本文都是李宏毅老师课堂上的总结
背景和意义:
通常在实际生活中我们的训练集和测试集有很大的差异,例如下图左边为你的训练集,而真正让你进行检测和预测的确是右边的图片。

1. Domain Adaptaion 与 transformer learing的区别
Domain Adaptation 是 transformer learing 的一个子部分


如上图所示
就是只有source domain 有label ,在不同的domain 中预测相同的任务
2.什么是domain?
- 按照数据分类(例如:我们举出的背景例子中的两个数据可以理解为两个不同的domain)
- 按照任务分类(例如:分割任务,分类任务)
Source domain(S): 主要是指我们的训练集 这里每个数据都有相应的label
Target domain(T): 主要是预测集 没有label 而且与S 是不同的domain
3.运用
例如 使用gta5 的街景数据,帮助真实世界的街道数据分割之类的任务,因为gta是电脑生成的很容易获取位置
4.原理
Features: 这里就是指的提取出的特征,例如通过resnet 或者vgg提取出的特征 如下图所示
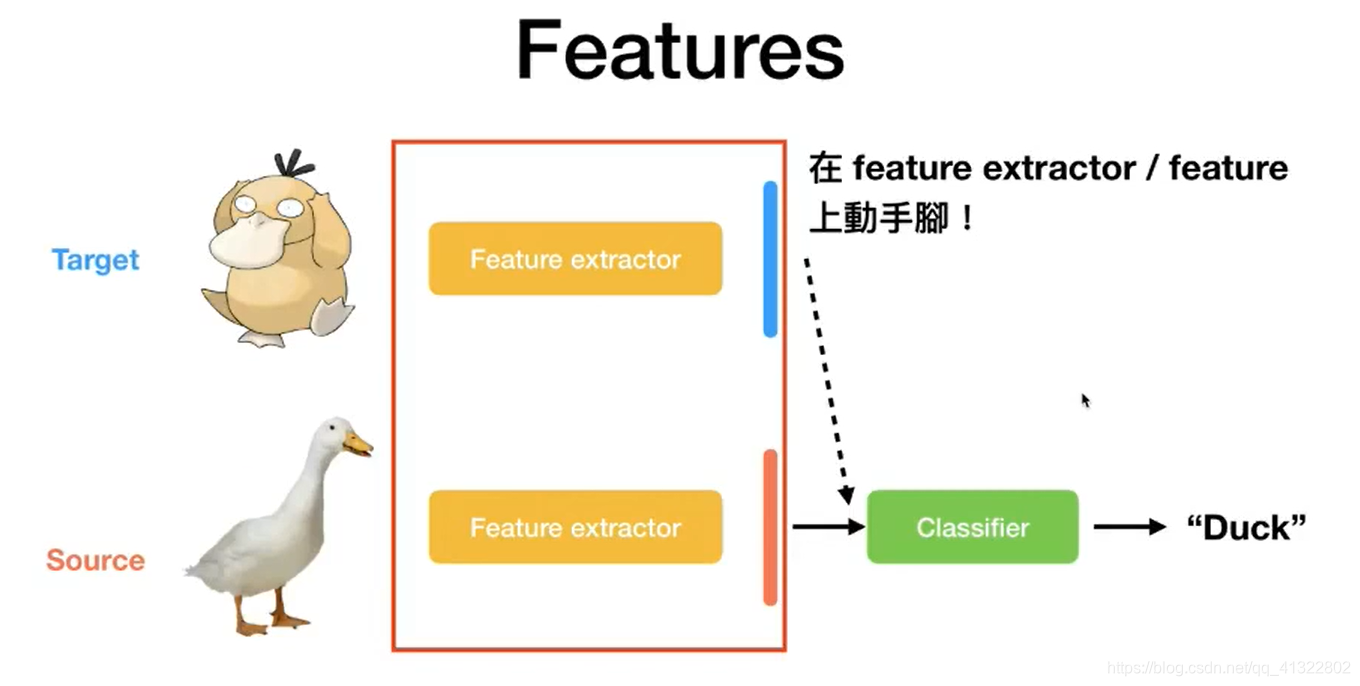
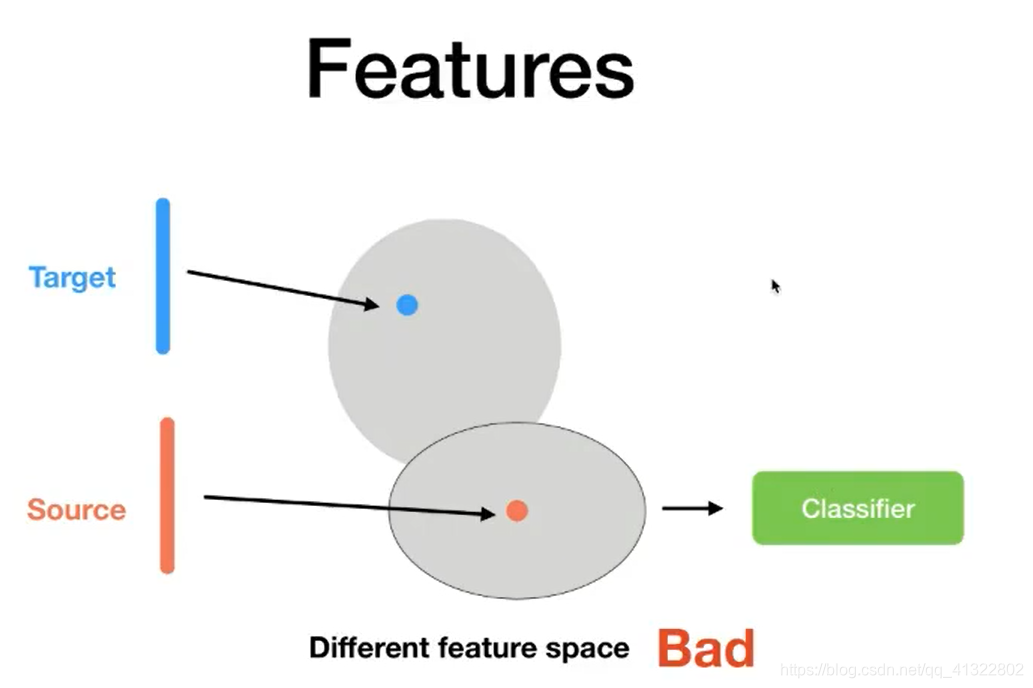
我们可以将特征假设在一个向量空间中 ,我们可以看出s和t的特征分布的差别非常的大,所以我们希望可以将这两个向量空间的映射到一个相似的区间之内。
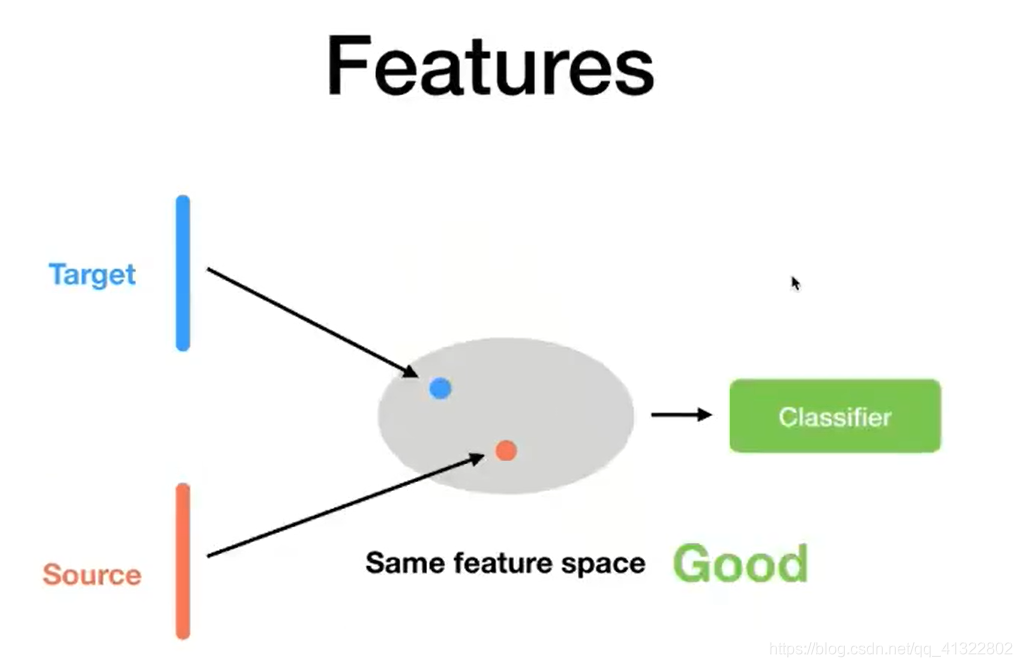
希望得到的:
5.实现方法
主要的实现方法分为三类:
- Discrepancy-base methods
- Adversarial-based methods
- Reconstruction-based methods
我个人认为 2 和 3的主要区别在于是否分解 3是对数据的分解而2主要是让网络提取 S和T的特征分布相似。
1. Discrepancy-base methods
主要通过一些统计量,计算Target domain 和 Source domain的距离,希望他们统计量上的分布式非常接近的.
