本文内容来源于《动手深度学习》一书。跟着沐神做kaggle比赛。
1、比赛介绍:
该任务是预测房屋销售价格的基础上的信息,如卧室的数量,生活区,位置,附近的学校,和卖方总结。
数据包括2020年在加州售出的房屋,测试数据集中售出的房屋排在训练数据集中之后。此外,私人排行榜房屋也在公开排行榜房屋之后出售。
数据如下图所示,通过下面的网址,下载训练数据和测试数据:
比赛链接.

2、导入数据:
在jupyter notebook里编写的,下面的格式也是:
使用pandas读入数据:
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
train_data = pd.read_csv(r"../data/kaggle_house_pred/train.csv")
test_data = pd.read_csv(r"../data/kaggle_house_pred/test.csv")
# print(train_data.columns)
# print(test_data.columns)
print(train_data.shape) # (47439, 41)
print(test_data.shape) # (31626, 40),少了一个出售价格,需要我们预测
(47439, 41)
(31626, 40)
其中trian_data比test_data多了一列,这一列就是我们要预测的房价。
[i for i in train_data.columns if i not in test_data.columns]
[‘Sold Price’]
从上面可以看出,我们要预测的房价列名为Sold Price
3、项目构建:
打印训练数据的前四列,看看特征,以及相应标签,以便我们选择特征:
train_data.iloc[0:4]
(这里打印很乱,截图)
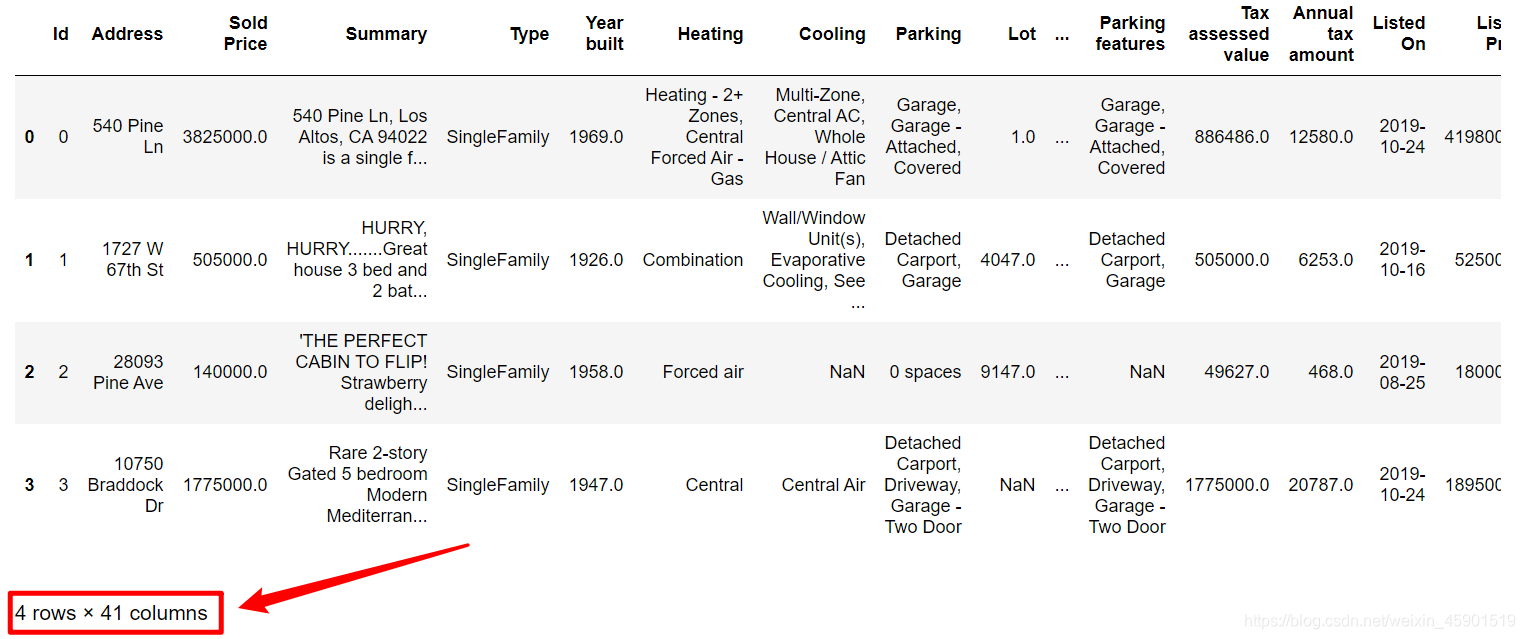
可以发现,一共有41列,也就是41个特征。额,这么说也不对,其中还有一列是标签,一列是id。
特征选择:
特征选择是个挺麻烦的事,直接关系到后面模型预测的结果,而且要是特征选择的特别多,而我们的数据不够多,很容易就过拟合了。
先看看train_data和test_data有哪些特征:
train_data.columns
Index(['Id', 'Address', 'Sold Price', 'Summary', 'Type', 'Year built',
'Heating', 'Cooling', 'Parking', 'Lot', 'Bedrooms', 'Bathrooms',
'Full bathrooms', 'Total interior livable area', 'Total spaces',
'Garage spaces', 'Region', 'Elementary School',
'Elementary School Score', 'Elementary School Distance',
'Middle School', 'Middle School Score', 'Middle School Distance',
'High School', 'High School Score', 'High School Distance', 'Flooring',
'Heating features', 'Cooling features', 'Appliances included',
'Laundry features', 'Parking features', 'Tax assessed value',
'Annual tax amount', 'Listed On', 'Listed Price', 'Last Sold On',
'Last Sold Price', 'City', 'Zip', 'State'],
dtype='object')
test_data.columns
Index(['Id', 'Address', 'Summary', 'Type', 'Year built', 'Heating', 'Cooling',
'Parking', 'Lot', 'Bedrooms', 'Bathrooms', 'Full bathrooms',
'Total interior livable area', 'Total spaces', 'Garage spaces',
'Region', 'Elementary School', 'Elementary School Score',
'Elementary School Distance', 'Middle School', 'Middle School Score',
'Middle School Distance', 'High School', 'High School Score',
'High School Distance', 'Flooring', 'Heating features',
'Cooling features', 'Appliances included', 'Laundry features',
'Parking features', 'Tax assessed value', 'Annual tax amount',
'Listed On', 'Listed Price', 'Last Sold On', 'Last Sold Price', 'City',
'Zip', 'State'],
dtype='object')
train_data中Sold Price需要剔除,因为是标签。 train_data和test_data中的Id需要剔除,因为和结果无关。(重点放在,删除的语法怎么写,以后方便查看)
在从数据集中删除ID,同时把训练和测试数据集合并起来:
合并起来的原因是:为了在整个数据集上进行归一化。
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:])) # 注意:这里将训练集和测试集合并成了一个数据集,以便归一化数据
因为都是加州的房子,需要剔除State;Summary是文本数据,分析有限就直接剔除,同理Address:每个房子的地址都不同,如果进行独热编码负担太大,分析也有限,所以也剔除。另外:
由于我打算使用MLP进行房价预测,比较简单,所有我就自己选择了一些认为影响房价的特征:Year built、Lot、Bedrooms、Bathrooms、Full bathrooms、Total spaces、High School Score、Tax assessed value、Annual tax amount、Listed Price、Last Sold Price、Zip
(我原本想着Summary是文本数据,也就是对房子的评价,建立一个模型把Summary进行分类,再送入预测房价的模型中,但是有点麻烦,主要还是不熟,就没弄)。
all_features = all_features.loc[:, ["Year built", "Lot", "Bathrooms", "Full bathrooms", "Total spaces", "High School Score","Tax assessed value", "Annual tax amount", "Listed Price", "Last Sold Price", "Zip"]]
预处理:
存在缺失值,这里的原始数据用NAN表示缺失。看看是否有nan值,也就是缺失值
np.any(all_features.isnull()) # 看看是否有nan值,也就是缺失值
# 返回True,说明有缺失值
True
发现有缺失值。
- 一、数值特征:将所有缺失的值替换为相应特征的平均值。 通过将特征重新缩放到零均值和单位方差来标准化数据:
# 获取数值特征的索引名
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std())) # 零均值和单位方差来标准化数据
all_features[numeric_features] = all_features[numeric_features].fillna(0) # 因为已经标准化数据了,这些特征的缺失值用平均值0填充
print(numeric_features)
Index([‘Year built’, ‘Lot’, ‘Bathrooms’, ‘Full bathrooms’, ‘Total spaces’,
‘High School Score’, ‘Tax assessed value’, ‘Annual tax amount’,
‘Listed Price’, ‘Last Sold Price’, ‘Zip’],
dtype=‘object’)
- 二、离散值特征:用一次独热编码替换
# 字符串特征,则用one-hot编码替换
all_features = pd.get_dummies(all_features, dummy_na=True) # pd.get_dummies是:利用pandas实现one hot encode的方式
all_features.shape
(79065, 11)
从pandas格式中提取NumPy格式,并将其转换为张量表示:
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values,
dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values,
dtype=torch.float32)
train_labels = torch.tensor(train_data["Sold Price"].values.reshape(-1, 1),
dtype=torch.float32)
print(train_features.shape) # 两个维度,0维:样本数;1维:特征数
print(train_labels.shape) # 标签
torch.Size([47439, 11])
torch.Size([47439, 1])
训练:
loss = nn.MSELoss() # 均方损失函数
in_features = train_features.shape[1] # 特征数
def get_net():
net = nn.Sequential(nn.Linear(in_features, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 1)) # 多层感知机
return net
我们更关心相对误差 y ? y ^ y \frac{{{\rm{y}} - \hat y}}{y} yy?y^??(RMSE),解决这个问题的一种方法是用价格预测的对数来衡量差异:
def log_rmse(net, features, labels):
# torch.clamp函数:将输入input张量每个元素的夹紧到区间 [min,max][min,max],并返回结果到一个新张量。这里是区间1~无穷大
clipped_preds = torch.clamp(net(features), 1, float('inf'))
# 将标签和预测值取对数,并送入rmse中
rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))
return rmse.item() # 返回数值,而不是tensor
我们的训练函数将借助Adam优化器:
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size) # 将训练数据打包成batch_size大小,并可迭代取出
