Deeplearning4j 旨在将模型与 Java 应用程序集成,提供了一组组件,用于构建包含 AI 的基于 JVM 的应用程序

Eclipse Deeplearning4j是一个用于 JVM 的开源分布式深度学习库。Deeplearning4j 是用 Java 编写的,与任何 JVM 语言兼容,例如Scala、Clojure 或Kotlin。底层计算是用 C、C++ 和Cuda 编写的。Keras将用作 Python API。Deeplearning4j与 Hadoop 和Apache Spark集成,将 AI 带入业务环境,以在分布式 GPU 和 CPU 上使用。
Deeplearning4j实际上是一堆项目,旨在支持基于 JVM 的深度学习应用程序的所有需求。除了 Deeplearning4j 本身(高级 API),它还包括ND4J(通用线性代数)、SameDiff(基于图的自动微分)、DataVec (ETL)、Arbiter(超参数搜索)和C++ LibND4J(支持所有上述的)。LibND4J 反过来调用标准库来支持 CPU 和 GPU,例如OpenBLAS、OneDNN (MKL-DNN)、cuDNN和cuBLAS。
Eclipse Deeplearning4j 的目标是为构建包含 AI 的应用程序提供一组核心组件。企业内的 AI 产品通常具有比机器学习更广泛的范围。该发行版的总体目标是为构建深度学习应用程序提供智能默认值。
Deeplearning4j 在某种程度上与其他所有深度学习框架竞争。范围内最具可比性的项目是TensorFlow,它是领先的端到端深度学习生产框架。TensorFlow 目前有 Python、C++ 和 Java(实验性)的接口,以及 JavaScript 的单独实现。TensorFlow 使用两种训练方式:基于图和立即模式(eager execution)。Deeplearning4j 目前仅支持基于图的执行。
PyTorch,可能是领先的深度学习研究框架,只支持即时模式;它有 Python、C++ 和 Java 的接口。H2O Sparkling Water 将 H2O 开源分布式内存机器学习平台与 Spark 集成。H2O 具有 Java 和 Scala、Python、R 和 H2O Flow 笔记本的接口。
Deeplearning4j 的商业支持可以从Konduit购买,它也支持许多从事该项目的开发人员。
Deeplearning4j 的工作原理
Deeplearning4j 将加载数据和训练算法的任务视为单独的过程。您使用 DataVec 库加载和转换数据,并使用张量和 ND4J 库训练模型。
您通过RecordReader接口摄取数据,并使用RecordReaderDataSetIterator. 您可以选择一个DataNormalization类作为您的DataSetIterator. 使用ImagePreProcessingScaler图像数据时,NormalizerMinMaxScaler如果沿输入数据的所有尺寸的均匀范围,NormalizerStandardize对于其他大多数情况下。如有必要,您可以实现自定义DataNormalization类。
DataSet对象是数据特征和标签的容器,并将值保存在以下几个实例中INDArray:一个用于示例的特征,一个用于标签,另外两个用于屏蔽(如果您使用的是时间序列数据)。在特征的情况下,INDArray是大小为 的张量Number of Examples x Number of Features。通常,您会将数据分成小批量进行训练;an 中的示例数量INDArray小到足以放入内存,但大到足以获得良好的梯度。
如果您查看用于定义模型的 Deeplearning4j 代码,例如下面的 Java 示例,您会发现它是一个非常高级的 API,类似于 Keras。事实上,Deeplearning4j 的计划 Python 接口将使用 Keras;现在,如果您有 Keras 模型,则可以将其导入 Deeplearning4j。
MultiLayerConfiguration conf =新的NeuralNetConfiguration 。建造者() 。optimizationAlgo (OptimizationAlgorithm 。STOCHASTIC_GRADIENT_DESCENT )。更新程序(新Nesterovs (learningRate ,0.9 ))。列表(新DenseLayer 。生成器()。n在(numInputs )。NOUT (numHiddenNodes )。激活(“RELU” )。
构建(),新的输出层。生成器(LossFunction . NEGATIVELOGLIKELIHOOD )。 激活(“softmax” )。n在(numHiddenNodes )。nOut ( numOutputs )。构建() )。反向传播(真)。构建();
该MultiLayerNetwork班可在Eclipse Deeplearning4j最简单的网络配置的API; 对于 DAG 结构,请ComputationGraph改用 。请注意,优化算法(本例中的 SGD)与更新器(本例中的 Nesterov)是分开指定的。这个非常简单的神经网络有一个带有ReLU激活函数的密集层和一个带有-log(likelihood)损失和softmax激活函数的输出层,并通过反向传播解决。更复杂的网络也可能具有GravesLSTM、ConvolutionLayer、EmbeddingLayer和其他支持的两打层类型和十六层空间类型。
训练模型的最简单方法是.fit()使用您DataSetIterator的参数调用模型配置上的方法。您还可以重置迭代器并根据需要在任意.fit()多个时期内调用该方法,或者使用EarlyStoppingTrainer.
要测试模型性能,请使用一个Evaluation类来查看训练模型与测试数据的拟合程度,这些数据不应与训练数据相同。
Deeplearning4j 提供了一个侦听器工具,可帮助您直观地监控网络的性能,它将在每个小批量处理后调用。最常用的侦听器之一是ScoreIterationListener.
安装和测试 Deeplearning4j
目前,试用 Deeplearning4j 的最简单方法是使用官方快速入门。它需要相对较新的 Java 版本、Maven 的安装、工作的 Git 以及 IntelliJ IDEA(首选)或 Eclipse 的副本。还有一些用户提供的快速入门。首先使用 Git 或 GitHub Desktop 将 eclipse/deeplearning4j-examples 存储库克隆到您自己的机器上。然后从 dl4j-examples 文件夹使用 Maven 安装项目。
martinheller @马丁斯-视网膜-的MacBook dl4j -实例%MVN全新安装
[ INFO ]扫描的项目... [ WARNING ] [ WARNING ]部分中遇到的问题,同时建立有效的模式进行组织。deeplearning4j :dl4j -实例:罐子:1.0 。0 - beta7 [警告]
'build.plugins.plugin.(groupId:artifactId)'必须是唯一的,但发现插件 org 的重复声明。阿帕奇。行家。插件:行家-编译-插件@行250 ,列21
[ WARNING ]
[ WARNING ]这是强烈推荐,因为他们威胁到你构建的稳定性,解决这些问题。[ WARNING ] [ WARNING ]对于这个原因,未来
Maven的版本可能不会再支持建立这种畸形的项目。
[警告]
[信息]
[信息] ------------------<组织。deeplearning4j : dl4j - examples >----------------- [信息] DL4J 1.0 的构建简介。0 - beta7 [ INFO ] --------------------------------[ jar ]--------- ------------------------下载自
中央:https ://repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-enforcer-plugin/1.0.1/maven-enforcer-plugin-1.0.1.pom从中央
下载:https : //repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-enforcer-plugin/1.0.1/maven-enforcer-plugin-1.0.1.pom (6.5 kB at 4.4 kB/s )从中央下载:https : //repo.maven.apache.org/maven2/org/apache/maven/enforcer/enforcer/1.0.1/enforcer-1.0.1.pom从中央下载:https :
//repo.maven.apache.org/maven2/org/apache/maven/enforcer/enforcer/1.0.1/enforcer-1.0.1.pom (11 kB at 137 kB/s)从中央
下载: https : // repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-enforcer-plugin/1.0.1/maven-enforcer-plugin-1.0.1.jar从中央下载:https ://repo.maven .apache.org/maven2/org/apache/maven/plugins/maven-enforcer-plugin/1.0.1/maven-enforcer-plugin-1.0.1.jar (22 kB at 396 kB/s)从中央下载:https : //repo.maven.apache.org/maven2/org/codehaus/mojo/exec-maven-plugin/1.4.0/exec-maven-plugin-1.4.0.pom
从中央下载:https : //repo.maven.apache.org/maven2/org/codehaus/mojo/exec-maven-plugin/1.4.0/exec-maven-plugin-1.4.0.pom (12 kB at 283 kB/s)从中央下载:https : //repo.maven.apache.org/maven2/org/codehaus/mojo/exec-maven-plugin/1.4.0/exec-maven-plugin-1.4.0.jar 已下载来自中央:https ://repo.maven.apache.org/maven2/org/codehaus/mojo/exec-maven-plugin/1.4.0/exec-maven-plugin-1.4.0.jar(46 kB at 924 kB /s)从中央下载:https :
//repo.maven.apache.org/maven2/com/lewisd/lint-maven-plugin/0.0.11/lint-maven-plugin-0.0.11.pom从中央
下载:https ://repo.maven.apache .org/maven2/com/lewisd/lint-maven-plugin/0.0.11/lint-maven-plugin-0.0.11.pom(19 kB at 430 kB/s)从中央下载:https ://repo.maven .apache.org/maven2/com/lewisd/lint-maven-plugin/0.0.11/lint-maven-plugin-0.0.11.jar从中央下载:https ://repo.maven.apache.org/maven2/ com/lewisd/lint-maven-plugin/0.0.11/lint-maven-plugin-0.0.11.jar (106 kB at 1.6 MB/s)从中央下载
: https : //repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-compiler-plugin/3.5.1/maven-compiler-plugin-3.5.1.pom
...
[警告] - org . agrona 。收藏品。散列[警告] - org 。agrona 。收藏品。Long2ObjectCache$ValueIterator [警告] -组织。agrona 。收藏品。Int2ObjectHashMap$EntrySet [警告] -
组织。agrona 。并发。SleepingIdleStrategy
[警告] - org 。agrona 。收藏品。MutableInteger [警告] - org 。agrona 。收藏品。Int2IntHashMap [警告] - org 。agrona 。收藏品。IntIntConsumer 【警告】-组织。agrona 。同时
. 状态。StatusIndicator
[警告] - 175更多... [警告] javafx - base - 14 - mac 。jar 、javafx - graphics - 14 - mac 。罐子,雅加达。XML 。绑定- API - 2.3 。2.jar定义1 个重叠类:[警告]
-模块-信息[ WARNING ]的protobuf - 1.0 。0 - β7的。罐子,番石榴- 19.0 。罐限定3重叠的类:[ WARNING ] - COM 。谷歌。第三方。公共后缀。TrieParser [警告] - com 。谷歌。第三方。公共后缀。
PublicSuffixPatterns
[警告] - com 。谷歌。第三方。公共后缀。PublicSuffixType [ WARNING ] JSR305 - 3.0 。2.jar ,番石榴- 1.0 。0 - β7的。罐限定35重叠的类:[ WARNING ] -的javax 。注释。正则表达式[警告] - javax
. 注释。并发。不可变
[警告] - javax 。注释。元。TypeQualifierDefault [警告] - javax 。注释。元。TypeQualifier [警告] - javax 。注释。语法[警告] - javax 。注释。检查返回值[警告]
- javax 。注释。CheckForNull
[警告] - javax 。注释。非空[警告] - javax 。注释。元。TypeQualifierNickname [警告] - javax 。注释。MatchesPattern [警告] - 还有25个...... [警告] maven -阴影-
插件检测到某些类文件
[警告]存在于两个或多个JAR 中。当这种情况发生,只有一个[ WARNING ]单一的版本类被复制到超级罐子。【警告】通常这是不是有害的,并可以跳过这些警告,[警告] ,否则试图基于手动排除假象
[警告] mvn 依赖项:tree - Ddetail = true和上面的输出。[警告]参见HTTP ://maven.apache.org/plugins/maven-shade-plugin/ [ INFO ] 。附接阴影伪影。[ INFO ] [ INFO ] --- Maven的-安装-插件:2.4 :安装(默认-安装) @
dl4j -实例--- [ INFO ]安装/体积/数据/回购/ deeplearning4j -实例/ dl4j -实例/目标/ dl4j -实例- 1.0 。0 - β7的。jar 到/ Users / martinheller /。m2 /存储库/组织/ deeplearning4j / dl4j -
实例/ 1.0 。0 -联蛋白β7 / dl4j -实例- 1.0 。0 - β7的。jar
[信息]安装/卷/数据/ repos / deeplearning4j - examples / dl4j - examples / pom 。xml 到/ Users / martinheller /。m2 /存储库/组织/ deeplearning4j / dl4j -示例/ 1.0 . 0 -联蛋白β7 / dl4j -实例- 1.0 。0 - β7的。POM
[ INFO ]安装/体积/数据/回购/ deeplearning4j -实例/ dl4j -实例/目标/ dl4j -实例- 1.0 。0 - beta7 -阴影。jar 到/ Users / martinheller /。m2 / repository / org / deeplearning4j / dl4j - examples / 1.0 。0 -联蛋白β7 / dl4j -实例- 1.0 。0 - β7的-阴影。jar
[信息] ---------------------------------------------- -------------------------- [信息]
构建成功
[信息] --------------------------------------------- --------------------------- [ INFO ]总时间: 05 : 07 min [ INFO ]完成时间: 2020 - 07 - 10T10 : 58 : 55 - 04 : 00 [信息] ----------------------------------------- ------------------------------- martinheller@Martins - Retina - MacBook dl4j
-例子%
安装完成后,使用 IntelliJ IDEA 打开 dl4j-examples/ 目录并尝试运行一些示例。
dl4j-examples 下的 README 列出了所有示例并对其进行了简要说明。顺便说一句,您可以使用 IntelliJ IDEA 首选项安装新版本的 JDK 并将其应用于项目。
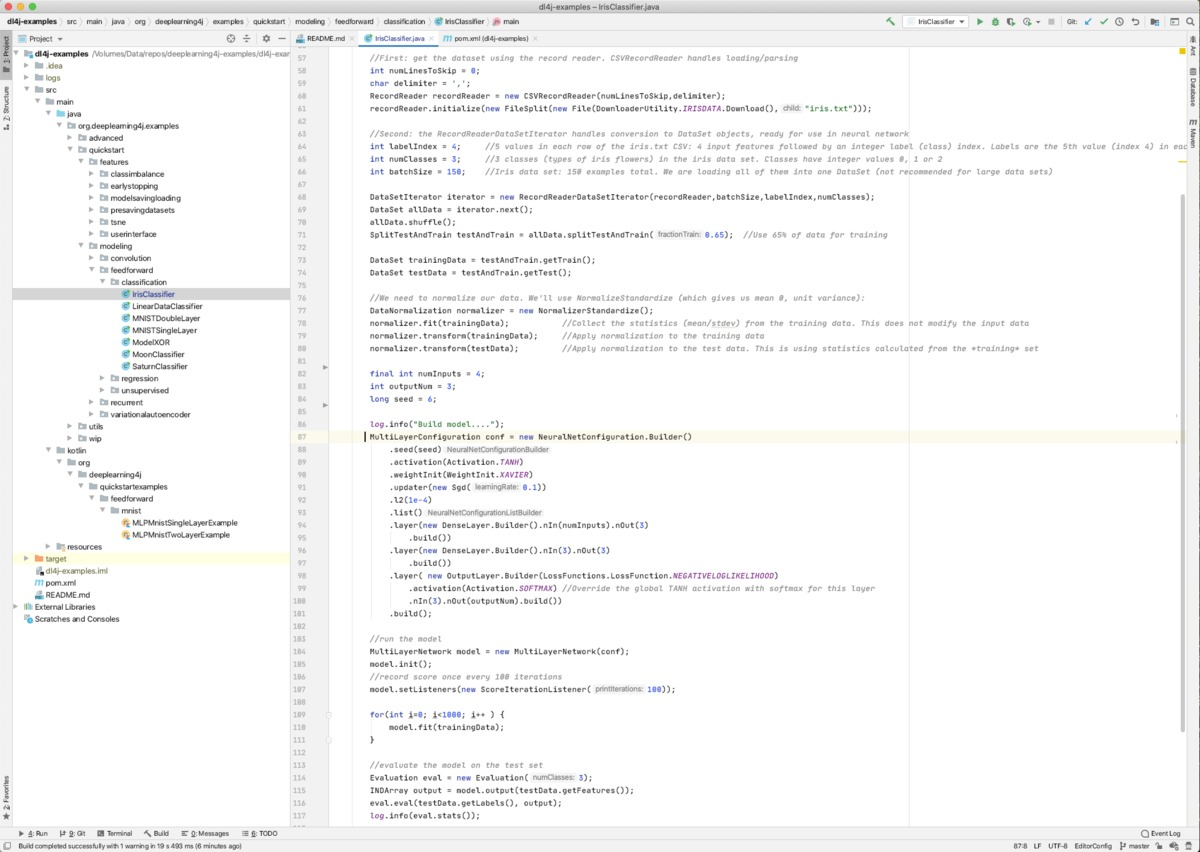
著名的鸢尾花数据集只有 150 个样本,通常很容易建模,尽管其中一些鸢尾花经常被错误分类。这里使用的模型是三层密集神经网络。
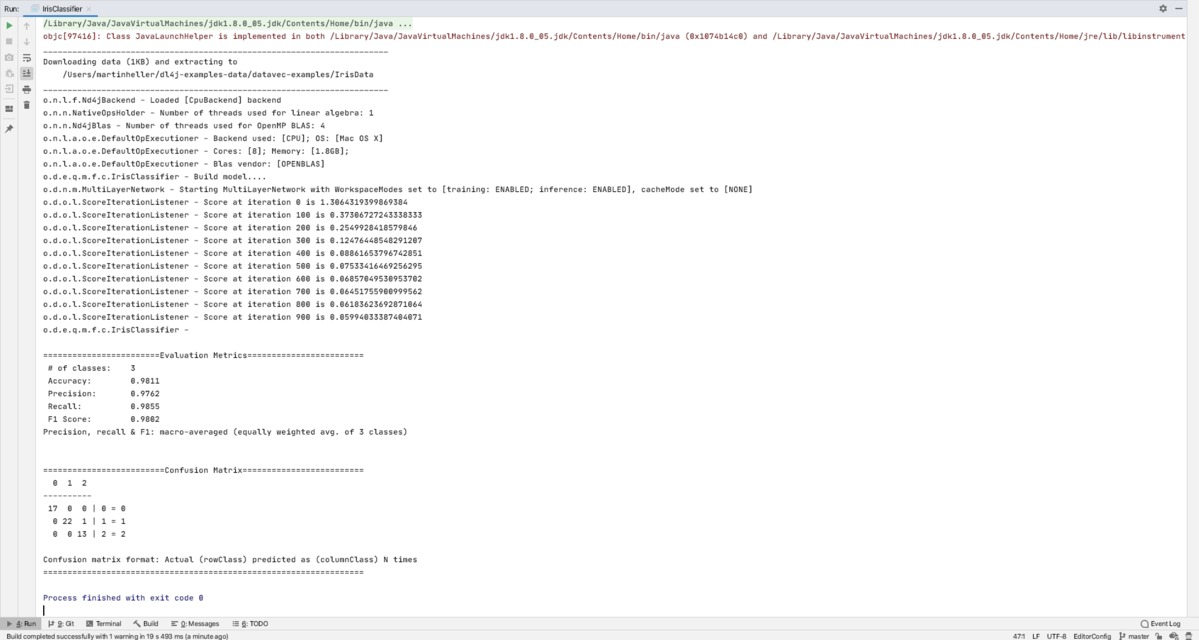
运行上图所示的 Iris 分类器会产生相当好的拟合:准确率、精确度、召回率和 F1 分数都约为 98%。请注意,在混淆矩阵中,只有一个测试用例被错误分类。
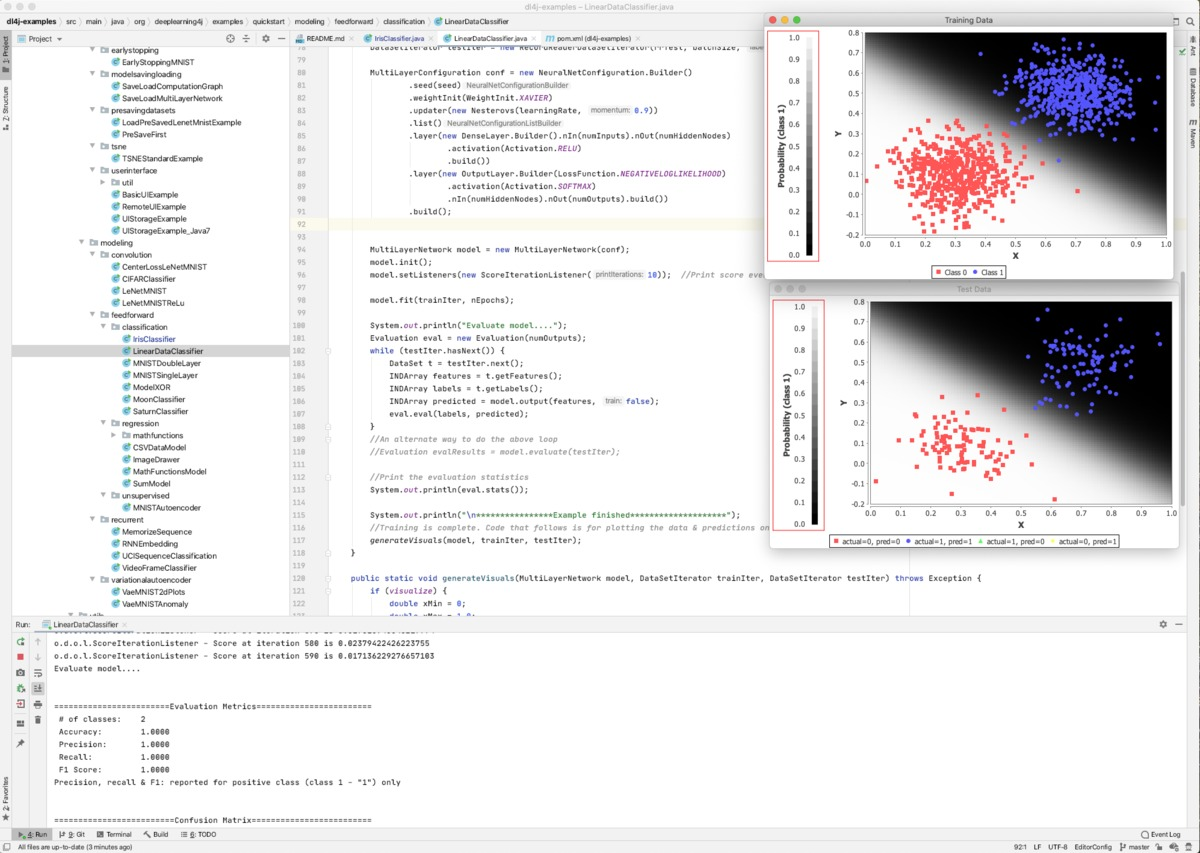
线性分类器演示在几秒钟内运行,并为训练和测试数据集生成概率图。数据是专门为线性可分为两类而生成的。
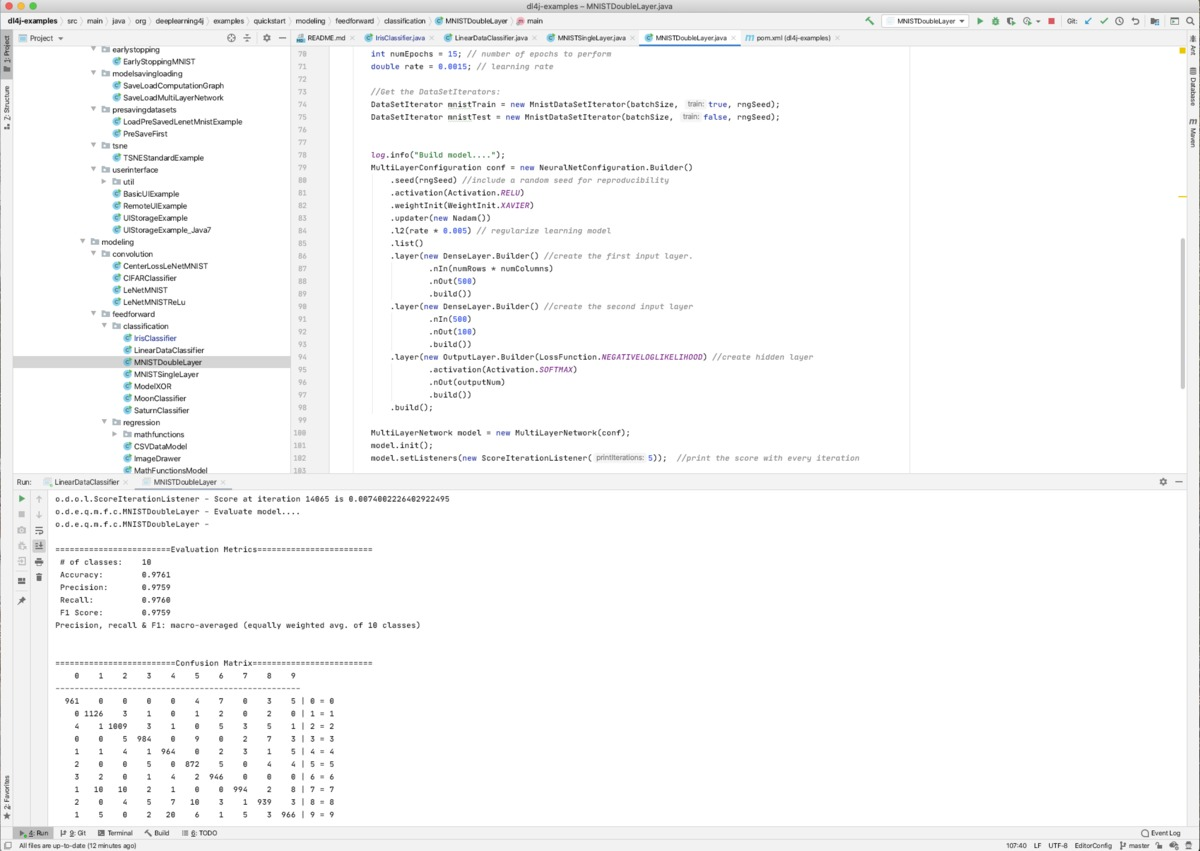
MNIST 手写数字数据集的多层感知器 (MLP) 分类模型在大约 14K 次迭代后产生了约 97% 的准确度、精确度、召回率和 F1 分数。这不如卷积神经网络(如 LeNet)在该数据集上的结果好或快。
Deeplearning4j 性能
对 Java 程序进行基准测试可能很棘手。特别是,您需要在对代码进行计时之前对其进行预热以消除 JIT 编译器的开销,并且您需要确保 JVM 具有足够的 RAM 配置用于进行基准测试的程序。Deeplearning4j 社区为各种流行的模型和配置维护了一个基准代码存储库。
据开发人员称,Deeplearning4j 在使用多个 GPU 的非平凡图像识别任务中与 Caffe 一样快。要使用多台机器,您可以使用 Spark 运行 Deeplearning4j
Java 应用程序的深度学习
总的来说,Deeplearning4j 是一个很有价值的库,用于加载和调节数据以及在 Java VM 上执行深度学习。虽然尚未像 TensorFlow 或 PyTorch 那样成熟,但 Deeplearning4j 将吸引希望将深度学习模型集成到基于 Java 的应用程序中的数据科学家。Deeplearning4j 能够导入 Keras 模型,这将简化想要从 TensorFlow 转换的人的过渡。
Deeplearning4j 支持创建图形然后运行它们,就像TensorFlow 1 一样。它不支持即时模式训练,如 TensorFlow 2 和 PyTorch。这对生产来说并不重要,但它可能会使使用 Deeplearning4j 对研究的吸引力降低。
超硬核!贯穿一生的知识点总结,你要的我都有
Deeplearning4j 目前有两种分布式训练机制,参数平均和梯度共享。后者更可取,但它仅在版本 1.0.0-beta3 中添加到库中。Deeplearning4j 还与 Spark 集成,这有助于支持在一组机器上进行训练。在具有多个 GPU 的单个服务器上进行训练时,使用 Spark 并没有真正的帮助。