OpenVINO计算机视觉模型加速教程
一、基础
1、OpenVINO介绍
OpenVINO是2018年5月份发布的第一个版本,为什么要选择在这个时候呢?在这之前深度学习是很火的,有很多计算机视觉的框架,在深度学习之前比如opencv,matlab,有这些计算机视觉开发的框架但是深度学习发展之后这些视觉框架就面临尴尬的问题?就是他们都是针对传统的计算机视觉的,对于这些深度学习的这些计算机视觉,虽然他们也做了一些不同程度的支持,但是从本质上来说,他们不是一个全新的全面支持计算机深度学习部署的一个框架的,因此在这个时候intel就发现这里面所蕴含的市场需求能量以及开发者的需求,所以它就开源了OpenVINO这个计算机视觉的框架。
这个框架相比于其他的传统视觉框架如opencv,matlab等有哪些优势呢?就是他支持多种边缘硬件平台上面的加速计算(举一个简单的例子:比喻opencv在计算机或其他计算机视觉硬件平台上你运行一个CDNN这样一个计算机人脸识别的训练模型,在CPU上是一秒5帧的存在,但是用来OpenVINO加速那么就可以做到每秒20帧的存在,30帧都有可能,因此OpenVINO就可以完成平均提速5-10倍)。
为什么能够提高这么高的速度呢?就在于openVINO是intel采用了多种硬件平台指令以及多线程方法,从底层指令集方面就对训练模型进行了一个融合加速。
现在最新的版本是2021.2版本,同时intel在openVINO这个框架里面还使用了大量的预训练模型,因此说支持多种常见场景的视觉任务的快速演示(比如说我们人脸识别,他有四个轻量级的模型都只有几M,然后速度可以达到100多帧每秒并且特别稳定,行人检测,车牌检测识别,场景文字检测识别,对于这些常见的视觉任务基于openVINO可以很快的实现他的demo运行,就是说可以做到快速演示的效果这也是openVINO的一大优势,这样也就可以省略你大量的训练,找数据训练模型这些时间可以完成快速交付)
https://docs.openvinotoolkit.org/2021.1/index.html 官网
OpenVINO里面还分为两个部分,两个最重要的组件,一个是模型优化器就是来进行模型转换的,第二个是推理引擎就是用来模型加速的。有了这两个东西我们的OpenVINO才可以对接到我们说用Epoch 训练出来的模型那我就可以转换为orx然后转接给OpenVINO进行加速调用。比如说我们是tensorflow训练出来的模型你生成的pp文件之后我们也可以转换给OpenVINO,通过它的MO模型优化器来给他转换成中间格式然后进行调用加速。所以就说可以实现对接到我们几乎所有深度学习的所训练所产生出来的模型都可以由OpenVINO来进行部署然后主要是支持CPU和intel所支持的图形卡,fpga以及计算棒等各种多边缘硬件的计算上面都可以进行部署及一些公共机上面都可以进行部署。
他的优势就是可以去掉N卡,在控制模型不是很大的情况下,满足生产条件的时候我通过CPU就可以支持了然后从而我们就可以不需要换一个高层的n卡了(N卡意思就是NVIDIA系列的显卡),从而将成本优势显著提升。因此是一个很好的深度学习模型部署框架。
并且同时intel在OpenVINO中将原来的Opencv的一些基础传统的计算机视觉相关的东西给也整合进去了,因此一旦有了OpenVINO那么你也就拥有了opencv所有的功能并且加上深度学习和部署框架加速的功能。因此openVINO就是这样一个计算机视觉相关的框架。
2、课程涉及
OpenVINO C++/Python开发环境配置、OpenVINO C++/Python SDK开发技巧、还有就是对ONNX格式模型和Tensorflow模型与OpenVINO的支持,最新的YOLOV5转ONNX后与openVINO结合的代码演示。
3、OpenVINO开发环境安装与搭建
OpenVINO介绍就是快速构建视觉应用原型系统与解决方案,在端侧设备上部署并实时运行模型,他的作用就是在我们pc电脑和一些板卡上都可以实时运行。使用的版本是2021.2版本,最新的版本。

图片1
3.1、系统卸载vs、安装工具VS2019、OpenVINO_2021.2.185 、Python3.6.5 、cmake
安装卸载vs工具 https://www.cnblogs.com/kuangqiu/p/7760281.html,
工具vs删除链接;https://github.com/Microsoft/VisualStudioUninstaller/releases
regedit可以查看一下注册表vs删除;https://blog.csdn.net/inch2006/article/details/102372940
VS2019下载;https://visualstudio.microsoft.com/zh-hans/ 之后执行exe,下载c++库进行安装
OpenVINO_2021.2.185 需注册下载 双击安装即可 https://docs.openvinotoolkit.org/2021.2/openvino_docs_install_guides_installing_openvino_windows.html 都有对应的安装步骤和对应环境安装网页步骤 注意还要执行脚本
Python3.6.5 安装链接 https://www.jb51.net/article/147615.htm 官网链接 https://www.python.org/downloads/windows/
Pycharm IDE 使用教程https://www.runoob.com/python/python-ide.html 官网链接 https://www.jetbrains.com/pycharm/download/#section=windows
cmake:CMake 3.10 or higher 64-bit NOTE: If you want to use Microsoft Visual Studio 2019, you are required to install CMake 3.14.
cmake:链接:https://cmake.org/download/ 注意配置环境变量
3.2、OpenVINO安装目录熟悉
deployment_tools
inference_engine 推理引擎
model_optimizer 模型优化器
ngraph 最新的也属于推理引擎里面的
open_model_zoo 开放模型库
models
intel interl自己所训练出来的模型库供我们所使用的,这里面只有模型的说明,
真正的使用还是需要tools->downloader ->downloader工具去下载
public 各色其他人提供的模型库
tools 帮助我们下载一些我们所需要的模型
downloader 下载、转换工具的,如pytorch_to_onnx转换、
3.3、安装环境测试
执行openvino_2021.2.185\deployment_tools\demo\demo_security_barrier_camera.bat 这个脚本,测试C++环境。这是车辆车牌号识别模型的案例,如果环境正确的话最后的效果图为。
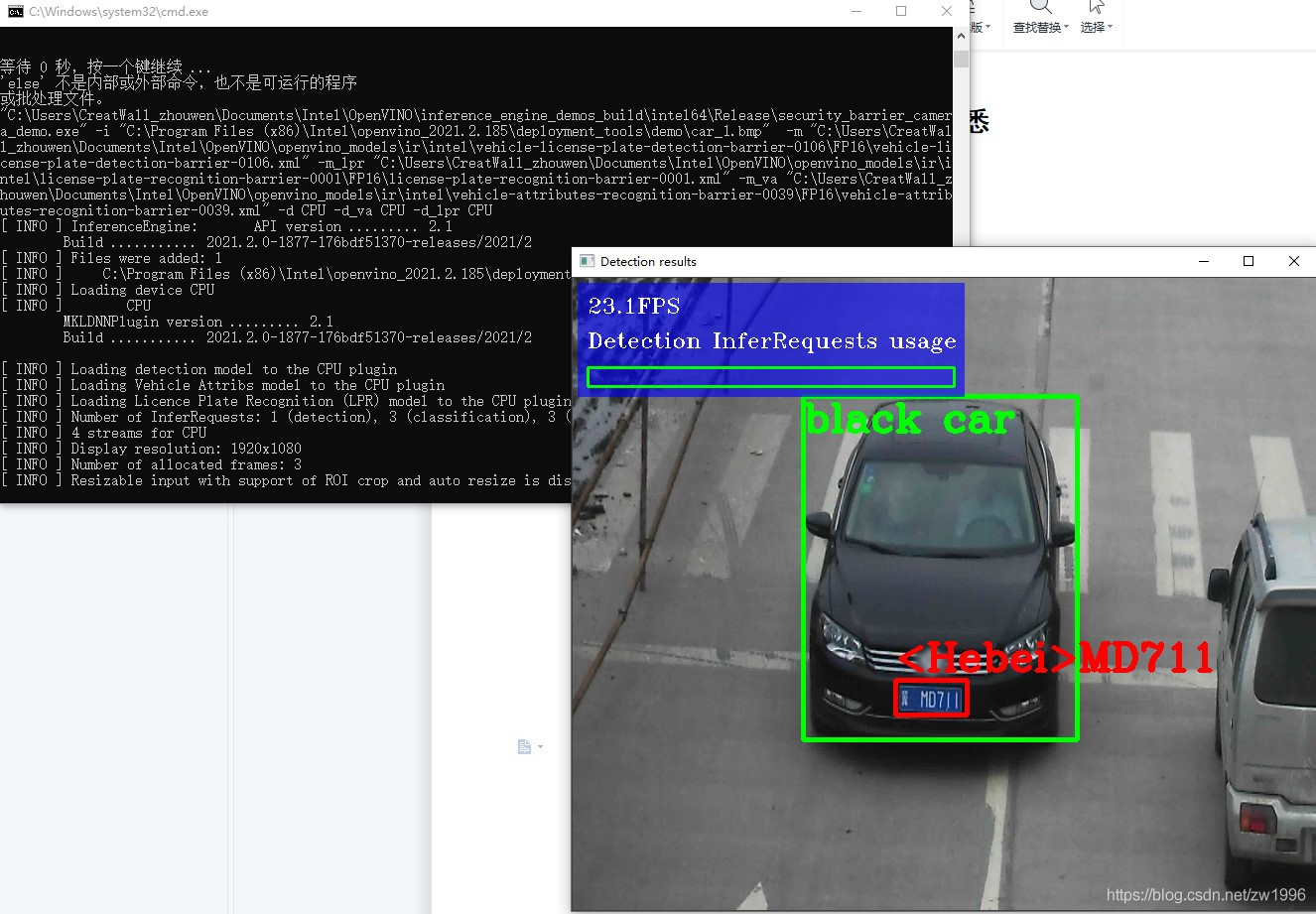
图2
3.4、OpenVINO基本概要
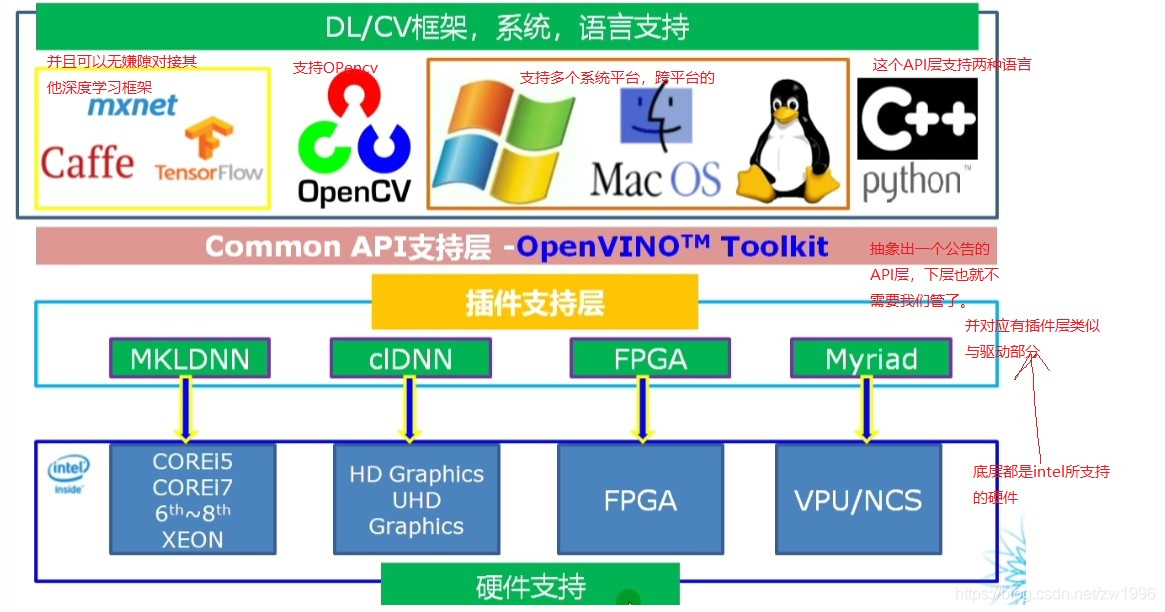
图3
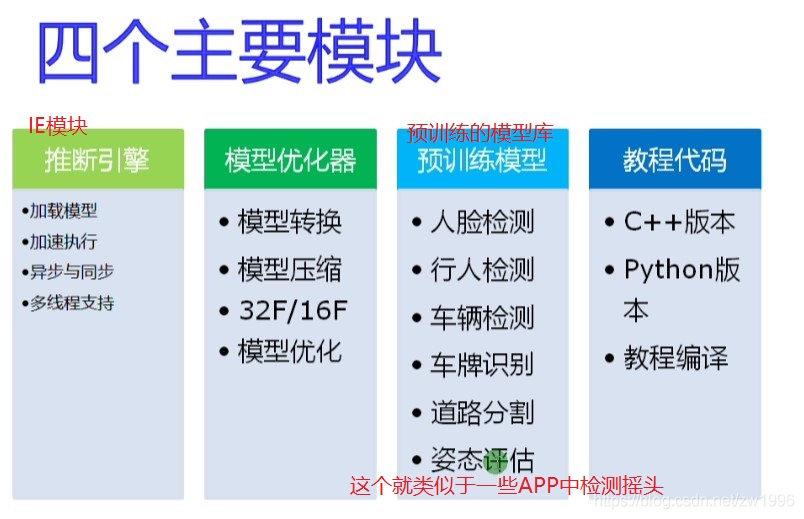
图4
3.5、C++ vs开发环境配置测试
配置包含目录
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\include
C:\Program Files (x86)\Intel\openvino_2021.2.185\opencv\include\opencv2
配置库目录
C:\Program Files (x86)\Intel\openvino_2021.2.185\opencv\lib
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\lib\intel64\Release
配置链接依赖库
使用python脚本输出
C:\Program Files (x86)\Intel\openvino_2021.2.185\opencv\lib 不带d的451.lib库
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\lib\intel64\Release的lib库
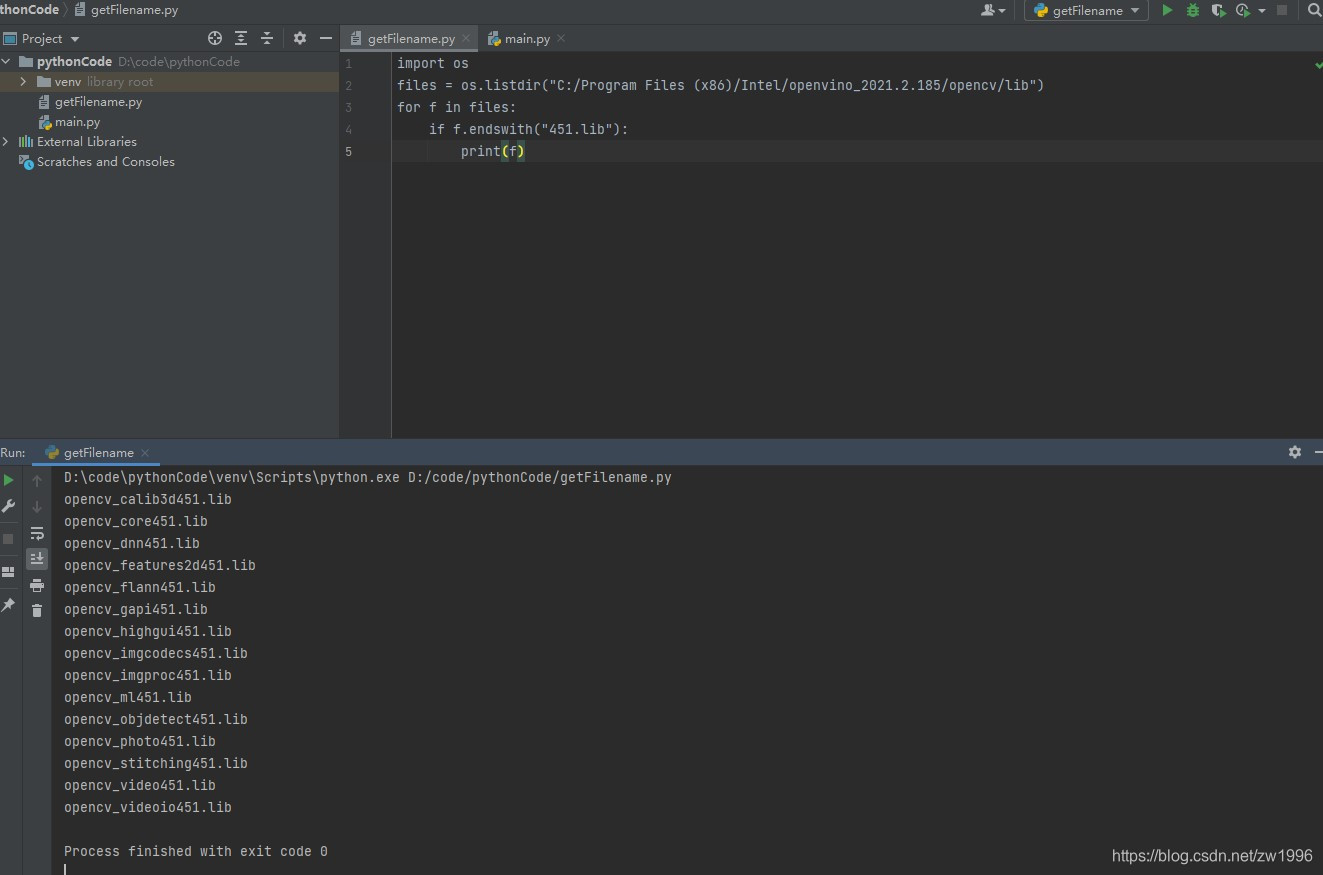
图5
配置环境变量
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\external\tbb\bin
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\inference_engine\bin\intel64\Release
C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\ngraph\lib
C:\Program Files (x86)\Intel\openvino_2021.2.185\opencv\bin
测试代码
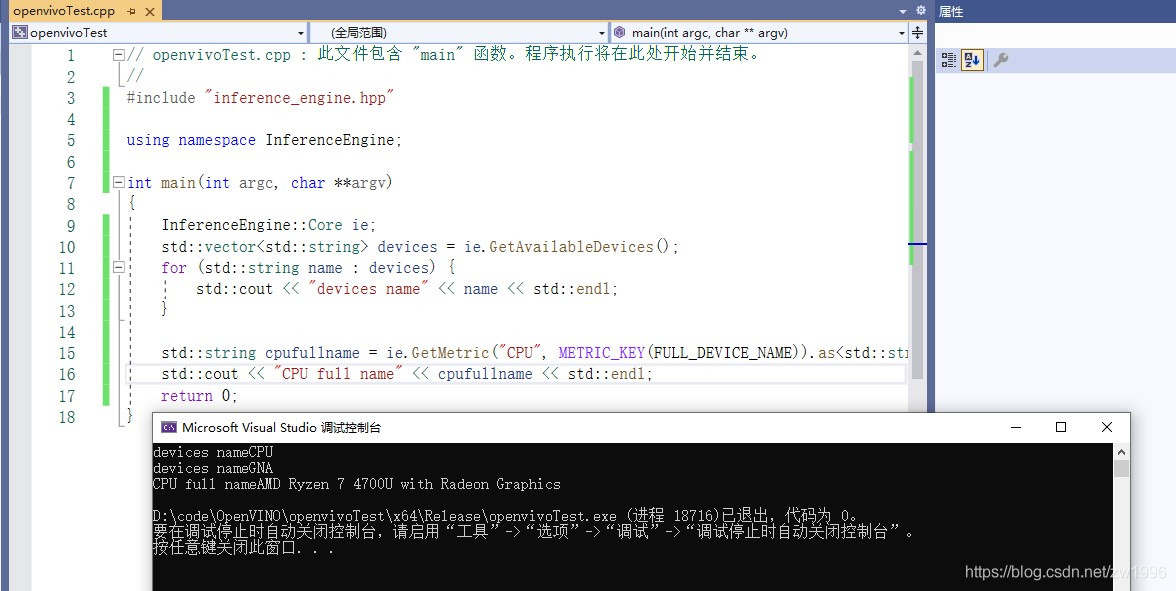
图6
举例一个一起学习的群友遇到的问题:无法定位程序输入点 报动态链接库inference_engine.dll的错误,如图
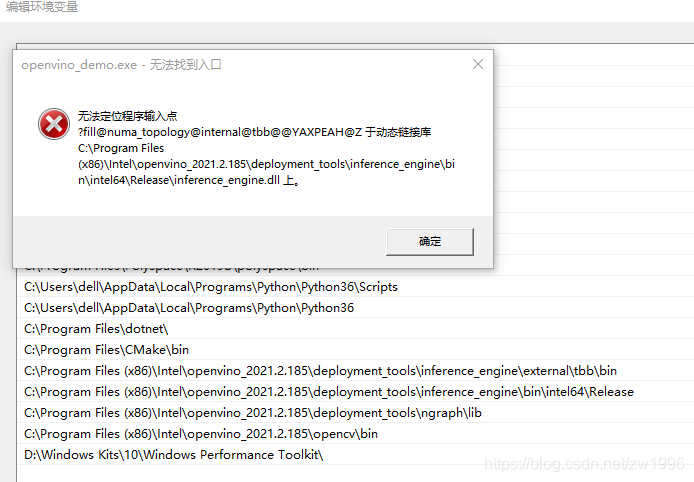
图9
问题解决方法:环境变量设置的时候要把openVINO相关的四个环境变量设置放到最前面,就解决了这个问题。
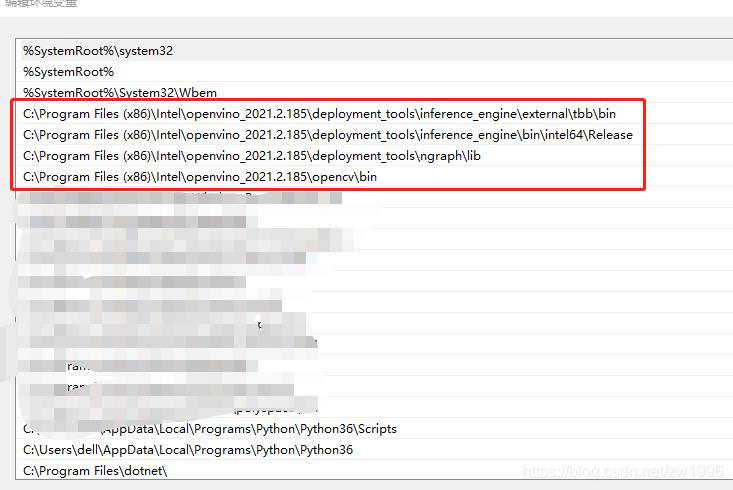
图10
3.6、OpenVINO SDK学习
入手的IE模块也就是推理模块,这是最常用的熟悉之后再看转换模块就简单了。
首先是OpenVINO开发流程也就是给你一个模型你如何运行一个模型完成推理然后进行显示等各个环节。
第二个就是查询你当前的设备硬件支不支持的问题,有一些查询硬件支持的函数,有哪里设备模块可以支持模型加速等。
第三个就是与你应用程序集成开发的SDK的应用与函数介绍,
OpenVINO IE开发流程:
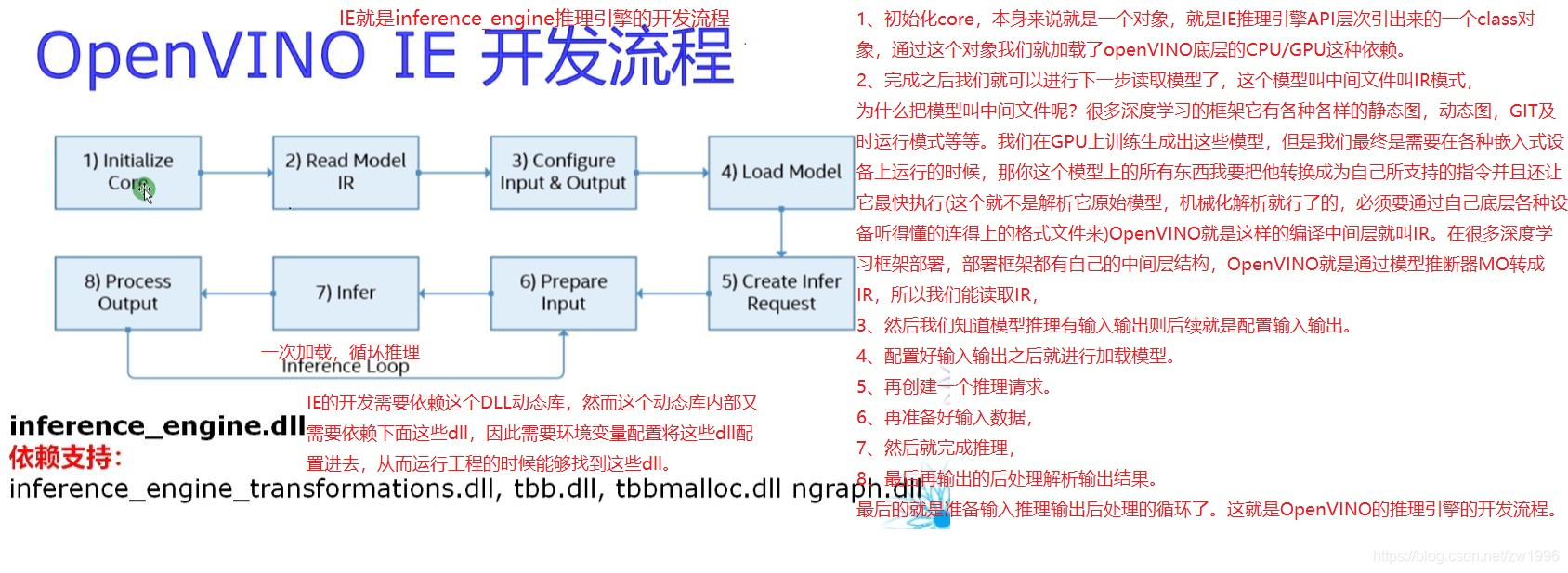
图7
1、初始化core,本身来说就是一个对象,就是IE推理引擎API层次引出来的一个class对象,通过这个对象我们就加载了openVINO底层的CPU/GPU这种依赖。
2、完成之后我们就可以进行下一步读取模型了,这个模型叫中间文件叫IR模式,
为什么把模型叫中间文件呢?很多深度学习的框架它有各种各样的静态图,动态图,GIT及时运行模式等等。我们在GPU上训练生成出这些模型,但是我们最终是需要在各种嵌入式设备上运行的时候,那你这个模型上的所有东西我要把他转换成为自己所支持的指令并且还让它最快执行(这个就不是解析它原始模型,机械化解析就行了的,必须要通过自己底层各种设备听得懂的连得上的格式文件来)OpenVINO就是这样的编译中间层就叫IR。在很多深度学习框架部署,部署框架都有自己的中间层结构,OpenVINO就是通过模型推断器MO转成IR,所以我们能读取IR。
3、然后我们知道模型推理有输入输出则后续就是配置输入输出。
4、配置好输入输出之后就进行加载模型。
5、再创建一个推理请求。
6、再准备好输入数据。
7、然后就完成推理。
8、最后再输出的后处理解析输出结果。
9、最后的就是准备输入推理输出后处理的循环了。这就是OpenVINO的推理引擎的开发流程。
硬件支持查询:
引入头文件:#include "inference_engine.hpp"
命名空间引入:using namespace InferenceEngine;
设备查询函数:
创建核心类对象:InferenceEngine::Core ie;
查询可用设备:std::vector<std::string> devices = ie.GetAvailableDevices();
输出设备全名:ie.GetMetric("CPU", METRIC_KEY(FULL_DEVICE_NAME)).as<std::string>();
IE相关API函数支持:
核心类:InferenceEngine::Core ie;
进行数据转换的:InferenceEngine::Blob、InferenceEngine::TBlob、 InferenceEngine:: NV12Blob
格式设置:InferenceEngine::BlobMap
输入输出格式读取设置:InferenceEngine::InputsDataMap,InferenceEngine::InputInfo,InferenceEngine::OutputDataMap
一些包装类:
通过Core进行read之后得到CNN网络:InferenceEngine::CNNNetwork
将CNN网络变成可执行网络:InferenceEngine::ExecutableNetwork
请求,可以得到推理的对象,最后解析输出:InferenceEngine::InferRequest
二、项目实践
1、ResNet18实现图像分类
1.1、预训练模型介绍:OpenVINO自带的模型ResNet18图像分类的模型,这个图像分类的模型是怎么把他变成IR的,ResNet18本身是一个pytorch模型是怎么转换成ONNX格式然后又转换为IR的格式,最后完成演示的。这个怎么转是有一套流程的之后再说。
现在是如果有现成的模型存在了,我们怎么通过OpenVINO IE 的SDK将它用起来,实现一个图像分类的推理部署。
1.2、预处理图像:图像是有一个预处理的过程,就是说我们要使用这个模型的所有图像首先要把它转换到0-1之间,正常图像是在0-255之间RGB三个通道,这边的输出是0-1之间。
1.3、均值mean=[0.485, 0.456, 0.406] 方差std=[0.229, 0.224, 0.225] 操作是减去它的均值,除以它的方差,这部分就是通过opencv的API来处理。
1.4、输入格式输出格式,每种深度学习框架输入输出都有自己定义的格式的, 输入格式NCHW (number of images多少张图, channel图像的通道数,H高度,W宽度 )=13244*244 就表示是彩色图像每次推理一张图片宽高为244。
推理完成之后的输出格式:1X1000(这个模型是基于imagenet_classes数集训练的因为他有1000个分类,因此他的输出是1乘以1000)这样的话我们寻找他的最大的index对应的string就是我们图像的确切分类了。
1.5代码层面怎么做:
1、初始化Core ie
2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
3、获取输入与输出格式并设置精度
4、获取可执行网络并链接硬件
5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
6、获取输入的Blob 格式转换类对象
7、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
8、执行推理
9、获取我们的output
10、最后需要获取输出的维度信息 解析数据 并输出最大的那个就是我们resnet18图像识别出来的结果
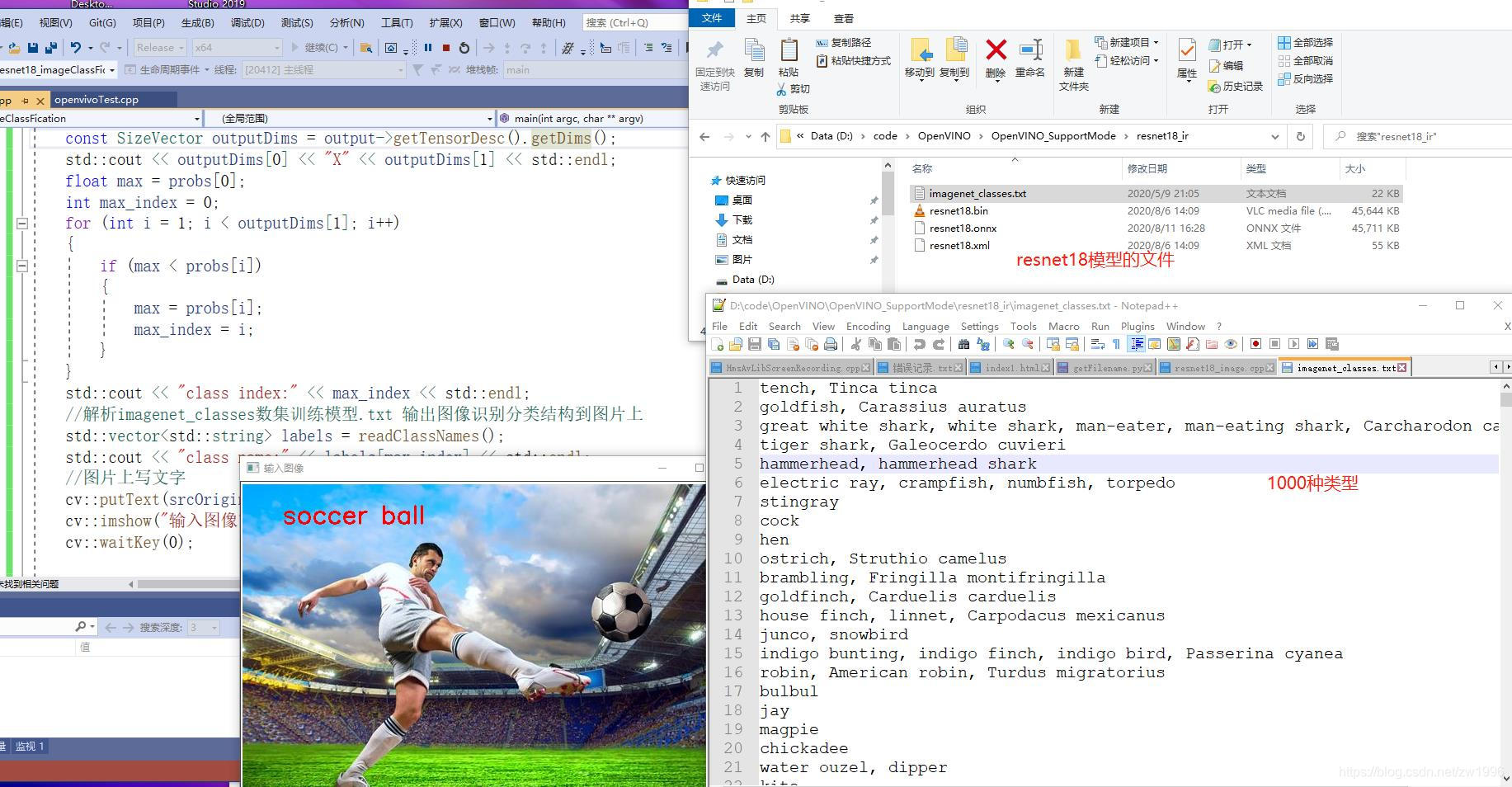
图8
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
std::string labels_txt_file = "D:/code/OpenVINO/OpenVINO_SupportMode/resnet18_ir/imagenet_classes.txt"; //模型的文件名
std::vector<std::string> readClassNames();//读取文件的函数
int main(int argc, char** argv)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/resnet18_ir/resnet18.xml";
std::string binFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/resnet18_ir/resnet18.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
//因为这个模型是来自pytorch数字集所以它的精度是FP32的全精度的 所以我们这个时候需要设置FP32
input_data->setPrecision(Precision::FP32);
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::RGB);
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
//因为这个模型是来自pytorch数字集所以它的精度是FP32的全精度的 所以我们这个时候需要设置FP32
output_data->setPrecision(Precision::FP32);
