摘要:本章一是介绍了如何去用一个vector来表示一个word呢?先给出两种方法1-of-N Encoding和Word Class,但都有局限性,1-of-N Encoding无法体现词义之间的联系,而word class也无法体现全面的信息,由此引出了word embedding。
二是主要讲到word embedding是用向量表示词(输入一个词,输出一个向量)。word embedding的基本思路就是:通过上下文找到这个词的意义,基于降维思想提供了count-based和prediction-based两种方法。
三是介绍了prediction-based方法如何去预测,为什么可以work ,以及参数共享的特点,与如何去training 这个NN ,并介绍了该思想在机器问答、机器翻译、图像分类、文档嵌入等方面的应用。
1. Introduction(引入)
词嵌入(word embedding)是降维算法(Dimension Reduction)的典型应用。
用一个vector来表示一个word的几种方法
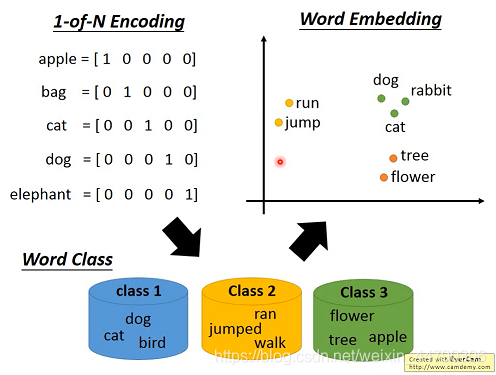
1.1 1-of-N Encoding
用一个vector来表示一个word,这个vector的维度就是世界上可能有的词的数目,每一个word对应其中一个维度。用这种方法来描述一个word,得到的vector不够informative信息丰富,每个word的vector都不一样,无法从中得到任何信息,以及词和词之间的联系。
1.2 Word Class
如何解决上述问题?
那就建立word class,把有相同性质的word放在同一个 class内(聚类),但光做clustering是不够的,不同class之间关联依旧无法被有效地表达出来。
1.3 Word Embedding
词嵌入(Word Embedding)把每一个word都投影到高维空间上,当然这个空间的维度要远比1-of-N Encoding的维度低,假如后者有10w维,那前者只需要50~100维就够了,这实际上也是Dimension Reduction的过程。
2.如何做Word Embedding
2.1 简要概念

Word Embedding是一个无监督学习的方法,只需要让机器阅读大量的文章,就可以知道每个词汇embedding的feature vector是什么样子。
产生词向量是无监督的,我们需要做的就是训练一个神经网络,找到一个function,输入一个词,输出该词对应的word embedding 的 vector。训练数据是一大堆文字,即只有input,没有output。

这里不能用auto-encoder来解决。
基本思想:每一个词汇的含义都可以根据它的上下文来得到。
比如机器在两个不同的地方阅读到了“bxx520宣誓就职”、“axx520宣誓就职”,它就会发现“bxx”和“axx”前后都有类似的文字内容,于是机器就可以推测“马xx”和“蔡xx”这两个词汇代表了可能有同样地位的东西,即使它并不知道这两个词汇是人名。
怎么用这个思想来找出word embedding的vector呢?
2.2 两种实现方法
2.2.1 Count based
假如wi和wj这两个词汇常常在同一篇文章中出现,它们的word vector分别用V(wi)和V(wj)来表示,则V(wi)和V(wj)会比较接近。
假设 Ni,j 是wi和wj这两个词汇在相同文章里同时出现的次数,我们希望它与V(wi). V(wj)的内积越接近越好。(这里与matrix factorization的方法是一致的)

常见的算法是斯坦福的:Glove Vector
Glove Vector:GloVe是一种用于获取单词向量表示的无监督学习算法。
中心思想是:左边是vector的内积,右边是出现的次数,左边和右边越接近越好。
2.2.2 Prediction based
how to do predition
给定一个sentence句子,我们要训练一个神经网络,它要做的就是根据当前的word wi-1,来预测下一个可能出现的word wi是什么。
输入:前一个word的1-of-N encoding的feature vector
输出:下一个word,是某个词的概率,vector的维度是世界上word的数目。

第一层hidden layer的维数可以由我们决定,而它的input又唯一确定了一个word,因此提取出第一层hidden layer的input,实际上就得到了一组可以自定义维数的Word Embedding的向量。
Why prediction works
为什么第一层的输入与word embedding中的vector是接近的?
prediction-based方法是如何体现根据词汇的上下文来了解该词汇的含义这件事呢?
为了使这两个不同的input通过NN能得到相同的output,就必须在进入hidden layer之前,就通过weight的转换将这两个input vector投影到位置相近的低维空间上,也就是说,尽管两个input vector作为1-of-N编码看起来完全不同,但经过参数的转换,将两者都降维到某一个空间中,在这个空间里,经过转换后的new vector 1和vector 2是非常接近的,因此它们同时进入一系列的hidden layer,最终输出时得到的output是相同的。
总结:对1-of-N编码进行Word Embedding降维的结果就是神经网络模型第一层hidden layer的输入向量[z1,z2,z3…]T,该向量同时也考虑了上下文词汇的关联,我们可以通过控制第一层hidden layer的大小从而控制目标降维空间的维数。
Sharing Parameters
前面仅仅通过前一个词来预测下一个词可能太差了,所以可以引申为通过前几个词来预测下一个词。

