UNITER多模态预训练模型原理
1. 数据
? 过去的5年中,Vision+NLP的研究者所使用的主要数据集如下展示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RtY76Rgr-1626104469607)(./img/过去5年researcher用到的数据集展示.png)]](https://img-blog.csdnimg.cn/20210712234148384.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RheWxvcmFuZHk=,size_16,color_FFFFFF,t_70)
? 本文中所使用到的4种数据集如下图所示,Conceptual Captions和SBU Captions数据集是免费的,但是不是太clean:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qmaVDFtw-1626104469608)(./img/本论文中用到的四种数据集.png)]](https://img-blog.csdnimg.cn/20210712234158299.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RheWxvcmFuZHk=,size_16,color_FFFFFF,t_70)
2. 算法
2.1 整体结构
? 这里采用的是two-stage training pipeline训练流程。在一些大量的,含有噪声但是比较cheap的数据上,我们设计一些预训练任务,但是这些预训练任务需要被小心的design,因为我们要获得一个鲁棒的training。然后,把这些预训练好的模型通过fine-tining适应到下流的任务中,同时在下流任务中的数据一般是规模比较小的而且clean的。同时之前的任务一般最多只能适应2-3个task,但是这里我们同时在下游fine-tine9个model,取得了9个SOTA。具体如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TlTHv1MW-1626104469610)(./img/训练流程.png)]](https://img-blog.csdnimg.cn/20210712234209171.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RheWxvcmFuZHk=,size_16,color_FFFFFF,t_70)
? 原始训练数据的形式是如下图所示:

? 首先通过目标检测模型把image转换成一系列的region,然后把句子tokenize之后转化成一个序列,之后把它们作为输入转化到UNITER中:

? UNITER的结构由三个部分构成,第一个部分是Image Embedder,具体来说就是用Faster-RCNN抽取每个region的region feature,同时用一个7维的向量(可能是四个坐标位置加上宽高或者面积等信息构成的7维向量,UNITER并没有直接使用检测器针对每个region输出的类别信息)来encode每一个region的position,将region feature和location feature通过fc层再相加构成了一个Image feature。
? 在Text Embedder中,就和bert中类似,就是一个token embedding和position embedding相加之后经过一个Layer Norm层,得到了Text Feature。把前面两部分特征经过transfomer就得到了UNITER Model。
? 除此之外UNITER还设计了三个预训练的任务去训练UNITER模型。第一个是Masked Language Modeling(MLM),即随机mask掉一些词,然后训练模型尝试让他去recover这个词。相同的MRM表示的是我们随机mask掉图片中提取出来的一些区域,然后recover这些缺失的区域。第三个任务是Image-Text-Matching(ITM),在这个任务中我们抽取整样本图文pair或者负样本图文pair,让模型去预测输入时正还是负。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yztaS0nm-1626104469611)(.\img\UNITER_Model.png)]](https://img-blog.csdnimg.cn/20210712234244857.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RheWxvcmFuZHk=,size_16,color_FFFFFF,t_70)
2.2 具体细节
? 下面让我们看一下每一个预训练任务具体的细节。
? (1)第一个预训练任务MLM,输入是图片和文本对,随机的mask掉一些位置的词语,目标是在这些mask掉的位置让UNITER去recover原本的token,所以这里用到的损失函数是负的log似然函数,具体如下图:

? (2)第二个预训练任务是MRM,被mask掉的不是word,而是图片中的region,希望能够recover那些mask掉的region,这里提出了三种方法(对应三种loss)去重构。第一种是让模型recover出的feature对应的vector1和真实的feature对应的vector2之间做L2范数损失。

? 第二种是Faster-RCNN得到的是class label和bbox,所以我们针对一个region可以让UNITER去预测它的分类,我们希望ground truth的class可以得到最高的置信度分数,具体来说如下图所示,橙色的是ground的label,绿色的是UNITER的输出置信度,我们可以用交叉熵损失,从而让他学习到每一个mask类型的分类。

? 第三种是我们可以用Faster-RCNN输出的类别分布做损失,橙色的是Faster-RCNN的输出,我们希望UNITER输出的分布尽可能接近橙色的分布,具体见下图:

? (3)第三个预训练任务是ITM,每当我们输入一个image-text pair,我们希望通过随机mask掉image或者text来建造一个negative pair,我们的目标是预测输入的image-text pair是不是存在对应关系,所以这是一个二分类问题。