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto infer_request = executable_network.CreateInferRequest();
//6、获取输入的Blob 格式转换类对象
auto input = infer_request.GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//7、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
cv::Mat srcOriginal = cv::imread("D:/succoBlar.png");//需要解析的原图
cv::Mat src;
cv::cvtColor(srcOriginal, src, cv::COLOR_BGR2RGB);// 因为resnet18模型接收的顺序是RGB的 而opencv的顺序是BGR的 需要进行一下转换再进行resnet18模型的图像预处理
cv::Mat blob_image;//转换为网络可以解析图片格式
cv::resize(src, blob_image, cv::Size(w, h));//转换大小
blob_image.convertTo(blob_image, CV_32F);//转换为浮点数
blob_image = blob_image / 255.0;//转换到0-1之间
cv::subtract(blob_image, cv::Scalar(0.485, 0.456, 0.406), blob_image);//每个通道的值都减去均值
cv::divide(blob_image, cv::Scalar(0.229, 0.224, 0.225), blob_image);// 每个通道的值都除以方差
//8、将设置好的数据设置到输入的Blob中 -> 实际上GetBlob()的时候就已经开辟好了存储输入图像数据内存空间
float* data = static_cast<float*>(input->buffer());//这就是直接将数据转换后填充到input那指定空间里面去了
//注意;opencv返回的mat图像的顺序是HWC 要将他转换为 NCHW 就是要将HWC类型的矩阵转换为NCHW类型 就是矩阵填充的问题
// HWC =》NCHW 转换
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image 是opencv过来的HWC格式 -》 转换为NCHW就是每一个通道变成一张图 按照通道顺序来的。第几个通道的就是第几张图的这种存放
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3f>(row, col)[ch];
}
}
}
//8、执行推理
infer_request.Infer();
//9、获取我们的output
auto output = infer_request.GetBlob(output_name);
const float* probs = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//将输出数据转换 Precision精度
//10、最后需要获取输出的维度信息 解析数据 并输出最大的那个就是我们resnet18图像识别出来的结果
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[0] << "X" << outputDims[1] << std::endl;
float max = probs[0];
int max_index = 0;
for (int i = 1; i < outputDims[1]; i++)
{
if (max < probs[i])
{
max = probs[i];
max_index = i;
}
}
std::cout << "class index:" << max_index << std::endl;
//解析imagenet_classes数集训练模型.txt 输出图像识别分类结构到图片上
std::vector<std::string> labels = readClassNames();
std::cout << "class name:" << labels[max_index] << std::endl;
//图片上写文字
cv::putText(srcOriginal, labels[max_index], cv::Point(50,50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imshow("输入图像", srcOriginal);
cv::waitKey(0);
return 0;
}
//解析imagenet_classes.txt 文件 获取到1000种类别
std::vector<std::string> readClassNames()
{
std::vector<std::string> classNames;
std::ifstream fp(labels_txt_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
2、SSD车辆与车牌检测
上面项目我们使用resnet18这个模型实现了图像分类这个功能,resnet18这种残差系列的网络它也是一种基础的骨干网络,实现图像分类是他的一个基本功能,在计算机视觉当中除了分类是我们最常见的,另外一个最常见的就是目标检测。所以接下来我们就实现一个对象检测的网络如何通过openVINO实现部署和加速。这边我们使用了openVINO模型库当中本身自带的一个模型,这个模型就可以很快的帮我们实现一个特定应用场景的对象检测,这个应用场景就是车辆与车牌的检测,在高速路卡口是非常常见的。本案例就是实现如何通过OpenVINO这个框架来实现一个快速的车辆和车牌的检测。
2.1、车辆车牌检测实践案例
2.1.1、模型的介绍

图11
这边也要讲解一下;你可能有一些很通用的模型,然后会很大全场景都可以检测,这种就是开放场景检测,但是在实际的应用当中,可能你的程序的应用场景是应用在某一个垂直的领域上,你只要在这个上面做到最好就行了,所以这个时候了你就可能把你的模型建立的很小,但是模型也会变成在特定的场景下使用才会识别率高。例如我们当前这个车辆车牌检测的模型就很小,但是在高速路卡口这个应用场景就很好了。
"C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\open_model_zoo\models\intel\vehicle-license-plate-detection-barrier-0106\description\vehicle-license-plate-detection-barrier-0106.html"可以查看这个文件,就是官方对ehicle-license-plate-detection-barrier-0106这个模型做出的官方说明。
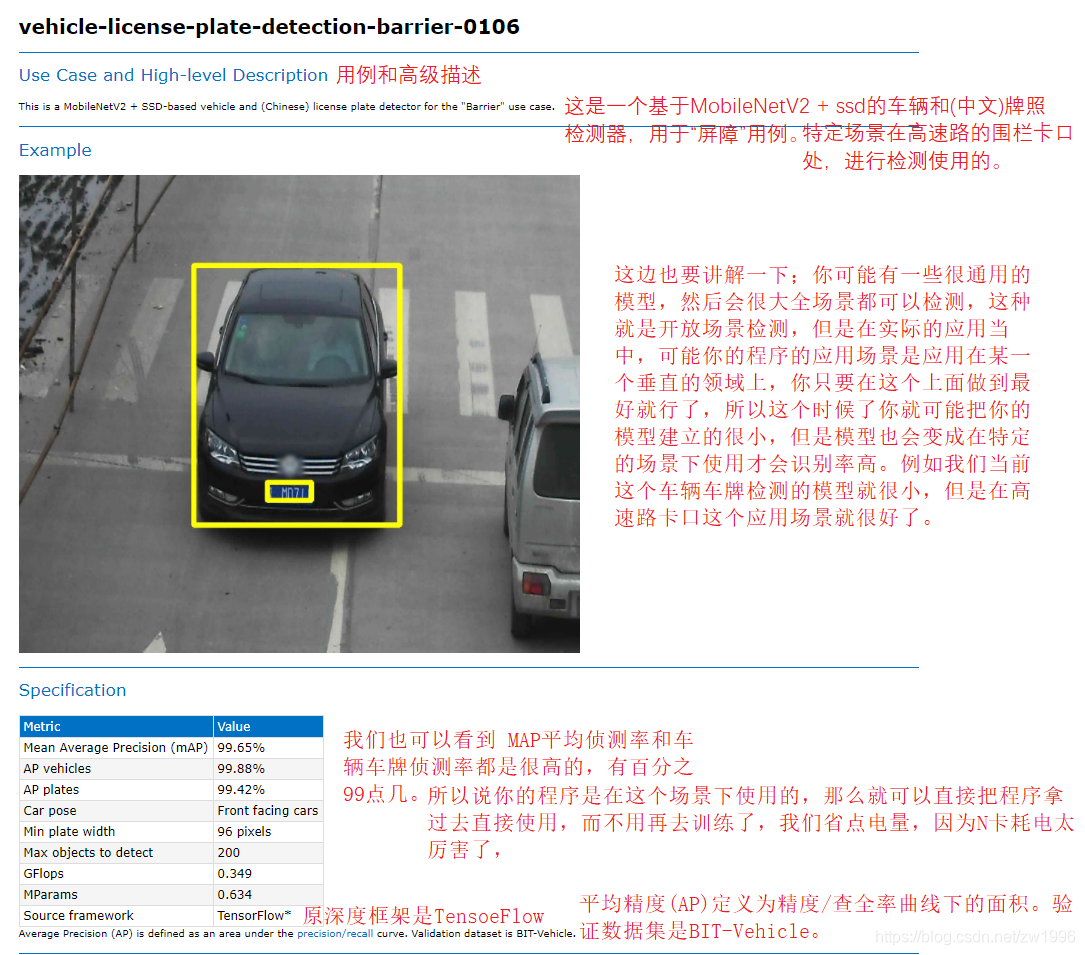
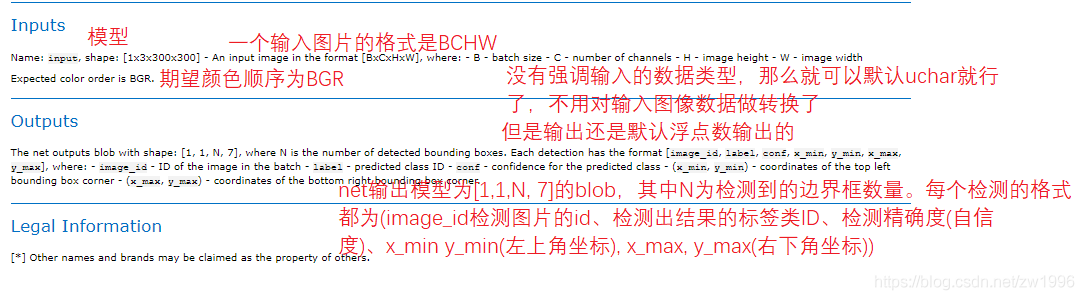
图12 13
2.1.2、代码的流程调用顺序
与之前resnet18图像分类也差不多,
加载模型
设置输入输出
构建输入
执行推断
解析输出
显示结果
都可以直接拿上次代码进行改造。
2.1.3、下载OpenVINO模型库里面的模型
之前知道openvino_2021.2.185\deployment_tools\open_model_zoo\models\intel在这个目录下就是OpenVINO支持的intel的所有模型库,但是这里只有介绍说明,实践模型下载还是需要去通过工具下载的。
Intel官方模型的工具下载;
使用这个目录下的这个脚本;“C:\Program Files (x86)\Intel\openvino_2021.2.185\deployment_tools\open_model_zoo\tools\downloader\downloader.py”,
执行命令;
之前遇到了权限无法下载的问题:解决方法是找到cmd.exe用管理员方式打开即可。
下载成功后会在生成vehicle-license-plate-detection-barrier-0106文件夹
vehicle-license-plate-detection-barrier-0106 会下载三种不同量化比例的模型
FP16 半精度的
FP16-INT8 8位量化的
FP32 全精度的
我们在PC上使用的是FP32全精度的。
2.1.4、代码演示

图14
实例代码
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
int main(int argc, char** argv)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/vehicle-license-plate-detection-barrier-0106/FP32/vehicle-license-plate-detection-barrier-0106.xml";
std::string binFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/vehicle-license-plate-detection-barrier-0106/FP32/vehicle-license-plate-detection-barrier-0106.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto infer_request = executable_network.CreateInferRequest();
//6、获取输入的Blob 格式转换类对象
auto input = infer_request.GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//7、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
cv::Mat src = cv::imread("D:/Vihecle.jpg");//需要解析的原图
//cv::namedWindow("input",cv::WINDOW_FREERATIO);//设置窗口自由比例 保证图片太大也能正常显示
int im_h = src.rows;
int im_w = src.cols;
cv::Mat blob_image;//转换为网络可以解析图片格式
cv::resize(src, blob_image, cv::Size(w, h));//转换大小
//8、将设置好的数据设置到输入的Blob中 -> 实际上GetBlob()的时候就已经开辟好了存储输入图像数据内存空间
unsigned char* data = static_cast<unsigned char*>(input->buffer());//这就是直接将数据转换后填充到input那指定空间里面去了
//注意;opencv返回的mat图像的顺序是HWC 要将他转换为 NCHW 就是要将HWC类型的矩阵转换为NCHW类型 就是矩阵填充的问题
// HWC =》NCHW 转换
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image 是opencv过来的HWC格式 -》 转换为NCHW就是每一个通道变成一张图 按照通道顺序来的。第几个通道的就是第几张图的这种存放
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
//8、执行推理
infer_request.Infer();
//9、获取我们的output
auto output = infer_request.GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//10、最后需要获取输出的维度信息 解析数据
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//是输出的那个N
const int object_size = outputDims[3];//是输出的那个7
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n*object_size + 1];// +1表示输出的是7个里面的第二个lableID
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //输出得到的都是0-1的浮点数坐标 要乘以原宽高才是实际坐标
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
if (lable == 2)//车牌
{
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
}
else
{
cv::rectangle(src, box, cv::Scalar(0, 0, 255), 2, 8, 0);
}
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
}
}
cv::imshow("input", src);
cv::waitKey(0);
return 0;
}
2.2、中文车牌识别
为什么是中文车牌识别呢?因为OpenVINO训练出来的模型十分友好,可以直接检测中文的车牌并输出结果。当然这个也是特定场景应用在高速路卡口的车牌检测识别的场景,是固定的应用场景上面可以使用的,但是你其他的场景你可以去训练它开源的训练,在github上,有训练的框架和脚本,是基于tersorflow1.x版本开发的。
2.2.1、模型介绍

图15
查看license-plate-recognition-barrier-0001.html 提供的官方模板介绍

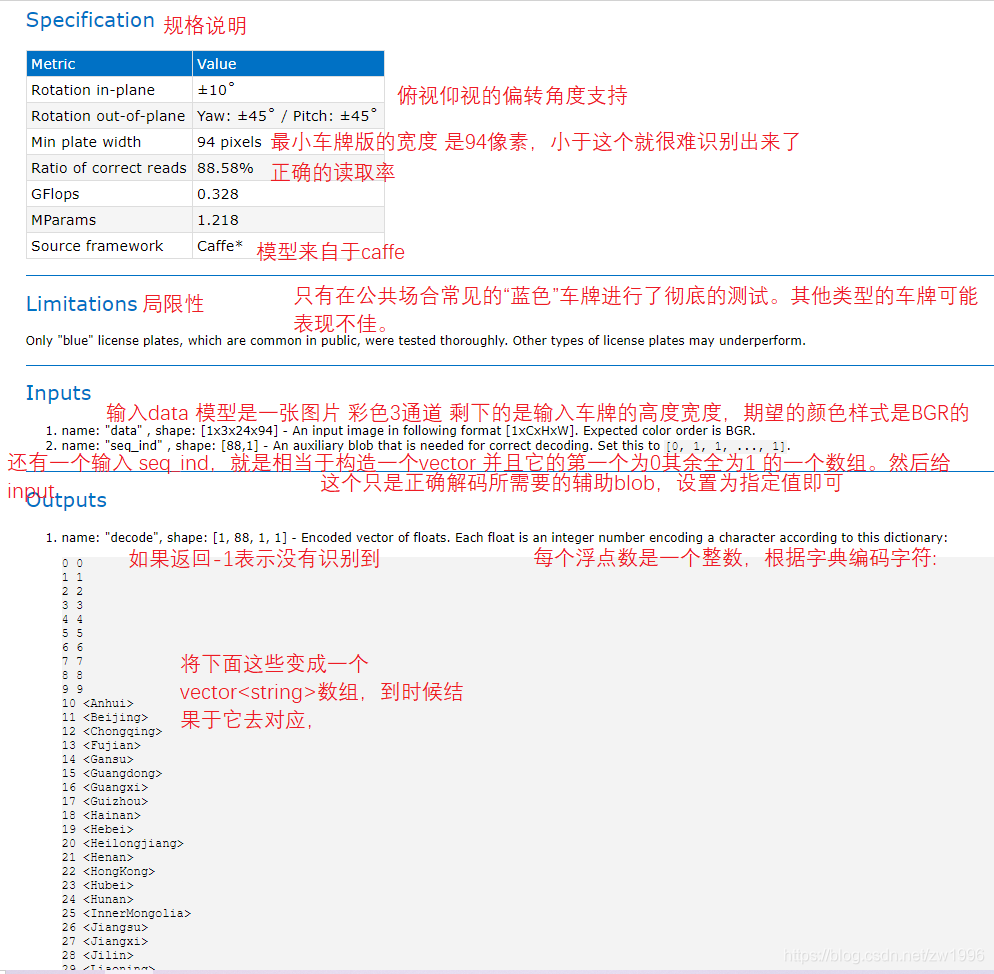
图16、17
2.2.2、调用执行流程
加载模型(两个模型(检测和识别),都只加载一次的)
检测车辆与车牌,如果是车牌那么就去识别车牌,如果是车辆就不做处理
2.2.3、代码演示
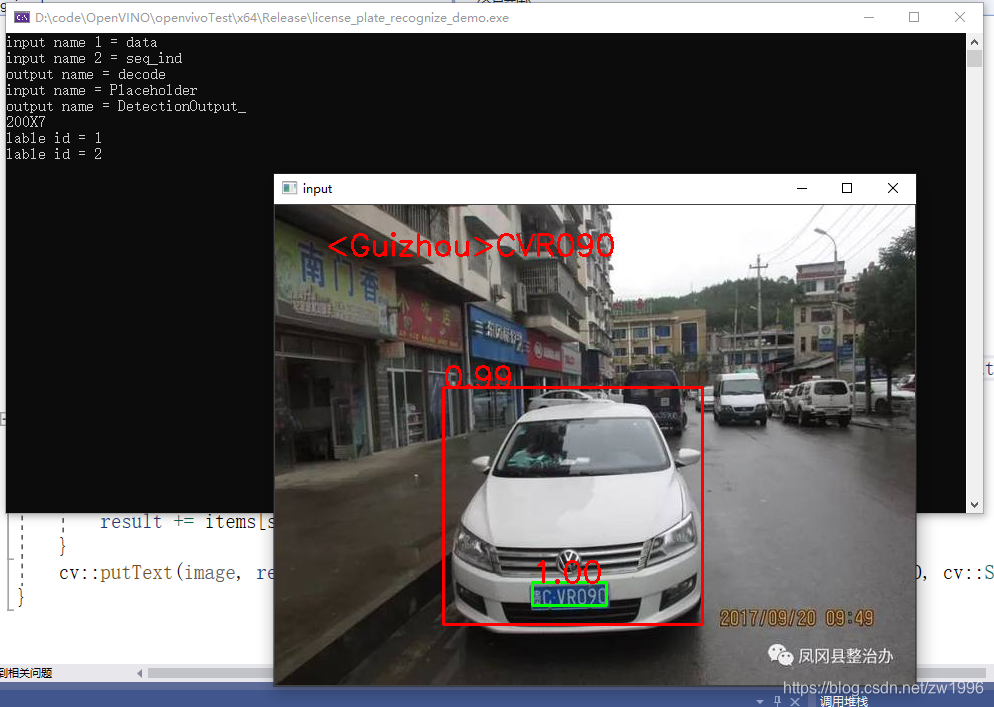
图18
实践代码
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
static const char* const items[] = {
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"<Anhui>", "<Beijing>", "<Chongqing>", "<Fujian>",
"<Gansu>", "<Guangdong>", "<Guangxi>", "<Guizhou>",
"<Hainan>", "<Hebei>", "<Heilongjiang>", "<Henan>",
"<HongKong>", "<Hubei>", "<Hunan>", "<InnerMongolia>",
"<Jiangsu>", "<Jiangxi>", "<Jilin>", "<Liaoning>",
"<Macau>", "<Ningxia>", "<Qinghai>", "<Shaanxi>",
"<Shandong>", "<Shanghai>", "<Shanxi>", "<Sichuan>",
"<Tianjin>", "<Tibet>", "<Xinjiang>", "<Yunnan>",
"<Zhejiang>", "<police>",
"A", "B", "C", "D", "E", "F", "G", "H", "I", "J",
"K", "L", "M", "N", "O", "P", "Q", "R", "S", "T",
"U", "V", "W", "X", "Y", "Z"
};
void load_plate_recog_model(InferenceEngine::InferRequest &plate_request, std::string &plate_input_name1, std::string &plate_input_name2, std::string &plate_output_name);
void fetch_plate_text(InferenceEngine::InferRequest& plate_request, std::string& plate_input_name1, std::string& plate_input_name2, std::string& plate_output_name, cv::Mat &image, cv::Mat plateROI);
int main(int argc, char** argv)
{
InferenceEngine::InferRequest plate_request;
std::string plate_input_name1;//这个名字虽然官方文档说了叫什么名字,但是有时候有bug,因此最后是代码获取名字
std::string plate_input_name2;
