一、引言
? ? ? ? LSTM出现以来,在捕获时间序列依赖关系方面表现出了强大的潜力,直到Transformer的大杀四方。但是,就像我在上一篇博客《RNN与LSTM原理浅析》末尾提到的一样,虽然Transformer在目标检测、目标识别、时间序列预测等各领域都有着优于传统模型的表现,甚至是压倒性的优势。但Transformer所依赖的Multi-Head Attention机制给模型带来了巨大的参数量与计算开销,这使得模型难以满足实时性要求高的任务需求。我也提到,LSTM想与Transformer抗衡,似乎应该从注意力机制方面下手。事实上,已经有研究这么做了,那就是LSTNet。
二、LSTNet
? ? ? ? 2018年,论文《Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks》正式提出了LSTNet。LSTNet的出现可以认为是研究人员通过注意力机制提升LSTM模型时序预测能力的一次尝试,文中共提出了LST-Skip与LST-Atten两种模型。其中,LST-Skip需要手动设置序列的周期,比较适用于交通流预测等周期明确可知的时间序列,而LST-Atten模型则可以自动捕捉模型的周期。实验表明,上述两种模型在周期序列预测中表现出了良好的性能。
? ? ? ? 然而,上述模型的性能受制于序列的周期与可用历史状态的长度。首先,模型的注意力机制为“时间注意力机制”,其本质是利用了序列内部的时间性周期,因此对于没有明显周期性的序列(如:车辆轨迹序列)则不能很好地发挥优势。其次,LST-Atten依赖于历史状态挖掘序列的周期,若可用的历史状态较短,无法反映一个完整的周期,则模型可自主挖掘周期性的优势仍无法体现。
三、方法? ? ? ??
? ? ? ? 本文以实现LST-Atten为例(在进入FC层前的张量处理与原文稍有不同),描述LSTM中的时间注意力机制。由于在CSDN的编辑器中不方便使用各种专业符号,因此下文中使用的符号一切从简,不以专业性为目的。
? ? ? ? 我们假设使用过去的A帧数据预测未来的B帧,且LSTM编码器中A个LSTM单元的隐状态为H,LSTM解码器中第一个LSTM单元的隐状态为h1。那么集成了时间注意力机制的LSTM编码-解码器工作原理可用如下表示:

? ? ? ? ?其中,F为打分函数,用于计算H与h1之间的余弦相关度。然后,通过softmax函数,这些余弦相关度被转换为各历史隐状态的相对权重。H中各时刻隐藏状态的加权和与解码器第一帧输出的隐藏状态h1相结合,最终通过全连接层得到第一帧的预测输出。 其工作原理如图1所示。
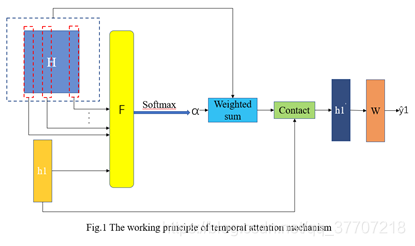
四、结果?
? ? ? ? 该模型在公共交通流数据集 PeMS04 上进行了测试。 我们选择了测试点1测得的交通流数据,其中70%的数据用于模型训练,30%的数据用于模型测试。使用 Adam 作为优化器,MSE 作为模型测量指标,学习率为 0.0001,训练 800 轮。 训练损失如图2所示,测试结果如表1所示。
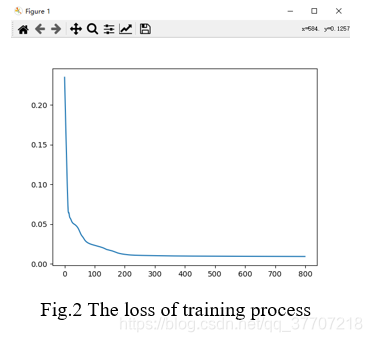
?