? 前面介绍了这么多预训练任务和方法,具体哪些方法对模型性能提升有效果,这个在实验中具体介绍。
3.计算
3.1 计算资源
? 计算基本资源如下所示,每个virtual machine(VM)是有16个机器,每个机器上有4块V100的卡。对于UNITER base来说,预训练4.5天即可,加上finetune基本上10天时间确定一个模型的performance足够,UNITER large需要4个VM,预训练需要10天时间。


3.2 Optimization on Limited GPUs
? 本文中一共用了三种计算优化方法,下面依次介绍一下。
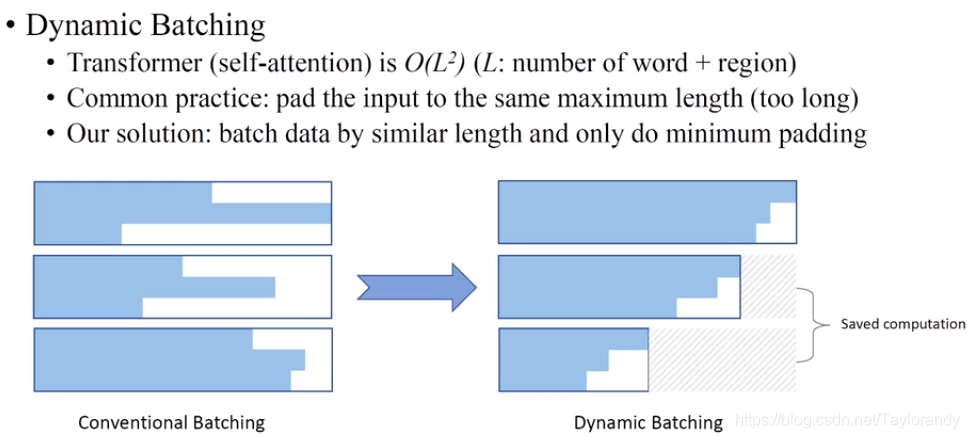
3.2.1 Dynamic Batching
? 第一种就是动态batching,因为transformer的计算复杂度是和输入序列的长度的二次方呈线性相关,这里的长度在我们的vision+language里面是词的数量加上region的长度。一般的batching是像左边图这样,把输入padding至相同的长度,所以可以看见浪费很多的计算空间,而我们的做法是把输入按照长度进行排序,然后把长度相近的放在同一个batch里,这样我们就减少了padding从而节省了计算时间。
3.2.2 Gradient Accumulation
? UNITER large里面用了四个Virtual Machine(VM),而时间主要花费在network communication overhead上,我们用Gradient Accumulation减少交流的频率,从而增加总吞吐量。

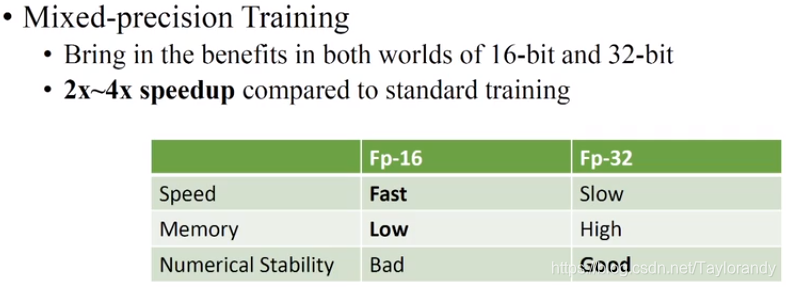
3.2.3 Mixed-precision Training
? 这里同时应用了16bit和32bit的图像表示,节省了空间,从而batchsize可以增大,从而减少训练时间。
4.下游任务具体实现过程
4.1 Visual Question Answering
? 对于一个图片,回答和图片相关的问题。我们把图片和问题输入到UNITER中,输出是答案的分布,得到最大概率的答案作为我们的预测答案,我们这里用交叉熵损失监督这个下有任务的fine-tuning。


4.2 Visual Entailment
? 问题描述为图片是premise,文本为Hypothesis,目标是预测文本text是不是Entail图片。有三种label,Entailment(确定)、Neutral(中立)、Contradiction(反对),输出是三个类别,用交叉熵监督。


