1.3 假设空间
学习过程:在所有假设空间中搜索,为了使搜索结果与训练集一致,可以修改或删除假设。
那么西瓜的色泽、根蒂、敲声就是样本的属性/特征,假设空间就是由数据集属性/特征的所有值组成的空间。学习过程就是就是学习符合“好瓜”特征的值。
所有假设空间:
倘若“色泽”有3种取值,那样本空间则为4,因为还包括任意值 *;
总假设空间还要+1,即加上空集,没有“好瓜”。
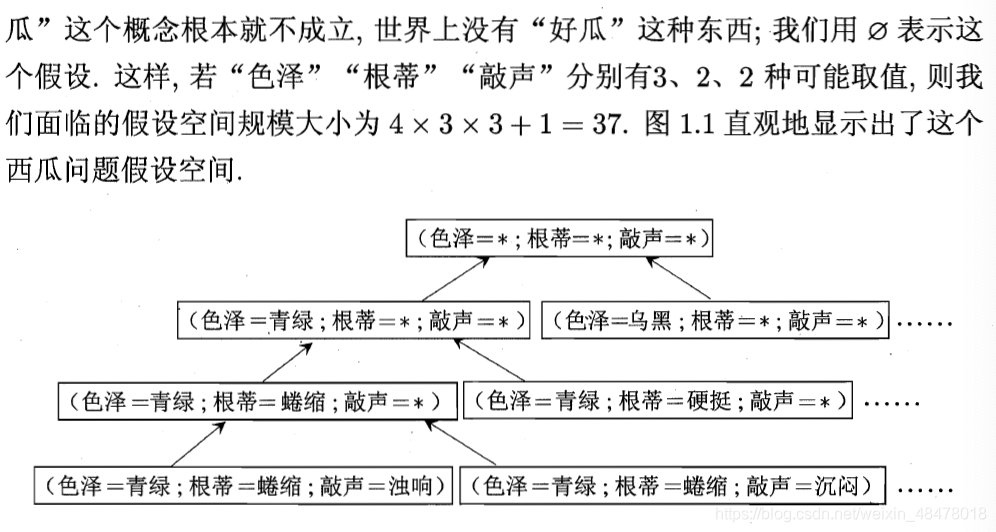
假设空间搜索方式可以自顶向下或自底向上等,可能根据数据集情况而定。
1.4 归纳偏好
怎么判断哪一个瓜“更好”,是尽可能特殊,还是尽可能一般? 如果不选择偏好,模型无法判断更好,某个瓜时而是好瓜时而是坏瓜就没有意义了。
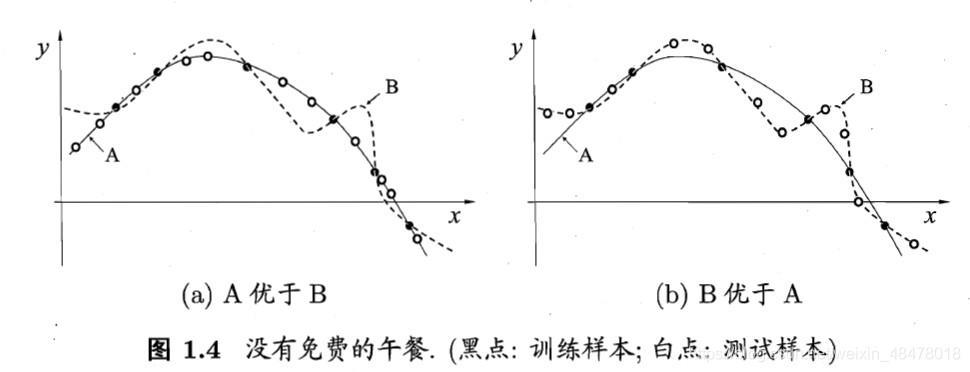
常用奥卡姆剃刀原则:“若有多个假设与观察一致,选择最简单的”。即曲线越平滑的,方程次数越小的。
但是可能出现,训练集外的数据更符合复杂的B模型而不是简单的A模型。传说中的No free lunch? 没有免费的午餐定理?若算法a在某些问题上比算法b好,那么必然存在另一些问题,在这些问题中b比a性能更优。没有单一的,通用的最佳机器学习算法,必须根据数据和背景知识来选择合适的机器学习模型。
误差公式: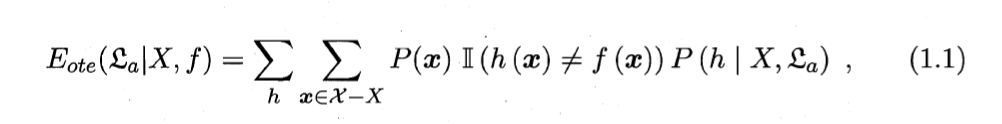
- Eote (E: expectation期望;ote: off-training error训练集外误差)
- χ?X:训练集外样本
- Ⅱ(*) 指示函数 (indicator function): 定义在某集合X上的函数,表示其中有哪些元素属于某一子集A。则Ⅱ(h(x)≠f(x))为,假设与目标函数不符,分类不正确。
公式解读:
用训练集X训练出的模型a,和实际目标函数 f 的误差 = 对于不同假设h,训练集外每个样本的概率
×
\times
× 分类结果
×
\times
× 训练集训练a模型得到假设h的概率之和
其中,分类结果只有在不正确的时候,也就是h(x)≠f(x)的时候,指示函数Ⅱ(h(x)≠f(x))才为1。所以公式只会对分类不正确的概率求和。
2.1 经验误差与过拟合
欠拟合易解决,改善学习能力即可,如决策树扩展分支、神经网络增加训练轮数等; 而过拟合只能缓解。 通过评估,选择泛化误差最小的模型,即最优模型(model selection).
