE)
scaler = torch.cuda.amp.GradScaler()
for epoch in range(NUM_EPOCHS):
train_fn(train_loader, model, optimizer, loss_fn, scaler)
#save model
checkpoint = {
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict()
}
save_checkpoint(checkpoint)
#check accuracy
check_accuracy(val_loader, model, device=DEVICE)
#print some example to a folder
save_predictions_as_imgs(
val_loader, model, folder="saved_images/", device=DEVICE
)
if __name__ == "__main__":
main()?utils.py:
import torch
import torchvision
from dataset import CarvanaDataset
from torch.utils.data import DataLoader
def save_checkpoint(state, filename="my_checkpoint.pth.tar"):
print("=> Saving checkpoint")
torch.save(state, filename)
def load_checkpoint(checkpoint, model):
print("=> Loading checkpoint")
model.load_state_dict(checkpoint["state_dict"])
def get_loaders(
train_dir,
train_maskdir,
val_dir,
val_maskdir,
batch_size,
train_transform,
val_transform,
num_workers=4,
pin_memory=True,
):
train_ds = CarvanaDataset(
image_dir=train_dir,
mask_dir=train_maskdir,
transform=train_transform,
)
train_loader = DataLoader(
train_ds,
batch_size=batch_size,
num_workers=num_workers,
pin_memory=pin_memory,
shuffle=True,
)
val_ds = CarvanaDataset(
image_dir=val_dir,
mask_dir=val_maskdir,
transform=val_transform,
)
val_loader = DataLoader(
val_ds,
batch_size=batch_size,
num_workers=num_workers,
pin_memory=pin_memory,
shuffle=False,
)
return train_loader, val_loader
def check_accuracy(loader, model, device="cuda"):
num_correct = 0
num_pixels = 0
dice_score = 0
model.eval()
with torch.no_grad():
for x, y in loader:
x = x.to(device)
y = y.to(device).unsqueeze(1)
preds = torch.sigmoid(model(x))
preds = (preds > 0.5).float()
num_correct += (preds == y).sum()
num_pixels += torch.numel(preds)
dice_score += (2*(preds*y).sum()) / (
(preds + y).sum() + 1e-8
)
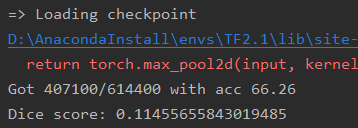
print(
f"Got {num_correct}/{num_pixels} with acc {num_correct/num_pixels*100:.2f}"
)
print(f"Dice score: {dice_score/len(loader)}")
model.train()
def save_predictions_as_imgs(
loader, model, folder="saved_images/", device="cuda"
):
model.eval()
for idx,(x,y)in enumerate(loader):
x = x.to(device=device)
with torch.no_grad():
preds = torch.sigmoid(model(x))
preds = (preds > 0.5).float()
torchvision.utils.save_image(
preds, f"{folder}/pred_{idx}.png"
)
torchvision.utils.save_image(y.unsqueeze(1), f"{folder}{idx}.png")
model.train()
数据集:
图片要求尺寸240X160,使用如下代码进行转换:
#提取目录下所有图片,更改尺寸后保存到另一目录
from PIL import Image
import os.path
import glob
def convertpng(pngfile,outdir,width=240,height=160):
img=Image.open(pngfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(pngfile)))
except Exception as e:
print(e)
for pngfile in glob.glob("D:\\AllPycharmProjects\\ImageRes\\data\\val_images\\*.png"):
convertpng(pngfile,"D:\\AllPycharmProjects\\ImageRes\\3")?训练集63张图片(可用数据实在有限):
?
