����Ŀ¼
������ѧϰ��Դ��Ŀ��hands-on data analysis��֮����ܽᡣƽ̨ʹ��jupyter notebook��
��Ŀ����:https://github.com/datawhalechina/ensemble-learning
�½�ѧϰ��Ƶ����:https://www.bilibili.com/video/BV1oQ4y1X7ep/
�ߵ���ѧ
�ߵ���ѧ���漰���Ļ�����������:
�����������������Ϻ���������������(�Ͳ���̵������Ϻ��������ó��Ⱥ�������)���߽���
��Ԫ����(nά�ռ�)����Ԫ������ƫ�������ݶ��������ſ˱�Jacobian������Hessian����
�����ļ�ֵ/��ֵ(���Ż�����)��һ/��Ԫ�����ж���ֵ�ķ����������ʽԼ�����Ż�����(�������ճ��ӷ�)
̩�չ�ʽ�������ݶȵ��Ż������C�ݶ��½����������ݶȵ��Ż������Cţ�ٵ�����
���ǵ�������������,����ֻ����������Ϊ�IJ����ص����ݡ�
��Ԫ��������ظ���
-
nά�ռ�
�� n n n Ϊ������,�� R n \mathbf{R}^{n} Rn ��ʾ n n n Ԫ����ʵ���� ( x 1 , x 2 , ? ? , x n ) \left(x_{1}, x_{2}, \cdots,\right.\left.x_{n}\right) (x1?,x2?,?,xn?) ��ȫ�������ɵļ���,��
R n = R �� R �� ? �� R = { ( x 1 , x 2 , ? ? , x n ) �O x i �� R , i = 1 , 2 , ? ? , n } . \mathbf{R}^{n}=\mathbf{R} \times \mathbf{R} \times \cdots \times \mathbf{R}=\left\{\left(x_{1}, x_{2}, \cdots, x_{n}\right) \mid x_{i} \in \mathbf{R}, i=1,2, \cdots, n\right\}. Rn=R��R��?��R={(x1?,x2?,?,xn?)�Oxi?��R,i=1,2,?,n}.R n \mathbf{R}^{n} Rn �е�Ԫ�� ( x 1 , x 2 , ? ? , x n ) \left(x_{1}, x_{2}, \cdots, x_{n}\right) (x1?,x2?,?,xn?) ��ʱҲ�õ�����ĸ x \boldsymbol{x} x ����ʾ, �� x = ( x 1 , x 2 , ? ? , x n ) . \boldsymbol{x}=\left(x_{1}, x_{2}, \cdots,\right.\left.x_{n}\right) . x=(x1?,x2?,?,xn?).
�����е� x i ( i = 1 , 2 , ? ? , n ) x_{i}(i=1,2, \cdots, n) xi?(i=1,2,?,n) ��Ϊ��ʱ,��������Ԫ��Ϊ R n \mathbf{R}^{n} Rn �е���Ԫ,��Ϊ0�� O��
�ڽ���������,ͨ��ֱ������ϵ, R 2 \mathbf{R}^{2} R2 (�� R 3 \mathbf{R}^{3} R3 )�е�Ԫ�طֱ���ƽ��(��ռ�)�еĵ�(������)����һһ��Ӧ��
Ϊ���ڼ��� R n \mathbf{R}^{n} Rn �е�Ԫ�ؼ佨����ϵ,�� R n \mathbf{R}^{n} Rn �ж����ߴ���������:
�� x = ( x 1 , x 2 , ? ? , x n ) , y = ( y 1 , y 2 , ? ? , y n ) \boldsymbol{x}=\left(x_{1}, x_{2}, \cdots, x_{n}\right), \boldsymbol{y}=\left(y_{1}, y_{2}, \cdots, y_{n}\right) x=(x1?,x2?,?,xn?),y=(y1?,y2?,?,yn?) Ϊ R n \mathbf{R}^{n} Rn ����������Ԫ��, �� �� R \lambda \in \mathbf{R} ����R,�涨:
x + y = ( x 1 + y 1 , x 2 + y 2 , ? ? , x n + y n ) , �� x = ( �� x 1 , �� x 2 , ? ? , �� x n ) \begin{array}{c} \boldsymbol{x}+\boldsymbol{y}=\left(x_{1}+y_{1}, x_{2}+y_{2}, \cdots, x_{n}+y_{n}\right), \\ \lambda \boldsymbol{x}=\left(\lambda x_{1}, \lambda x_{2}, \cdots, \lambda x_{n}\right) \end{array} x+y=(x1?+y1?,x2?+y2?,?,xn?+yn?),��x=(��x1?,��x2?,?,��xn?)?
