首先我们介绍一下block -trerm decomposition:
 正如文章中说说,BTD是CP分解和Tucker分解的组合形式,它是把一个张量写成了多个Tucker分解的合并形式。这里我们可以提前说一下,tensorized transformer的一个优势在于写成核张量的形式可以对核张量做低秩近似,从而减小模型的参数量。另一点,后续在处理multi-head attention时,其实主要就是multi-core tensors。
正如文章中说说,BTD是CP分解和Tucker分解的组合形式,它是把一个张量写成了多个Tucker分解的合并形式。这里我们可以提前说一下,tensorized transformer的一个优势在于写成核张量的形式可以对核张量做低秩近似,从而减小模型的参数量。另一点,后续在处理multi-head attention时,其实主要就是multi-core tensors。
下面我们补充一下transformer的基本模型:
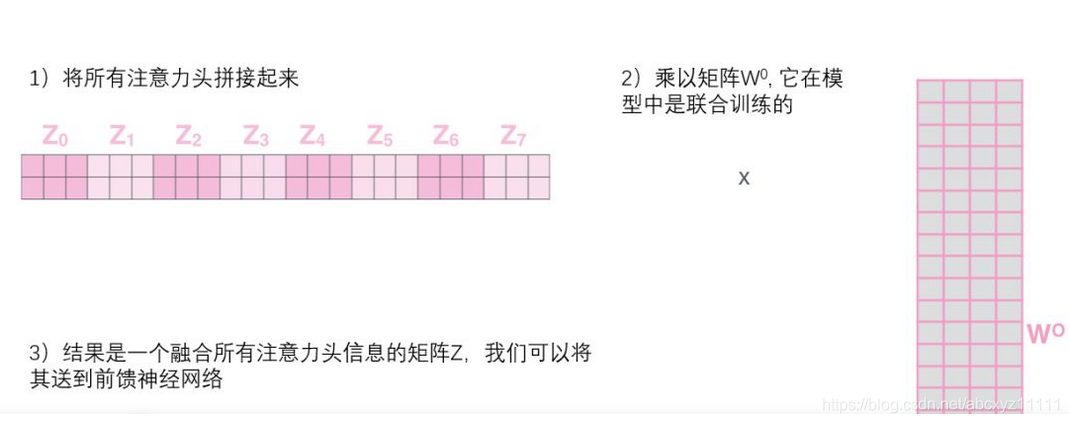
 这里的 Q,K,V并不是当初的参数矩阵,而是已经乘上input X的结果。而所谓多头其实就是有多组这样的参数矩阵,从而有多组的Output, 最后多组output拼接后乘上权重矩阵;
这里的 Q,K,V并不是当初的参数矩阵,而是已经乘上input X的结果。而所谓多头其实就是有多组这样的参数矩阵,从而有多组的Output, 最后多组output拼接后乘上权重矩阵;
另外补充一下input X的生成过程:对于图像而言,在X前其实是经历了一个卷积的过程,X的维数实际对应着卷积核的通道数。
 下面图解说明了张量化的方法:
下面图解说明了张量化的方法:


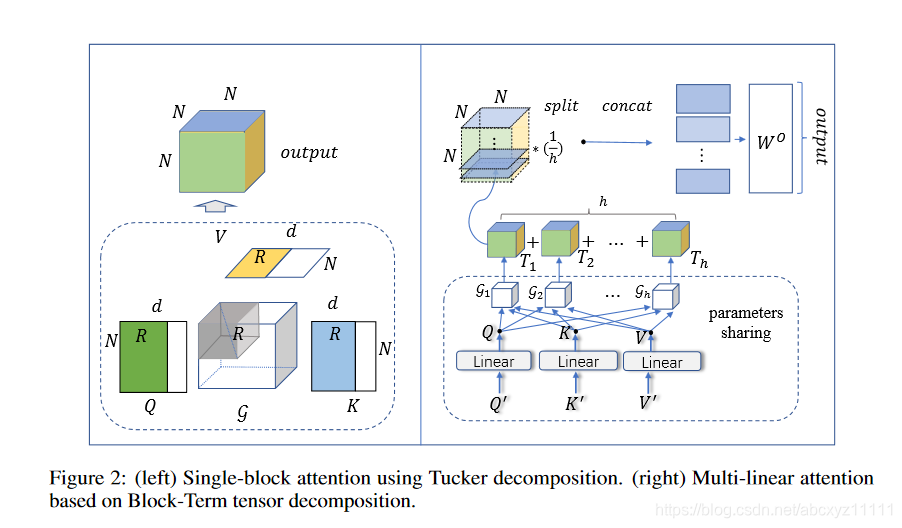 我们可以看出作者在尝试将atten写成tucker分解的形式,写成这样的形式后,在多头机制下,保持Q,K,V这样的参数矩阵不变,仅仅改变核张量(核张量是三阶对角阵,参数很少,这种方法极大的减小参数量),这样我们可以得到多个三阶张量Ti,将这些三阶张量直接做平均得到新的三阶张量,然后做切片,将切片拼接后再乘上权重矩阵。
我们可以看出作者在尝试将atten写成tucker分解的形式,写成这样的形式后,在多头机制下,保持Q,K,V这样的参数矩阵不变,仅仅改变核张量(核张量是三阶对角阵,参数很少,这种方法极大的减小参数量),这样我们可以得到多个三阶张量Ti,将这些三阶张量直接做平均得到新的三阶张量,然后做切片,将切片拼接后再乘上权重矩阵。
这种方法最大的价值在于多头的机制下,他能够极大的减小参数量:
 下面我对这篇文章模型不太能理解或者说有一定质疑的部分:
下面我对这篇文章模型不太能理解或者说有一定质疑的部分:
- 他的AttenTD模型里的Q,K,V和原来transformer里的是否有关系?引理一的等式关系,我看过补充材料的证明,还是不太能接受这样的结论。另一方面也就是说,我个人认为,新模型里面QKV的关系建立并不像trandfomer模型具有良好的解释性。
- 这里多头权重本质上是相同的,就是做了个平均,他的权重矩阵乘的其实是矩阵T的切片,所以这里的权重矩阵相比于transformer的用法是否不太合理?