4.3 Natural Language for Vision Reasoning
? 问题描述为输入两张图片和一个text描述,判断文字是否为两张图片的描述。这里结构做了一定的改动,我们把输入的两张图片分别put到两个UNITER结构种,并且把text描述double一下,使得两边是一样的描述,这样就得到了联合特征表达,把这个联合特征表达经过一个叫Bi-Attention层输出预测的label。


4.4 Visual Commonsense Reasoning
? 问题描述为对于一个问题有四个备选答案,model必须从四个备选答案中选择出一个作为prediction,并且从四个备选的理由中选出选择这个答案的理由。所以在训练中,我们把问题和每个备选的答案concat到一块,分别和图片一起输入到UNITER中得到了四个score,最高score的答案作为最后的预测,同理在选择理由的时候我们也可以把问题答案和理由的选项concat到一起,输入到UNITER中,然后用交叉熵去监督训练。


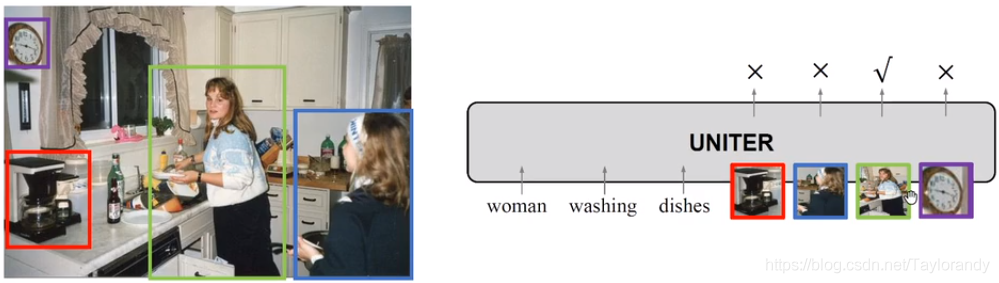
4.5 Referring Expression Comprehension
? 问题描述为输入是一个句子,模型要在图片中找到对应的区域。之前有讲到,其实图片部分是表征为一系列的region集合,所以可以每一个region都输出一个score,得到最高score的region作为预测的region。

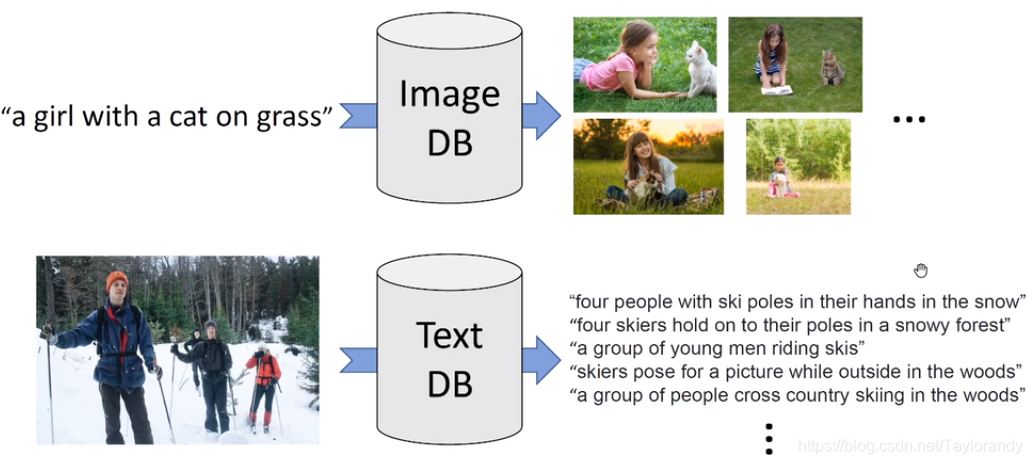
4.6 Image-Text Retrieval
? 这个问题描述是给定一个text,找出对应的图片,或者给定一个图片,找出对应的text。和前面介绍到的图文匹配很像,通过选取positive还是negative pair的方式来训练model,UNITER的目标是判断输入的pair是positive还是negative。