������������������ļ��� R n \mathbf{R}^{n} Rn ��Ϊ** n n n ά�ռ�**��n n nά�ռ��������ľ���:
R n \mathbf{R}^{n} Rn �е� x = ( x 1 , x 2 , ? ? , x n ) \boldsymbol{x}=\left(x_{1}, x_{2}, \cdots, x_{n}\right) x=(x1?,x2?,?,xn?) �͵� y = ( y 1 , y 2 , ? ? , y n ) \boldsymbol{y}=\left(y_{1}, y_{2}, \cdots, y_{n}\right) y=(y1?,y2?,?,yn?) �������, ���� �� ( x , y ) \rho(\boldsymbol{x}, \boldsymbol{y}) ��(x,y), �涨
�� ( x , y ) = ( x 1 ? y 1 ) 2 + ( x 2 ? y 2 ) 2 + ? + ( x n ? y n ) 2 \rho(\boldsymbol{x}, \boldsymbol{y})=\sqrt{\left(x_{1}-y_{1}\right)^{2}+\left(x_{2}-y_{2}\right)^{2}+\cdots+\left(x_{n}-y_{n}\right)^{2}} ��(x,y)=(x1??y1?)2+(x2??y2?)2+?+(xn??yn?)2? -
��Ԫ����
�� D D D �� R 2 \mathbf{R}^{2} R2��һ���ǿ��Ӽ�,��ӳ�� f : D �� R f: D \rightarrow \mathbf{R} f:D��R Ϊ������ D D D �ϵĶ�Ԫ����,����Ϊ z = f ( x , y ) , ( x , y ) �� D z=f(x, y),(x, y) \in D z=f(x,y),(x,y)��D �� z = f ( P ) , P �� D z=f(P), P \in D z=f(P),P��D��
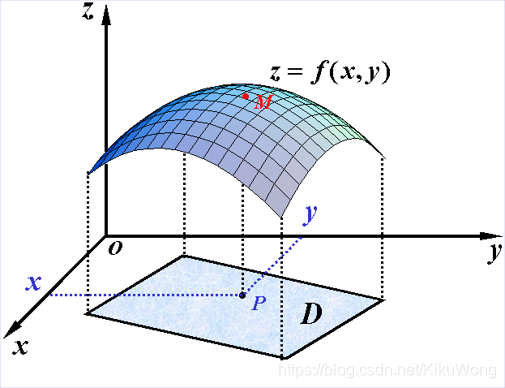
��Ԫ������ƫ����
���Ԫ���� z = f ( x , y ) z=f(x, y) z=f(x,y) �ڵ� ( x 0 , y 0 ) \left(x_{0}, y_{0}\right) (x0?,y0?) ��ij�������ж���,��� lim ? �� x �� 0 �� x z �� x \lim\limits_{\Delta x \to 0} \frac{\Delta_{x} z}{\Delta x} ��x��0lim?��x��x?z? ����,�ͳ���Ϊ���� z = f ( x , y ) z=f(x, y) z=f(x,y)�ڵ�( x 0 , y 0 ) \left.x_{0}, y_{0}\right) x0?,y0?) ���� x x x ��ƫ������
���� ? z ? x �O ( x 0 , y 0 ) \left.\frac{\partial z}{\partial x}\right|_{\left(x_{0}, y_{0}\right)} ?x?z?�O�O?(x0?,y0?)?, ? f ? x �O ( x 0 , y 0 ) \left.\frac{\partial f}{\partial x}\right|_{\left(x_{0}, y_{0}\right)} ?x?f?�O�O�O?(x0?,y0?)?,�� ? z ? x �O ( x 0 , y 0 ) = lim ? �� x �� 0 �� x z �� x = lim ? �� x �� 0 f ( x 0 + �� x , y 0 ) ? f ( x 0 , y 0 ) �� x \left.\frac{\partial z}{\partial x}\right|_{\left(x_{0}, y_{0}\right)}=\lim\limits_{\Delta x \to 0} \frac{\Delta_{x} z}{\Delta x} =\lim\limits_{\Delta x \rightarrow 0} \frac{f\left(x_{0}+\Delta x, y_{0}\right)-f\left(x_{0}, y_{0}\right)}{\Delta x} ?x?z?�O�O?(x0?,y0?)?=��x��0lim?��x��x?z?=��x��0lim?��xf(x0?+��x,y0?)?f(x0?,y0?)? .