?最后,我在测试集中选取了 4000 个样本点进行可视化,结果如图 3 所示。
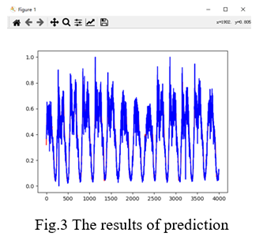
?五、源代码
"模型训练"
import numpy as np
import torch
import torch.nn as nn
import os
import matplotlib.pyplot as plt
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
file=np.load('PeMS04.npz')
data=torch.from_numpy(file['data'])
device = torch.device('cuda:0')
'定义子函数与类模型'
def creat_dataset(data,look_back,pre_len):
data_x = []
data_y = []
for i in range(len(data)-look_back-pre_len+1): # 对选好的该辆车的数据划分输入(过去8点)与输出(未来12点)
data_x.append(data[i:i + look_back, :])
data_y.append(data[i+look_back:i+look_back+pre_len, :])
return np.asarray(data_x), np.asarray(data_y) # 转为ndarray数据
class LSTM_Atten(nn.Module):
"""搭建Decoder结构"""
def __init__(self,look_back,pre_len):
super(LSTM_Atten, self).__init__()
self.lstm = nn.LSTM(input_size=1, #1个输入特征
hidden_size=128, #隐状态h扩展为为128维
num_layers=1, #1层LSTM
batch_first=True, # 输入结构为(batch_size, seq_len, feature_size). Default: False
)
self.lstmcell=nn.LSTMCell(input_size=128, hidden_size=128)
self.drop=nn.Dropout(0.2) #掉落率
self.fc1=nn.Linear(256,128)
self.fc2=nn.Linear(128,1)
self.look_back=look_back
self.pre_len=pre_len
self.Softmax=nn.Softmax(dim=1)
def forward(self, x):
H,(h,c) = self.lstm(x.float(),None) #编码
h=h.squeeze(0)
c=c.squeeze(0)
H_pre=torch.empty((h.shape[0],self.pre_len,128*2)).to(device)
for i in range(self.pre_len): #解码
h_t, c_t = self.lstmcell(h, (h, c)) # 预测
H=torch.cat((H,h_t.unsqueeze(1)),1)
h_atten=self.Atten(H) #获取结合了注意力的隐状态
H_pre[:,i,:]=h_atten #记录解码器每一步的隐状态
h, c = h_t, c_t # 将当前的隐状态与细胞状态记录用于下一个时间步
return self.fc2(self.fc1(H_pre)).squeeze(2)
def Atten(self,H):
h=H[:,-1,:].unsqueeze(1) #[batch_size,1,128]
H=H[:,-1-self.look_back:-1,:] #[batch_size,look_back,128]
atten=torch.matmul(h,H.transpose(1,2)).transpose(1,2) #注意力矩阵
atten=self.Softmax(atten)
atten_H=atten*H #带有注意力的历史隐状态
atten_H=torch.sum(atten_H,dim=1).unsqueeze(1) #按时间维度降维
return torch.cat((atten_H,h),2).squeeze(1)
'数据预处理'
#data格式:[数据条数;记录点id;3个特征(0号特征是交通流)]
look_back=20
pre_len=30
data=data[0:11890,0,0].unsqueeze(1).numpy() #第0个记录点记录的前11890条交通流数据作为训练集[11890,1]
data=(data-data.min())/(data.max()-data.min()) #数据归一化
X,Y=creat_dataset(data,look_back,pre_len) #[11871,5,1],[11871,1] 使用前5点预测后一点
X=torch.from_numpy(X).to(device)
Y=torch.from_numpy(Y).to(device)
'训练模型'
model=LSTM_Atten(look_back,pre_len).to(device)
loss_fun=nn.MSELoss()
optimizer=torch.optim.Adam(model.parameters(),0.0001)
epoch=800
batch_size=3947
cost=[]
for i in range(epoch):
for t in range(int(11871/batch_size)):
input=X[t*batch_size:(t+1)*batch_size,:,:] #按batch_size获取输入与标签
label=Y[t*batch_size:(t+1)*batch_size,:].squeeze(2)
output=model(input.float()) #预测值
loss=loss_fun(label.float(),output.float()) #计算MSE损失
