��Ŀ
Exploring Word Segmentation and Medical Concept Recognition for Chinese Medical Texts
����ҽѧ�ı��ִ���ҽѧ����ʶ���о�
������Ĵ�ѧ
ժҪ
����:Ҫ�������Ӳ���,����ҽѧ���ݼ�ȱ����
����:�ռ��˵��Ӳ��� �C ACEMR(���˹���ע��),����ģ��BiLSTM,BERT,ZEN; ����ϵͳ:WMSeg,TwASP
ʵ����֤���˽���һ��ר��ҽ�����ݼ��ı�Ҫ��,���������ö�����Դ��ģ���������������дﵽ�������,Ϊδ��ҽѧ����ģ��ѡ���о��ṩ��һ����ָ����
https://github.com/cuhksz-nlp/ACEMR (��������)
��������ؼ���
���ķִ�(CWS)��ҽѧ����ʶ���Ǵ������ĵ��Ӳ���(EMRs)�������������,�����������ĵ��Ӳ��������������з�������Ҫ���á�
֮ǰ���о���1��~��7��,���ǹ����Լ������ݼ��������о��� ��
�ռ���һ�����ݼ�ACEMR:500 EMRs (7K sentences)
���һ���������ݼ�����һЩʵ�顣
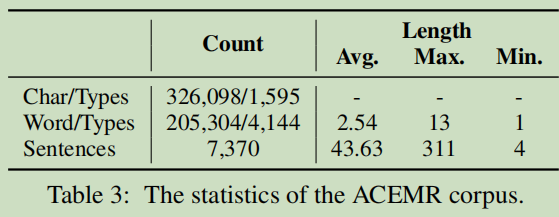
ACEMR����
�����ռ�
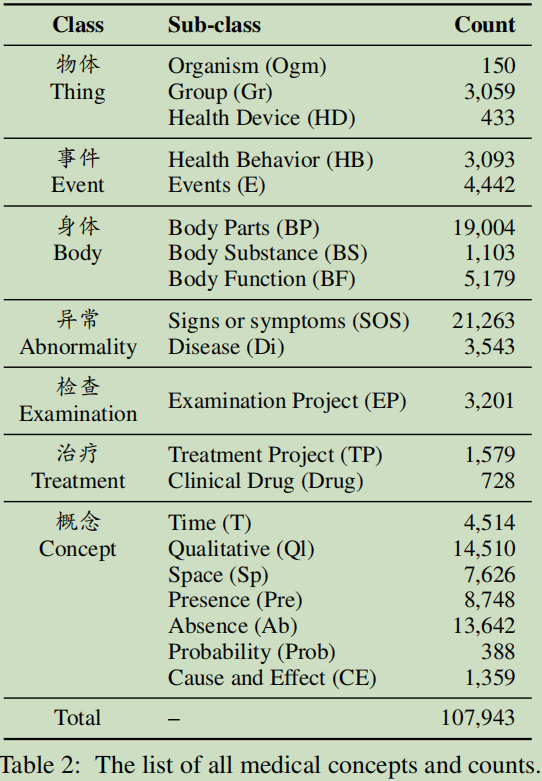
����5������:����ϵͳ��θ����ѧ������ѧ�����ƺ����ಡѧ
������Ϣ:

CWS��ҽѧ����ע��
����:
����
EMR��CWS
�������б������(��ʵ����)
Medical Concept Recognition
�������б������(��ʵ����)
����������һЩ�䷨������,�����չʾ���������:POS,������ϵ,�䷨�ṹ
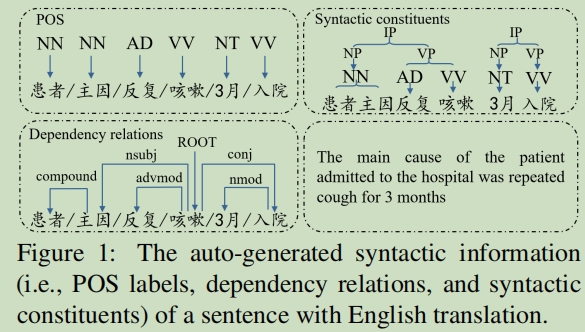
ʵ��
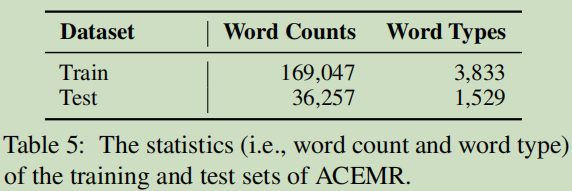
���ݼ�:ACMER,CTB6
train��test:
CWS���:
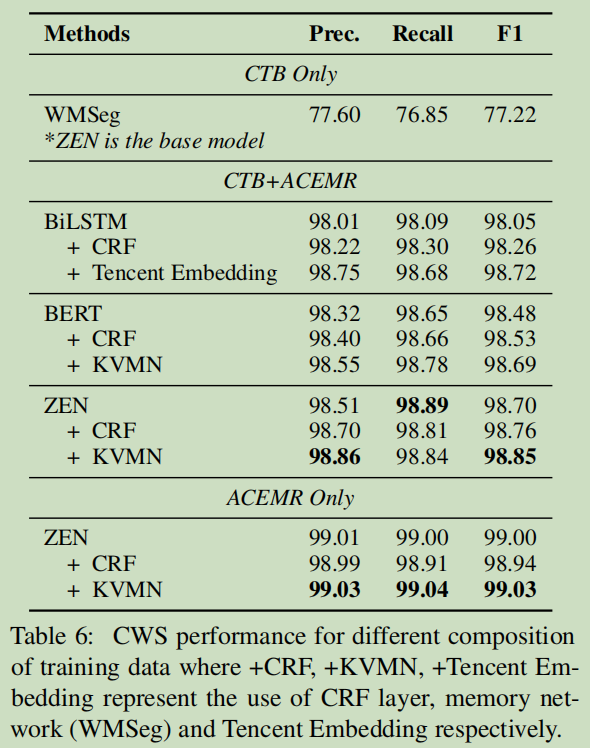
�������������:
���1:CTB Only,��ʾ��CTB6��ѵ��,��ACEMR���Լ�����֤;
���2:CTB+ACEMR,
���3:ACEMR Only
ΪʲôҪ��CTB������ѽ?����̫����!!����˵������㷨����?������˵��������ݼ���ѽ?