5.实验
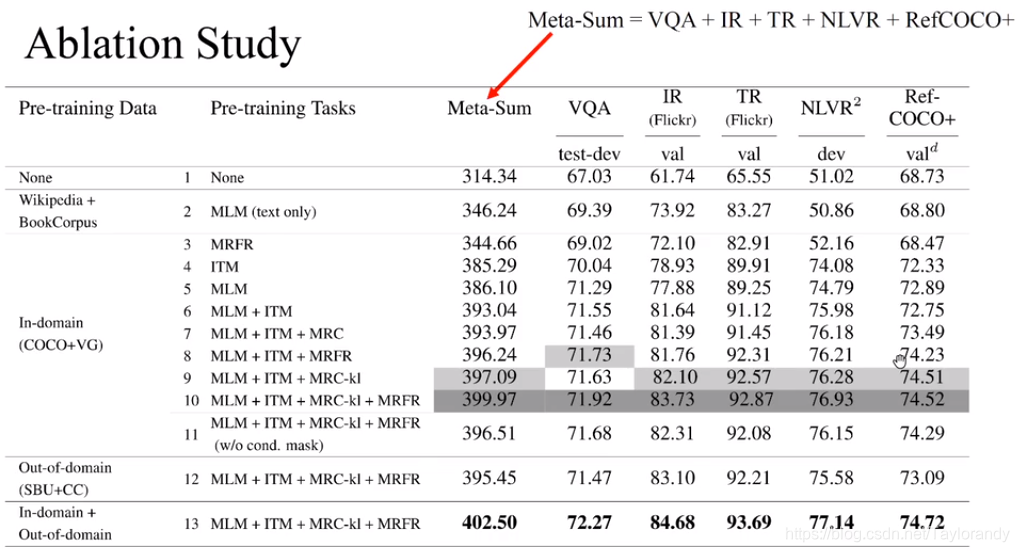
5.1 消融实验
? 为了验证前面哪种方式对模型性能提升最大,此处针对五个下游任务做了消融实验,通过是将五个任务的结果合并成一个Meta-Sum的评价指标用来衡量模型的好坏。同时在消融实验中得到了几个结论如下所示:
? 1、Language Pre-training is better than No pretraining.
? 2、Vision + Language together > Vision/Language
? 3、Best combination : MLM + ITM + MRC-kl + MRFR
? 4、More data the better
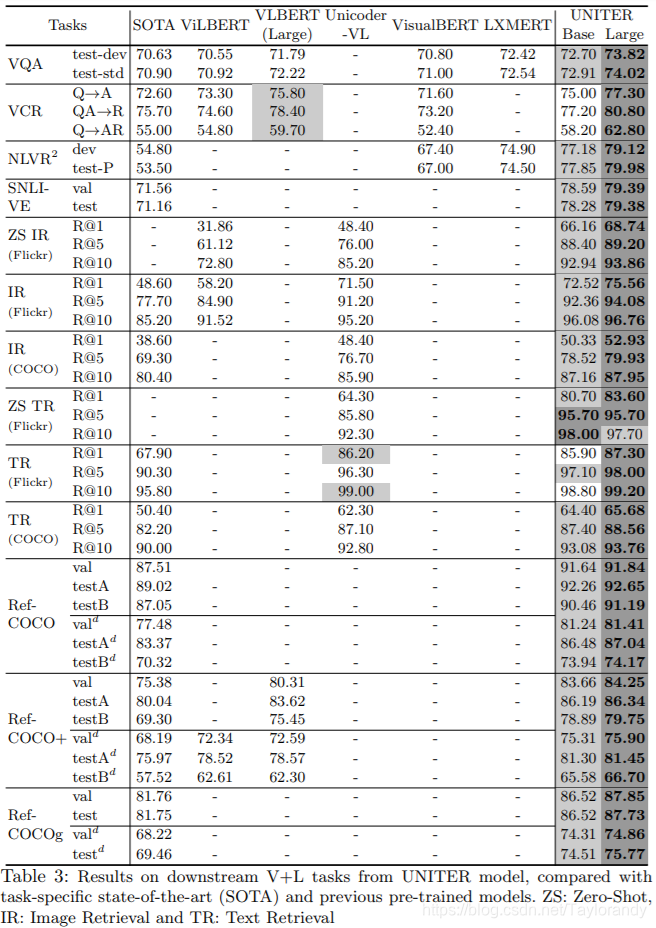
5.2 实验结果
? 多项任务取得SOTA
6.核心代码阅读
? UNITER模型的核心在根目录下的model文件夹下的model.py中,其中包含UniterConfig类、UniterPreTrainedModel类、UniterModel类(主模型类)。下面就介绍一下UniterConfig类和UniterModel类,同时介绍一下构成UniterModel类的一些子类。github代码网址链接:https://github.com/ChenRocks/UNITER
6.1 UniterConfig类
? 该类主要是配置Uniter模型的一些超参数,具体的超参数含义在如下代码后面标识。
class UniterConfig(object):
"""Configuration class to store the configuration of a `UniterModel`.
"""
def __init__(self,
vocab_size_or_config_json_file, #在`UniterModel`中'inputs_ids'的词表size
hidden_size=768, #编码层和池化层的size
num_hidden_layers=12, #transformer encoder中隐藏层的数量
num_attention_heads=12, #attention head的数量对于每个transformer encoder隐藏层
intermediate_size=3072, #size of "intermediate" (i.e.feed-forward) layer in the Transformer encoder
hidden_act="gelu", #激活函数,swish和relu同样支持
hidden_dropout_prob=0.1, #在embedding,编码和池化中的全连接层drop概率
attention_probs_dropout_prob=0.1,#attention中的drop概率
max_position_embeddings=512, #最大序列长度,通常设置为(e.g., 512 or 1024 or 2048)
type_vocab_size=2, #`token_type_ids`的词表size
initializer_range=0.02): #初始权重矩阵的标准差
if isinstance(vocab_size_or_config_json_file, str):
with open(vocab_size_or_config_json_file,
"r", encoding='utf-8') as reader:
json_config = json.loads(reader.read())
for key, value in json_config.items():
self.__dict__[key] = value
elif isinstance(vocab_size_or_config_json_file, int):
self.vocab_size = vocab_size_or_config_json_file
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
else:
raise ValueError("First argument must be either a vocabulary size "
"(int) or the path to a pretrained model config "
"file (str)")
@classmethod
def from_dict(cls, json_object):
"""Constructs a `UniterConfig` from a
Python dictionary of parameters."""
config = UniterConfig(vocab_size_or_config_json_file=-1)
for key, value in json_object.items():
config.__dict__[key] = value
return config
@classmethod
def from_json_file(cls, json_file):
"""Constructs a `UniterConfig` from a json file of parameters."""
with open(json_file, "r", encoding='utf-8') as reader:
text = reader.read()
return cls.from_dict(json.loads(text))
def __repr__(self):
return str(self.to_json_string())
def to_dict(self):
"""Serializes this instance to a Python dictionary."""
output = copy.deepcopy(self.__dict__)
return output
def to_json_string(self):
"""Serializes this instance to a JSON string."""
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
6.2 UniterModel类