std::string plate_output_name;
load_plate_recog_model(plate_request, plate_input_name1, plate_input_name2, plate_output_name);//加载车牌识别模型
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/vehicle-license-plate-detection-barrier-0106/FP32/vehicle-license-plate-detection-barrier-0106.xml";
std::string binFilename = "D:/code/OpenVINO/OpenVINO_SupportMode/vehicle-license-plate-detection-barrier-0106/FP32/vehicle-license-plate-detection-barrier-0106.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto infer_request = executable_network.CreateInferRequest();
//6、获取输入的Blob 格式转换类对象
auto input = infer_request.GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//7、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
cv::Mat src = cv::imread("D:/Vihecle.jpg");//需要解析的原图
//cv::namedWindow("input",cv::WINDOW_FREERATIO);//设置窗口自由比例 保证图片太大也能正常显示
int im_h = src.rows;
int im_w = src.cols;
cv::Mat blob_image;//转换为网络可以解析图片格式
cv::resize(src, blob_image, cv::Size(w, h));//转换大小
//8、将设置好的数据设置到输入的Blob中 -> 实际上GetBlob()的时候就已经开辟好了存储输入图像数据内存空间
unsigned char* data = static_cast<unsigned char*>(input->buffer());//这就是直接将数据转换后填充到input那指定空间里面去了
//注意;opencv返回的mat图像的顺序是HWC 要将他转换为 NCHW 就是要将HWC类型的矩阵转换为NCHW类型 就是矩阵填充的问题
// HWC =》NCHW 转换
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image 是opencv过来的HWC格式 -》 转换为NCHW就是每一个通道变成一张图 按照通道顺序来的。第几个通道的就是第几张图的这种存放
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
//8、执行推理
infer_request.Infer();
//9、获取我们的output
auto output = infer_request.GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//10、最后需要获取输出的维度信息 解析数据
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//是输出的那个N
const int object_size = outputDims[3];//是输出的那个7
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1表示输出的是7个里面的第二个lableID
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //输出得到的都是0-1的浮点数坐标 要乘以原宽高才是实际坐标
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
if (lable == 2)//车牌
{
// recognize plate 识别车牌
cv::Rect plate_roi;//每边都比检测出来的矩形多出一点点,便于识别
plate_roi.x = box.x - 5;
plate_roi.y = box.y - 5;
plate_roi.width = box.width + 10;
plate_roi.height = box.height + 10;
fetch_plate_text(plate_request, plate_input_name1, plate_input_name2, plate_output_name, src, src(plate_roi));
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
}
else
{
cv::rectangle(src, box, cv::Scalar(0, 0, 255), 2, 8, 0);
}
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
}
}
cv::imshow("input", src);
cv::waitKey(0);
return 0;
}
void load_plate_recog_model(InferenceEngine::InferRequest& plate_request, std::string& plate_input_name1, std::string& plate_input_name2, std::string& plate_output_name)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/license-plate-recognition-barrier-0001/FP32/license-plate-recognition-barrier-0001.xml";
std::string binFilename = "D:/code/OpenVINO/license-plate-recognition-barrier-0001/FP32/license-plate-recognition-barrier-0001.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
int cnt = 0;
for (auto item : inputs)//因为这个模型有两个输入 则会循环两次的
{
if (cnt == 0)
{
plate_input_name1 = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
}
if (cnt == 1)
{
plate_input_name2 = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::FP32);
}
//input_name = item.first;
std::cout << "input name " << cnt+1 << " = " << item.first << std::endl;
cnt++;
}
for (auto item : outputs)
{
plate_output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << plate_output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
plate_request = executable_network.CreateInferRequest();
}
void fetch_plate_text(InferenceEngine::InferRequest& plate_request, std::string& plate_input_name1, std::string& plate_input_name2, std::string& plate_output_name, cv::Mat& image, cv::Mat plateROI)
{
//设置输入
auto input1 = plate_request.GetBlob(plate_input_name1);
size_t num_channels = input1->getTensorDesc().getDims()[1];
size_t h = input1->getTensorDesc().getDims()[2];
size_t w = input1->getTensorDesc().getDims()[3];
size_t image_size = h * w;
cv::Mat blob_image;//转换为网络可以解析图片格式
cv::resize(plateROI, blob_image, cv::Size(w, h));//转换大小
unsigned char* data = static_cast<unsigned char*>(input1->buffer());//这就是直接将数据转换后填充到input那指定空间里面去了
//注意;opencv返回的mat图像的顺序是HWC 要将他转换为 NCHW 就是要将HWC类型的矩阵转换为NCHW类型 就是矩阵填充的问题
// HWC =》NCHW 转换
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image 是opencv过来的HWC格式 -》 转换为NCHW就是每一个通道变成一张图 按照通道顺序来的。第几个通道的就是第几张图的这种存放
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
auto input2 = plate_request.GetBlob(plate_input_name2);
int max_sequence = input2->getTensorDesc().getDims()[0];//第二个输入的第一维是序列的长度
float* blob2 = input2->buffer().as<float*>();
blob2[0] = 0.0f;
std::fill(blob2 + 1, blob2 + max_sequence, 1.0f);
//执行推理
plate_request.Infer();
//输出结果
auto output = plate_request.GetBlob(plate_output_name);
const float* plate_data = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
std::string result;
for (int i = 0; i < max_sequence; i++)
{
if (plate_data[i] == -1)
break;
result += items[std::size_t(plate_data[i])];
}
cv::putText(image, result.c_str(), cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
}
3、行人检测
3.1、模型介绍


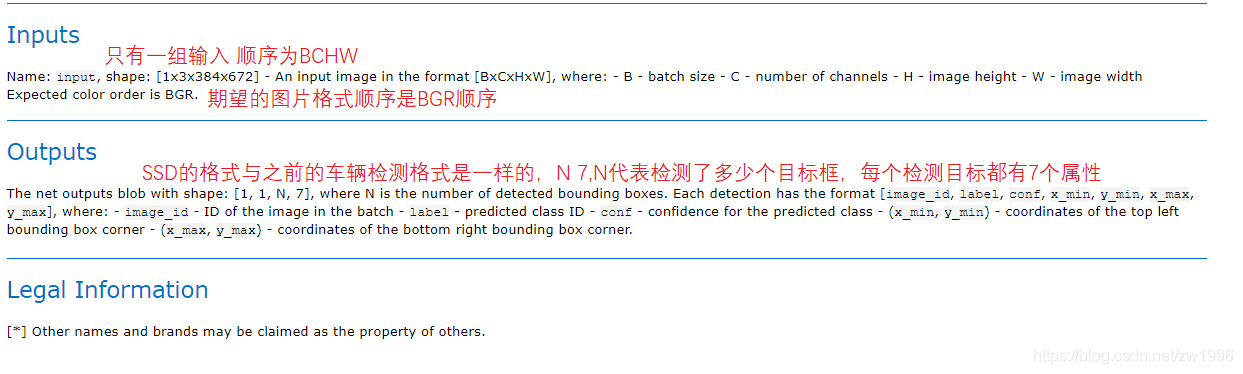
图 19 20 21
3.2、程序执行流程
因为都是SSD模型并且与车辆检测模型的输入输出格式一致都是BCHW的输入,1 1 N 7格式的输出,因此可以直接将车辆检测的整体代码直接拿过来用,只需要改一下模型路径即可。
3.3、程序演示部分
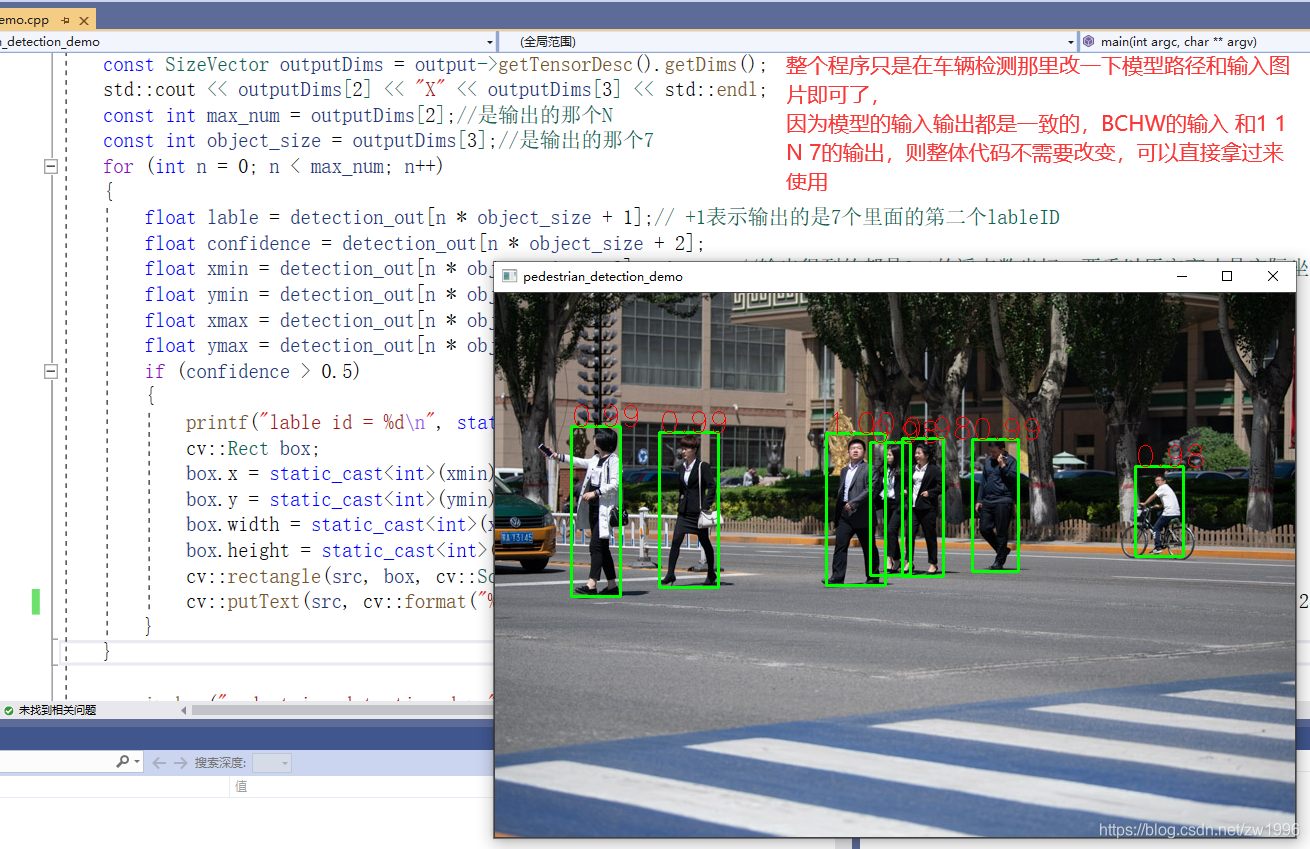
图22
3.4、视频当中的行人检测
代码流程差不多,只是将推理部分抽出成一个函数,通过传参的方式传入的,输入改为读取视频每帧都进行图像推理之后再显示。
可以看出对视频使用openVINO模型检测。对于速度方面是没有什么影响的,对于这个宽高不是很大的视频而言。openVINO模型对视频处理都是有每秒上百帧的效果的,也可以指定openVINO使用模型之后对模型也有很显著的加速效果的。
实践效果
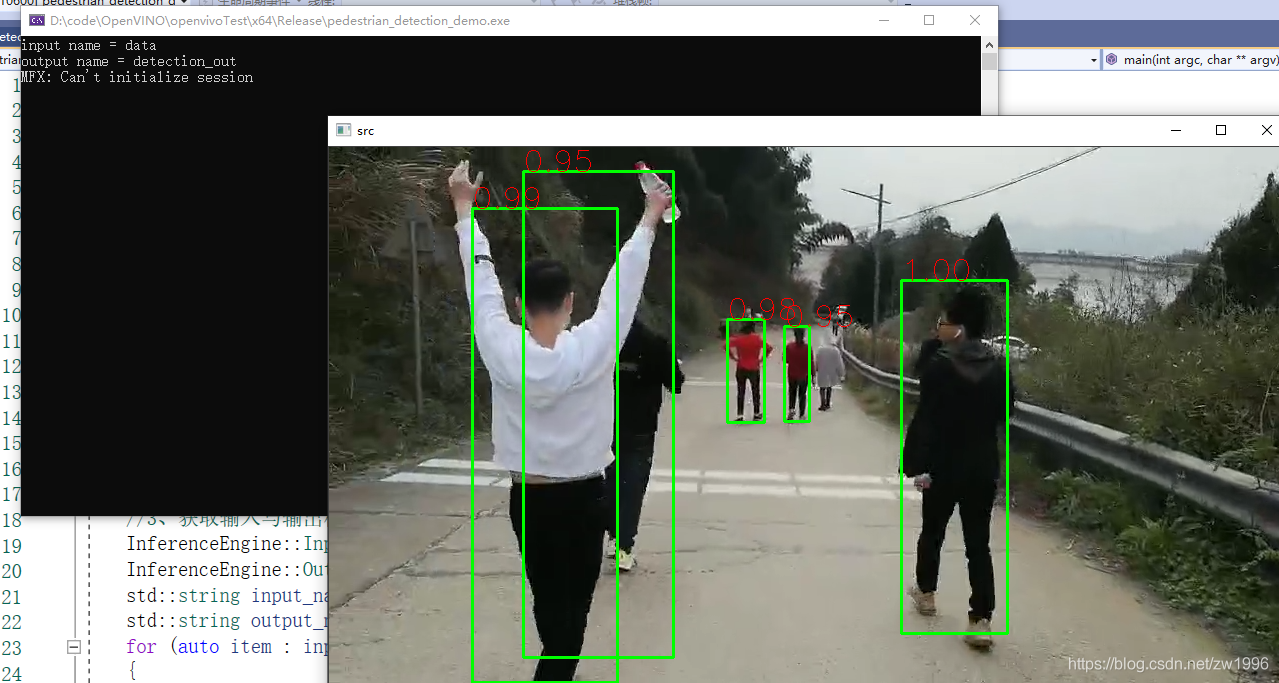
图23
代码实践
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
void infer_process(cv::Mat &src, InferenceEngine::InferRequest & infer_request, std::string& input_name, std::string& output_name);
//图像行人检测
int main(int argc, char** argv)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/pedestrian-detection-adas-0002/FP32/pedestrian-detection-adas-0002.xml";
std::string binFilename = "D:/code/OpenVINO/pedestrian-detection-adas-0002/FP32/pedestrian-detection-adas-0002.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto infer_request = executable_network.CreateInferRequest();
//6、创建视频流/加载视频文件
cv::VideoCapture capture("D:/padestrian_detection.mp4");
cv::Mat src;
while (true)
{
bool ret = capture.read(src);
if (ret == false)
break;
//7、循环执行推理
infer_process(src, infer_request, input_name, output_name);
cv::imshow("src", src);
char c = cv::waitKey(1);
if (c == 27)//按下esc
break;
}
//cv::imshow("pedestrian_detection_demo", src);
cv::waitKey(0);
return 0;
}
void infer_process(cv::Mat& src, InferenceEngine::InferRequest& infer_request, std::string& input_name, std::string& output_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request.GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//2、对输入图像转换
int im_h = src.rows;
int im_w = src.cols;
cv::Mat blob_image;//转换为网络可以解析图片格式
cv::resize(src, blob_image, cv::Size(w, h));//转换大小
//3、将设置好的数据设置到输入的Blob中 -> 实际上GetBlob()的时候就已经开辟好了存储输入图像数据内存空间
unsigned char* data = static_cast<unsigned char*>(input->buffer());//这就是直接将数据转换后填充到input那指定空间里面去了
//注意;opencv返回的mat图像的顺序是HWC 要将他转换为 NCHW 就是要将HWC类型的矩阵转换为NCHW类型 就是矩阵填充的问题
// HWC =》NCHW 转换
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image 是opencv过来的HWC格式 -》 转换为NCHW就是每一个通道变成一张图 按照通道顺序来的。第几个通道的就是第几张图的这种存放
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
//4、执行推理
infer_request.Infer();
//5、获取我们的output
auto output = infer_request.GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//6、最后需要获取输出的维度信息 解析数据
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//是输出的那个N
const int object_size = outputDims[3];//是输出的那个7
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1表示输出的是7个里面的第二个lableID
