? ? ? ?到目前为止,我们的建模工作仅限于单个时间序列。 RNN 自然非常适合多变量时间序列,并且也是我们在时间序列模型中介绍的向量自回归 (VAR) 模型的非线性替代方案。
导入各类包
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from pathlib import Path
import numpy as np
import pandas as pd
import pandas_datareader.data as web
from sklearn.metrics import mean_absolute_error
from sklearn.preprocessing import minmax_scale
import tensorflow as tf
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, LSTM
import tensorflow.keras.backend as K
import matplotlib.pyplot as plt
import seaborn as sns
gpu_devices = tf.config.experimental.list_physical_devices('GPU')
if gpu_devices:
print('Using GPU')
tf.config.experimental.set_memory_growth(gpu_devices[0], True)
else:
print('Using CPU')
sns.set_style('whitegrid')
np.random.seed(42)
results_path = Path('results', 'multivariate_time_series')
if not results_path.exists():
results_path.mkdir(parents=True)加载数据
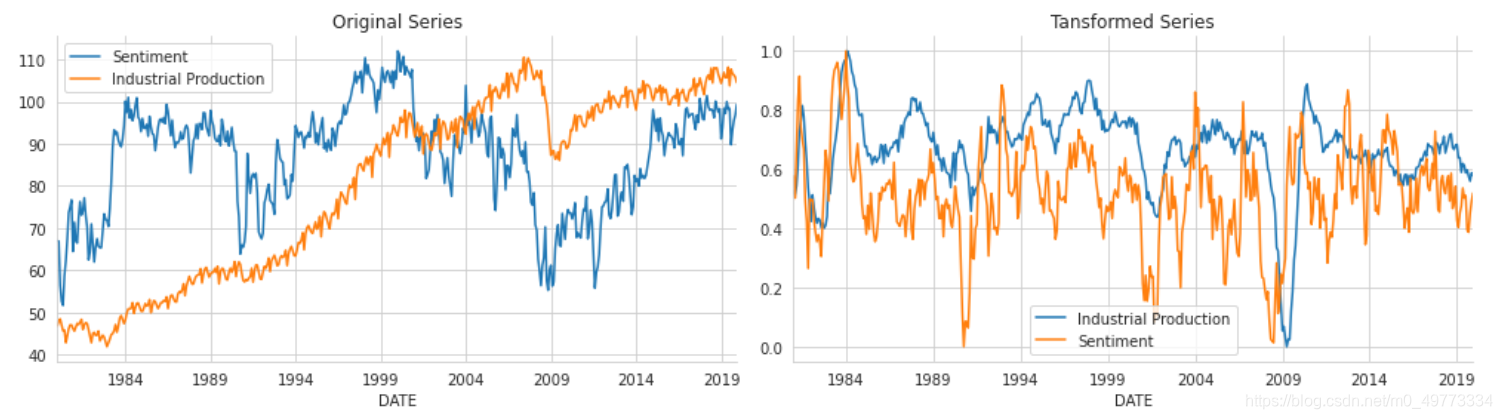
? ? ? ?为了进行比较,使用我们用于 VAR 示例的相同数据集、消费者情绪的月度数据以及来自美联储 FRED 服务的工业生产。
df = web.DataReader(['UMCSENT', 'IPGMFN'], 'fred', '1980', '2019-12').dropna()
df.columns = ['sentiment', 'ip']#两列分别是sentiment和ip
df.info()
df.head()#导出第8章的数据。
准备数据
?平稳性:我们使用先验对数变换来实现我们在第 8 章时间序列模型中使用的平稳性要求:
df_transformed = (pd.DataFrame({'ip': np.log(df.ip).diff(12),#对数变换
'sentiment': df.sentiment.diff(12)})
.dropna())#删除缺失值缩放:然后我们将转换后的数据缩放到 [0,1] 区间:
df_transformed = df_transformed.apply(minmax_scale)绘制原始序列和转换后序列的图
fig, axes = plt.subplots(ncols=2, figsize=(14,4))
columns={'ip': 'Industrial Production', 'sentiment': 'Sentiment'}
df.rename(columns=columns).plot(ax=axes[0], title='Original Series')
df_transformed.rename(columns=columns).plot(ax=axes[1], title='Tansformed Series')
sns.despine()
fig.tight_layout()
fig.savefig(results_path / 'multi_rnn', dpi=300)原始数据序列和转换后数据序列如下图:
?将数据重塑为 RNN 格式
? ? ? ? ?我们可以直接重塑以获得不重叠的序列,即把每年的数据作为一个样本(仅当样本数可被窗口大小整除时才有效):
df.values.reshape(-1, 12, 2).shape#reshape在这里指的是可以直接转化成两列? ? ? ?但是,我们想要动态而不是非重叠的滞后值。 create_multivariate_rnn_data 函数将多个时间序列的数据集转换为 Keras RNN 层所需的大小,即 n_samples x window_size x n_series。
def create_multivariate_rnn_data(data, window_size):
y = data[window_size:]
n = data.shape[0]
X = np.stack([data[i: j]
for i, j in enumerate(range(window_size, n))], axis=0)
return X, y? ? ? ? 我们将使用 24 个月的 window_size 并为我们的 RNN 模型获取所需的输入。
window_size = 18
X, y = create_multivariate_rnn_data(df_transformed, window_size=window_size)
X.shape, y.shape#x,y都是经过RNN转化后的数据。输出x,y的大小
((450, 18, 2), (450, 2))
? ? ? ?最后,我们将数据拆分为一个训练集和一个测试集,使用过去 24 个月来进行交叉验证。
test_size =24#24个月
train_size = X.shape[0]-test_size
X_train, y_train = X[:train_size], y[:train_size]
X_test, y_test = X[train_size:], y[train_size:]#跟之前一样切分训练集和测试集。
X_train.shape, X_test.shape#输出训练集和测试集的大小。((426, 18, 2), (24, 18, 2))
?定义模型架构
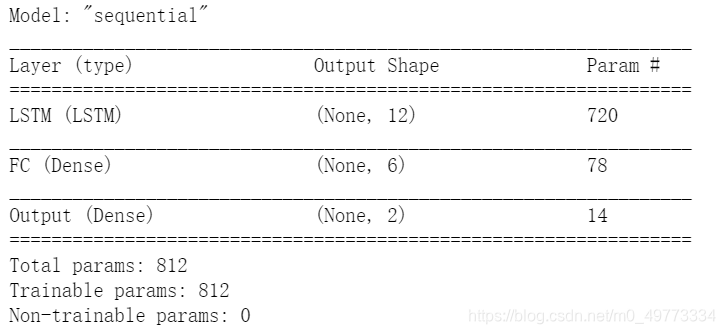
? ? ? ? 我们同样使用堆叠的LSTM,其中两个堆叠的 LSTM 层分别具有 12 和 6 个单元,然后是一个具有 10 个单元的全连接层。 输出层有两个单元,每个时间序列一个。 我们使用平均绝对损失和推荐的 RMSProp 优化器编译它们。
K.clear_session()
n_features = output_size = 2
lstm_units = 12
dense_units = 6
rnn = Sequential([
LSTM(units=lstm_units,
dropout=.1,
recurrent_dropout=.1,
input_shape=(window_size, n_features), name='LSTM',
return_sequences=False),
Dense(dense_units, name='FC'),
Dense(output_size, name='Output')
])
rnn.summary()该模型有 1,268 个参数。
rnn.compile(loss='mae', optimizer='RMSProp')
#用RMSProp进行优化,RMSProp主要是AdaGrad的一种改进,用于加快梯度下降速度。MAE即平均绝对误差用于作为损失函数。训练模型
? ? ? ?其中我们训练了?100?个epoch,其中batch_size 值为 20:
lstm_path = (results_path / 'lstm.h5').as_posix()#as_posix()只是一个判断路径的函数。
checkpointer = ModelCheckpoint(filepath=lstm_path,
verbose=1,
monitor='val_loss',
mode='min',
save_best_only=True)
early_stopping = EarlyStopping(monitor='val_loss',
patience=10,
restore_best_weights=True)
result = rnn.fit(X_train,
y_train,
epochs=100,
batch_size=20,
shuffle=False,
validation_data=(X_test, y_test),
callbacks=[early_stopping, checkpointer],
verbose=1)Epoch 1/100 19/22 [========================>.....] - ETA: 0s - loss: 0.2743 Epoch 00001: val_loss improved from inf to 0.04285, saving model to results/multivariate_time_series/lstm.h5 22/22 [==============================] - 1s 25ms/step - loss: 0.2536 - val_loss: 0.0429 Epoch 2/100 20/22 [==========================>...] - ETA: 0s - loss: 0.1013 Epoch 00002: val_loss improved from 0.04285 to 0.03912, saving model to results/multivariate_time_series/lstm.h5 22/22 [==============================] - 0s 13ms/step - loss: 0.0991 - val_loss: 0.0391 Epoch 3/100 20/22 [==========================>...] - ETA: 0s - loss: 0.0956 Epoch 00003: val_loss did not improve from 0.03912 22/22 [==============================] - 0s 12ms/step - loss: 0.0941 - val_loss: 0.0404 Epoch 4/100 19/22 [========================>.....] - ETA: 0s - loss: 0.0965 Epoch 00004: val_loss improved from 0.03912 to 0.03764, saving model to results/multivariate_time_series/lstm.h5 22/22 [==============================] - 0s 14ms/step - loss: 0.0945 - val_loss: 0.0376 Epoch 5/100 18/22 [=======================>......] - ETA: 0s - loss: 0.0910 Epoch 00005: val_loss did not improve from 0.03764 22/22 [==============================] - 0s 12ms/step - loss: 0.0918 - val_loss: 0.0504 Epoch 6/100 21/22 [===========================>..] - ETA: 0s - loss: 0.0903 Epoch 00006: val_loss improved from 0.03764 to 0.03714, saving model to results/multivariate_time_series/lstm.h5 22/22 [==============================] - 0s 13ms/step - loss: 0.0898 - val_loss: 0.0371 Epoch 7/100 20/22 [==========================>...] - ETA: 0s - loss: 0.0898 Epoch 00007: val_loss did not improve from 0.03714 22/22 [==============================] - 0s 12ms/step - loss: 0.0885 - val_loss: 0.0376 Epoch 8/100 19/22 [========================>.....] - ETA: 0s - loss: 0.0908 Epoch 00008: val_loss did not improve from 0.03714 22/22 [==============================] - 0s 13ms/step - loss: 0.0884 - val_loss: 0.0491 Epoch 9/100 19/22 [========================>.....] - ETA: 0s - loss: 0.0899 Epoch 00009: val_loss did not improve from 0.03714 22/22 [==============================] - 0s 12ms/step - loss: 0.0876 - val_loss: 0.0418 Epoch 10/100 19/22 [========================>.....] - ETA: 0s - loss: 0.0906 Epoch 00010: val_loss improved from 0.03714 to 0.03557, saving model to results/multivariate_time_series/lstm.h5 22/22 [==============================] - 0s 13ms/step - loss: 0.0892 - val_loss: 0.0356 Epoch 11/100 19/22 [========================>.....] - ETA: 0s - loss: 0.0916 Epoch 00011: val_loss did not improve from 0.03557 22/22 [==============================] - 0s 13ms/step - loss: 0.0894 - val_loss: 0.0463 Epoch 12/100 18/22 [=======================>......] - ETA: 0s - loss: 0.0883 Epoch 00012: val_loss did not improve from 0.03557 22/22 [==============================] - 0s 13ms/step - loss: 0.0877 - val_loss: 0.0389 Epoch 13/100 18/22 [=======================>......] - ETA: 0s - loss: 0.0882 Epoch 00013: val_loss did not improve from 0.03557 22/22 [==============================] - 0s 13ms/step - loss: 0.0873 - val_loss: 0.0451 Epoch 14/100 18/22 [=======================>......] - ETA: 0s - loss: 0.0879 Epoch 00014: val_loss improved from 0.03557 to 0.03552, saving model to results/multivariate_time_series/lstm.h5 22/22 [==============================] - 0s 14ms/step - loss: 0.0867 - val_loss: 0.0355 Epoch 15/100 20/22 [==========================>...] - ETA: 0s - loss: 0.0854 Epoch 00015: val_loss improved from 0.03552 to 0.03534, saving model to results/multivariate_time_series/lstm.h5 22/22 [==============================] - 0s 12ms/step - loss: 0.0837 - val_loss: 0.0353 Epoch 16/100 19/22 [========================>.....] - ETA: 0s - loss: 0.0864 Epoch 00016: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 13ms/step - loss: 0.0841 - val_loss: 0.0412 Epoch 17/100 22/22 [==============================] - ETA: 0s - loss: 0.0837 Epoch 00017: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 14ms/step - loss: 0.0837 - val_loss: 0.0356 Epoch 18/100 20/22 [==========================>...] - ETA: 0s - loss: 0.0859 Epoch 00018: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 15ms/step - loss: 0.0845 - val_loss: 0.0357 Epoch 19/100 20/22 [==========================>...] - ETA: 0s - loss: 0.0845 Epoch 00019: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 14ms/step - loss: 0.0832 - val_loss: 0.0376 Epoch 20/100 20/22 [==========================>...] - ETA: 0s - loss: 0.0837 Epoch 00020: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 13ms/step - loss: 0.0824 - val_loss: 0.0357 Epoch 21/100 18/22 [=======================>......] - ETA: 0s - loss: 0.0839 Epoch 00021: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 14ms/step - loss: 0.0825 - val_loss: 0.0379 Epoch 22/100 21/22 [===========================>..] - ETA: 0s - loss: 0.0827 Epoch 00022: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 14ms/step - loss: 0.0822 - val_loss: 0.0359 Epoch 23/100 22/22 [==============================] - ETA: 0s - loss: 0.0818 Epoch 00023: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 13ms/step - loss: 0.0818 - val_loss: 0.0375 Epoch 24/100 21/22 [===========================>..] - ETA: 0s - loss: 0.0823 Epoch 00024: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 15ms/step - loss: 0.0820 - val_loss: 0.0359 Epoch 25/100 18/22 [=======================>......] - ETA: 0s - loss: 0.0823 Epoch 00025: val_loss did not improve from 0.03534 22/22 [==============================] - 0s 13ms/step - loss: 0.0810 - val_loss: 0.0471
评估结果
? ? ? ?训练在 22 个 epoch 后提前停止,测试集MAE的值为1.71,在VAR模型中测试集的MAE值为1.91,所以RNN更有优势。然而,这两个结果并不完全具有可比性,因为 RNN 模型产生 24 个先验预测,而 VAR 模型使用自己的预测作为其样本外预测的输入。 我们需要调整 VAR 设置以获得可比较的预测并比较它们的性能:
pd.DataFrame(result.history).plot();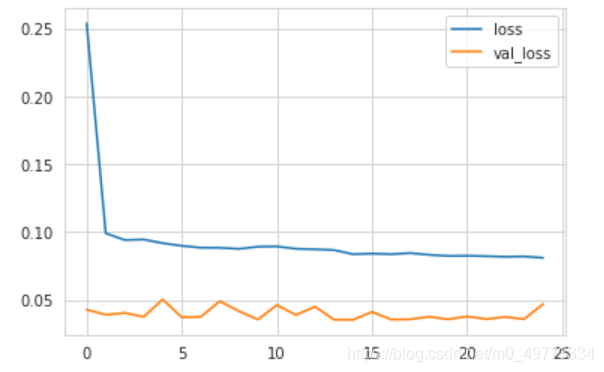 ?
?
test_mae = mean_absolute_error(y_pred, y_test)
print(test_mae)#输出测试集的MAE
输出测试集的MAE: 0.03533523602534612
y_test.index#输出y值?
#绘制交叉验证测试集与验证集的比较图。
fig, axes = plt.subplots(ncols=3, figsize=(17, 4))
pd.DataFrame(result.history).rename(columns={'loss': 'Training',
'val_loss': 'Validation'}).plot(ax=axes[0], title='Train & Validiation Error')
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('MAE')
col_dict = {'ip': 'Industrial Production', 'sentiment': 'Sentiment'}
for i, col in enumerate(y_test.columns, 1):
y_train.loc['2010':, col].plot(ax=axes[i], label='training', title=col_dict[col])
y_test[col].plot(ax=axes[i], label='out-of-sample')
y_pred[col].plot(ax=axes[i], label='prediction')
axes[i].set_xlabel('')
axes[1].set_ylim(.5, .9)
axes[1].fill_between(x=y_test.index, y1=0.5, y2=0.9, color='grey', alpha=.5)
axes[2].set_ylim(.3, .9)
axes[2].fill_between(x=y_test.index, y1=0.3, y2=0.9, color='grey', alpha=.5)
plt.legend()
fig.suptitle('Multivariate RNN - Results | Test MAE = {:.4f}'.format(test_mae), fontsize=14)
sns.despine()
fig.tight_layout()
fig.subplots_adjust(top=.85)
fig.savefig(results_path / 'multivariate_results', dpi=300);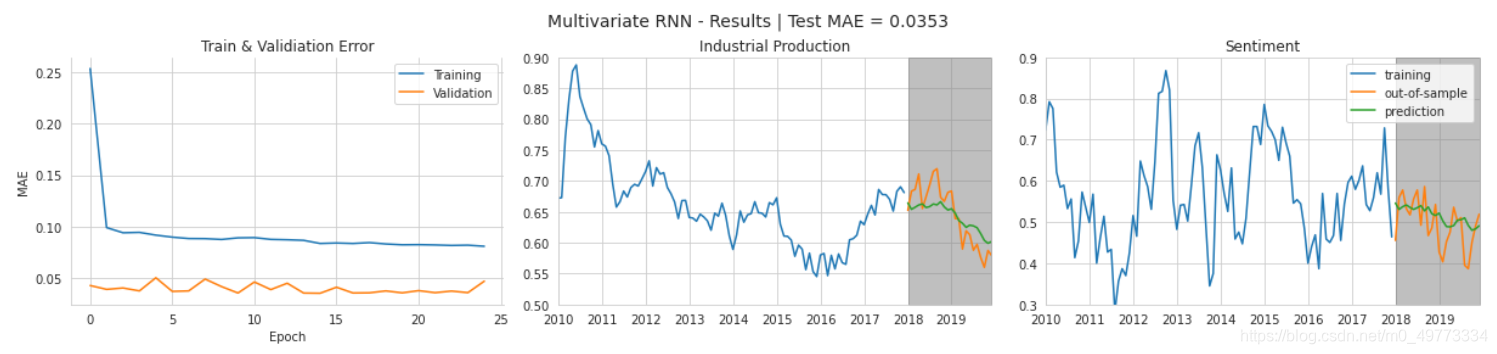
? ? ? ?样本外数据的波动明显大于预测值,但整体走势保持一致。