用测试误差作为泛化误差的近似,而不是等同于泛化误差,所以文中假设测试集是独立同分布采样而得。于是为了采样合理,提到不同测试集划分方法,如“留出法” 、“交叉验证法” 和“自助法”。
训练集:用于训练模型
验证集:用于模型选择和调参
测试集:用于评估模型实际使用时的泛化能力
2.3 性能度量
均方误差公式解读:m个预测值f(xi)与实际值yi误差的平方和的均值
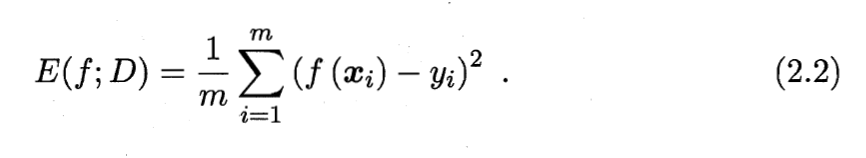
SSE, Sum of squared errors (和方差): 预测数据和原始数据对应点误差的平方和(平方是为了忽略预测值-实际值差的正负号)
MSE, mean square error (均方方差):
S
S
E
n
SSE \over n
nSSE?
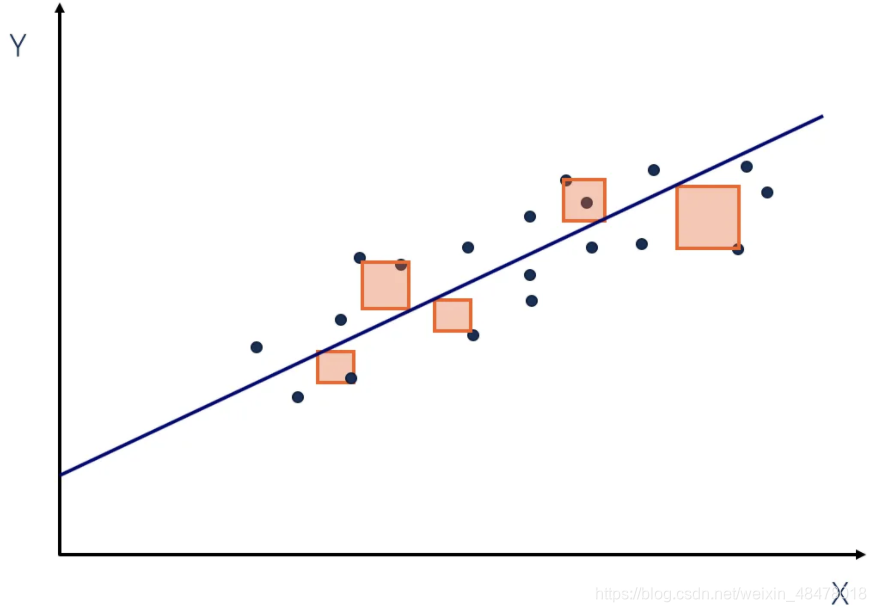
若SSE是正方形,那MSE就是平均大小的正方形:
2.3.1 错误率与精度
错误率公式: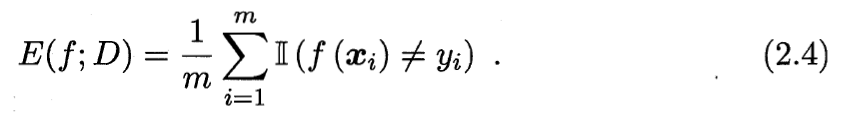
公式解读:
预
测
错
误
的
个
数
样
本
总
数
预测错误的个数 \over 样本总数
样本总数预测错误的个数?
对Ⅱ(f(xi)≠yi) 求和,即预测值f(xi)不等于实际值yi的个数,也就是预测错误的个数。
精度公式: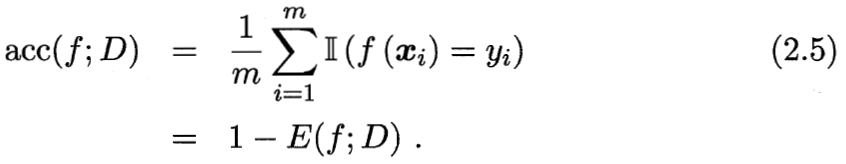
公式解读: 预 测 正 确 的 个 数 样 本 总 数 预测正确的个数 \over 样本总数 样本总数预测正确的个数? = 1- 错误率