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //输出得到的都是0-1的浮点数坐标 要乘以原宽高才是实际坐标
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
//printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
}
4、实时人脸检测之异步推理
4.1、模型介绍
在OpenVINO当中自带了一系列的人脸检测的轻量级模型,多数都是可以达到100或更高的fps,所以说可以更适合部署在边缘端侧设备上的。

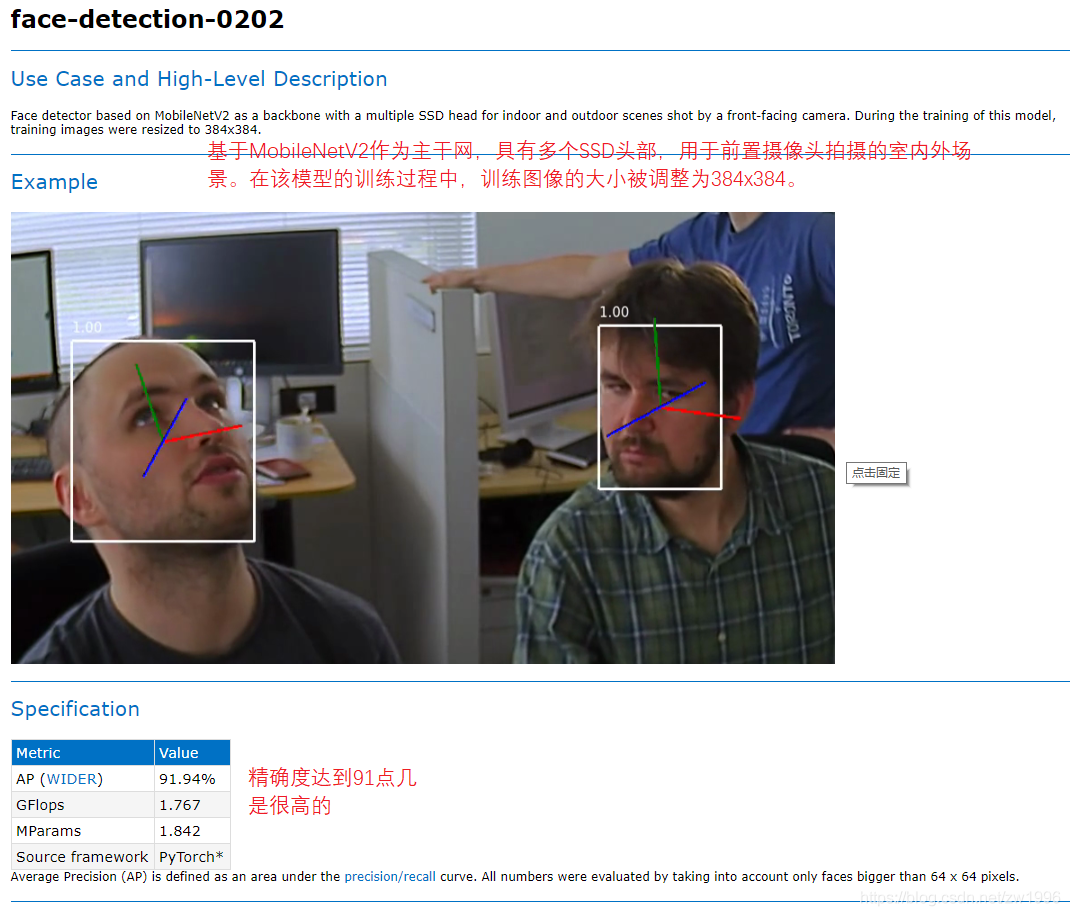

图24,25,26
可以与OpenCV做一个对比,opencv都是一个个算法都是传统模块,而OpenVINO了也是一个个算法所不同的是这里的一个个算法都是基于深度学习的模块,所提供的一个个模型,你根据这个模型去围绕开展就可以得到不同的算法表现
4.2、同步/异步执行
之前的模型实践都是使用的infer_request.Infer()都是同步的模型,而异步的是有所差异的,
4.3、代码演示
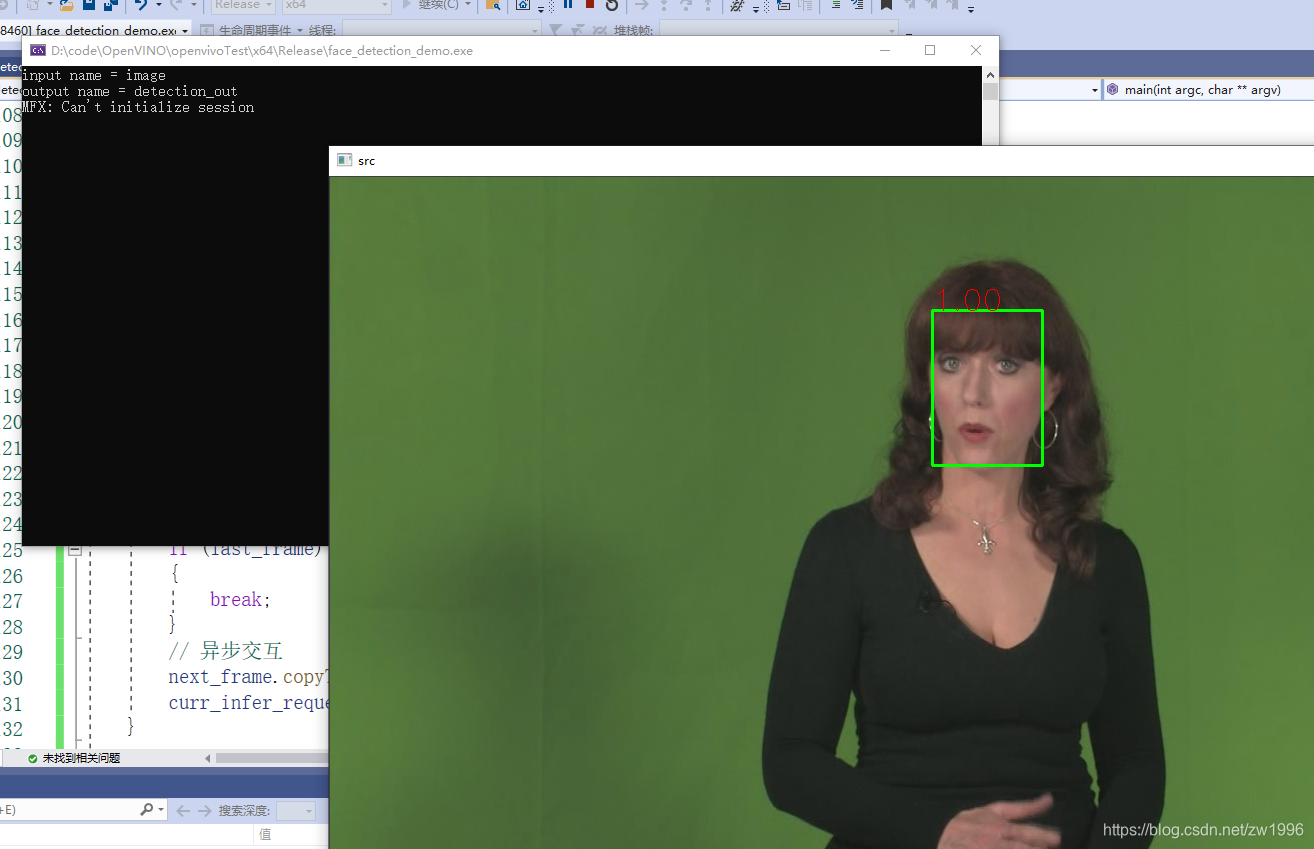
图30
同步实现
异步实现
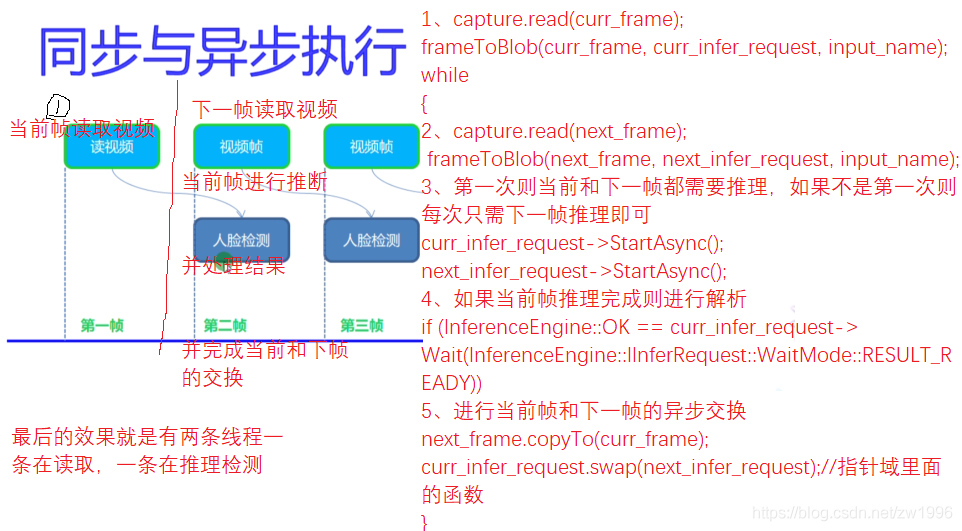
图27
代码实践
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//将mat过来的数据U8类型的 转为Blob,因为Blob是任意类型的因此也声明为模板、
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name);
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.xml";
std::string binFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
cv::VideoCapture capture(0);
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
while (true)
{
bool ret = capture.read(next_frame);
if (ret == false)//是最后一帧了
{
last_frame = true;//不在输入设置了
}
if (!last_frame)//不是最后一帧就设置下一帧
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//开始进行推理
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//每次开始都是下一帧准备异步 下面有交换
{
next_infer_request->StartAsync();
}
}
//7、循环执行推理 每次推理都是当前帧 等待推理成功就进行解析
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
infer_process(curr_frame, curr_infer_request, output_name);
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//按下esc
break;
if (last_frame)
{
break;
}
// 异步交互
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//指针域里面的函数
}
return 0;
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request->GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 模型输出推理函数封装
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name)
{
//1、执行推理
//infer_request->Infer(); 异步推理就不需要这一步了
//2、获取我们的output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//3、最后需要获取输出的维度信息 解析数据
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//是输出的那个N
const int object_size = outputDims[3];//是输出的那个7
int im_h = src.rows;
int im_w = src.cols;
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1表示输出的是7个里面的第二个lableID
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //输出得到的都是0-1的浮点数坐标 要乘以原宽高才是实际坐标
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
//printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
}
5、实时人脸表情识别
主要是基于人脸检测的前提下加载人脸表情识别的模型对人脸常见的5种表情进行识别。
5.1、模型介绍

图28、29
5.2、程序执行流程
就是基于人脸检测之后将人脸检测的ROI区域送给表情识别模型,再进行检测输出结果。
注意;做一下保护 保证人脸检测获取到的矩形在图像内, 做大小判断而不是坐标判断,否则人脸表情检测的时候进行设置输入时会奔溃。
5.3、代码演示
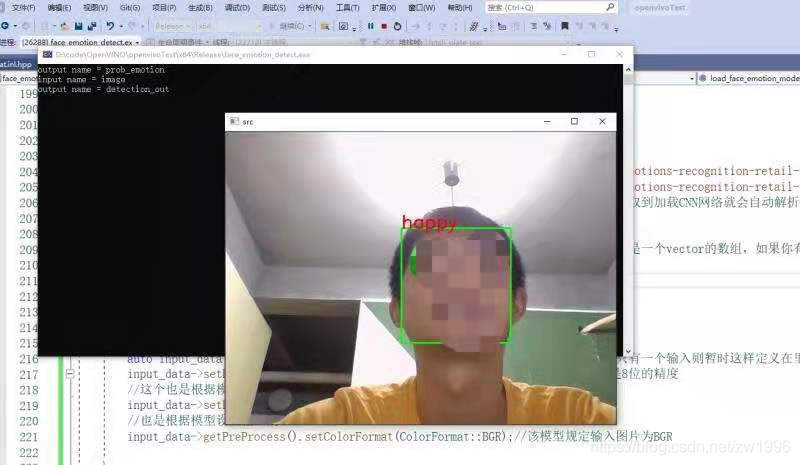
图31
代码实践
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//将mat过来的数据U8类型的 转为Blob,因为Blob是任意类型的因此也声明为模板、
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
//表情的几个值
static const char* const items[] = {
"neutral", "happy", "sad", "surprise", "anger"
};
//加载人脸表情识别的模型 传出 推理以及输入输出名称
void load_face_emotion_model(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name);
//人脸表情检测 设置输入 推理 解析输出
std::string text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name, cv::Mat& image, cv::Rect& face_roi);
//人脸检测 异步推理之后对结果进行处理
cv::Rect infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name);
//SSD MobileNetV2 模型输入推理设置函数 就是将输入的src转换为对应格式设置到 infer_request的Blob中
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//加载人脸表情识别的模型
std::shared_ptr<InferenceEngine::InferRequest> face_emotion_request;
std::string face_emotion_input_name;
std::string face_emotion_output_name;
load_face_emotion_model(face_emotion_request, face_emotion_input_name, face_emotion_output_name);
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.xml";
std::string binFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
cv::VideoCapture capture(0);
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
while (true)
{
bool ret = capture.read(next_frame);
if (ret == false)//是最后一帧了
{
last_frame = true;//不在输入设置了
}
if (!last_frame)//不是最后一帧就设置下一帧
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//开始进行推理
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//每次开始都是下一帧准备异步 下面有交换
{
next_infer_request->StartAsync();
}
}
//7、循环执行推理 每次推理都是当前帧 等待推理成功就进行解析
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
//人脸检测的推理 返回人脸矩形框
cv::Rect face_box = infer_process(curr_frame, curr_infer_request, output_name);
//对返回的人脸位置矩形框进行表情识别 设置输入 进行推理 解析输出
if(face_box.width > 64 && face_box.height > 64 && face_box.x > 0 && face_box.y > 0)//要做保护 不然容易奔溃
text_recognization_text(face_emotion_request, face_emotion_input_name, face_emotion_output_name, curr_frame, face_box);
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//按下esc
break;
if (last_frame)
{
break;
}
// 异步交互
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//指针域里面的函数
}
return 0;
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request->GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 模型输出推理函数封装
cv::Rect infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name)
{
//1、执行推理
//infer_request->Infer(); 异步推理就不需要这一步了
cv::Rect box;
//2、获取我们的output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//3、最后需要获取输出的维度信息 解析数据
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//是输出的那个N
const int object_size = outputDims[3];//是输出的那个7
int im_h = src.rows;
int im_w = src.cols;
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1表示输出的是7个里面的第二个lableID
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //输出得到的都是0-1的浮点数坐标 要乘以原宽高才是实际坐标
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.9)
{
//printf("lable id = %d\n", static_cast<int>(lable));、
//做一下保护 保证矩形在图像类 做大小判断而不是坐标判断
xmin = std::min(std::max(0.0f, xmin), static_cast<float>(im_w));
ymin = std::min(std::max(0.0f, ymin), static_cast<float>(im_h));
xmax = std::min(std::max(0.0f, xmax), static_cast<float>(im_w));
ymax = std::min(std::max(0.0f, ymax), static_cast<float>(im_h));
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
//std::cout << box.x << " " << box.y << " " << box.width << " " << box.height;
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
return box;
//cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
return box;
}
void load_face_emotion_model(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/emotions-recognition-retail-0003/FP32/emotions-recognition-retail-0003.xml";
std::string binFilename = "D:/code/OpenVINO/emotions-recognition-retail-0003/FP32/emotions-recognition-retail-0003.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)//因为这个模型有两个输入 则会循环两次的
{
face_emotion_input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
}
for (auto item : outputs)
{
face_emotion_output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << face_emotion_output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
face_emotion_request = executable_network.CreateInferRequestPtr();
}
std::string text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name, cv::Mat& image, cv::Rect& face_roi)
{
//设置输入
cv::Mat faceROI = image(face_roi);
frameToBlob(faceROI, face_emotion_request, face_emotion_input_name);
//执行推理
face_emotion_request->Infer();
//输出string结果返回
auto output = face_emotion_request->GetBlob(face_emotion_output_name);
const float* probs = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//将输出数据转换 Precision精度
//10、最后需要获取输出的维度信息 解析数据 并输出最大的那个就是我们resnet18图像识别出来的结果
const SizeVector outputDims = output->getTensorDesc().getDims();
float max = probs[0];
int max_index = 0;
for (int i = 1; i < outputDims[1]; i++)
{
if (max < probs[i])
{
max = probs[i];
max_index = i;
}
}
cv::putText(image, items[max_index], face_roi.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