MCR���:
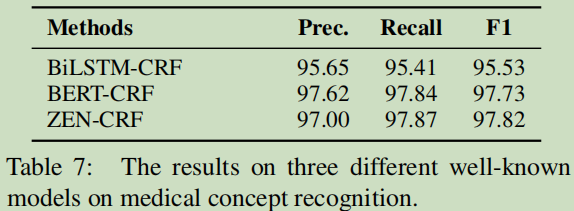
�����Ǹ��Թ���
����һ���Ϣ�õ���Ч��:
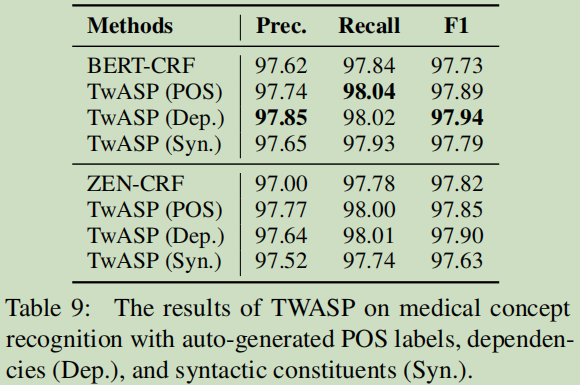
�������Ϲ����˲���һ�¡�
�ܽ�:
������Ŀ��������,��������ʵû��ʲô�о���
�������Կ�һ��������������,��������������ȥѧϰһ�¡�
��Ѷ��Directional Skip-Gram: Explicitly Distin guishing Left and Right Context for Word Embeddings,https://ai.tencent.com/ailab/nlp/zh/embedding.html;
Improving Chinese Word Segmentation with Wordhood Memory Networks
����:Yuanhe Tian, Yan Song, Fei Xia, Tong Zhang, Yonggang Wang
���ĵ�ַ:https://www.aclweb.org/anthology/2020.acl-main.734/
GitHub:https://github.com/SVAIGBA/WMSeg
Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-way Attentions of Auto-analyzed Knowledge
����:Yuanhe Tian, Yan Song, Xiang Ao, Fei Xia, Xiaojun Quan, Tong Zhang, Yonggang Wang
���ĵ�ַ:https://www.aclweb.org/anthology/2020.acl-main.735/
GitHub:https://github.com/SVAIGBA/TwASP
�ο�:
��1��Junjie Xing, Kenny Zhu, and Shaodian Zhang. 2018.
Adaptive Multi-task Transfer Learning for Chinese Word Segmentation in Medical Text. In Proceedings of the 27th International Conference on Computational Linguistics, pages 3619�C3630.
��2��Qi Wang, Yangming Zhou, Tong Ruan, Daqi Gao,
Yuhang Xia, and Ping He. 2019. Incorporating Dictionaries into Deep Neural Networks for the Chinese Clinical Named Entity Recognition. Journal of biomedical informatics, 92:103133.
��3��Yan Xu, Yining Wang, Tianren Liu, Jiahua Liu, Yubo
Fan, Yi Qian, Junichi Tsujii, and Eric I Chang. 2014. Joint Segmentation and Named Entity Recognition using Dual Decomposition in Chinese discharge summaries. Journal of the American Medical Informatics Association, 21(e1):e84�Ce92.
��4��Dong Xu, Meizhuo Zhang, Tianwan Zhao, Chen Ge,
Weiguo Gao, Jia Wei, and Kenny Q Zhu. 2015. Datadriven Information Extraction from Chinese Electronic Medical Records. PloS one, 10(8):e0136270.
��5��Yu-Bing Li, Xue-Zhong Zhou, Run-Shun Zhang, YingHui Wang, Yonghong Peng, Jing-Qing Hu, Qi Xie, Yan-Xing Xue, Li-Li Xu, Xiao-Fang Liu, et al. 2015. Detection of Herb-Symptom Associations from Traditional Chinese Medicine Clinical Data. EvidenceBased Complementary and Alternative Medicine,2015.
��6��Shaodian Zhang, Tian Kang, Xingting Zhang, Dong Wen, No��mie Elhadad, and Jianbo Lei. 2016. Speculation Detection for Chinese Clinical Notes: Impacts of Word Segmentation and Embedding Models. Journal of biomedical informatics, 60:334�C341.
��7��Bin He, Bin Dong, Yi Guan, Jinfeng Yang, Zhipeng
Jiang, Qiubin Yu, Jianyi Cheng, and Chunyan Qu.2017. Building a Comprehensive Syntactic and Semantic Corpus of Chinese Clinical Texts. Journal of biomedical informatics, 69:203�C217.