optimizer.zero_grad() #梯度清零
loss.backward() #反向传播
optimizer.step() #参数更新
print(((i + 1) / epoch) * 100)
cost.append(loss.item()) #记录损失
torch.save(model.state_dict(),'lstm-atten.pth')
plt.figure()
plt.plot(cost)
plt.show()"模型测试"
import numpy as np
import torch
import torch.nn as nn
import os
import matplotlib.pyplot as plt
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
file=np.load('PeMS04.npz')
data=torch.from_numpy(file['data'])
'定义子函数与类模型'
def creat_dataset(data,look_back,pre_len):
data_x = []
data_y = []
for i in range(len(data)-look_back-pre_len+1): # 对选好的该辆车的数据划分输入(过去8点)与输出(未来12点)
data_x.append(data[i:i + look_back, :])
data_y.append(data[i+look_back:i+look_back+pre_len, :])
return np.asarray(data_x), np.asarray(data_y) # 转为ndarray数据
class LSTM_Atten(nn.Module):
"""搭建Decoder结构"""
def __init__(self,look_back,pre_len):
super(LSTM_Atten, self).__init__()
self.lstm = nn.LSTM(input_size=1, #1个输入特征
hidden_size=128, #隐状态h扩展为为128维
num_layers=1, #1层LSTM
batch_first=True, # 输入结构为(batch_size, seq_len, feature_size). Default: False
)
self.lstmcell=nn.LSTMCell(input_size=128, hidden_size=128)
self.drop=nn.Dropout(0.2) #掉落率
self.fc1=nn.Linear(256,128)
self.fc2=nn.Linear(128,1)
self.look_back=look_back
self.pre_len=pre_len
self.Softmax=nn.Softmax(dim=1)
def forward(self, x):
H,(h,c) = self.lstm(x.float(),None) #编码
h=h.squeeze(0)
c=c.squeeze(0)
H_pre=torch.empty((h.shape[0],self.pre_len,128*2))
for i in range(self.pre_len): #解码
h_t, c_t = self.lstmcell(h, (h, c)) # 预测
H=torch.cat((H,h_t.unsqueeze(1)),1)
h_atten=self.Atten(H) #获取结合了注意力的隐状态
H_pre[:,i,:]=h_atten #记录解码器每一步的隐状态
h, c = h_t, c_t # 将当前的隐状态与细胞状态记录用于下一个时间步
return self.fc2(self.fc1(H_pre)).squeeze(2)
def Atten(self,H):
h=H[:,-1,:].unsqueeze(1) #[batch_size,1,128]
H=H[:,-1-self.look_back:-1,:] #[batch_size,look_back,128]
atten=torch.matmul(h,H.transpose(1,2)).transpose(1,2) #注意力矩阵
atten=self.Softmax(atten)
atten_H=atten*H #带有注意力的历史隐状态
atten_H=torch.sum(atten_H,dim=1).unsqueeze(1) #按时间维度降维
return torch.cat((atten_H,h),2).squeeze(1)
'数据预处理'
#data格式:[数据条数;记录点id;3个特征(0号特征是交通流)]
look_back=20
pre_len=30
data=data[11890:,0,0].unsqueeze(1).numpy() #第0个记录点记录的11890后的5102条交通流数据作为训练集[5102,1]
data=(data-data.min())/(data.max()-data.min()) #数据归一化
X,Y=creat_dataset(data,look_back,pre_len) #[5083,10,1],[5083,10,1] 使用前5点预测后一点
X=torch.from_numpy(X)
Y=torch.from_numpy(Y).squeeze(2)
'测试模型'
model=LSTM_Atten(look_back,pre_len)
loss_fun=nn.MSELoss()
model.load_state_dict(torch.load('lstm-atten.pth'))
output=model(X.float()).squeeze(1)
loss=loss_fun(output.float(),Y.float())
print(loss)
plt.figure()
plt.plot(output[0:4000,0].detach(),'r')
plt.plot(Y[0:4000,0],'b')
plt.show()