return items[max_index];
}
6、人脸关键点landmark检测
6.1、模型介绍
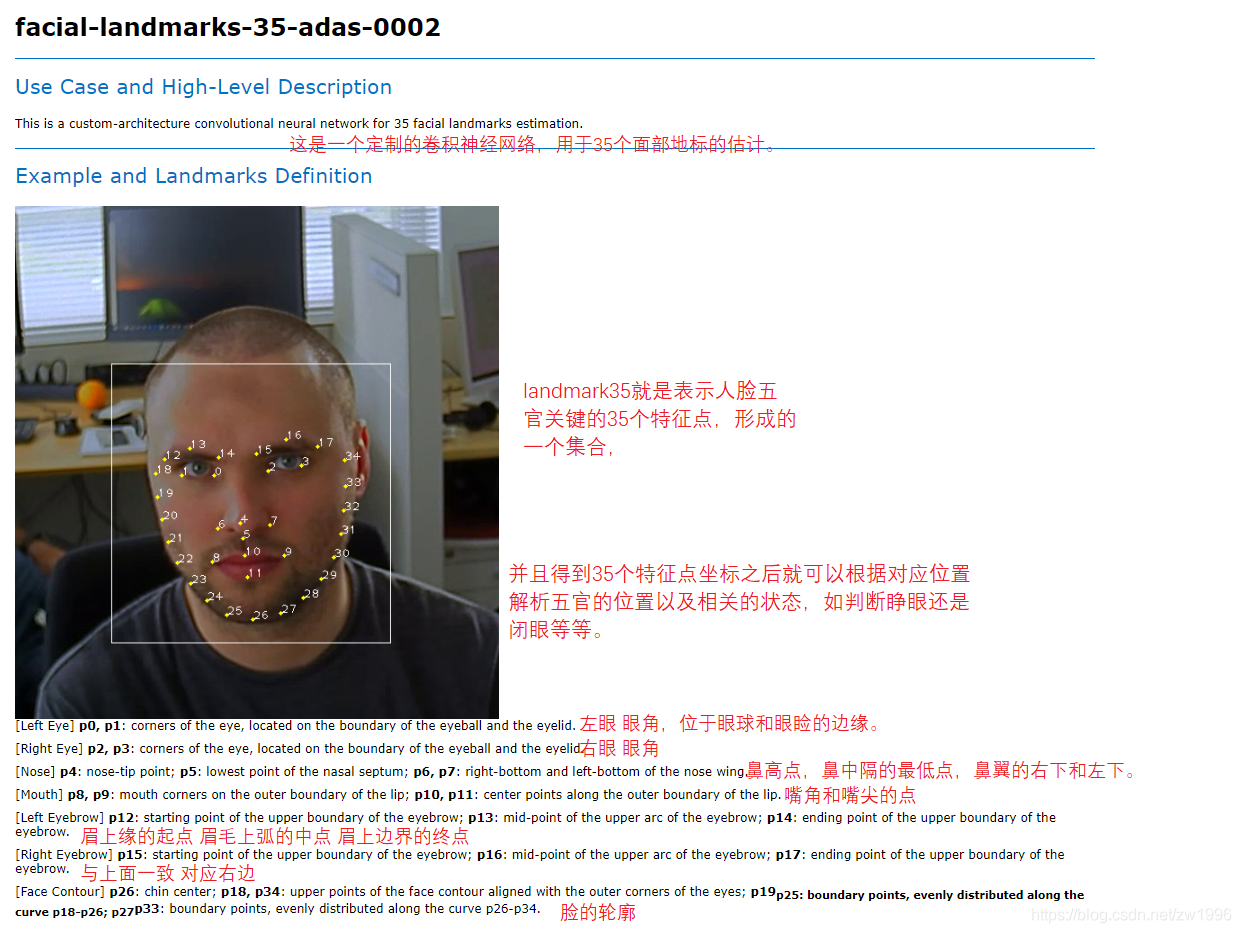
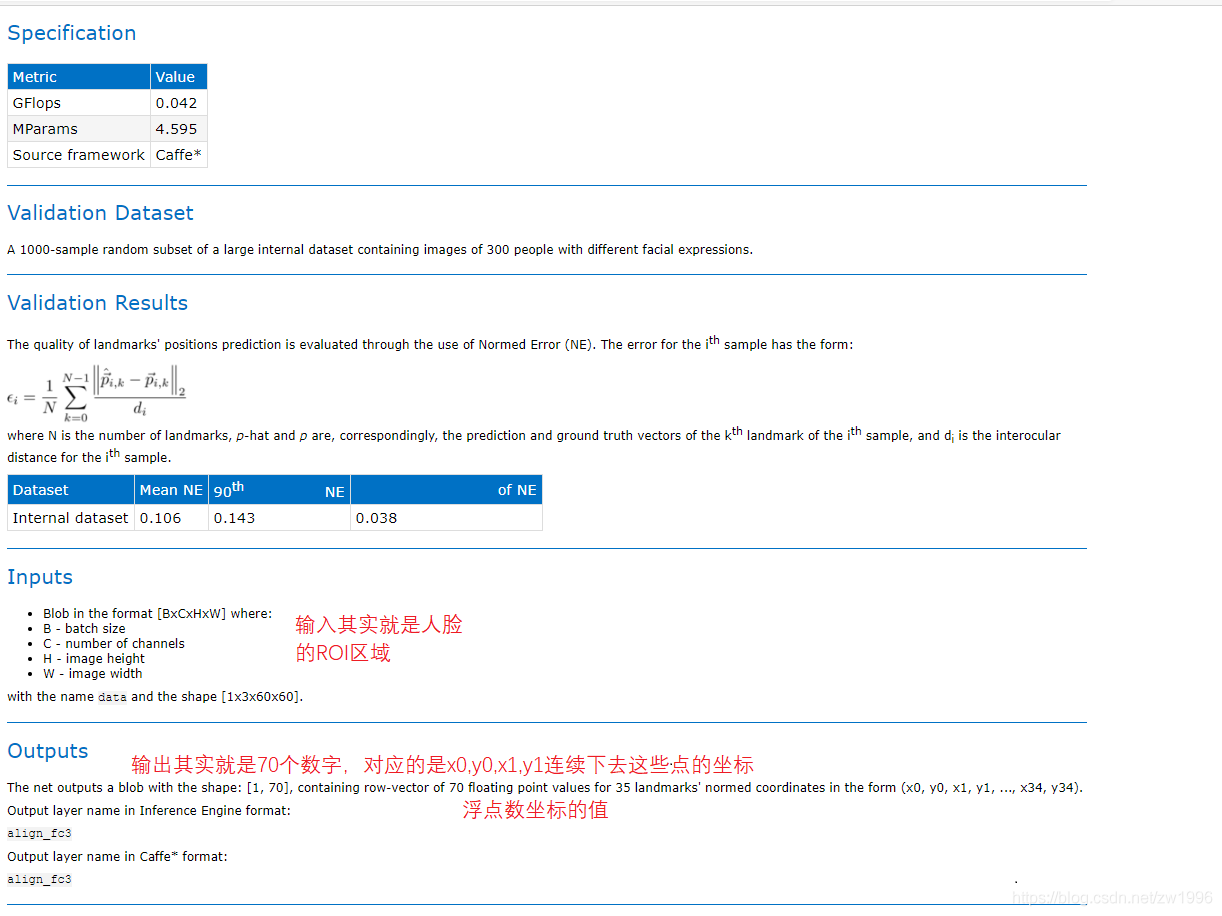
图 32、33
6.2、程序执行流程
完成人脸检测获取ROI区域直接直接进行landMark检测即可。与人脸表情流程一致.
6.3、代码演示
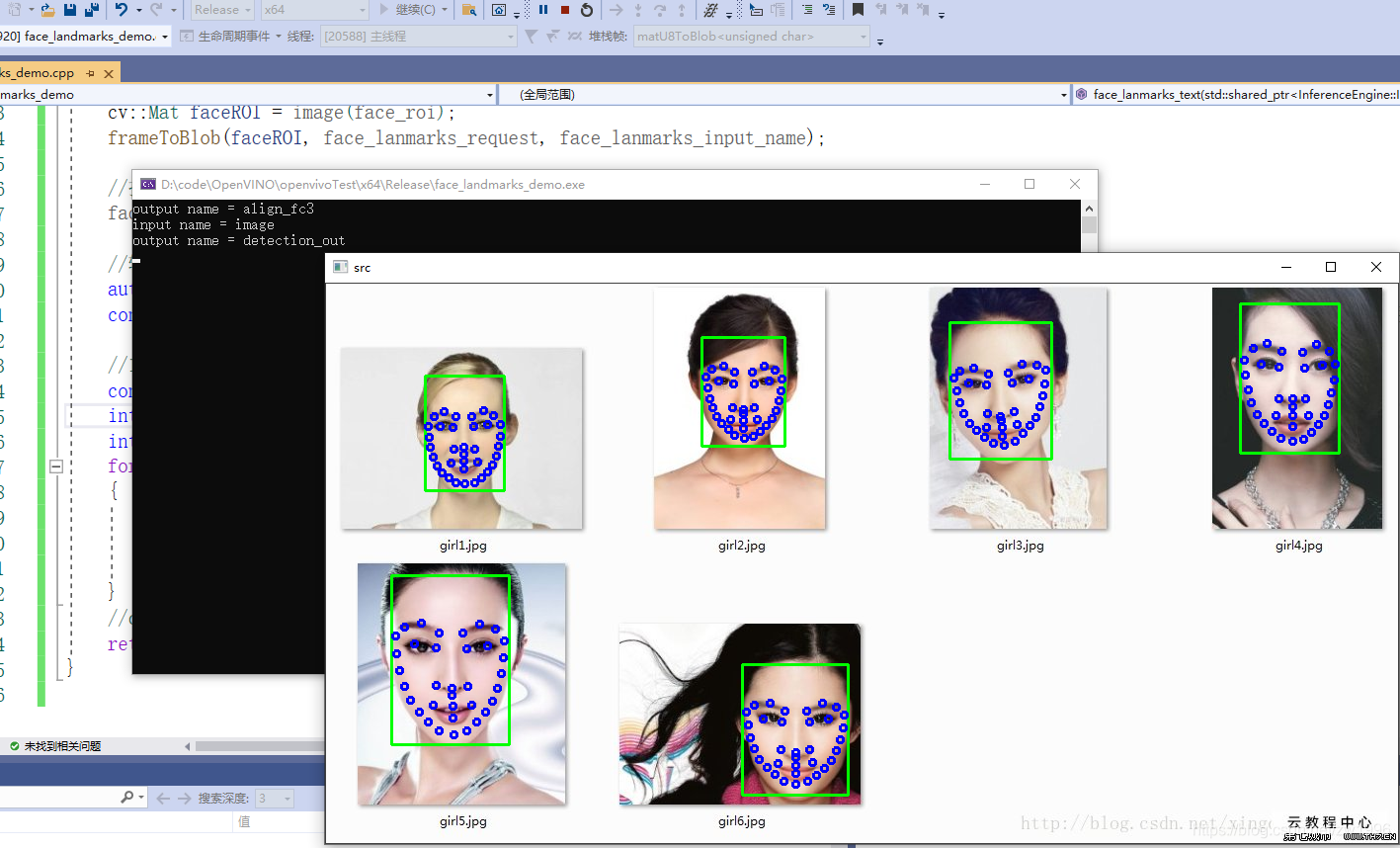
图34
根本在于查看输入有几个是什么结构,输出是什么结构怎么解析、多个网络同时在一起怎么调用,同步与异步的使用。
代码实践
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//将mat过来的数据U8类型的 转为Blob,因为Blob是任意类型的因此也声明为模板、
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
//表情的几个值
static const char* const items[] = {
"neutral", "happy", "sad", "surprise", "anger"
};
//加载人脸表情识别的模型 传出 推理以及输入输出名称
void load_textRecognization_model(std::string xmlFilename, std::string binFilename, std::shared_ptr<InferenceEngine::InferRequest>& face_request, std::string& face_input_name, std::string& face_output_name);
//人脸表情检测 设置输入 推理 解析输出
void text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name, cv::Mat& image, cv::Rect& face_roi);
//人脸检测 异步推理之后对结果进行处理
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name, std::vector<cv::Rect>& vc_RoiRect);
//SSD MobileNetV2 模型输入推理设置函数 就是将输入的src转换为对应格式设置到 infer_request的Blob中
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//加载人脸表情识别的模型
std::shared_ptr<InferenceEngine::InferRequest> face_landmarks_request;
std::string face_landmarks_input_name;
std::string face_landmarks_output_name;
std::string facial_landmarks_xmlFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.xml";
std::string facial_landmarks_binFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.bin";
load_textRecognization_model(facial_landmarks_xmlFilename, facial_landmarks_binFilename, face_landmarks_request, face_landmarks_input_name, face_landmarks_output_name);
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.xml";
std::string binFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
//图片读取
#if 1
cv::Mat curr_frame = cv::imread("D:/face_emotion.jpg");
std::vector<cv::Rect> vc_RoiRect;
frameToBlob(curr_frame, curr_infer_request, input_name);
curr_infer_request->Infer();
infer_process(curr_frame, curr_infer_request, output_name, vc_RoiRect);
//对返回的人脸位置矩形框进行表情识别 设置输入 进行推理 解析输出
for (int i = 0; i < vc_RoiRect.size(); i++)
{
if (vc_RoiRect[i].width > 64 && vc_RoiRect[i].height > 64 && vc_RoiRect[i].x > 0 && vc_RoiRect[i].y > 0)//要做保护 不然容易奔溃
text_recognization_text(face_landmarks_request, face_landmarks_input_name, face_landmarks_output_name, curr_frame, vc_RoiRect[i]);
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(0);
#endif
#if 0
//视频读取
cv::VideoCapture capture(0);
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
std::vector<cv::Rect> vc_RoiRect;
while (true)
{
vc_RoiRect.clear();
bool ret = capture.read(next_frame);
if (ret == false)//是最后一帧了
{
last_frame = true;//不在输入设置了
}
if (!last_frame)//不是最后一帧就设置下一帧
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//开始进行推理
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//每次开始都是下一帧准备异步 下面有交换
{
next_infer_request->StartAsync();
}
}
//7、循环执行推理 每次推理都是当前帧 等待推理成功就进行解析
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
//人脸检测的推理 返回人脸矩形框
infer_process(curr_frame, curr_infer_request, output_name, vc_RoiRect);
//对返回的人脸位置矩形框进行表情识别 设置输入 进行推理 解析输出
for (int i = 0; i < vc_RoiRect.size(); i++)
{
if (vc_RoiRect[i].width > 64 && vc_RoiRect[i].height > 64 && vc_RoiRect[i].x > 0 && vc_RoiRect[i].y > 0)//要做保护 不然容易奔溃
face_lanmarks_text(face_landmarks_request, face_landmarks_input_name, face_landmarks_output_name, curr_frame, vc_RoiRect[i]);
}
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//按下esc
break;
if (last_frame)
{
break;
}
// 异步交互
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//指针域里面的函数
}
#endif
return 0;
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request->GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 模型输出推理函数封装
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name, std::vector<cv::Rect> &vc_RoiRect)
{
//1、执行推理
//infer_request->Infer(); 异步推理就不需要这一步了
cv::Rect box;
//2、获取我们的output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//3、最后需要获取输出的维度信息 解析数据
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//是输出的那个N
const int object_size = outputDims[3];//是输出的那个7
int im_h = src.rows;
int im_w = src.cols;
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1表示输出的是7个里面的第二个lableID
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //输出得到的都是0-1的浮点数坐标 要乘以原宽高才是实际坐标
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.95)
{
//printf("lable id = %d\n", static_cast<int>(lable));、
//做一下保护 保证矩形在图像类 做大小判断而不是坐标判断
xmin = std::min(std::max(0.0f, xmin), static_cast<float>(im_w));
ymin = std::min(std::max(0.0f, ymin), static_cast<float>(im_h));
xmax = std::min(std::max(0.0f, xmax), static_cast<float>(im_w));
ymax = std::min(std::max(0.0f, ymax), static_cast<float>(im_h));
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
//std::cout << box.x << " " << box.y << " " << box.width << " " << box.height;
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
vc_RoiRect.push_back(box);
//cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
return ;
}
void load_textRecognization_model(std::string xmlFilename, std::string binFilename, std::shared_ptr<InferenceEngine::InferRequest>& face_emotion_request, std::string& face_emotion_input_name, std::string& face_emotion_output_name)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
/*std::string xmlFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.xml";
std::string binFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.bin";*/
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)//因为这个模型有两个输入 则会循环两次的
{
face_emotion_input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
}
for (auto item : outputs)
{
face_emotion_output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << face_emotion_output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
face_emotion_request = executable_network.CreateInferRequestPtr();
}
void text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& face_lanmarks_request, std::string& face_lanmarks_input_name, std::string& face_lanmarks_output_name, cv::Mat& image, cv::Rect& face_roi)
{
//设置输入
cv::Mat faceROI = image(face_roi);
frameToBlob(faceROI, face_lanmarks_request, face_lanmarks_input_name);
//执行推理
face_lanmarks_request->Infer();
//输出string结果返回
auto output = face_lanmarks_request->GetBlob(face_lanmarks_output_name);
const float* probs = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//将输出数据转换 Precision精度
//10、最后需要获取输出的维度信息 解析数据 这里获取的坐标是相当于人脸的坐标 最后绘制点是需要以图片的坐标
const SizeVector outputDims = output->getTensorDesc().getDims();//
int i_width = face_roi.width;
int i_height = face_roi.height;
for (int i = 0; i < outputDims[1]; i+=2)
{
float x = probs[i] * i_width + face_roi.x;
float y = probs[i + 1] * i_height + face_roi.y;
cv::circle(image, cv::Point(x, y), 3, cv::Scalar(255, 0, 0), 2, 8, 0);//绘制圈
}
//cv::putText(image, items[max_index], face_roi.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
return ;
}
7、实时语义道路分割模型
OpenVINO也对语义道路分割模型进行了一个支持,这个支持也就是语义道路分割模型,它分割的道路为四个部分:背景,道路,路边,标记线(车道线等)。
7.1、模型介绍
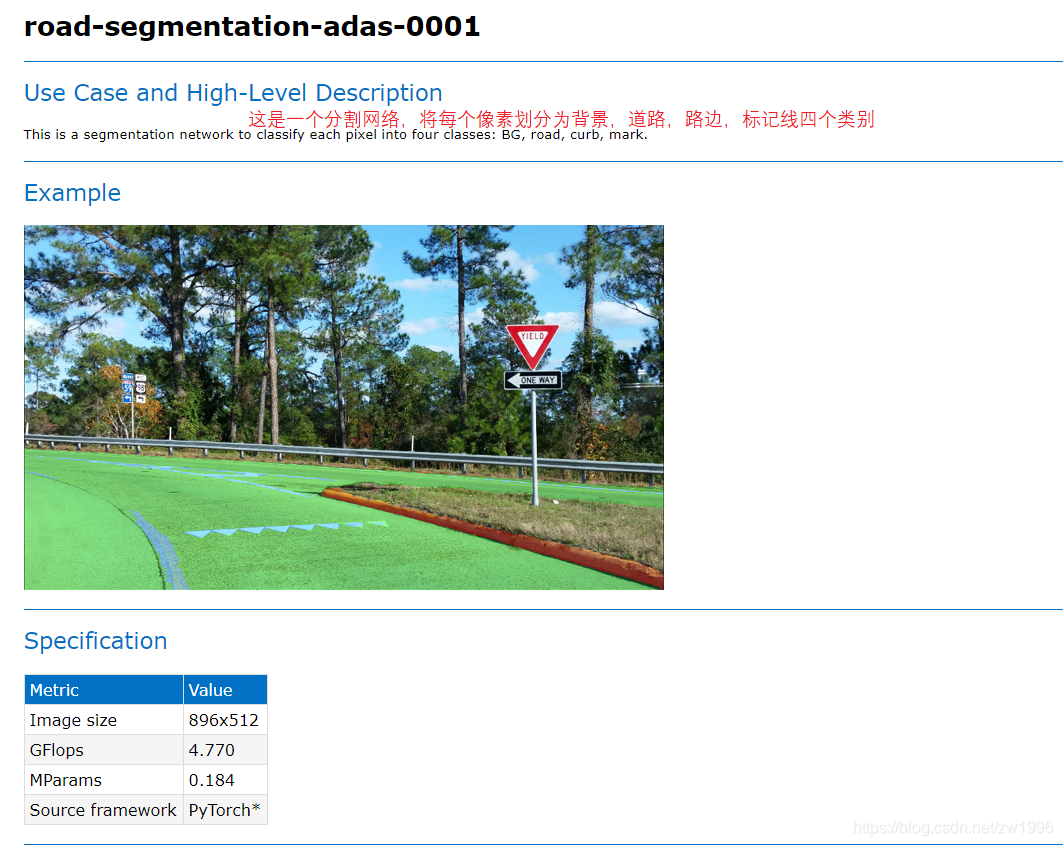
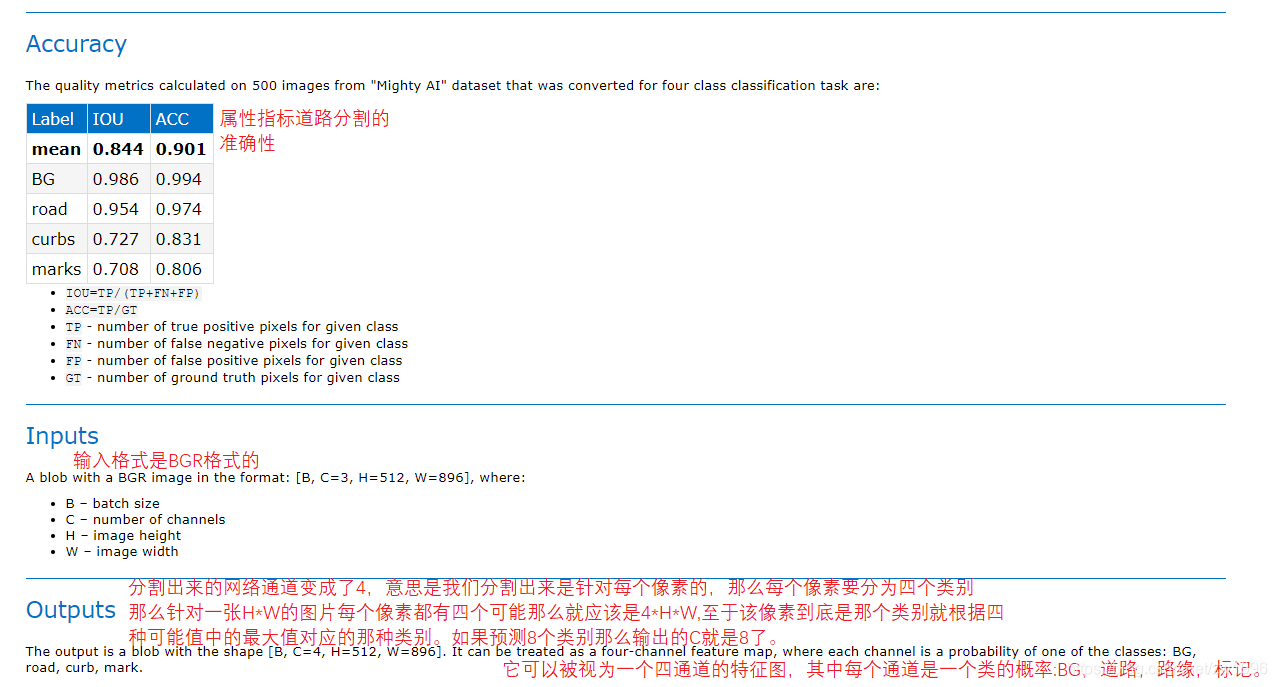
图35、36
7.2、程序流程
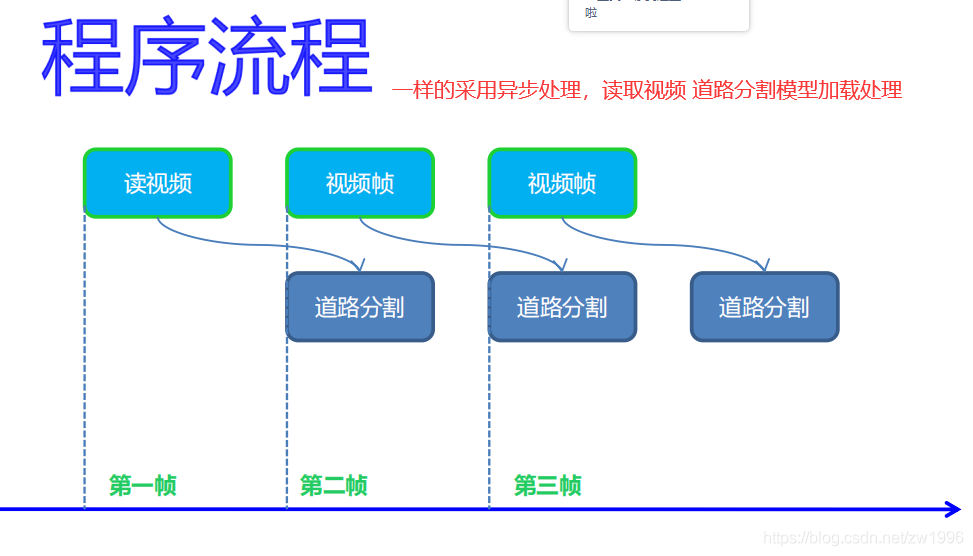
图37
7.3、代码演示
关键就是在于如何解析分割网络中的多通道输出
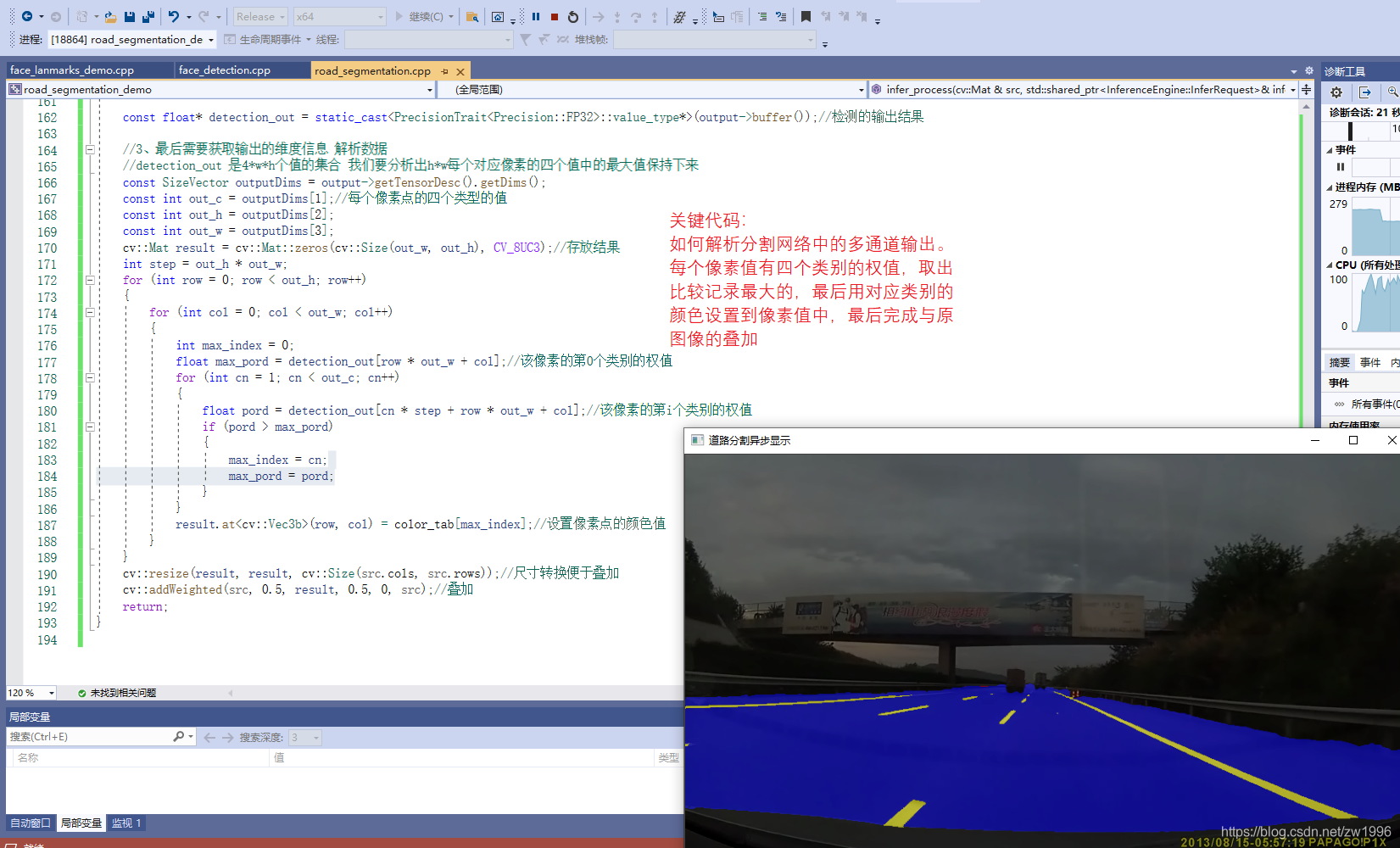
图38
代码实践
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//将mat过来的数据U8类型的 转为Blob,因为Blob是任意类型的因此也声明为模板、
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name);
// SSD MobileNetV2 模型输出推理函数封装
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
std::vector<cv::Vec3b> color_tab;
int main(int argc, char** argv)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/road-segmentation-adas-0001/FP32/road-segmentation-adas-0001.xml";