每个维度连接到的weight必须是一样的,否则,一个词会对应有两个词向量,且减少参数量(1-of-N encoding的vector的维度是10w维,feature vector是50维。如果我们强迫让所有的1-of-N encoding后面接的weight全部一样,就不会随着context的增长而需要更多的参数)。
公式化表示: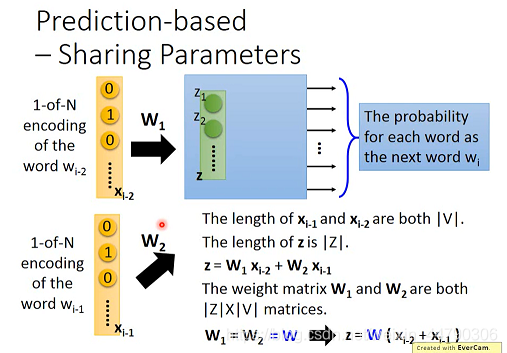
假设:Xi-1和Xi-2的长度都是|v|,表示数据中的words总数,hidden layer的input为向量z,长度为|Z|,表示降维后的维数, z = W1xi-2 + W2xi-1,其中W1和W2都是|Z|*|V|维的weight matrix。
如何让 w i w^i wi与 w j w^j wj相等呢?

- wi和wj的初始值相同
- wi和wj的更新过程相同
所以需要这样: w i w ^i wi和 w j w^j wj 使得两个weight永远tie在一起,以确保参数共享,减少计算量。
如何Training 这个神经网络

这个NN完全是unsupervised,只需要将文章数据直接丢给它即可。
比如丢给NN的input是“潮水”和“退了”,希望它的output是“就”,之前提到这个NN的输出是一个由概率组成的vector,而目标 “就” 是只有某一维为1的1-of-N编码。
每次输入两个word,输出结果与后续的word做交叉熵,取交叉熵之和的最小值。
Various Architectures
Prediction-based方法还可以有多种变形:
-
CBOW(Continuous bag of word model)
拿前后的词汇去预测中间的词汇 -
Skip-gram
拿中间的词汇去预测前后的词

注意:Word vector并不需要用DNN
3.Word embedding――Application
- 将不同国家和首都放在一个维度
- 将动词的三个时态联系起来

如果把word vector两两相减,把他们映射到一个二维空间中,如果他们落在了同一块区域,说明这两个word之间会存在一个包含另外一个的关系。

3.1 Multi-lingual Embedding(类似实现翻译)
如果你要用上述方法分别训练一个英文的语料库(corpus)和中文的语料库,你会发现两者的word vector之间是没有任何关系的,因为Word Embedding只体现了上下文的关系,如果你的文章没有把中英文混合在一起使用,机器就没有办法判断中英文词汇之间的关系。
但是,如果你知道某些中文词汇和英文词汇的对应关系,你可以先分别获取它们的word vector,然后再去训练一个模型,把具有相同含义的中英文词汇投影到新空间上的同一个点。
接下来遇到未知的新词汇,无论是中文还是英文,你都可以采用同样的方式将其投影到新空间,就可以自动做到类似翻译的效果了。

3.2 Multi-domain Embedding(应用于影像分类)
例如,先找一组word vector,比如dog、horse、auto、cat等的vector,这时候我们learning一个model,这个model的input是一张图片,output是一个跟word vector一样维度的vector,这时候我们只需要将一部分图片进行训练使得狗的图片对应dog的word vector,车的图片对应car的word vector这样。
应用训练好的model会找到image(pixel vector)与word vector之间的映射关系,所以即使这个model之前没见过cat图,但是还是能将猫图投影到猫的word vector,对training时没出现的类别也可以进行分类!

4. 总结与展望
本章主要学习了Word Embedding(词嵌入)的知识,其基本思想是:通过上下文找到这个词的意义,它是无监督学习的(输入一个词,输出一个向量),实现方法有 Count based(基于统计) 与 Prediction based(基于预测)两种。
Count based的主要思想是:两词向量共同出现的频率比较高的话,那么这两个词向量也应该比较相似。Prediction based 的方法是,我们要训练一个神经网络,它要做的就是根据当前的word wi-1 ,来预测下一个可能出现的word wi是什么。以及Prediction based 方法的实际应用等。
最后,对于词的多义性来说,通过Word Eembedding得到的与词对应的vector却是唯一的,这显然不能满足我们对同一词的不同语义进行分析的需求,这也是Word Eembedding的主要缺陷。因此,Word Eembedding主要应用在预训练过程,对语义的进一步分析往往是通过后续模型中的特定的设计来实现的(例如应用RNN与LSTM去解决词多义问题)。