? UniterModel的主模块,首先是在构造函数中先进行UniterTextEmbeddings、UniterImageEmbeddings、UniterEncoder等类的初始化。分仅有text,仅有image或者既有text又有image三种情况构造embedding layer。
class UniterModel(UniterPreTrainedModel):
""" Modification for Joint Vision-Language Encoding
"""
def __init__(self, config, img_dim):
super().__init__(config)
self.embeddings = UniterTextEmbeddings(config) # textEmbedding类
self.img_embeddings = UniterImageEmbeddings(config, img_dim) # imageEmbedding类
self.encoder = UniterEncoder(config) # encoder类使用的就是bert的encoder
self.pooler = BertPooler(config)
self.apply(self.init_weights)
def _compute_txt_embeddings(self, input_ids, position_ids,
txt_type_ids=None):
output = self.embeddings(input_ids, position_ids, txt_type_ids)
return output
def _compute_img_embeddings(self, img_feat, img_pos_feat, img_masks=None,
img_type_ids=None):
if img_type_ids is None:
img_type_ids = torch.ones_like(img_feat[:, :, 0].long())
img_type_embeddings = self.embeddings.token_type_embeddings(
img_type_ids)
output = self.img_embeddings(img_feat, img_pos_feat,
img_type_embeddings, img_masks)
return output
def _compute_img_txt_embeddings(self, input_ids, position_ids,
img_feat, img_pos_feat,
gather_index, img_masks=None,
txt_type_ids=None, img_type_ids=None):
txt_emb = self._compute_txt_embeddings(
input_ids, position_ids, txt_type_ids)
img_emb = self._compute_img_embeddings(
img_feat, img_pos_feat, img_masks, img_type_ids)
# align back to most compact input
gather_index = gather_index.unsqueeze(-1).expand(
-1, -1, self.config.hidden_size)
embedding_output = torch.gather(torch.cat([txt_emb, img_emb], dim=1),
dim=1, index=gather_index)
return embedding_output
def forward(self, input_ids, position_ids,
img_feat, img_pos_feat,
attention_mask, gather_index=None, img_masks=None,
output_all_encoded_layers=True,
txt_type_ids=None, img_type_ids=None):
# compute self-attention mask
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(
dtype=next(self.parameters()).dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
# embedding layer
if input_ids is None:
# image only
embedding_output = self._compute_img_embeddings(
img_feat, img_pos_feat, img_masks, img_type_ids)
elif img_feat is None:
# text only
embedding_output = self._compute_txt_embeddings(
input_ids, position_ids, txt_type_ids)
else:
embedding_output = self._compute_img_txt_embeddings(
input_ids, position_ids,
img_feat, img_pos_feat,
gather_index, img_masks, txt_type_ids, img_type_ids)
encoded_layers = self.encoder(
embedding_output, extended_attention_mask,
output_all_encoded_layers=output_all_encoded_layers)
if not output_all_encoded_layers:
encoded_layers = encoded_layers[-1]
return encoded_layers
6.3 UniterModel模块中的关键子模块
? 这里就介绍UniterTextEmbeddings、UniterImageEmbeddings、UniterEncoder三个关键子模块的代码。
6.3.1 UniterTextEmbeddings类