std::string binFilename = "D:/code/OpenVINO/road-segmentation-adas-0001/FP32/road-segmentation-adas-0001.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
cv::VideoCapture capture("D:/lane.avi");
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
//设置推理输入
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
color_tab.push_back(cv::Vec3b(0, 0, 0));//对应BG
color_tab.push_back(cv::Vec3b(255, 0, 0));//对应road
color_tab.push_back(cv::Vec3b(0, 0, 255));//对应curb
color_tab.push_back(cv::Vec3b(0, 255, 255));//对应mark
while (true)
{
bool ret = capture.read(next_frame);
if (ret == false)//是最后一帧了
{
last_frame = true;//不在输入设置了
}
if (!last_frame)//不是最后一帧就设置下一帧
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//开始进行推理
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//每次开始都是下一帧准备异步 下面有交换
{
next_infer_request->StartAsync();
}
}
//7、循环执行推理 每次推理都是当前帧 等待推理成功就进行解析
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
infer_process(curr_frame, curr_infer_request, output_name);
}
cv::imshow("道路分割异步显示", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//按下esc
break;
if (last_frame)
{
break;
}
// 异步交互
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//指针域里面的函数
}
return 0;
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request->GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 模型输出推理函数封装
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name)
{
//1、执行推理
//infer_request->Infer(); 异步推理就不需要这一步了
//2、获取我们的output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//3、最后需要获取输出的维度信息 解析数据
//detection_out 是4*w*h个值的集合 我们要分析出h*w每个对应像素的四个值中的最大值保持下来
const SizeVector outputDims = output->getTensorDesc().getDims();
const int out_c = outputDims[1];//每个像素点的四个类型的值
const int out_h = outputDims[2];
const int out_w = outputDims[3];
cv::Mat result = cv::Mat::zeros(cv::Size(out_w, out_h), CV_8UC3);//存放结果
int step = out_h * out_w;
for (int row = 0; row < out_h; row++)
{
for (int col = 0; col < out_w; col++)
{
int max_index = 0;
float max_pord = detection_out[row * out_w + col];//该像素的第0个类别的权值
for (int cn = 1; cn < out_c; cn++)
{
float pord = detection_out[cn * step + row * out_w + col];//该像素的第i个类别的权值
if (pord > max_pord)
{
max_index = cn;
max_pord = pord;
}
}
result.at<cv::Vec3b>(row, col) = color_tab[max_index];//设置像素点的颜色值
}
}
cv::resize(result, result, cv::Size(src.cols, src.rows));//尺寸转换便于叠加
cv::addWeighted(src, 0.5, result, 0.5, 0, src);//叠加
return;
}
8、实例分割
我们最常见的实例分割模型就是:Mask R-CNN模型,而openVINO当中也支持多种Mask R-CNN,不同级别,不同分辨率的都是支持的。
8.1、实例分割模型


图39 40
8.2、程序执行流程
流程的关键还是在与处理输出,特别是解析raw_masks的mask矩阵属性,需很利于opencv的相关知识进行转换叠加处理。
8.3、代码演示
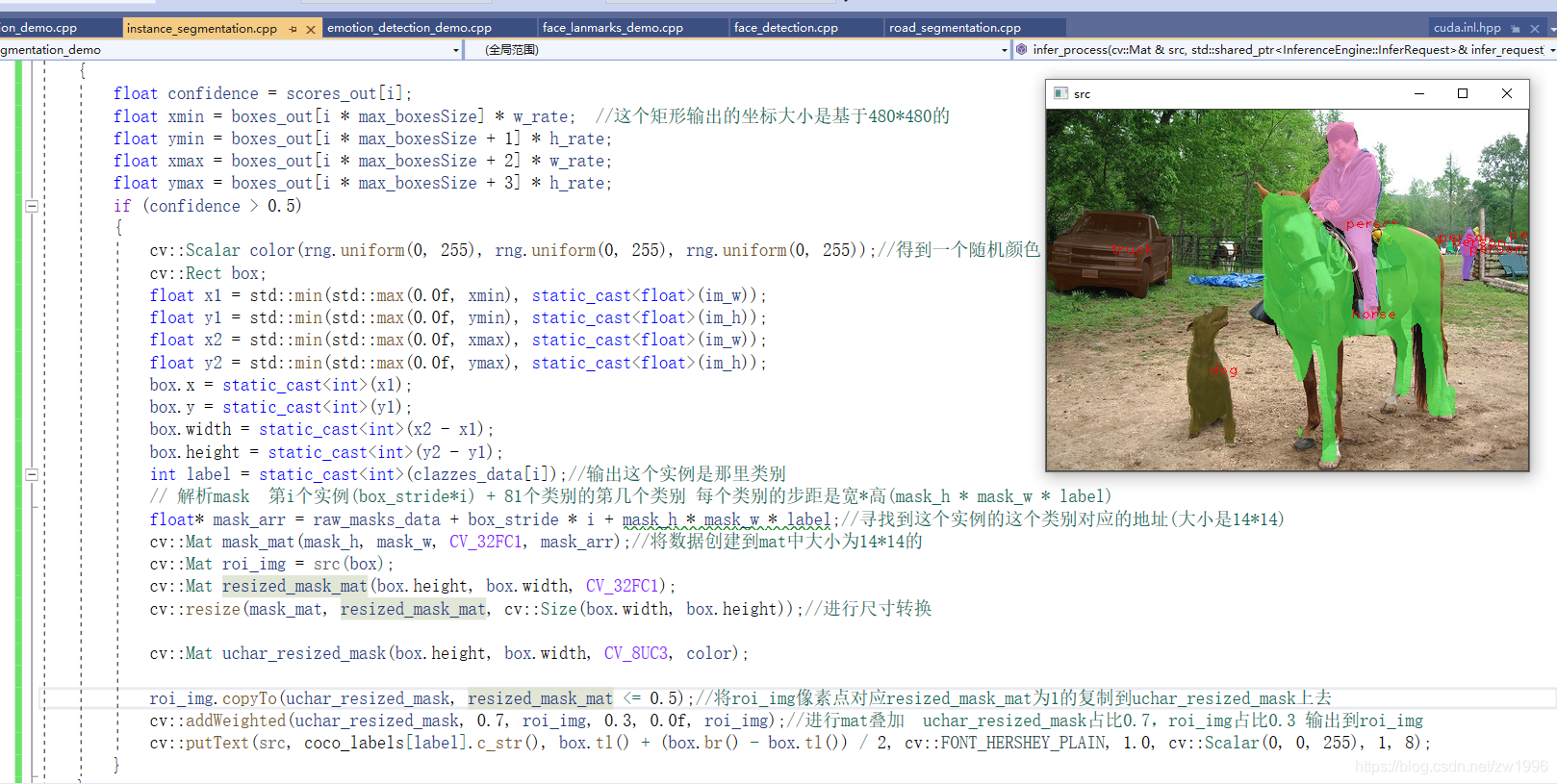
图41
代码实践
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//将mat过来的数据U8类型的 转为Blob,因为Blob是任意类型的因此也声明为模板、
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
void read_coco_labels(std::vector<std::string>& labels) {
std::string label_file = "coco_labels.txt";
std::ifstream fp(label_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
labels.push_back(name);
}
fp.close();
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request);
// SSD MobileNetV2 模型输出推理函数封装
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
std::vector<std::string> coco_labels;
int main(int argc, char** argv)
{
read_coco_labels(coco_labels);
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/instance-segmentation-security-0050/FP32/instance-segmentation-security-0050.xml";
std::string binFilename = "D:/code/OpenVINO/instance-segmentation-security-0050/FP32/instance-segmentation-security-0050.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string info_name = "";
int in_index = 0;
for (auto item : inputs)
{
if (in_index == 0)
{
input_name = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::U8);
input_data->setLayout(Layout::NCHW);
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);
std::cout << "input name = " << input_name << std::endl;
}
else
{
info_name = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::FP32);
std::cout << "info_name name = " << info_name << std::endl;
}
in_index++;
}
for (auto item : outputs)//因为该模型是名字是准确的到时候访问的时候直接可以根据官方文档给的名字指定
{
std::string output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto curr_infer_request = executable_network.CreateInferRequestPtr();
//6、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
cv::Mat curr_frame = cv::imread("D:/objects.jpg");
std::vector<cv::Rect> vc_RoiRect;
frameToBlob(curr_frame, curr_infer_request, input_name);//设置第一个输入
//设置第二个输入
auto input2 = curr_infer_request->GetBlob(info_name);
auto imInfoDim = inputs.find(info_name)->second->getTensorDesc().getDims()[1];
InferenceEngine::MemoryBlob::Ptr minput2 = InferenceEngine::as<InferenceEngine::MemoryBlob>(input2);
auto minput2Holder = minput2->wmap();
float* p = minput2Holder.as<InferenceEngine::PrecisionTrait<InferenceEngine::Precision::FP32>::value_type*>();
p[0] = static_cast<float>(inputs[input_name]->getTensorDesc().getDims()[2]);
p[1] = static_cast<float>(inputs[input_name]->getTensorDesc().getDims()[3]);
p[2] = 1.0f;
std::cout << p[0] << " " << p[1] << std::endl;
infer_process(curr_frame, curr_infer_request);
cv::imshow("src", curr_frame);
char c = cv::waitKey(0);
return 0;
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request->GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 模型输出推理函数封装
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request)
{
//1、执行推理
infer_request->Infer(); //异步推理就不需要这一步了
//2、获取我们的output
auto scores = infer_request->GetBlob("scores");
auto boxes = infer_request->GetBlob("boxes");
auto clazzes = infer_request->GetBlob("classes");
auto raw_masks = infer_request->GetBlob("raw_masks");
const float* scores_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(scores->buffer());//检测的输出结果
const float* boxes_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(boxes->buffer());// 这个矩形输出的坐标大小是基于480*480的
const float* clazzes_data = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(clazzes->buffer());
const auto raw_masks_data = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(raw_masks->buffer());//输出的是 raw_masks 结构
//3、最后需要获取输出的维度信息 解析数据
const SizeVector scores_outputDims = scores->getTensorDesc().getDims();
const SizeVector boxes_outputDims = boxes->getTensorDesc().getDims();
const SizeVector mask_outputDims = raw_masks->getTensorDesc().getDims();
const int max_scoresSize = scores_outputDims[0];//100
const int max_boxesSize = boxes_outputDims[1];//4
int mask_h = mask_outputDims[2];//raw_masks 宽高 真实与官方文档不一致 现在是14*14
int mask_w = mask_outputDims[3];
size_t box_stride = mask_h * mask_w * mask_outputDims[1];//表示每一个实例的之间的步距 81*14*14,这100个实例之间每个实例都隔这么多字节
int im_w = src.cols;
int im_h = src.rows;
float w_rate = static_cast<float>(im_w) / 480.0;
float h_rate = static_cast<float>(im_h) / 480.0;
cv::RNG rng(12345);
for (int i = 0; i < max_scoresSize; i++)
{
float confidence = scores_out[i];
float xmin = boxes_out[i * max_boxesSize] * w_rate; //这个矩形输出的坐标大小是基于480*480的
float ymin = boxes_out[i * max_boxesSize + 1] * h_rate;
float xmax = boxes_out[i * max_boxesSize + 2] * w_rate;
float ymax = boxes_out[i * max_boxesSize + 3] * h_rate;
if (confidence > 0.5)
{
cv::Scalar color(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255));//得到一个随机颜色
cv::Rect box;
float x1 = std::min(std::max(0.0f, xmin), static_cast<float>(im_w));
float y1 = std::min(std::max(0.0f, ymin), static_cast<float>(im_h));
float x2 = std::min(std::max(0.0f, xmax), static_cast<float>(im_w));
float y2 = std::min(std::max(0.0f, ymax), static_cast<float>(im_h));
box.x = static_cast<int>(x1);
box.y = static_cast<int>(y1);