样例paper:Deep Domain Confusion:Maximizing for Domain Invariance
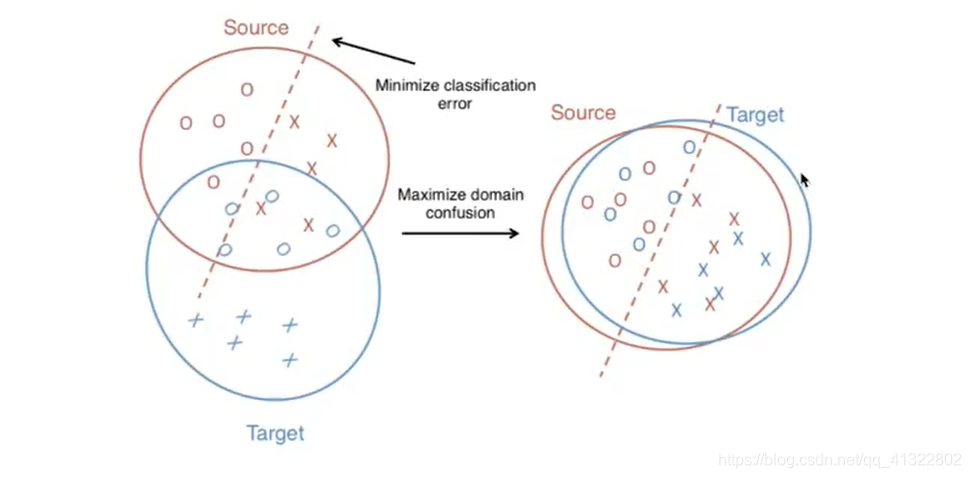
上图可以看出该种方法的思想:中左侧可以看出 S:中可以对数据进行分类,但是T和S 的分布差距比较大,后来经过处理之后得到右侧的图片,S和T的分布相似,而且可以通过S的分布和判断标准实现对T的分类。
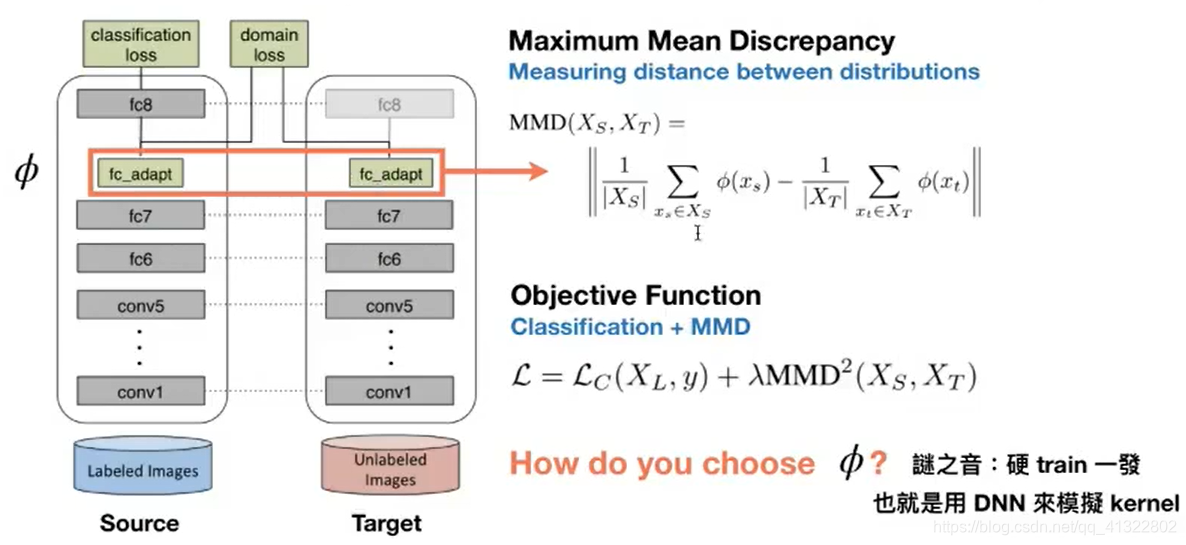