? 此类的作用是将训练语料中的text信息转化成embedding向量,embedding向量的构成分为三个部分words_embeddings(词嵌入向量)、position_embeddings(位置嵌入向量)、token_type_embeddings(是否为前后语句对嵌入向量)。
class UniterTextEmbeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size,
config.hidden_size, padding_idx=0)
self.position_embeddings = nn.Embedding(config.max_position_embeddings,
config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size,
config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model
# variable name and be able to load any TensorFlow checkpoint file
self.LayerNorm = FusedLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, position_ids, token_type_ids=None):
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
words_embeddings = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = (words_embeddings
+ position_embeddings
+ token_type_embeddings)
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
6.3.2 UniterImageEmbeddings类
? Uniter模型中Image转化为embedding向量是关键,img_feat和img_pos_feat是如何生成的可以去前面2.1小节看一下,简单来说就是使用Faster-RCNN检测出多个region,region feature特征经过reshape或者dnn等方式转为img_feat,region的location转为img_pos_feat。然后分别经过fc层至相同维度,相加再经过LN层就生成了既含有图片特征又含有位置信息的embedding。
class UniterImageEmbeddings(nn.Module):
def __init__(self, config, img_dim): # img_dim在utils文件夹下的const.py内,默认等于2048
super().__init__()
self.img_linear = nn.Linear(img_dim, config.hidden_size)
self.img_layer_norm = FusedLayerNorm(config.hidden_size, eps=1e-12)
self.pos_layer_norm = FusedLayerNorm(config.hidden_size, eps=1e-12)
self.pos_linear = nn.Linear(7, config.hidden_size)
self.mask_embedding = nn.Embedding(2, img_dim, padding_idx=0) # 第一维度为2代表是否mask
# tf naming convention for layer norm
self.LayerNorm = FusedLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, img_feat, img_pos_feat, type_embeddings, img_masks=None):
if img_masks is not None:
self.mask_embedding.weight.data[0, :].fill_(0)
mask = self.mask_embedding(img_masks.long())
img_feat = img_feat + mask
transformed_im = self.img_layer_norm(self.img_linear(img_feat)) # img_feat做全连接
transformed_pos = self.pos_layer_norm(self.pos_linear(img_pos_feat)) # img_pos_feat做全连接
embeddings = transformed_im + transformed_pos + type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
6.3.3 UniterEncoder类
? Uniter模型中的Encoder部分使用的就是原始Bert中的encoder层,具体的可以去看pytorch版bert源码。
class UniterEncoder(nn.Module):
def __init__(self, config):
super().__init__()
layer = BertLayer(config)
self.layer = nn.ModuleList([copy.deepcopy(layer)
for _ in range(config.num_hidden_layers)])
def forward(self, input_, attention_mask,
output_all_encoded_layers=True):
all_encoder_layers = []
hidden_states = input_
for layer_module in self.layer:
hidden_states = layer_module(hidden_states, attention_mask)
if output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
if not output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
return all_encoder_layers