box.width = static_cast<int>(x2 - x1);
box.height = static_cast<int>(y2 - y1);
int label = static_cast<int>(clazzes_data[i]);//输出这个实例是那里类别
// 解析mask 第i个实例(box_stride*i) + 81个类别的第几个类别 每个类别的步距是宽*高(mask_h * mask_w * label)
float* mask_arr = raw_masks_data + box_stride * i + mask_h * mask_w * label;//寻找到这个实例的这个类别对应的地址(大小是14*14)
cv::Mat mask_mat(mask_h, mask_w, CV_32FC1, mask_arr);//将数据创建到mat中大小为14*14的
cv::Mat roi_img = src(box);
cv::Mat resized_mask_mat(box.height, box.width, CV_32FC1);
cv::resize(mask_mat, resized_mask_mat, cv::Size(box.width, box.height));//进行尺寸转换
cv::Mat uchar_resized_mask(box.height, box.width, CV_8UC3, color);
roi_img.copyTo(uchar_resized_mask, resized_mask_mat <= 0.5);//将roi_img像素点对应resized_mask_mat为1的复制到uchar_resized_mask上去
cv::addWeighted(uchar_resized_mask, 0.7, roi_img, 0.3, 0.0f, roi_img);//进行mat叠加 uchar_resized_mask占比0.7,roi_img占比0.3 输出到roi_img
cv::putText(src, coco_labels[label].c_str(), box.tl() + (box.br() - box.tl()) / 2, cv::FONT_HERSHEY_PLAIN, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
return;
}
9、场景文字检测
9.1、模型介绍
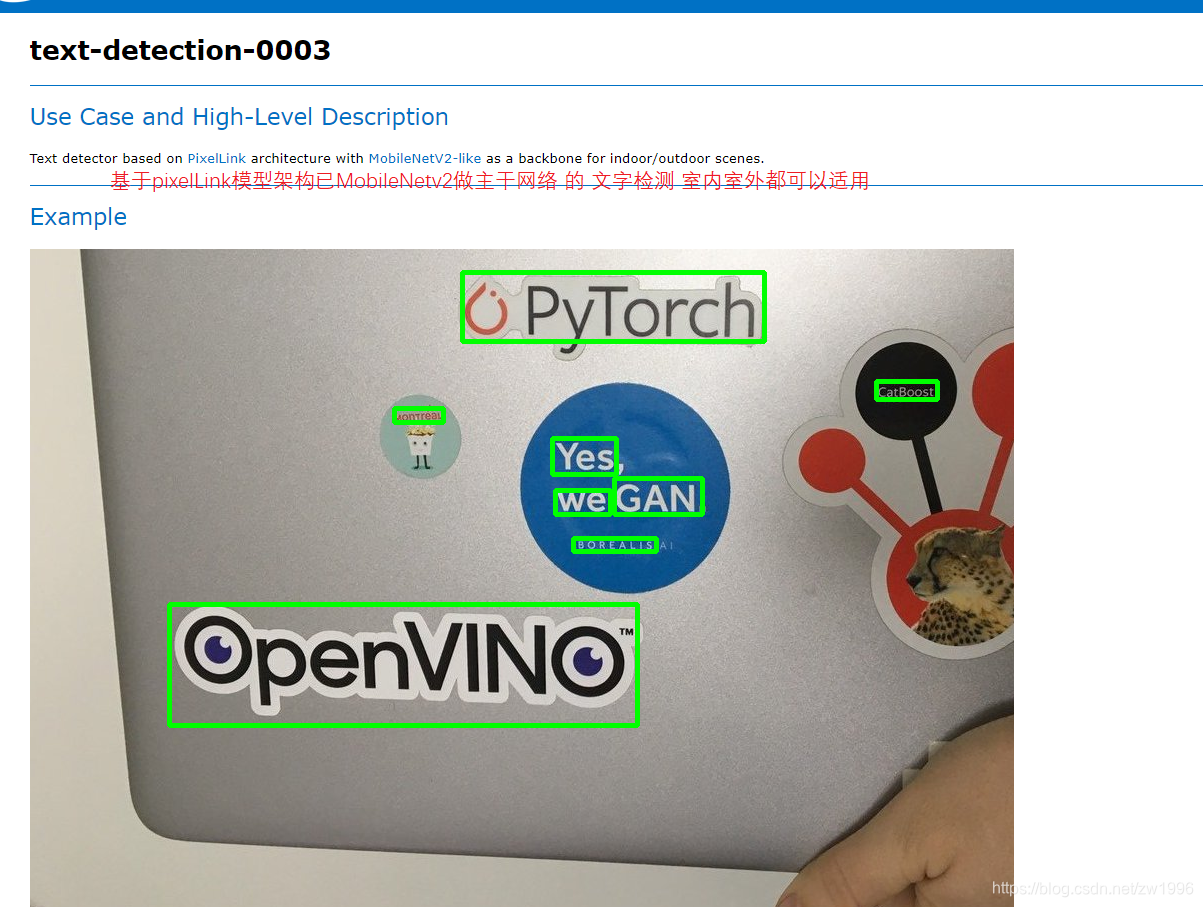
图42 43
9.2、程序执行步骤
加载模式
设置输入
解析输出
9.3、代码演示
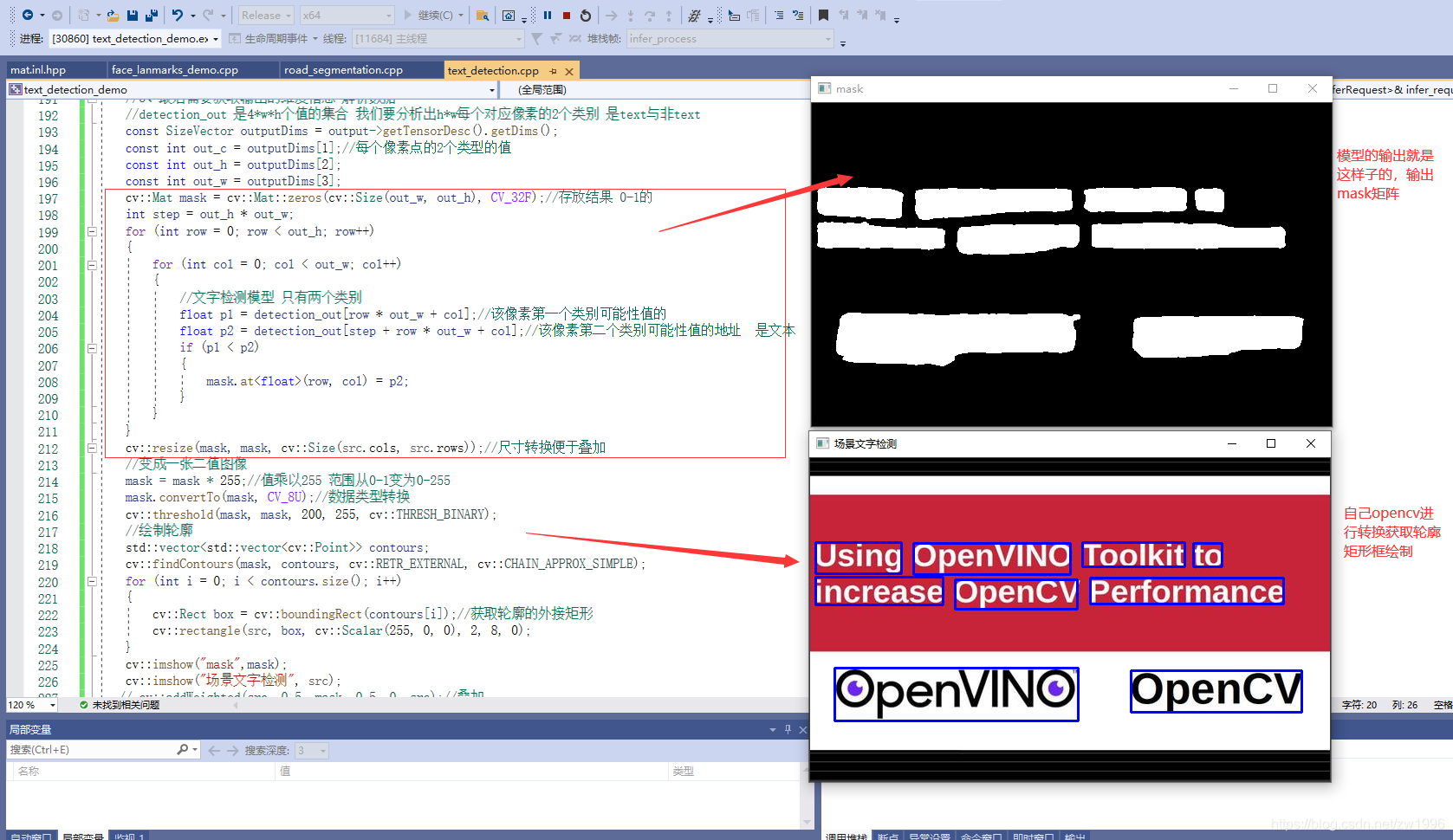
图44
代码实践
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//将mat过来的数据U8类型的 转为Blob,因为Blob是任意类型的因此也声明为模板、
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name);
// SSD MobileNetV2 模型输出推理函数封装
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
std::vector<cv::Vec3b> color_tab;
int main(int argc, char** argv)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/text-detection-0003/FP32/text-detection-0003.xml";
std::string binFilename = "D:/code/OpenVINO/text-detection-0003/FP32/text-detection-0003.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name1 = "";
std::string output_name2 = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
int out_index = 0;
for (auto item : outputs)
{
if (out_index == 1)
{
output_name2 = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name1 << std::endl;
}
else
{
output_name1 = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name1 << std::endl;
}
out_index++;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto curr_infer_request = executable_network.CreateInferRequestPtr();
auto next_infer_request = executable_network.CreateInferRequestPtr();
//6、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
#if 1
cv::Mat curr_frame = cv::imread("D:/openvino_ocr.jpg");
std::vector<cv::Rect> vc_RoiRect;
frameToBlob(curr_frame, curr_infer_request, input_name);
curr_infer_request->Infer();
infer_process(curr_frame, curr_infer_request, output_name2);//暂时只需要第二个输出就已经可以精确定位了
//cv::imshow("src", curr_frame);
char c = cv::waitKey(0);
#endif
#if 0
cv::VideoCapture capture("D:/lane.avi");
cv::Mat curr_frame;
cv::Mat next_frame;
capture.read(curr_frame);
//设置推理输入
frameToBlob(curr_frame, curr_infer_request, input_name);
bool first_frame = true;
bool last_frame = false;
color_tab.push_back(cv::Vec3b(0, 0, 0));//对应BG
color_tab.push_back(cv::Vec3b(255, 0, 0));//对应road
color_tab.push_back(cv::Vec3b(0, 0, 255));//对应curb
color_tab.push_back(cv::Vec3b(0, 255, 255));//对应mark
while (true)
{
bool ret = capture.read(next_frame);
if (ret == false)//是最后一帧了
{
last_frame = true;//不在输入设置了
}
if (!last_frame)//不是最后一帧就设置下一帧
{
frameToBlob(next_frame, next_infer_request, input_name);
}
if (first_frame)
{
curr_infer_request->StartAsync();//开始进行推理
next_infer_request->StartAsync();
first_frame = false;
}
else
{
if (!last_frame)//每次开始都是下一帧准备异步 下面有交换
{
next_infer_request->StartAsync();
}
}
//7、循环执行推理 每次推理都是当前帧 等待推理成功就进行解析
if (InferenceEngine::OK == curr_infer_request->Wait(InferenceEngine::IInferRequest::WaitMode::RESULT_READY))
{
infer_process(curr_frame, curr_infer_request, output_name);
}
cv::imshow("道路分割异步显示", curr_frame);
char c = cv::waitKey(1);
if (c == 27)//按下esc
break;
if (last_frame)
{
break;
}
// 异步交互
next_frame.copyTo(curr_frame);
curr_infer_request.swap(next_infer_request);//指针域里面的函数
}
#endif
return 0;
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request->GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 模型输出推理函数封装
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name)
{
//1、执行推理
//infer_request->Infer(); 异步推理就不需要这一步了
//2、获取我们的output
auto output = infer_request->GetBlob(output_name);
//输出的值是0-1之间的浮点数表示这个类别的自信性 我们选择自信度比较大的那个类别即可
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//3、最后需要获取输出的维度信息 解析数据
//detection_out 是2*w*h个值的集合 我们要分析出h*w每个对应像素的2个类别 是text与非text
const SizeVector outputDims = output->getTensorDesc().getDims();
const int out_c = outputDims[1];//每个像素点的2个类型的值
const int out_h = outputDims[2];
const int out_w = outputDims[3];
cv::Mat mask = cv::Mat::zeros(cv::Size(out_w, out_h), CV_32F);//存放结果 0-1的
int step = out_h * out_w;
for (int row = 0; row < out_h; row++)
{
for (int col = 0; col < out_w; col++)
{
//文字检测模型 只有两个类别
float p1 = detection_out[row * out_w + col];//该像素第一个类别可能性值的
float p2 = detection_out[step + row * out_w + col];//该像素第二个类别可能性值的地址 是文本
if (p1 < p2)
{
mask.at<float>(row, col) = p2;
}
}
}
cv::resize(mask, mask, cv::Size(src.cols, src.rows));//尺寸转换便于叠加
//变成一张二值图像
mask = mask * 255;//值乘以255 范围从0-1变为0-255
mask.convertTo(mask, CV_8U);//数据类型转换
cv::threshold(mask, mask, 200, 255, cv::THRESH_BINARY);
//绘制轮廓
std::vector<std::vector<cv::Point>> contours;
cv::findContours(mask, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
for (int i = 0; i < contours.size(); i++)
{
cv::Rect box = cv::boundingRect(contours[i]);//获取轮廓的外接矩形
cv::rectangle(src, box, cv::Scalar(255, 0, 0), 2, 8, 0);
}
cv::imshow("mask",mask);
cv::imshow("场景文字检测", src);
// cv::addWeighted(src, 0.5, mask, 0.5, 0, src);//叠加
return;
}
10、文字识别
10.1、模型介绍
图45
10.2、程序执行步骤
在文字检测之后返回文字区域给文字识别模型作为输入进行识别
10.3、代码演示
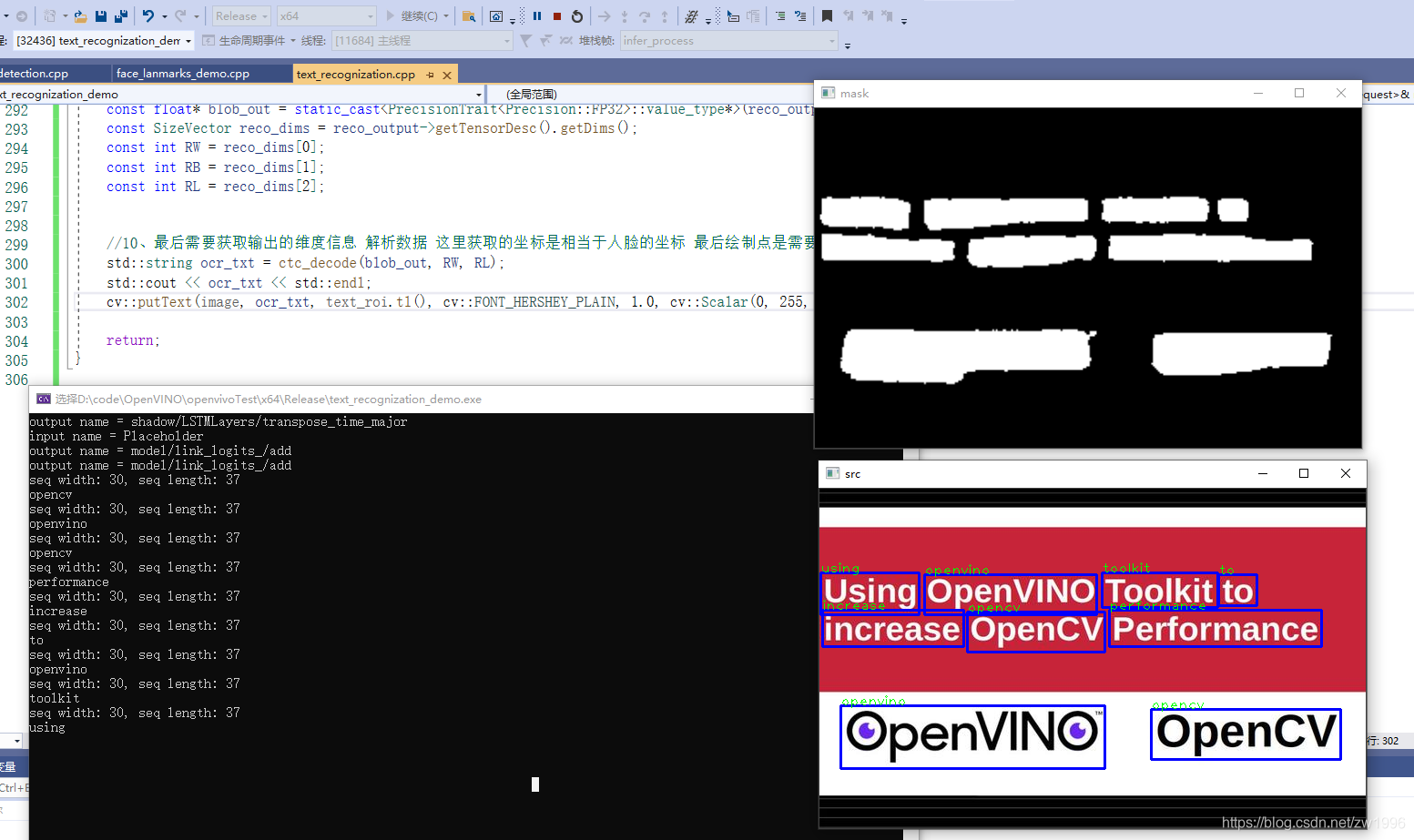
图46
代码实践
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <fstream>
using namespace InferenceEngine;
//将mat过来的数据U8类型的 转为Blob,因为Blob是任意类型的因此也声明为模板、
template <typename T> void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
//文字识别的CTC算法
std::string alphabet = "0123456789abcdefghijklmnopqrstuvwxyz#";
std::string ctc_decode(const float* blob_out, int seq_w, int seq_l) {
printf("seq width: %d, seq length: %d \n", seq_w, seq_l);
std::string res = "";
bool prev_pad = false;
const int num_classes = alphabet.length();
int seq_len = seq_w * seq_l;
for (int i = 0; i < seq_w; i++) {
int argmax = 0;
int max_prob = blob_out[i * seq_l];
for (int j = 0; j < num_classes; j++) {
if (blob_out[i * seq_l + j] > max_prob) {//seq_w个实例 seq_l类别 拿到每个实例37个类别置信比最大的那个作为结果
max_prob = blob_out[i * seq_l + j];
argmax = j;
}
}
auto symbol = alphabet[argmax];
if (symbol == '#') {
prev_pad = true;
}
else {
if (res.empty() || prev_pad || (!res.empty() && symbol != res.back())) {
prev_pad = false;
res += symbol;
}
}
}
return res;
}
//加载文字识别的模型 传出 推理以及输入输出名称
void load_textRecognization_model(std::string xmlFilename, std::string binFilename, std::shared_ptr<InferenceEngine::InferRequest>& request, std::string& input_name, std::string& output_name);
//文字识别 设置输入 推理 解析输出
void text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& request, std::string& input_name, std::string& output_name, cv::Mat& image, cv::Rect& face_roi);
//文字识别异步推理之后对结果进行处理
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name, std::vector<cv::Rect>& vc_RoiRect);
//SSD MobileNetV2 模型输入推理设置函数 就是将输入的src转换为对应格式设置到 infer_request的Blob中
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//加载文字识别的模型
std::shared_ptr<InferenceEngine::InferRequest> text_detection_request;
std::string text_detection_input_name;
std::string text_detection_output_name;