?二.在实验平台上运行:
输入:
python train.py运行时报错:
python3错误:使用python3执行.py文件遇到:*ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.9' not found
参考:https://blog.csdn.net/hq86937375/article/details/79689799解决了问题。
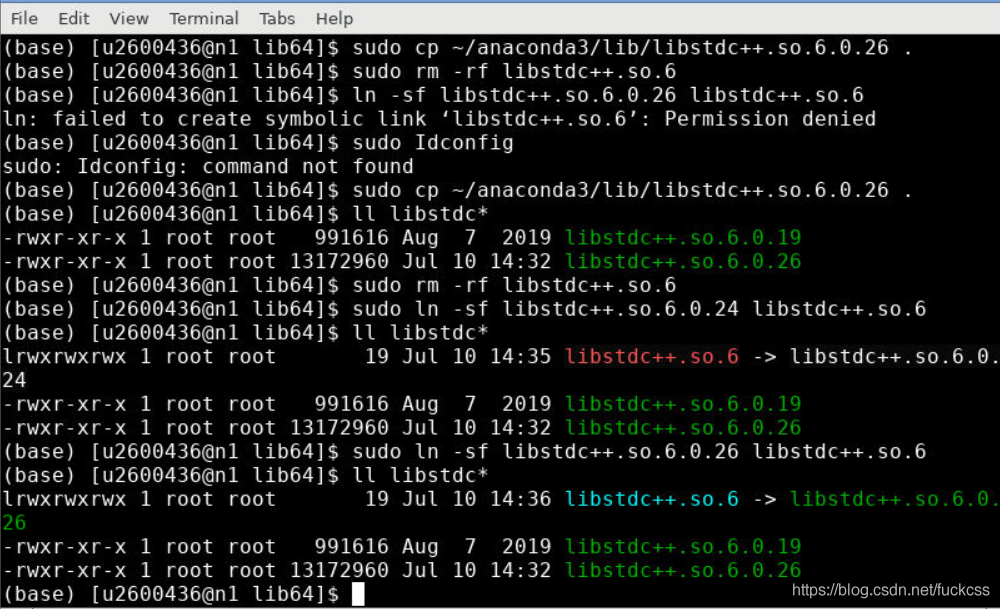
运行正常:
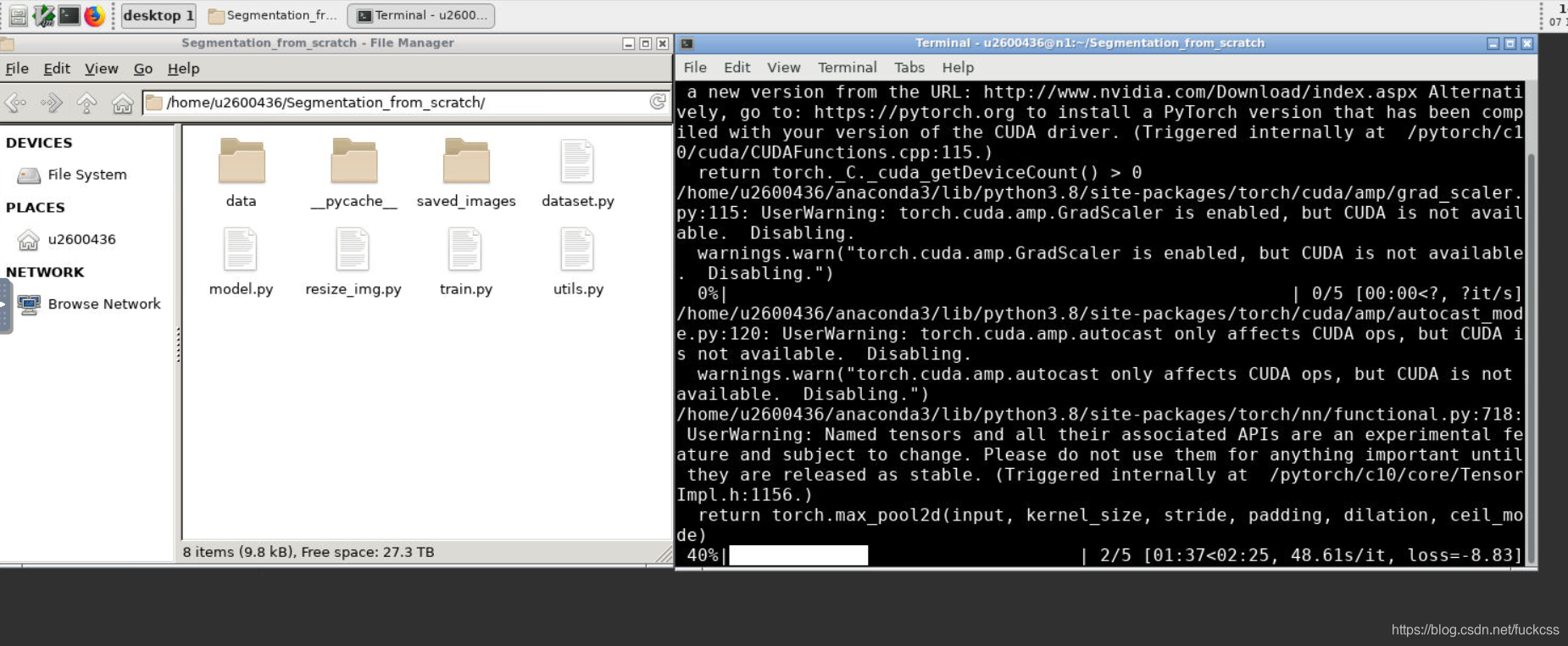
三.最终结果:
(1)预期pred结果(这个预期结果其实不太好,不是理想情况,而是我们目前能得到的最好效果的图片):

?实际pred结果:

(2)加载训练好的模型后查看acc:
四.总结
? ? ?? 整体上看,该方法得到的结果不好,但是主要原因我认为是我们的数据量太少,我能用来训练模型的图片只有63张,用来validation的图片只有16张,这用来机器学习远远不够!而B站视频中作者用了上百张图片进行训练,得到的效果很好,所以我认为数据量太少是主要原因!