ԭ������:https://blog.csdn.net/cdlwhm1217096231/article/details/95060636
����дĿ¼����
1.Attention���ƻ���֪ʶ
��X = [ x1 , ? ? , xN ] ��ʾN��������Ϣ,����ÿ������xi , i �� [ 1 , N ] ����ʾһ��������Ϣ��Ϊ�˽�ʡ������Դ,����Ҫ�����е���Ϣ�����뵽��������,ֻ��Ҫ��X��ѡ��һЩ��������ص���Ϣ��ע�������Ƶļ�����Է�Ϊ����:
- ������������Ϣ�ϼ���ע�����ֲ�;
- ����ע�����ֲ�������������Ϣ����Ȩƽ��
1.1ע�����ֲ�
- Ϊ�˴�N����������[ x1 , ? ? , xN ]��ѡ�����ij���ض�������ص���Ϣ,��Ҫ����һ����������صı�ʾ,��Ϊ��ѯ����q,��ͨ��һ����ֺ���������ÿ�����������Ͳ�ѯ����֮�������ԡ�
- ����һ����������صIJ�ѯ����q,��ע��������z �� [ 1 , N ] ����ʾ��ѡ����Ϣ������λ��,��z=i��ʾѡ���˵�i������������Ϊ�˷������,�������Ƚ���Soft Attentionע�������������ȼ����ڸ���q��X��,ѡ���i�����������ĸ��ʦ�i
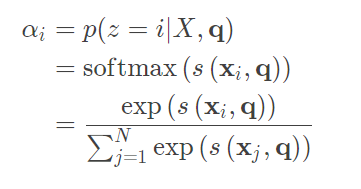
���Ц�i ��Ϊע�����ֲ�,S ( x i , q ) ��ע������ֺ���,����ʹ������ļ��ַ���������:
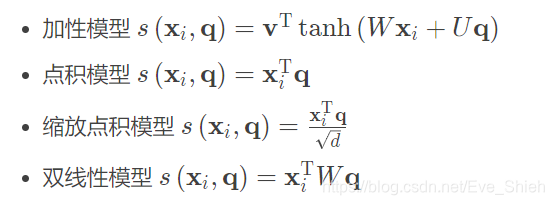
- ��ʽ��W��U��v�ǿ�ѧϰ�IJ���,d������������ά�ȡ�������,����ģ�ͺ͵��ģ�͵ĸ��ӶȲ��,���ǵ��ģ����ʵ���Ͽ��Ը��õ����þ���˻�,�Ӷ�����Ч�ʸ��ߡ���������������ά��d�Ƚϸ�,���ģ�͵�ֵͨ���нϴ�ķ���,�Ӷ�����softmax�������ݶȱȽ�С�����,���ŵ��ģ�Ϳ��Ժܺõؽ��������⡣˫����ģ�Ϳ��Կ�����һ�ַ����ĵ��ģ�͡���ȵ��ģ��,˫����ģ���ڼ������ƶ�ʱ�����˷ǶԳ��ԡ�
1.2 ��Ȩƽ��
- ע�����ֲ��� i ���Խ���Ϊ�ڸ���������صIJ�ѯqʱ,��i������������ע��ij̶ȡ��������һ����������Ϣѡ����ƶ�������Ϣ���л��ܡ�
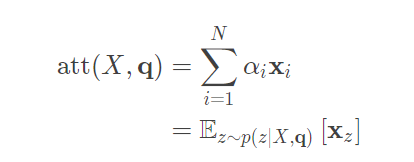
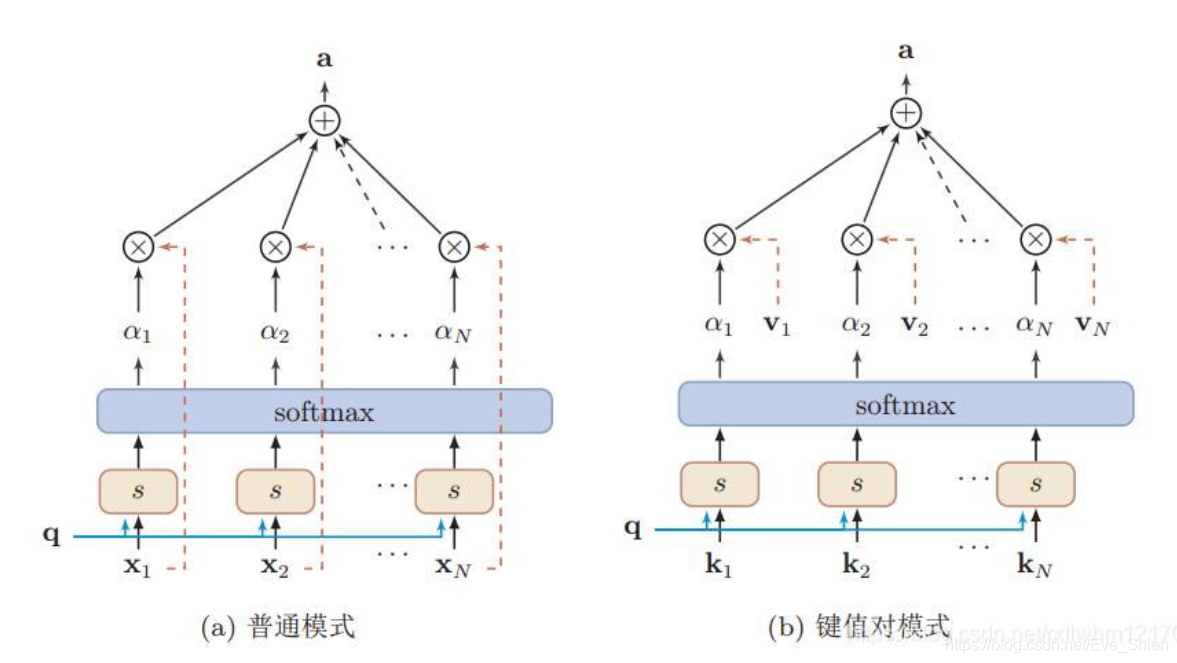
��ʽ��Ϊ��ע��������(Soft Attention Mechanism)����ͼ��������ע�������Ƶ�ʾ��ͼ:
2.�������͵�ע��������
2.1 Ӳע��������
- ����Ĺ�ʽE z �� p ( z �O X , q ) [ x z ] �ᵽ������ע��������,��ѡ�����Ϣ����������������ע�����ֲ��µ������������һ��ע������ֻ��ע��ijһ����������,����Ӳע��������(Hard Attention Mechanism)��Ӳע�������������ַ�������ʵ��:

- Ӳע������һ��ȱ���ǻ�������������������ķ�ʽ��ѡ����Ϣ��������յ���ʧ������ע�����ֲ�֮��ĺ�����ϵ���ɵ�,�����ʹ�÷����㷨����ѵ����Ϊ��ʹ�÷����㷨����ѵ��,һ��ʹ����ע�������ơ�
2.2 ��ֵ��ע����

2.3 ��ͷע����

2.4 ��ע����ģ��(Self Attention)
- ��ʹ��������������һ���仯���ȵ���������ʱ,ͨ������ʹ�þ��������ѭ��������б������õ�һ����ͬ���ȵ������������,����ͼ��ʾ:
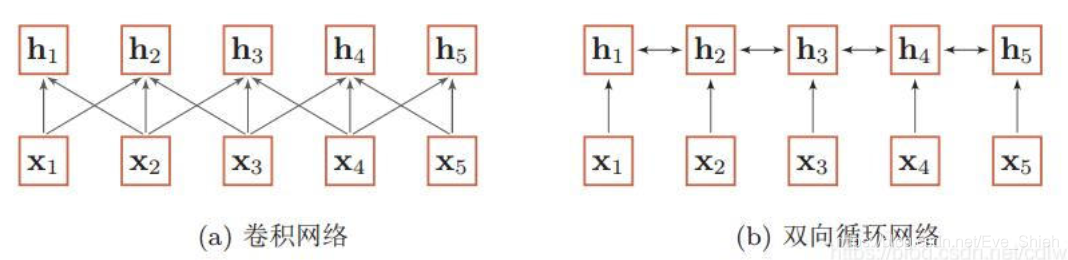
- ���ھ�����ѭ����������б��붼�ǿ��Կ�����һ�־ֲ��ı��뷽ʽ,ֻ��ģ��������Ϣ�ľֲ�������ϵ����Ȼѭ�����������Ͽ��Խ���������������ϵ,����������Ϣ���ݵ������Լ��ݶ���ʧ����,ʵ����Ҳֻ�ܽ����̾���������ϵ��
- ���Ҫ������������֮��ij�����������ϵ,����ʹ���������ַ���:һ�ַ�������������IJ���,ͨ��һ�������������ȡԶ�������Ϣ����;��һ�ַ�����ʹ��ȫ�������硣ȫ����������һ�ַdz�ֱ�ӵĽ�ģԶ����������ģ��,�����������䳤���������С���ͬ�����볤��,������Ȩ�صĴ�СҲ�Dz�ͬ�ġ���ʱ,�Ϳ�������ע��������������̬�������ɲ�ͬ���ӵ�Ȩ��,�������ע����ģ��(Self-Attention Model)��
- ������������ΪX = [ x 1 , ? ? , x N ] �� R d 1 �� N ,�������ΪH = [ h 1 , ? ? , h N ] �� R d 2 �� N,�����ͨ�����Ա任�õ�������������:
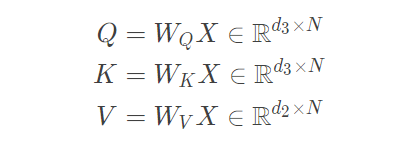


- ��ͼ������ȫ����ģ�ͺ���ע����ģ�͵ĶԱ�,����ʵ�߱�ʾ��ѧϰ��Ȩ��,���߱�ʾ��̬���ɵ�Ȩ�ء�������ע����ģ�͵�Ȩ���Ƕ�̬���ɵ�,��˿��Դ����䳤����Ϣ���С�
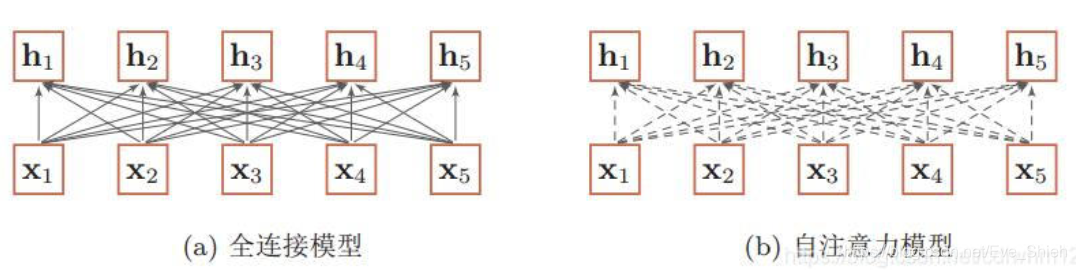
- ��ע����ģ�Ϳ�����Ϊ�������е�һ����ʹ��,�ȿ��������滻�������ѭ����,Ҳ���Ժ�����һ����ʹ��(������������X�����Ǿ������ѭ��������)����ע��ģ�ͼ����Ȩ�ئ� i j ֻ������qi�������,�Ӷ�������������Ϣ��λ����Ϣ�����,�ڵ���ʹ��ʱ,��ע��ģ��һ����Ҫ����λ�ñ�����Ϣ������������
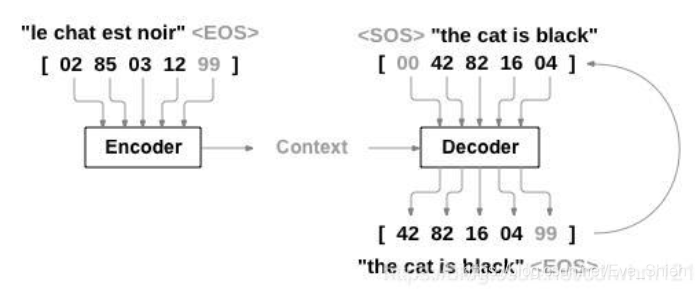
3.ʵս------��Seq2Seq������з��ﵽӢ��ķ���Ϊ������˵��
- ���û��������еľ�������ṹSeq2Seq(����ṹ���ο������е�����),���а���Encoder�������罫����ķ�����ӽ��б���,Ȼ�����뵽Decoder����������н���,��������õ���Ӣ�ľ��ӡ���������Ľṹ����: