БОЮФЪЧжаЮФаХЯЂДІРэПЮГЬЕФЦкФЉПМКЫДѓзївЕ,ЖдгкздШЛгябдДІРэжїСїШЮЮёЕФЕїбаБЈИц
ЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊ
АцШЈЩљУї:БОЮФЮЊCSDNВЉжїЁИ<Running Snail>ЁЙЕФдДДЮФеТ,зёбCC 4.0 BY-SAАцШЈавщ,зЊдиЧыИНЩЯдЮФГіДІСДНгМАБОЩљУїЁЃ
дЮФСДНг:https://blog.csdn.net/weixin_45884316/article/details/118684681
еЊвЊ
УќУћЪЕЬхЪЖБ№ЪЧздШЛгябдДІРэжаЕФШШЕубаОПЗНЯђжЎвЛ, ФПЕФЪЧЪЖБ№ЮФБОжаЕФУќУћЪЕЬхВЂНЋЦфЙщФЩЕНЯргІЕФЪЕЬхРраЭжаЁЃЪзЯШВћЪіСЫУќУћЪЕЬхЪЖБ№ШЮЮёЕФЖЈвхЁЂФПБъКЭвтвх; ШЛКѓНщЩмСЫУќУћЪЕЬхЪЖБ№баОПЕФЗЂеЙНјГЬ,ДгзюГѕЕФЙцдђКЭзжЕфЗНЗЈЕНДЋЭГЕФЭГМЦбЇЯАЗНЗЈдйЕНЯждкЕФЩюЖШбЇЯАЗНЗЈ,ВЛЖЯЕиНЋаТММЪѕгІгУЕНУќУћЪЕЬхЪЖБ№баОПжавдЬсИпадФм; зюКѓеыЖдЦРХаУќУћЪЕЬхЪЖБ№ФЃаЭЕФКУЛЕ,змНсСЫГЃгУЕФШєИЩЪ§ОнМЏКЭГЃгУЙЄОп,ВЂИјГіСЫЮДРДЕФбаОПНЈвщ ЁЃ
1. в§бд
?УќУћЪЕЬхЪЖБ№етИіЪѕгяЪзДЮГіЯждкMUC-6(Message Understanding Conferences),етИіЛсвщЙизЂЕФжївЊЮЪЬтЪЧаХЯЂГщШЁ(Information Extraction),ЕкСљНьMUCГ§СЫаХЯЂГщШЁЦРВтШЮЮёЛЙПЊЩшСЫаТЦРВтШЮЮёМДУќУћЪЕЬхЪЖБ№ШЮЮёЁЃГ§ДЫжЎЭт,ЦфЫћЯрЙиЕФЦРВтЛсвщАќРЈCoNLL(Conference on Computational Natural Language Learning)ЁЂACE(Automatic Content Extraction)КЭIEER(Information Extraction-Entity Recognition Evaluation)ЕШЁЃдкMUC-6жЎЧА,ДѓМвжївЊЪЧЙизЂШЫУћЁЂЕиУћКЭзщжЏЛњЙЙУћетШ§РрзЈвЕУћДЪЕФЪЖБ№ЁЃздMUC-6Ц№,КѓУцгаКмЖрбаОПЖдРрБ№НјааСЫИќЯИжТЕФЛЎЗж,БШШчЕиУћБЛНјвЛВНЯИЛЏЮЊГЧЪаЁЂжнКЭЙњМв,вВгаШЫНЋШЫУћНјвЛВНЯИЗжЮЊеўжЮМвЁЂвеШЫЕШаЁРрЁЃ
? ДЫЭт,вЛаЉЦРВтЛЙРЉДѓСЫзЈвЕУћДЪЕФЗЖЮЇ,БШШчCoNLLФГФъзщжЏЕФЦРВтжаАќКЌСЫВњЦЗУћЕФЪЖБ№ЁЃвЛаЉбаОПвВЩцМАЕчгАУћЁЂЪщУћЁЂЯюФПУћЁЂбаОПСьгђУћГЦЁЂЕчзггЪМўЕижЗЁЂЕчЛАКХТывдМАЩњЮяаХЯЂбЇСьгђЕФзЈгаУћДЪ(ШчЕААзжЪЁЂDNAЁЂRNAЕШ)ЁЃЩѕжСгавЛаЉЙЄзїВЛЯоЖЈЁАЪЕЬхЁБЕФРраЭ,ЖјЪЧНЋЦфЕБзіПЊЗХгђЕФУќУћЪЕЬхЪЖБ№КЭЗжРрЁЃ
2. баОПБГОА
? УќУћЪЕЬхЪЖБ№(Named Entity Recognition, NER)ЪЧNLPжавЛЯюЗЧГЃЛљДЁЕФШЮЮё,ЪЧаХЯЂЬсШЁЁЂЮЪД№ЯЕЭГЁЂОфЗЈЗжЮіЁЂЛњЦїЗвыЕШжкЖрNLPШЮЮёЕФживЊЛљДЁЙЄОпЁЃУќУћЪЕЬхвЛАужИЕФЪЧЮФБОжаОпгаЬиЖЈвтвхЛђепжИДњадЧПЕФЪЕЬх,бЇЪѕЩЯЭЈГЃАќРЈЪЕЬхРр,ЪБМфРр,Ъ§зжРрШ§ДѓРрКЭШЫУћЁЂЕиУћЁЂзщжЏЛњЙЙУћЁЂЪБМфЁЂШеЦкЁЂЛѕБвЁЂАйЗжБШЦпаЁРрЁЃNERОЭЪЧДгЗЧНсЙЙЛЏЕФЪфШыЮФБОжаГщШЁГіЩЯЪіЪЕЬх,ВЂЧвПЩвдАДеевЕЮёашЧѓЪЖБ№ГіИќЖрРрБ№ЕФЪЕЬхЁЃ
? NERЪЧвЛИіОпгаЬєеНадЕФбЇЯАЮЪЬт,дкДѓЖрЪ§гябдКЭСьгђжа,жЛгаКмЩйСПЕФбЕСЗЪ§ОнПЩгУ,ЭЌЪБЖдгкПЩвдзїЮЊУћГЦЕФЕЅДЪжжРрМИКѕУЛгаЯожЦ,вђДЫКмФбДгетжжаЁЕФЪ§ОнбљБОжаНјааИХРЈЁЃЦфЗЂеЙДгдчЦкЛљгкДЪЕфКЭЙцдђЕФЗНЗЈ,ЕНДЋЭГЛњЦїбЇЯАЕФЗНЗЈ,ЕННќФъРДЛљгкЩюЖШбЇЯАЕФЗНЗЈЁЃ
? NERЪЧNLPжавЛЯюЛљДЁадЙиМќШЮЮёЁЃДгздШЛгябдДІРэЕФСїГЬРДПД,NERПЩвдПДзїДЪЗЈЗжЮіжаЮДЕЧТМДЪЪЖБ№ЕФвЛжж,ЪЧЮДЕЧТМДЪжаЪ§СПзюЖрЁЂЪЖБ№ФбЖШзюДѓЁЂЖдЗжДЪаЇЙћгАЯьзюДѓЮЪЬтЁЃЭЌЪБNERвВЪЧЙиЯЕГщШЁЁЂЪТМўГщШЁЁЂжЊЪЖЭМЦзЁЂЛњЦїЗвыЁЂЮЪД№ЯЕЭГЕШжюЖрNLPШЮЮёЕФЛљДЁЁЃ
3. жївЊЗНЗЈ
УќУћЪЕЬхЪЖБ№ДгдчЦкЛљгкДЪЕфКЭЙцдђЕФЗНЗЈ,ЕНДЋЭГЛњЦїбЇЯАЕФЗНЗЈ, КѓРДВЩгУЛљгкЩюЖШбЇЯАЕФЗНЗЈ,вЛжБЕНЕБЯТШШУХЕФзЂвтСІЛњжЦЁЂЭМЩёОЭјТчЕШбаОПЗНЗЈ, УќУћЪЕЬхЪЖБ№ММЪѕТЗЯпЫцзХЪБМфдкВЛЖЯЗЂеЙЁЃ

3.1 ЛљгкЙцдђКЭзжЕфЕФЗНЗЈ
? ЛљгкЙцдђЕФNERЯЕЭГвРРЕгкШЫЙЄжЦЖЈЕФЙцдђЁЃЙцдђЕФЩшМЦвЛАуЛљгкОфЗЈЁЂгяЗЈЁЂДЪЛуЕФФЃЪНвдМАЬиЖЈСьгђЕФжЊЪЖЕШЁЃДЪЕфЪЧгЩЬиеїДЪЙЙГЩЕФДЪЕфКЭЭтВПДЪЕфЙВЭЌзщГЩ,ЭтВПДЪЕфжИвбгаЕФГЃЪЖДЪЕфЁЃ жЦЖЈКУЙцдђКЭДЪЕфКѓ,ЭЈГЃЪЙгУЦЅХфЕФЗНЪНЖдЮФБОНјааДІРэвдЪЕЯжУќУћЪЕЬхЪЖБ№ЁЃ
? ЕБзжЕфДѓаЁгаЯоЪБ,ЛљгкЙцдђЕФNERЯЕЭГПЩвдДяЕНКмКУЕФаЇЙћЁЃгЩгкЬиЖЈСьгђЕФЙцдђвдМАВЛЭъШЋЕФзжЕф,етжжNERЯЕЭГЕФЬиЕуЪЧИпОЋШЗТЪгыЕЭейЛиТЪ,ВЂЧвРрЫЦЕФЯЕЭГФбвдЧЈвЦгІгУЕНБ№ЕФСьгђжаШЅ:ЛљгкСьгђЕФЙцдђЭљЭљВЛЭЈгУ,ЖдаТЕФСьгђЖјбд,ашвЊжиаТжЦЖЈЙцдђЧвВЛЭЌСьгђзжЕфВЛЭЌЁЃЫљвдетжжЛљгкЙцдђЕФЗНЗЈОжЯоадЗЧГЃУїЯд,ВЛНіашвЊЯћКФОоДѓЕФШЫСІРЭЖЏ,ЧвВЛШнвздкЦфЫћЪЕЬхРраЭЛђЪ§ОнМЏРЉеЙЁЃ
3.2ЛљгкДЋЭГЛњЦїбЇЯАЕФЗНЗЈ
? дкЛљгкЛњЦїбЇЯАЕФЗНЗЈжа, УќУћЪЕЬхЪЖБ№БЛЕБзїЪЧађСаБъзЂЮЪЬтЁЃгыЗжРрЮЪЬтЯрБШ,ађСаБъзЂЮЪЬтжаЕБЧАЕФдЄВтБъЧЉВЛНігыЕБЧАЕФЪфШыЬиеїЯрЙи,ЛЙгыжЎЧАЕФдЄВтБъЧЉЯрЙи,МДдЄВтБъЧЉађСажЎМфЪЧгаЧПЯрЛЅвРРЕЙиЯЕЕФЁЃ
? ВЩгУЕФДЋЭГЛњЦїбЇЯАЗНЗЈжївЊАќРЈ:
- вўТэЖћПЩЗђФЃаЭ(Hidden Markov Model, HMM)
HMMЖдзЊвЦИХТЪКЭБэЯжИХТЪжБНгНЈФЃ,ЭГМЦЙВЯжИХТЪЁЃИќЪЪгУгквЛаЉЖдЪЕЪБадгавЊЧѓвдМАЯёаХЯЂМьЫїетбљашвЊДІРэДѓСПЮФБОЕФгІгУ,ШчЖЬЮФБОУќУћЪЕЬхЪЖБ№ЁЃ - зюДѓьи(Maximum Entropy, ME) [14]
MEНсЙЙНєДе,ОпгаНЯКУЕФЭЈгУад, ЦфжївЊШБЕуЪЧбЕСЗЪБМфИДдгадЗЧГЃИп,ЩѕжСЕМжТбЕСЗДњМлФбвдГаЪм,СэЭтгЩгкашвЊУїШЗЕФЙщвЛЛЏМЦЫу,ЕМжТПЊЯњБШНЯДѓЁЃ - зюДѓьиТэЖћПЩЗђФЃаЭ(Maximum Entropy Markov Model, MEMM) [15]
MEMMЖдзЊвЦИХТЪКЭБэЯжИХТЪНЈСЂСЊКЯИХТЪ,ЭГМЦЬѕМўИХТЪ,ЕЋгЩгкжЛдкОжВПзіЙщвЛЛЏШнвзЯнШыОжВПзюгХЁЃ - жЇГжЯђСПЛњ(Support Vector Machine, SVM)
SVMдке§ШЗТЪЩЯвЊБШHMMИпвЛаЉ,ЕЋЪЧHMMдкбЕСЗКЭЪЖБ№ЪБЕФЫйЖШвЊПьвЛаЉЁЃ жївЊЪЧгЩгкдкРћгУViterbiЫуЗЈЧѓНтУќУћЪЕЬхРрБ№ађСаЕФаЇТЪНЯИпЁЃ - ЬѕМўЫцЛњГЁ( Conditional Random Fields, CRF) [16]ЕШЁЃ
CRFФЃаЭЭГМЦШЋОжИХТЪ,дкЙщвЛЛЏЪБПМТЧЪ§ОндкШЋОжЕФЗжВМ,ЖјВЛЪЧНіНідкОжВПНјааЙщвЛЛЏ, вђДЫНтОіСЫMEMMжаБъМЧЦЋжУЕФЮЪЬтЁЃ дкДЋЭГЛњЦїбЇЯАжа, CRFБЛПДзїЪЧУќУћЪЕЬхЪЖБ№ЕФжїСїФЃаЭ, гХЕудкгкдкЖдвЛИіЮЛжУНјааБъзЂЕФЙ§ГЬжаCRFПЩвдРћгУФкВПМАЩЯЯТЮФЬиеїаХЯЂЁЃ ЕЋЭЌЪБДцдкЪеСВЫйЖШТ§ЁЂбЕСЗЪБМфГЄЕФЮЪЬтЁЃ
3.3 ЛљгкЩюЖШбЇЯАЕФЗНЗЈ
? НќФъРД, дкЛљгкЩёОЭјТчЕФНсЙЙЩЯМгШызЂвтСІЛњжЦЁЂЭМЩёОЭјТчЁЂЧЈвЦбЇЯАЁЂдЖМрЖНбЇЯАЕШШШУХбаОПММЪѕвВЪЧФПЧАЕФжїСїбаОПЗНЯђ ЁЃNERЪЙгУЩюЖШбЇЯАЕФдвђжївЊЪЧ:1.NERЪЪгУгкЗЧЯпадзЊЛЏЁЃ2.ЩюЖШбЇЯАБмУтДѓСПЕФШЫЙЄЬиеїЕФЙЙНЈ,НкЪЁСЫЩшМЦNERЙІФмЕФДѓСПОЋСІЁЃ3.ЩюЖШбЇЯАФмЭЈЙ§ЬнЖШДЋВЅРДбЕСЗ,етбљПЩвдЙЙНЈИќИДдгЕФЭјТчЁЃ5. ЖЫЕНЖЫЕФбЕСЗЗНЪНЁЃ
3.3.1 BiLSTM-CRF
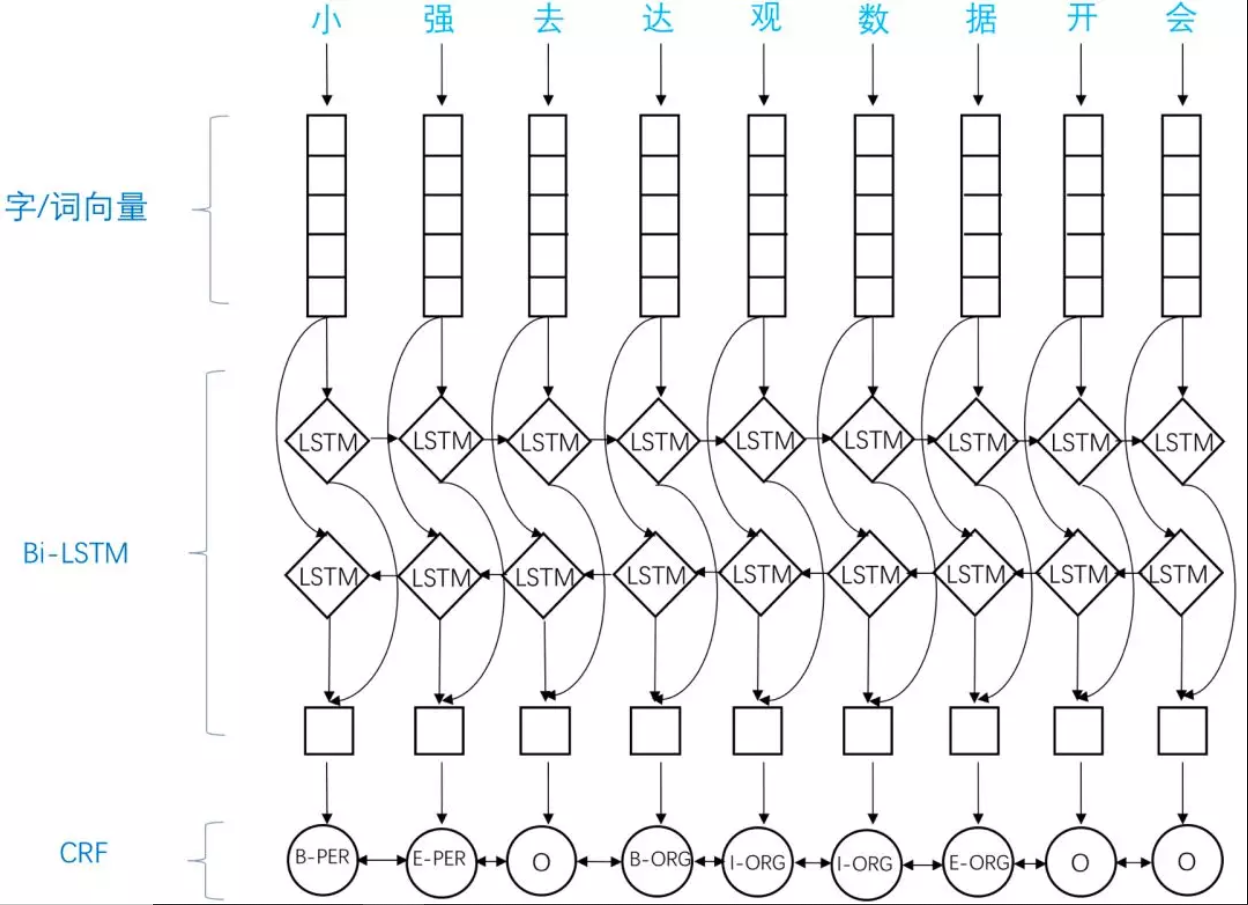
? BiLSTM-CRFжБЙлЯдЪОСЫФЃаЭНсЙЙгыгХЪЦ,ЦфжаBiLSTMЭЈЙ§ЧАЯђ/КѓЯђДЋЕнЕФЗНЪНбЇЯАађСажаФГзжЗћвРРЕЕФЙ§ШЅКЭНЋРДЕФаХЯЂ,CRFдђПМТЧЕНБъзЂађСаЕФКЯРэадЁЃФЃаЭжївЊгЩEmbeddingВу(жївЊгаДЪЯђСП,зжЯђСПвдМАвЛаЉЖюЭтЬиеї),ЫЋЯђLSTMВу,вдМАзюКѓЕФCRFВуЙЙГЩЁЃдкЬиеїЗНУц,ИУФЃаЭМЬГаСЫЩюЖШбЇЯАЗНЗЈЕФгХЪЦ,ЮоашЬиеїЙЄГЬ,ЪЙгУДЪЯђСПвдМАзжЗћЯђСПОЭПЩвдДяЕНКмКУЕФаЇЙћ,ШчЙћгаИпжЪСПЕФДЪЕфЬиеї,ФмЙЛНјвЛВНЛёЕУЬсИпЁЃ
? в§ШыЫЋЯђLSTMВузїЮЊЬиеїЬсШЁЙЄОп,LSTMгЕгаНЯЧПЕФГЄађСаЬиеїЬсШЁФмСІЁЃЫЋЯђLSTM,дкЬсШЁФГИіЪБПЬЬиеїЪБ,ФмЙЛРћгУИУЪБПЬжЎКѓЕФађСаЕФаХЯЂ,ЮовЩФмЙЛЬсИпФЃаЭЕФЬиеїЬсШЁФмСІЁЃв§ШыCRFзїЮЊНтТыЙЄОпЁЃжаЮФЪфШыОЙ§ЫЋЯђLSTMВуЕФБрТыжЎКѓ,ашвЊФмЙЛРћгУБрТыЕНЕФЗсИЛЕФаХЯЂ,НЋЦфзЊЛЏГЩNERБъзЂађСаЁЃЭЈЙ§ЙлВьађСа,дЄВтвўВизДЬЌађСа,CRFЮовЩЪЧЪзбЁЁЃ
? етаЉгХЪЦЪЙЕУТлЮФФЃаЭдкЕБЪБШЁЕУSOTAНсЙћ,вбОДяЕНЛђепГЌЙ§СЫЛљгкЗсИЛЬиеїЕФCRFФЃаЭ,ГЩЮЊФПЧАЛљгкЩюЖШбЇЯАЕФNERЗНЗЈжаЕФзюжїСїФЃаЭЁЃ
3.3.2 IDCNN-CRF
? ТлЮФFast and Accurate Entity Recognition with Iterated Dilated ConvolutionsЬсГідкNERШЮЮёжа,в§ШыХђеЭОэЛ§,вЛЗНУцПЩвдв§ШыCNNВЂааМЦЫуЕФгХЪЦ,ЬсИпбЕСЗКЭдЄВтЪБЕФЫйЖШ;СэвЛЗНУц,ПЩвдМѕЧсCNNдкГЄађСаЪфШыЩЯЬиеїЬсШЁФмСІШѕЕФСгЪЦЁЃОпЬхЪЙгУЪБ,dilated widthЛсЫцзХВуЪ§ЕФдіМгЖјжИЪ§діМгЁЃетбљЫцзХВуЪ§ЕФдіМг,ВЮЪ§Ъ§СПЪЧЯпаддіМгЕФ,ЖјИаЪмвАШДЪЧжИЪ§діМгЕФ,етбљОЭПЩвдКмПьИВИЧЕНШЋВПЕФЪфШыЪ§ОнЁЃIDCNNЖдЪфШыОфзгЕФУПвЛИізжЩњГЩвЛИіlogits,етРяОЭКЭBiLSTMФЃаЭЪфГіlogitsжЎКѓЭъШЋвЛбљ,дйЗХШыCRF LayerНтТыГіБъзЂНсЙћЁЃ
3.3.3 CAN-NER
Convolutional Attention Network for Chinese Named Entity Recognition(NAACL 2019)ЬсГіСЫгУЛљгкзЂвтСІЛњжЦЕФОэЛ§ЩёОЭјТчМмЙЙЁЃ

? ВЩгУвЛжжОэЛ§зЂвтЭјТчCAN,ЫќгЩОпгаОжВПattentionЕФЛљгкзжЗћЕФCNNКЭОпгаШЋОжattentionЕФGRUзщГЩ,гУгкЛёШЁДгОжВПЕФЯрСкзжЗћКЭШЋОжЕФОфзгЩЯЯТЮФжааХЯЂЁЃЪзЯШФЃаЭЪфШыЕФЪЧзжЗћ,ОэЛ§зЂвтСІВугУРДБрТыЪфШыЕФзжЗћађСаВЂвўЪНЕиЖдОжВПгявхЯрЙиЕФзжЗћНјааЗжзщЁЃЖдЪфШыНјааЯђСПЧЖШы,АќКЌзжЯђСПЁЂЗжДЪЯђСПКЭЮЛжУЯђСП,ЕУЕНЪфШыЯђСПКѓ,ВЩгУОжВП local attentionРДВЖзНДАПкЗЖЮЇФкжааФДЪКЭжмЮЇДЪЕФвРРЕ,ОжВП attention ЕФЪфГіБЛЫЭЕН CNN жа,зюКѓВЩгУМгКЭГиЛЏЗНАИЁЃЕУЕНОжВПЬиеїКѓ,НјШыЕНBiGRU-CRF жа,ЖјКѓВЩгУШЋОжЕФ attentionРДНјвЛВНВЖзНОфзгМЖБ№ЕФШЋОжаХЯЂЁЃКѓУцНг CRF,ЕУЕНЗжРрНсЙћЁЃself-attention ПЩвдВЖзНЙувхЕФЩЯЯТЮФаХЯЂ,МѕЩйЮогУжаМфДЪЕФИЩШХЁЃ
3.2.4 Lattice LSTM(еыЖджаЮФЕФNER)
? жаЮФЕФNERгыгЂЮФВЛЬЋвЛбљ,жаЮФNERЮЪЬтКмДѓГЬЖШЩЯШЁQгкЗжДЪЕФаЇЙћ,БШШчЪЕЬхБпНчКЭЕЅДЪЕФБпНчдкжаЮФNERПЩЬтжаОГЃЪЧвЛбљЕФЁЃЫљвддкжаЮФNERЮЪЬтжа,гаЪБЭЈГЃЯШЖдЮФБОНјааЗжДЪШЛКѓдйдЄВтађСажаЕЅДЪЕФРрБ№ЁЃетбљвЛРДЛсЕМжТвЛИіЮЪЬт,МДдкЗжДЪжадьГЩЕФДэЮѓЛсгАЯьЕНNERЕФНсЙћЁЃЛљгкзжЯђСПЕФФЃаЭФмЙЛБмУтЩЯЪіЮЪЬт,ЕЋвђЮЊЕЅДПВЩгУзжЯђСП,ЕМжТВ№ПЊСЫКмЖрВЂВЛгІИУВ№ПЊЕФДЪгя,ДгЖјЖЊЪЇСЫЫќУЧБОЩэЕФФкдкаХЯЂЁЃ

? ЁЖChinese NER Using Lattice LSTMЁЗЬсГівЛжжгУгкжаЮФNERЕФLSTMЕФИёзгФЃаЭ,гыЛљгкзжЗћЕФЗНЗЈЯрБШ,ИУФЃаЭЯдадЕиРћгУДЪКЭДЪађаХЯЂ;гыЛљгкДЪЕФЗНЗЈЯрБШ,ЭъећЕФЧЖШыДЪгяаХЯЂвђДЫ lattice LSTM ВЛЛсГіЯжЗжДЪДэЮѓЁЃУХПибЛЗЕЅдЊЪЙЕУФЃаЭФмЙЛДгОфзгжабЁдёзюЯрЙиЕФзжЗћКЭДЪ,вдЩњГЩИќКУЕФ NER НсЙћЁЃЕЋЪЧ,ДЫФЃаЭЖдгквЛаЉаТЕФДЪгяаЇЙћВЛРэЯыЁЃ
3.2.5 в§ШыBERTМАattention
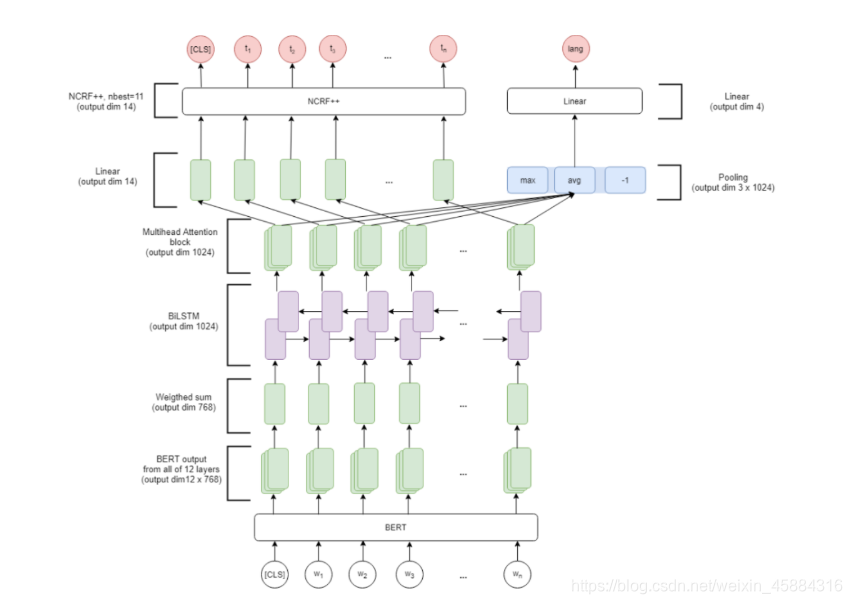
ТлЮФЁЖMultilingual Named Entity Recognition Using Pretrained Embeddings, Attention Mechanism and NCRFЁЗдкNCRFКЭBiLSTMжаМфМгШыСЫвЛВуMultihead Attention,ВЂгУBERTРДЛёШЁЩЯЯТЮФДЪБэЪО,ШЛКѓЩшМЦСЫвЛИіЖрШЮЮёНсЙЙРДбЇЯАЖргябдNERЁЃ
4.NERжївЊЪ§ОнМЏ
гЂЮФЪ§ОнМЏ
ЂйCoNLL 2003Ъ§ОнМЏАќРЈ1 393ЦЊгЂгяаТЮХЮФеТКЭ909ЦЊЕТгяаТЮХЮФеТ,гЂгягяСЯПтЪЧУтЗбЕФ,ЕТЙњгяСЯПташвЊЪеЗбЁЃгЂгягяСЯШЁздТЗЭИЩчЪеМЏЕФЙВЯэШЮЮёЪ§ОнМЏЁЃ Ъ§ОнМЏжаБъзЂСЫ4жжЪЕЬхРраЭ:PER,LOC,ORG MISCЁЃ
Ђк CoNLL 2002Ъ§ОнМЏЪЧДгЮїАрбРEFEаТЮХЛњЙЙЪеМЏЕФЮїАрбРЙВЯэШЮЮёЪ§ОнМЏЁЃЪ§ОнМЏБъзЂСЫ4жжЪЕ
ЬхРраЭ: PER,LOC,ORG,MISCЁЃ
Ђл ACE 2004 ЖргяжжбЕСЗгяСЯПтАцШЈЪєгкгябдЪ§ОнСЊУЫ(Linguistic Data Consortium, LDC), ACE 2004ЖргябдХрбЕгяСЯПтАќКЌгУгк 2004 ФъздЖЏФкШнЬсШЁ(ACE)ММЪѕЦРЙРЕФШЋЬзгЂгяЁЂ АЂРВЎгяКЭжаЮФХрбЕЪ§ОнЁЃгябдМЏгЩЮЊЪЕЬхКЭЙиЯЕБъзЂЕФИїжжРраЭЕФЪ§ОнзщГЩЁЃ
Ђм ACE 2005 ЖргяжжбЕСЗгяСЯПтАцШЈЪєгк LDC, АќКЌЭъећЕФгЂгяЁЂАЂРВЎгяКЭККгябЕСЗЪ§Он, Ъ§ОнРДдДАќРЈ:ЮЂВЉЁЂЙуВЅаТЮХЁЂаТЮХзщЁЂЙуВЅЖдЛАЕШ, ПЩвдгУРДзіЪЕЬхЁЂ ЙиЯЕЁЂ ЪТМўГщШЁЕШШЮЮёЁЃ
Ђн OntoNotes 5.0 Ъ§ОнМЏАцШЈЪєгк LDC, гЩ 1745K гЂгяЁЂ 900K жаЮФКЭ 300K АЂРВЎгяЮФБОЪ§ОнзщГЩ, OntoNotes 5.0 ЕФЪ§ОнРДдДвВЖржжЖрбљ, РДздЕчЛАЖдЛАЁЂаТЮХЭЈбЖЩчЁЂЙуВЅаТЮХЁЂЙуВЅЖдЛАКЭВЉПЭЕШЁЃЪЕЬхБЛБъзЂЮЊ PERSON,ORGANIZATION,LOCATION ЕШ 18 ИіРраЭЁЃ
Ђо MUC 7 Ъ§ОнМЏЪЧЗЂВМЕФПЩвдгУгкУќУћЪЕЬхЪЖБ№ШЮЮё, АцШЈЪєгк LDC,ЯТдиашвЊжЇИЖвЛЖЈЗбгУЁЃЪ§ОнШЁздББУРаТЮХЮФБОгяСЯПтЕФаТЮХБъЬт, ЦфжаАќКЌ 190K бЕСЗМЏЁЂ 64K ВтЪдМЏЁЃ
Ђп TwitterЪ§ОнМЏЪЧгЩZhangЕШЬсЙЉ,Ъ§ОнЪеМЏгкTwitter,бЕСЗМЏАќКЌСЫ4 000 ЭЦЬиЮФеТ, 3257ЬѕЭЦЬигУЛЇВтЪдЁЃИУЪ§ОнМЏВЛНіАќКЌЮФБОаХЯЂЛЙАќКЌСЫЭМЦЌаХЯЂ
ЦфЫќЪ§ОнМЏ
жаЮФЪ§ОнМЏ
- CCKS2017ПЊЗХЕФжаЮФЕФЕчзгВЁР§ВтЦРЯрЙиЕФЪ§ОнЁЃ
ЦРВтШЮЮёвЛ:https://biendata.com/competition/CCKS2017_1/
ЦРВтШЮЮёЖў:https://biendata.com/competition/CCKS2017_2/ - CCKS2018ПЊЗХЕФвєРжСьгђЕФЪЕЬхЪЖБ№ШЮЮёЁЃ
ЦРВтШЮЮё:https://biendata.com/competition/CCKS2018_2/ - (CoNLL 2002)Annotated Corpus for Named Entity RecognitionЁЃ
ЕижЗ:https://www.kaggle.com/abhinavwalia95/entity-annotated-corpus - NLPCC2018ПЊЗХЕФШЮЮёаЭЖдЛАЯЕЭГжаЕФПкгяРэНтЦРВтЁЃ
ЕижЗ:http://tcci.ccf.org.cn/conference/2018/taskdata.php - вЛМвЙЋЫОЬсЙЉЕФЪ§ОнМЏ,АќКЌШЫУћЁЂЕиУћЁЂЛњЙЙУћЁЂзЈгаУћДЪЁЃ
ЯТдиЕижЗ:https://bosonnlp.com/dev/resource
5.NERЙЄОп
Stanford NER
ЫЙЬЙИЃДѓбЇПЊЗЂЕФЛљгкЬѕМўЫцЛњГЁЕФУќУћЪЕЬхЪЖБ№ЯЕЭГ,ИУЯЕЭГВЮЪ§ЪЧЛљгкCoNLLЁЂMUC-6ЁЂMUC-7КЭACEУќУћЪЕЬхгяСЯбЕСЗГіРДЕФЁЃ
ЕижЗ:https://nlp.stanford.edu/software/CRF-NER.shtml
pythonЪЕЯжЕФGithubЕижЗ:https://github.com/Lynten/stanford-corenlp
# АВзА:pip install stanfordcorenlp
# ЙњФкдДАВзА:pip install stanfordcorenlp -i https://pypi.tuna.tsinghua.edu.cn/simple
# ЪЙгУstanfordcorenlpНјааУќУћЪЕЬхРрЪЖБ№
# ЯШЯТдиФЃаЭ,ЯТдиЕижЗ:https://nlp.stanford.edu/software/corenlp-backup-download.html
# ЖджаЮФНјааЪЕЬхЪЖБ№
from stanfordcorenlp import StanfordCoreNLP
zh_model = StanfordCoreNLP(r'stanford-corenlp-full-2018-02-27', lang='zh')
s_zh = 'ЮвАЎздШЛгябдДІРэММЪѕ!'
ner_zh = zh_model.ner(s_zh)
s_zh1 = 'ЮвАЎББОЉЬьАВУХ!'
ner_zh1 = zh_model.ner(s_zh1)
print(ner_zh)
print(ner_zh1)
[('ЮвАЎ', 'O'), ('здШЛ', 'O'), ('гябд', 'O'), ('ДІРэ', 'O'), ('ММЪѕ', 'O'), ('!', 'O')]
[('ЮвАЎ', 'O'), ('ББОЉ', 'STATE_OR_PROVINCE'), ('ЬьАВУХ', 'FACILITY'), ('!', 'O')]
# ЖдгЂЮФНјааЪЕЬхЪЖБ№
eng_model = StanfordCoreNLP(r'stanford-corenlp-full-2018-02-27')
s_eng = 'I love natural language processing technology!'
ner_eng = eng_model.ner(s_eng)
s_eng1 = 'I love Beijing Tiananmen!'
ner_eng1 = eng_model.ner(s_eng1)
print(ner_eng)
print(ner_eng1)
[('I', 'O'), ('love', 'O'), ('natural', 'O'), ('language', 'O'), ('processing', 'O'), ('technology', 'O'), ('!', 'O')]
[('I', 'O'), ('love', 'O'), ('Beijing', 'CITY'), ('Tiananmen', 'LOCATION'), ('!', 'O')]
MALLET
ТщЪЁДѓбЇПЊЗЂЕФвЛИіЭГМЦздШЛгябдДІРэЕФПЊдДАќ,ЦфађСаБъзЂЙЄОпЕФгІгУжаФмЙЛЪЕЯжУќУћЪЕЬхЪЖБ№ЁЃ ЙйЗНЕижЗ:http://mallet.cs.umass.edu/
Hanlp
HanLPЪЧвЛЯЕСаФЃаЭгыЫуЗЈзщГЩЕФNLPЙЄОпАќ,гЩДѓПьЫбЫїжїЕМВЂЭъШЋПЊдД,ФПБъЪЧЦеМАздШЛгябдДІРэдкЩњВњЛЗОГжаЕФгІгУЁЃжЇГжУќУћЪЕЬхЪЖБ№ЁЃ GithubЕижЗ:https://github.com/hankcs/pyhanlp
ЙйЭј:http://hanlp.linrunsoft.com/
# АВзА:pip install pyhanlp
# ЙњФкдДАВзА:pip install pyhanlp -i https://pypi.tuna.tsinghua.edu.cn/simple
# ЭЈЙ§crfЫуЗЈЪЖБ№ЪЕЬх
from pyhanlp import *
# вєвыШЫУћЪОР§
CRFnewSegment = HanLP.newSegment("crf")
term_list = CRFnewSegment.seg("ЮвАЎББОЉЬьАВУХ!")
print(term_list)
[Юв/r, АЎ/v, ББОЉ/ns, ЬьАВУХ/ns, !/w]
NLTK
NLTKЪЧвЛИіИпаЇЕФPythonЙЙНЈЕФЦНЬЈ,гУРДДІРэШЫРрздШЛгябдЪ§ОнЁЃ
GithubЕижЗ:https://github.com/nltk/nltk ЙйЭј:http://www.nltk.org/
# АВзА:pip install nltk
# ЙњФкдДАВзА:pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
import nltk
s = 'I love natural language processing technology!'
s_token = nltk.word_tokenize(s)
s_tagged = nltk.pos_tag(s_token)
s_ner = nltk.chunk.ne_chunk(s_tagged)
print(s_ner)
SpaCy
ЙЄвЕМЖЕФздШЛгябдДІРэЙЄОп,вХКЖЕФЪЧВЛжЇГжжаЮФЁЃ GihubЕижЗ: https://github.com/explosion/spaCy ЙйЭј:https://spacy.io/
# АВзА:pip install spaCy
# ЙњФкдДАВзА:pip install spaCy -i https://pypi.tuna.tsinghua.edu.cn/simple
import spacy
eng_model = spacy.load('en')
s = 'I want to Beijing learning natural language processing technology!'
# УќУћЪЕЬхЪЖБ№
s_ent = eng_model(s)
for ent in s_ent.ents:
print(ent, ent.label_, ent.label)
Beijing GPE 382
Crfsuite
ПЩвддиШыздМКЕФЪ§ОнМЏШЅбЕСЗCRFЪЕЬхЪЖБ№ФЃаЭЁЃ
ЮФЕЕЕижЗ:
https://sklearn-crfsuite.readthedocs.io/en/latest/?badge=latest
ДњТывбЩЯДЋ:https://github.com/yuquanle/StudyForNLP/blob/master/NLPbasic/NER.ipynb
6. змНс
? УќУћЪЕЬхЪЖБ№ЪЧздШЛгябдДІРэгІгУжаЕФживЊВНжш, ЫќВЛНіМьВтГіЪЕЬхБпНч,ЛЙМьВтГіУќУћЪЕЬхЕФРраЭ,ЪЧЮФБОвтвхРэНтЕФЛљДЁЁЃ БОЮФВћЪіСЫУќУћЪЕЬхЪЖБ№ЕФбаОПНјеЙ,ДгдчЦкЛљгкЙцдђКЭДЪЕфЕФЗНЗЈ,ЕНДЋЭГЛњЦїбЇЯАЕФЗНЗЈ,ЕННќФъРДЛљгкЩюЖШбЇЯАЕФЗНЗЈ, ЩёОЭјТчгы CRF ФЃаЭЯрНсКЯЕФ NN-CRF ФЃаЭвРОЩЪЧФПЧАУќУћЪЕЬхЪЖБ№ЕФжїСїФЃаЭЁЃ ЮДРДЕФбаОПжа,Ъ§ОнБъзЂКЭЗЧе§ЪНЮФБО(ЦРТлЁЂТлЬГЗЂбдЕШЮДГіЯжЙ§ЕФЪЕЬх)ШдЛсЪЧСНИіЬєеНЁЃЧЈвЦбЇЯАЁЂЖдПЙбЇЯАЁЂдЖМрЖНбЇЯАЗНЗЈвдМАЭМЩёОЭјТчЁЂзЂвтСІЛњжЦЁЂNERФЃаЭбЙЫѕЁЂЖрРрБ№ЪЕЬхЁЂЧЖЬзЪЕЬхЁЂЪЕЬхЪЖБ№КЭЪЕЬхСДНгСЊКЯШЮЮёЕШЖМЛсЪЧNERЮДРДбаОПЕФжиЕуЁЃ
ВЮПМЮФЯз
[1] Zhang Y , Yang J . Chinese NER Using Lattice LSTM[J]. 2018.
[2] Strubell E , Verga P , Belanger D , et al. Fast and Accurate Entity Recognition with Iterated Dilated Convolutions[J]. 2017.
[3] Zhu Y , Wang G , Karlsson B F . CAN-NER: Convolutional Attention Network forChinese Named Entity Recognition[J]. 2019.
[4] Emelyanov A A , Artemova E . Multilingual Named Entity Recognition Using Pretrained Embeddings, Attention Mechanism and NCRF[J]. 2019.
[5] Li J , Sun A , Han J , et al. A Survey on Deep Learning for Named Entity Recognition[J]. IEEE Transactions on Knowledge and Data Engineering, 2020, PP(99):1-1.
[6] Ratnaparkhi A . A Maximum Entropy Model for Part-Of-Speech Tagging. 2002.
[7] MCCALLUM A, FREITAG D, PEREIRA F C N. Maximum Entropy Markov Models for Information Extraction andSegmentation[C]//Icml, 2000, 17: 591-598
[8] Lafferty J , Mccallum A , Pereira F . Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C]// Proc. 18th International Conf. on Machine Learning. 2001.
[9] ГТЪяЖЋ, ХЗбєаЁвЖ. УќУћЪЕЬхЪЖБ№ММЪѕзлЪі[J]. ЮоЯпЕчЭЈаХММЪѕ, 2020, 046(003):251-260.
[10] СѕгюХє, РѕЖЌЖЌ. ЛљгкBLSTM-CNN-CRFЕФжаЮФУќУћЪЕЬхЪЖБ№ЗНЗЈ[J]. ЙўЖћБѕРэЙЄДѓбЇбЇБЈ, 2020, v.25(01):119-124.
[11] Huang Z , Wei X , Kai Y . Bidirectional LSTM-CRF Models for Sequence Tagging[J]. Computer Science, 2015.
[12] Xiang R , He W , Meng Q , et al. AFET: Automatic Fine-Grained Entity Typing by Hierarchical Partial-Label Embedding[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016.
[13] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural Language Processing (almost) from Scratch[J]. Journal of MachineLearning Research, 2011, 12(Aug): 2493-2537