std::string text_detection_xmlFilename = "D:/code/OpenVINO/text-recognition-0012/FP32/text-recognition-0012.xml";
std::string text_detection_binFilename = "D:/code/OpenVINO/text-recognition-0012/FP32/text-recognition-0012.bin";
load_textRecognization_model(text_detection_xmlFilename, text_detection_binFilename, text_detection_request, text_detection_input_name, text_detection_output_name);
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/text-detection-0003/FP32/text-detection-0003.xml";
std::string binFilename = "D:/code/OpenVINO/text-detection-0003/FP32/text-detection-0003.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name1 = "";
std::string output_name2 = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
int out_index = 0;
for (auto item : outputs)
{
if (out_index == 1)
{
output_name2 = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name1 << std::endl;
}
else
{
output_name1 = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name1 << std::endl;
}
out_index++;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto curr_infer_request = executable_network.CreateInferRequestPtr();
//6、输入图像数据预处理(包括BGR->RGB,大小 浮点数 计算转换 图像顺序转换HWC->NCHW)
//图片读取
cv::Mat curr_frame = cv::imread("D:/openvino_ocr.jpg");
std::vector<cv::Rect> vc_RoiRect;
frameToBlob(curr_frame, curr_infer_request, input_name);
curr_infer_request->Infer();
infer_process(curr_frame, curr_infer_request, output_name2, vc_RoiRect);
//对返回的文本区域的矩形框进行文字识别 设置输入 进行推理 解析输出
for (int i = 0; i < vc_RoiRect.size(); i++)
{
//if (vc_RoiRect[i].width > 32 && vc_RoiRect[i].height > 120 && vc_RoiRect[i].x > 0 && vc_RoiRect[i].y > 0)//要做保护 不然容易奔溃
text_recognization_text(text_detection_request, text_detection_input_name, text_detection_output_name, curr_frame, vc_RoiRect[i]);
}
cv::imshow("src", curr_frame);
char c = cv::waitKey(0);
return 0;
}
// SSD MobileNetV2 模型输入推理设置函数封装 因为要修改infer_request 所有还是需要传指针,智能指针
void frameToBlob(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& input_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request->GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
matU8ToBlob<uchar>(src, input);
return;
}
// SSD MobileNetV2 模型输出推理函数封装
void infer_process(cv::Mat& src, std::shared_ptr<InferenceEngine::InferRequest>& infer_request, std::string& output_name, std::vector<cv::Rect>& vc_RoiRect)
{
//1、执行推理
//infer_request->Infer(); 异步推理就不需要这一步了
cv::Rect box;
//2、获取我们的output
auto output = infer_request->GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//3、最后需要获取输出的维度信息 解析数据
//detection_out 是2*w*h个值的集合 我们要分析出h*w每个对应像素的2个类别 是text与非text
const SizeVector outputDims = output->getTensorDesc().getDims();
const int out_c = outputDims[1];//每个像素点的2个类型的值
const int out_h = outputDims[2];
const int out_w = outputDims[3];
cv::Mat mask = cv::Mat::zeros(cv::Size(out_w, out_h), CV_8U);//存放结果 0-1的
int step = out_h * out_w;
for (int row = 0; row < out_h; row++)
{
for (int col = 0; col < out_w; col++)
{
//文字检测模型 只有两个类别
float p1 = detection_out[row * out_w + col];//该像素第一个类别可能性值的
float p2 = detection_out[step + row * out_w + col];//该像素第二个类别可能性值的地址 是文本
if (p2 > 1.0) {
mask.at<uchar>(row, col) = 255;//之间存储 0 -255来mask文本区域
}
}
}
cv::resize(mask, mask, cv::Size(src.cols, src.rows));//尺寸转换便于叠加
//变成一张二值图像
//mask = mask * 255;//值乘以255 范围从0-1变为0-255
//mask.convertTo(mask, CV_8U);//数据类型转换
//cv::threshold(mask, mask, 200, 255, cv::THRESH_BINARY);
//绘制轮廓
std::vector<std::vector<cv::Point>> contours;
cv::findContours(mask, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
for (int i = 0; i < contours.size(); i++)
{
cv::Rect box = cv::boundingRect(contours[i]);//获取轮廓的外接矩形
box.x = box.x - 4;
box.y = box.y - 4;
box.width = box.width + 8;
box.height = box.height + 8;
cv::rectangle(src, box, cv::Scalar(255, 0, 0), 2, 8, 0);
vc_RoiRect.push_back(box);
}
cv::imshow("mask", mask);
return;
}
void load_textRecognization_model(std::string xmlFilename, std::string binFilename, std::shared_ptr<InferenceEngine::InferRequest>& request, std::string& input_name, std::string& output_name)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
/*std::string xmlFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.xml";
std::string binFilename = "D:/code/OpenVINO/facial-landmarks-35-adas-0002/FP32/facial-landmarks-35-adas-0002.bin";*/
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
/*std::string input_name = "";
std::string output_name = "";*/
for (auto item : inputs)//因为这个模型有两个输入 则会循环两次的
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
request = executable_network.CreateInferRequestPtr();
}
void text_recognization_text(std::shared_ptr<InferenceEngine::InferRequest>& request, std::string& input_name, std::string& output_name, cv::Mat& image, cv::Rect& text_roi)
{
//设置输入
cv::Mat gray;
cv::cvtColor(image, gray, cv::COLOR_BGR2GRAY);
cv::Mat faceROI = gray(text_roi);//因为文本识别的模型需要灰度图作为输入
// frameToBlob(faceROI, face_lanmarks_request, face_lanmarks_input_name);
auto reco_input_blob = request->GetBlob(input_name);
size_t num_channels = reco_input_blob->getTensorDesc().getDims()[1];
size_t h = reco_input_blob->getTensorDesc().getDims()[2];
size_t w = reco_input_blob->getTensorDesc().getDims()[3];
size_t image_size = h * w;
cv::Mat blob_image;
cv::resize(faceROI, blob_image, cv::Size(w, h));
// HWC =》NCHW
unsigned char* data = static_cast<unsigned char*>(reco_input_blob->buffer());
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
data[row * w + col] = blob_image.at<uchar>(row, col);//是unchar类型的
}
}
//执行推理
request->Infer();
//输出string结果返回
auto reco_output = request->GetBlob(output_name);
const float* blob_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(reco_output->buffer());
const SizeVector reco_dims = reco_output->getTensorDesc().getDims();
const int RW = reco_dims[0];
const int RB = reco_dims[1];
const int RL = reco_dims[2];
//10、最后需要获取输出的维度信息 解析数据 这里获取的坐标是相当于人脸的坐标 最后绘制点是需要以图片的坐标
std::string ocr_txt = ctc_decode(blob_out, RW, RL);
std::cout << ocr_txt << std::endl;
cv::putText(image, ocr_txt, text_roi.tl(), cv::FONT_HERSHEY_PLAIN, 1.0, cv::Scalar(0, 255, 0), 1);
return;
}
11、pytorch模型转换与部署
对于之前的很多检测识别都可以基于OpenVINO很快的开发出demo,但是还有一类网络他没有一些预训练的模型,那我们就可以通过其他的深度学习框架来进行训练,训练生成的模型之后,我们再重新部署到我们的OpenVINO上来进行推理加速这样的一个深度模型的部署,这一块了就需要一个底层的支持,这个支持呢就是需要我们OpenVINO当中的一个automasz,前面我们讲的都是OpenVINO当中的IE(interfaceEngine 推理引擎部分)而这个实例就是要讲怎么把一个pytorch模型转成onnx模型然后让OpenVINO来加载这个onnx模型或转为IR的模型让OpenVINO来加载这个IR的模型,最后实现一个模型的推理和演示的步骤。
关于环境部署的群友给的一些链接,因为自己学习openVINO也只是作为储备技术的,
所以这些部分相关的就暂时不去了解,实践了。
https://www.cnblogs.com/qianwangxingfu/p/13582884.html
https://www.bilibili.com/video/BV1UE411N7gS
anconda 配置pytorch 和tensorflow
安装Pycharm 在Pycharm 选下解释器 就可以了
11.1、ONNX与支持
如果你是用Pytorch来训练的一个模型的话,那么你是可以转换为onnx的。现在是你已经Pytorch模型已经训练好了有pth文件了,现在怎么把他变成一个onnx或者变成一个IR。(可以调用Pytorch里面的API进行转换),之前我们的案例都是加载bin和xml也就是IR的中间文件,其实我们也可以之间加载模型的onnx格式的文件完成推理也是有同样的效果的。
11.2、pth文件转ONNX格式文件
11.3、ONNX转换IR文件(binxml文件)
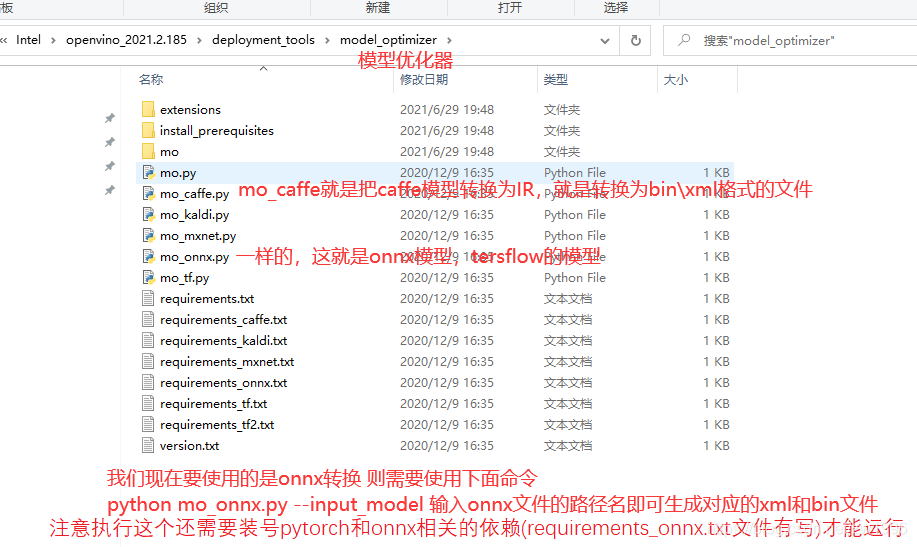
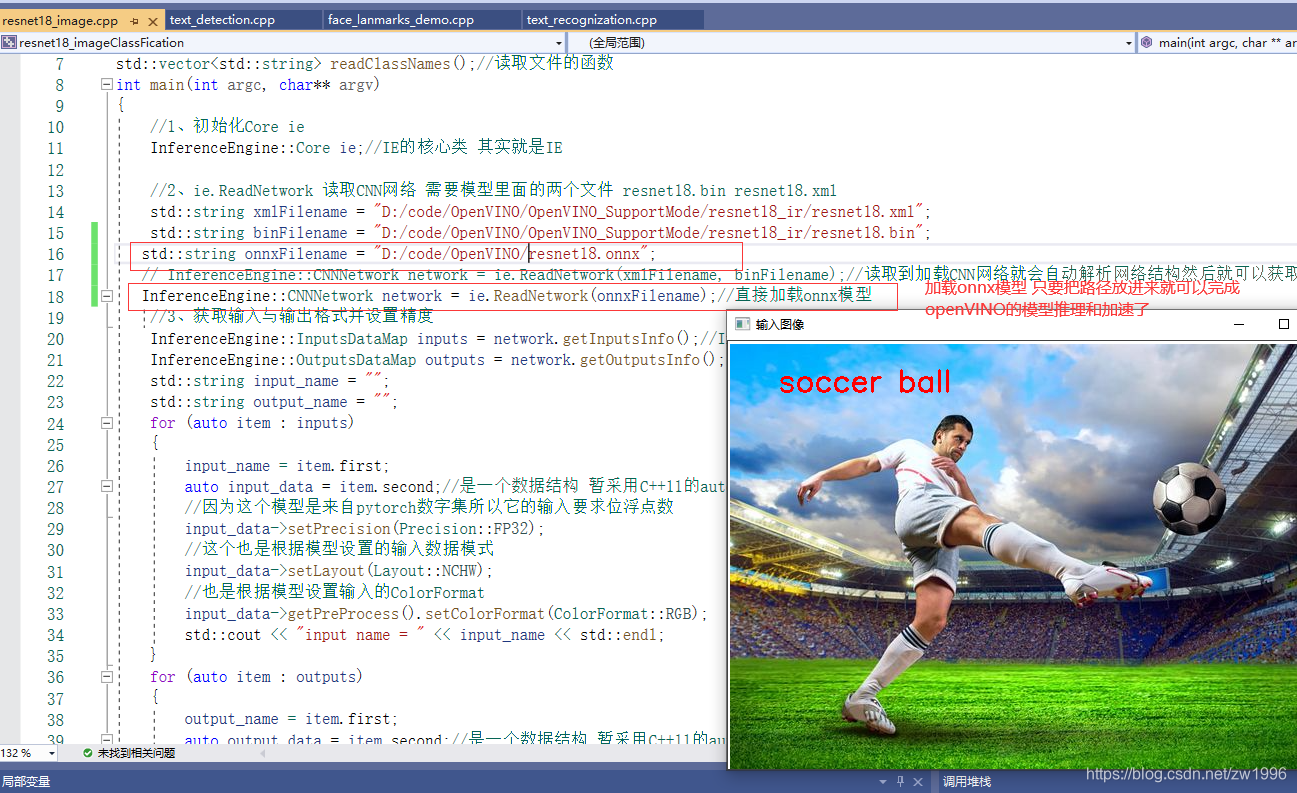
・图47 48
12、tensorflow模型转换与部署
13、YOLOv5模型部署与推理
总结:
OpenVINO的引入:模型的落地需求,特别是边缘设备上的落地
C++实践的环境搭建:配置头文件路径,库路径,库依赖,以及相关应用程序的环境变量配置
ResNet18图像分类模型:设置模型输入、解析二维输出[1,1000];
车辆与车牌的检测与识别:关键是解析思维输出[1,1,N,7]、多模型推理支持,ROI区域传递
行人检测:关键是视频的实时封装输入推理解析,以及输入接口的封装C++的泛化
人脸检测:视频的异步推理方式
表情识别:多模型推理支持以及异步推理保证实时
人脸Landmark35个关键点检测;注意返回的ROI区域判断以及人脸五官位置的扩展开发
实时语义道路分割:关键是解析分割网络的多通道输出,是1:4:h:w的格式,以及如何得到相应像素的对应类型的地址位置。以及相关的opencv技巧完成结果输出
实例分割:RCNN模型都是有两个输入层要设置的,以及解析实例ROI区域的类别mask生成以及相关opencv技术完成实例输出
场景文字检测:PixelLink模型输出的解析技巧,关键是浮点数与uchar类型的转换
场景文字识别:关键在于输入为灰度图要求、CTC贪心算法进行输出结构解析、以及文字区域的ROI截取。
后续还有模型转换,python等相关的内容因为暂时没有相关的技术储备所以先暂时放到这里,等相关深度学习模型以及python语言进行了系统性的学习后再来进行学习与openVINO相关的知识。
代码工程已经测试素材会上次到csdn资源中
博客笔记来自于;贾志刚老师的openVINO课程