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate,
weight_decay=weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad() # 梯度清零
l = loss(net(X), y) # 计算损失,注意:pytorch会自动将向量转换成标量,以便反向传播计算导数
l.backward() # 反向传播:计算梯度
optimizer.step() # 更新参数
train_ls.append(log_rmse(net, train_features, train_labels)) # 将训练的对数rmse保存下来,以便返回
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels)) # 将测试的对数rmse保存下来,以便返回
return train_ls, test_ls
K折交叉验证:
def get_k_fold_data(k, i, X, y): # i表示第几折
assert k > 1
fold_size = X.shape[0] // k # 分成k份,每折的大小
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size) # slice() 函数实现切片对象,主要用在切片操作函数里的参数传递。
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k): # 做k次
data = get_k_fold_data(k, i, X_train, y_train) # 获取训练集和验证集
net = get_net() # 模型
if torch.cuda.is_available():
net = net.cuda()
data = data.cuda()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size) # 得到损失,注意:data传入的是列表
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
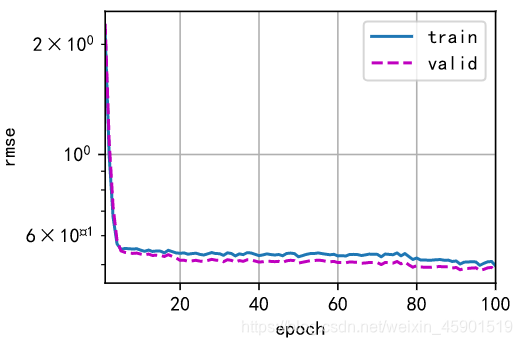
if i == 0: # 画第1折训练的曲线
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'fold {i + 1}, train log rmse {float(train_ls[-1]):f}, '
f'valid log rmse {float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
模型训练及选择:
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 0.01, 0.1, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')
fold 1, train log rmse 0.496148, valid log rmse 0.481028
fold 2, train log rmse 0.515603, valid log rmse 0.496411
fold 3, train log rmse 0.348585, valid log rmse 0.334969
fold 4, train log rmse 0.341814, valid log rmse 0.354099
fold 5, train log rmse 0.367565, valid log rmse 0.438403
5-折验证: 平均训练log rmse: 0.413943, 平均验证log rmse: 0.420982
模型推理及保存预测结果:
def train_and_pred(train_features, test_feature, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'train log rmse {float(train_ls[-1]):f}')
preds = net(test_features).detach().numpy()
test_data['Sold Price'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['Sold Price']], axis=1)
submission.to_csv(r'../data/kaggle_house_pred/submission.csv', index=False) # 将预测的房价结果保存下来
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
train log rmse 0.309912

4、上传预测结果到kaggle:
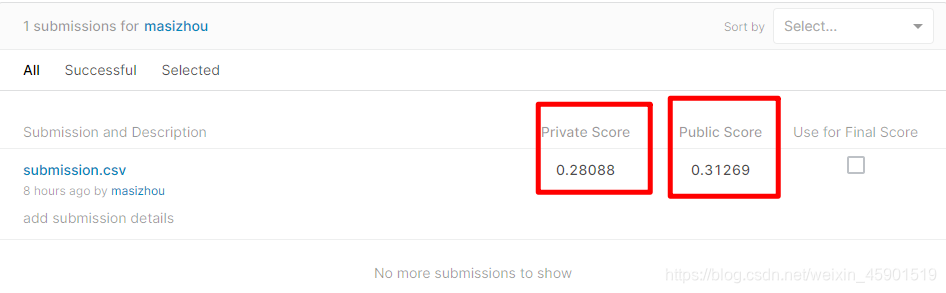
下面是我得的分数,也就是使用多层感知机(MLP)进行预测:
5、总结:
其实对于机器学习模型,最费时间,最费精力的不是模型的构建,而是数据的处理,就比如这个房价预测,要是把数据处理好了,好多模型都可以使用框架快速的搭建出来。
在这里我使用了 两层的感知机,并在每层使用relu激活函数,得到的预测结果还不错。但是我对于特征的选择和处理方面做的太少了。
看别人使用了全基本全部的特征,使用了多种方法,自然得分更高。我在最开始也把所有特征加入了,但是由于字符串特征直接用one-hot编码,使得特征变得很大(10万+),而我对于其他的编码不熟悉,因此就手动的选择了特征。
后面学到更多的模型了再做改进!!!
加油!!!