实现方法如上图所示:就是在Φ 上抽出features 计算距离,计算的方式就是Maximum Mean Discrepancy。
2. Adversarial-based Approaches
Domain Classifier:判断图片来自T 还是 S
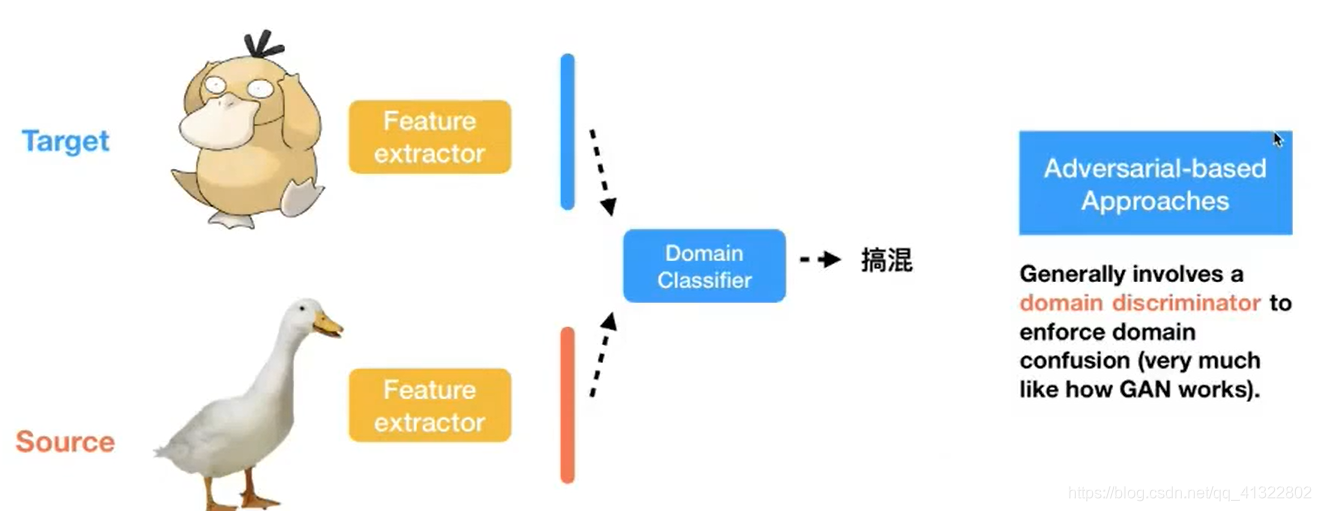
Simultaneous Deep Transfer Across Domains and Tasks 开山之作
假设:

paper:的主要内容
-
Maximu Domain Confusion
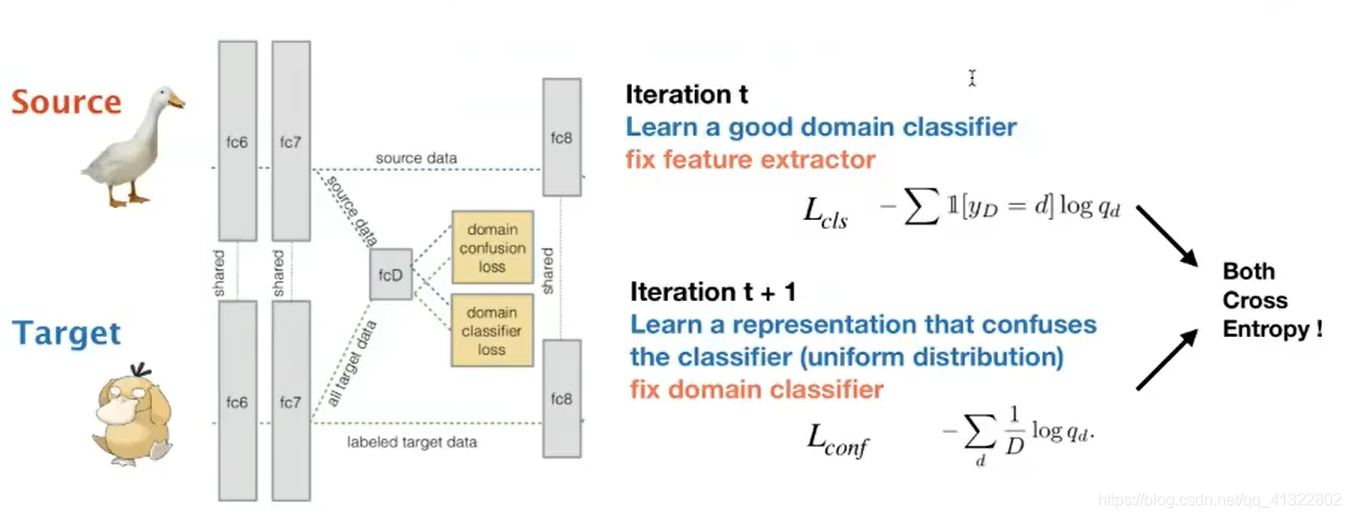
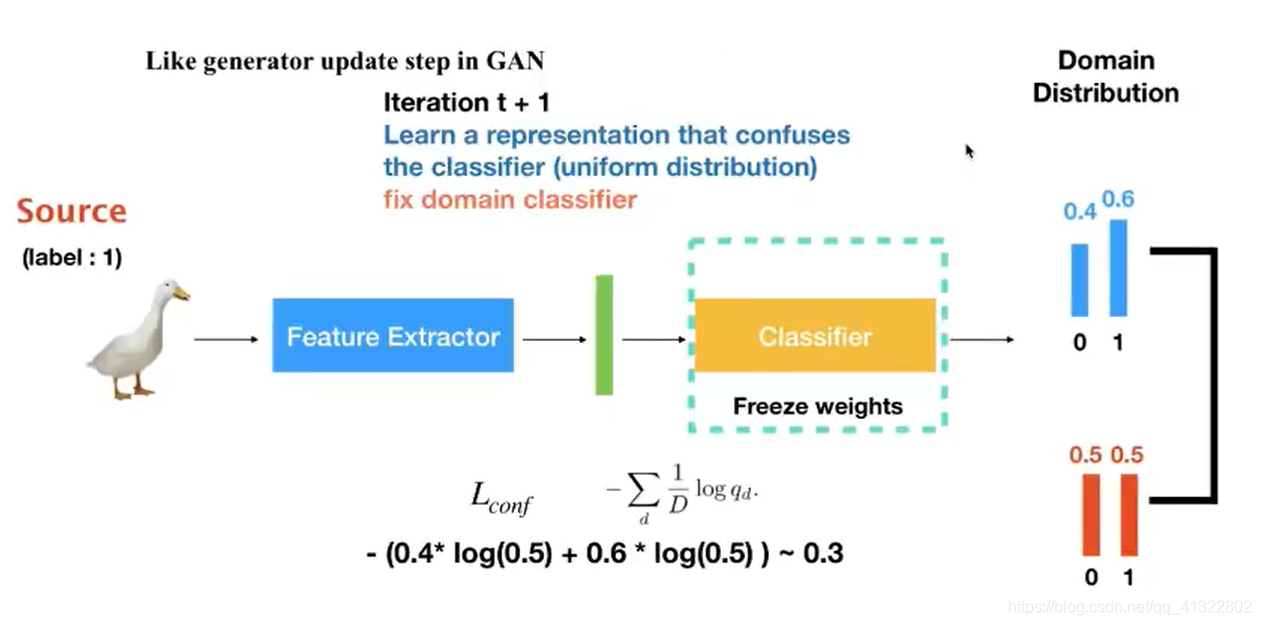
类似于GAN的思想:首先希望classifer可以正确分类,然后将classifer的参数不变,修改feature extractor希望他可以骗过classifer
-
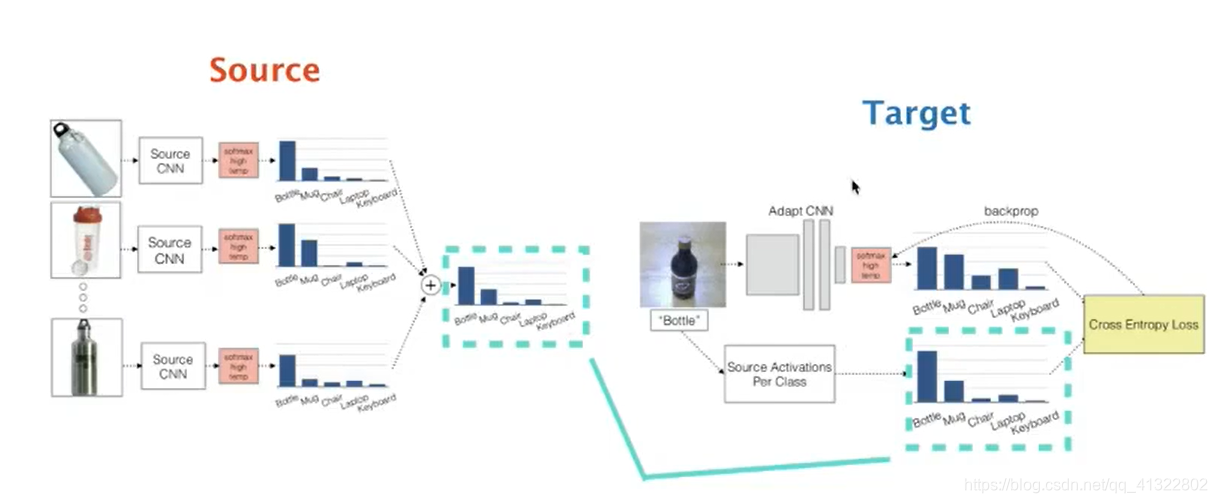
Transfer Label Correlation
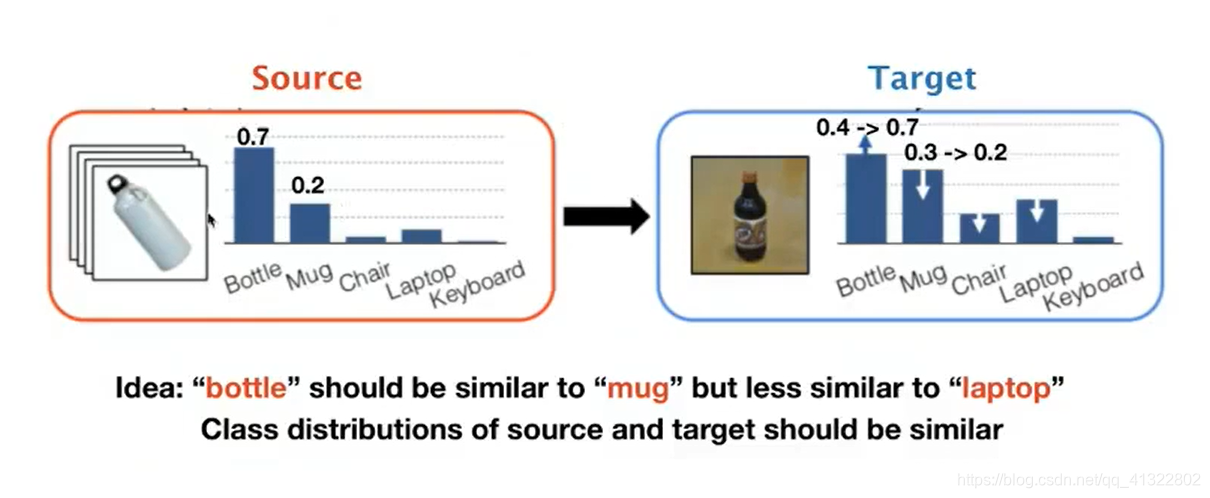
让判断东西可能性 也是相符合,class 与 class 之间的关系也作为一个特征。
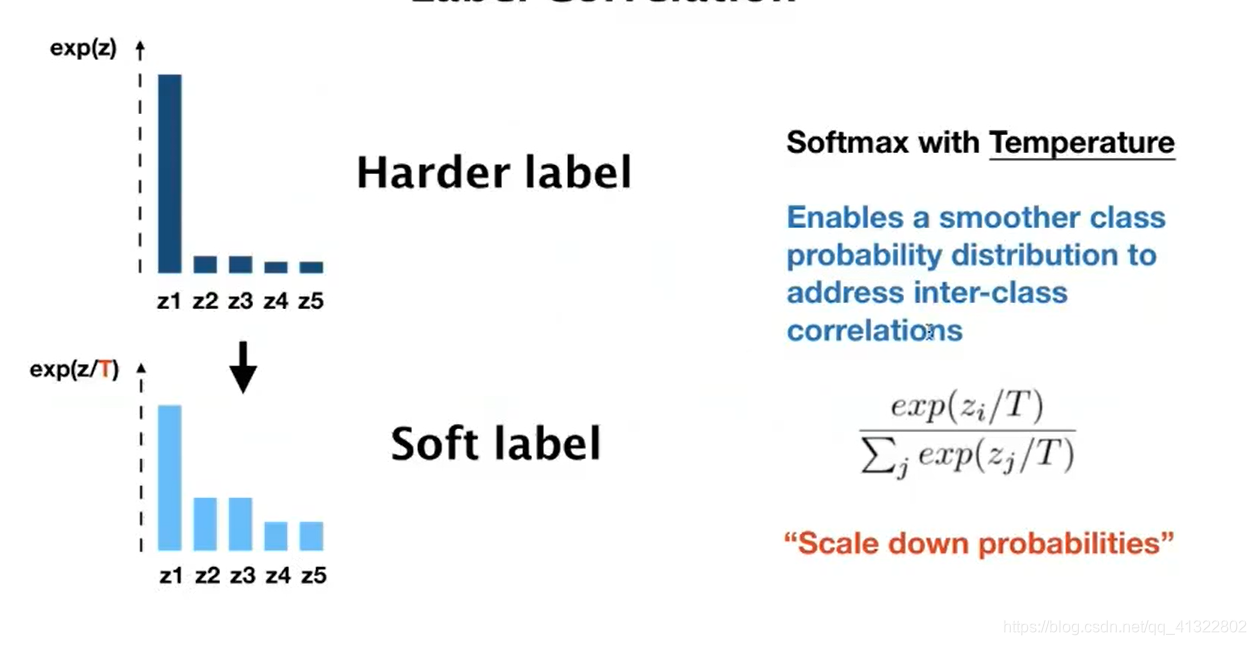
在实现上述之前 为了突出class之间的关系 我们将Harder lablel 转为 Soft label
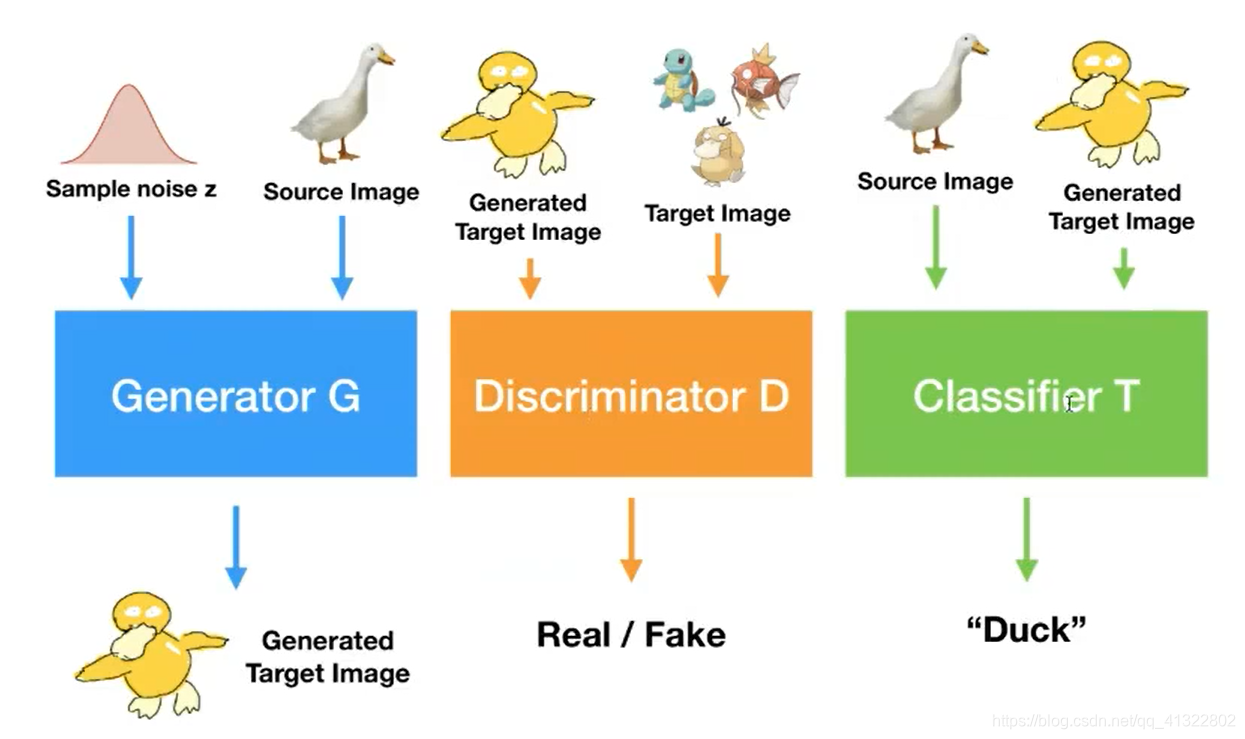
Pixel Level:使用GAN 进行对于原图生成神奇宝贝 然后交给鉴别器鉴别,最后用来分类。
文章为什么叫做Pixel level:其实默认s和t之间high level的性质差不多,但是low-level的差别较大。
3. Reonstruction-based
Deep Spearation Networks
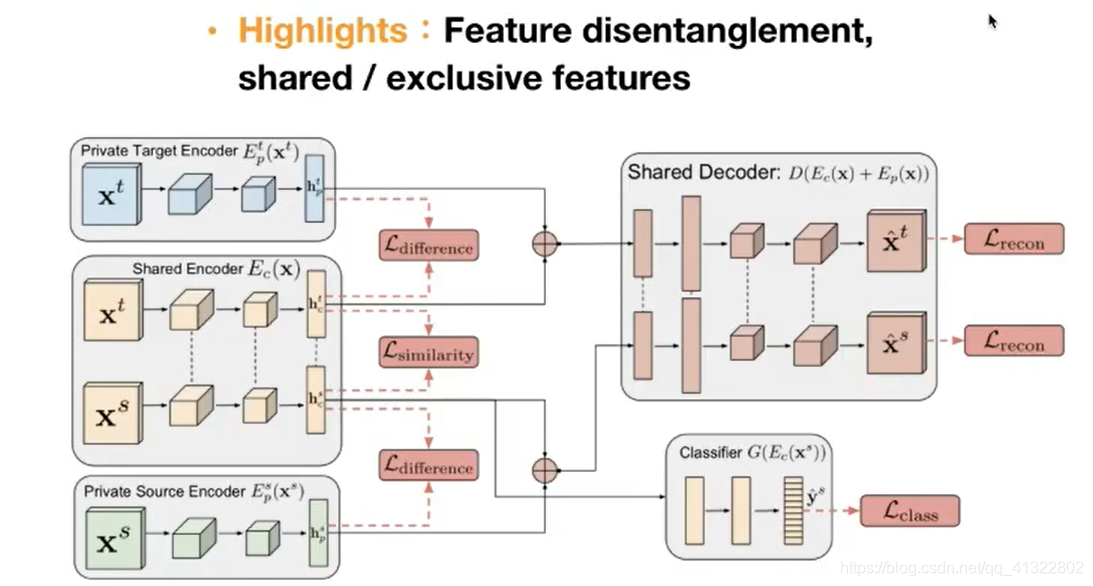
解释:
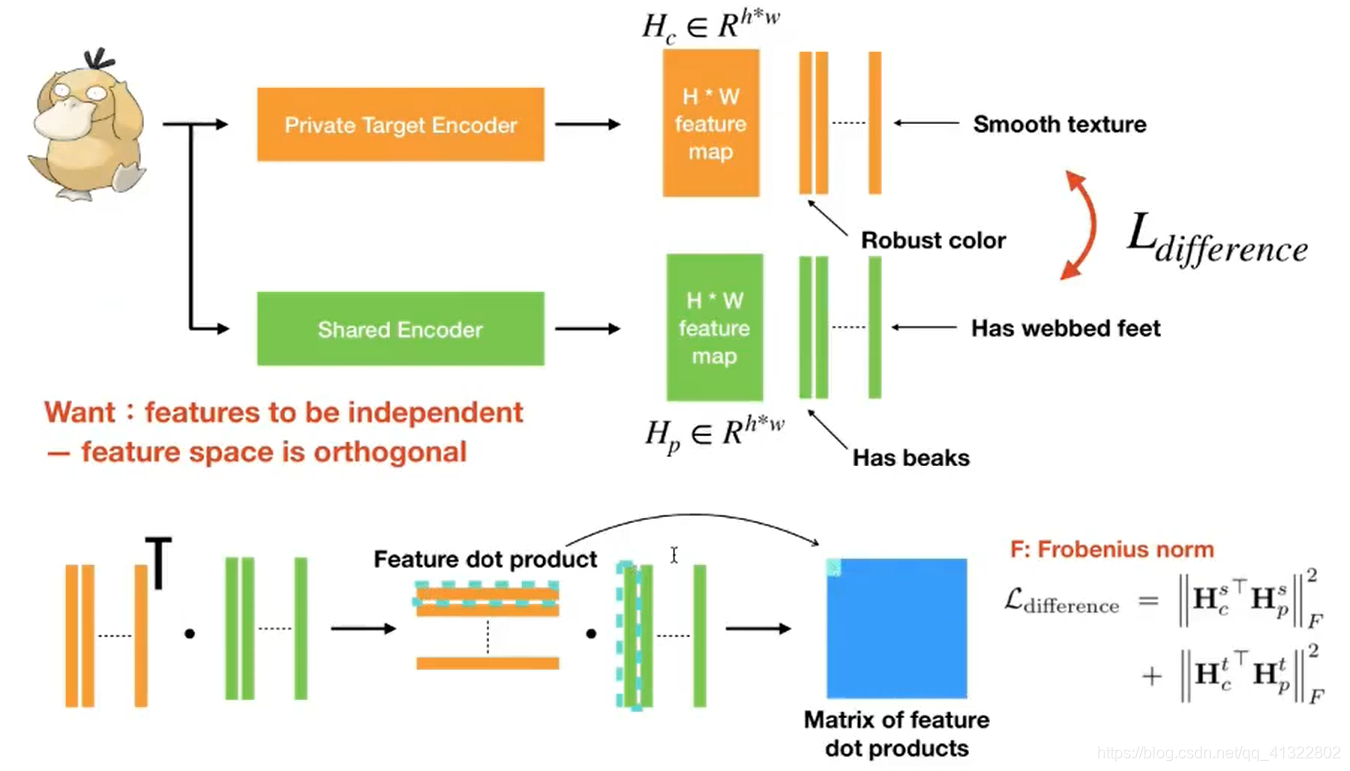
因为我们的目标是分离出特征 所以希望Private Target Encoder 和 Shared Encoder 得出的feature 越不相似越好 所以我们做的就是通过让他们得出的feature 相乘等于0 等于相互独立
Frobenius norm(Frobenius 范数)
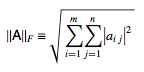
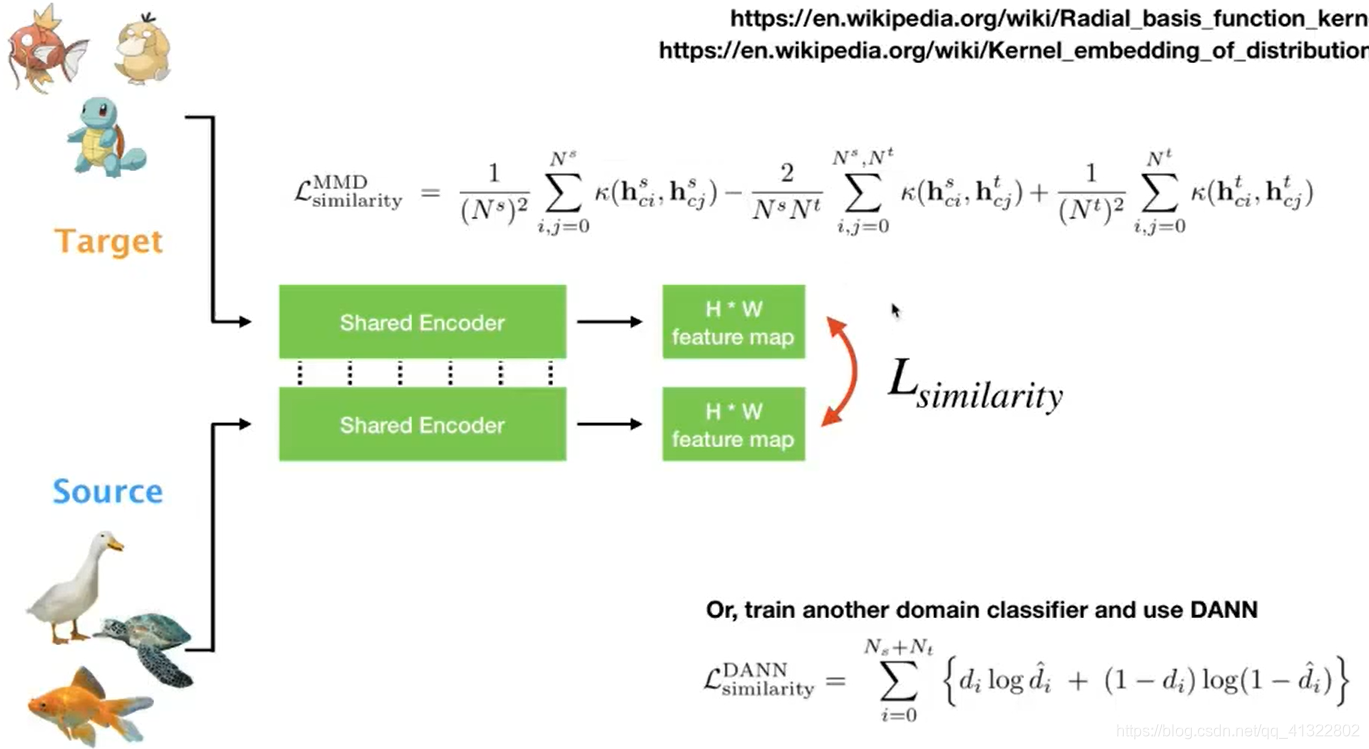
拉近相似度的距离:
L (reconstruction)为了训练出来的不是垃圾 可以重新生成之后和原本的数据非常相似。
Feature Disentanglement:例子:InfoGAN,ACGAN

他和其他gan 不同的地方在于有C(latent) 是可解释的

他的C(class)使得可以生成不同class 的照片