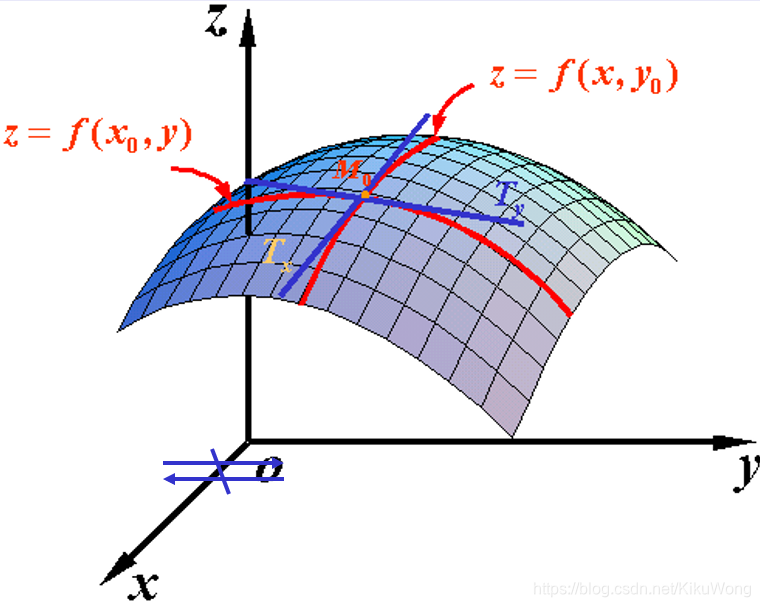
�ݶ���/ʸ��Gradient
�ݶ��ǵ����Զ�Ԫ�������ƹ�,�Ƕ�Ԫ�����Ը����Ա���ƫ�����γɵ�����,�������൱��һԪ�����ĵ�����
һ��ƫ������һ��������,ֻ��ӳ��Ԫ������һ���Ա���֮��Ĺ�ϵ��
�ݶ�������˺����������Ա�����ƫ����,�ۺ��˶������Ա����Ĺ�ϵ��
��һԪ�����ĵ�������,�ݶȾ����˶�Ԫ�����ĵ����Ժͼ�ֵ��
�ݶ�:ijһ�����ڸõ㴦�ķ��������Ÿ÷���ȡ�����ֵ,�������ڸõ㴦���Ÿ÷���(���ݶȵķ���)�仯���,�仯�����(Ϊ���ݶȵ�ģ)��
����:���Ԫ����
z
=
f
(
x
,
y
)
z=f(x, y)
z=f(x,y) ��ƽ������
D
D
D �Ͼ���һ������ƫ����,�����ÿһ����P
(
x
,
y
)
(x, y)
(x,y)���ɶ���һ������
{
?
f
?
x
,
?
f
?
y
}
=
f
x
(
x
,
y
)
i
?
+
f
y
(
x
,
y
)
j
?
\left\{\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}\right\}=f_{x}(x, y) \vec{i}+f_{y}(x, y) \vec{j}
{?x?f?,?y?f?}=fx?(x,y)i+fy?(x,y)j? ,�ú����ͳ�Ϊ����
z
=
f
(
x
,
y
)
z=f(x, y)
z=f(x,y) �ڵ�P
(
x
,
y
)
(x, y)
(x,y)���ݶ�,����gradf
(
x
,
y
)
(\mathrm{x}, \mathrm{y})
(x,y) ��
?
f
(
x
,
y
)
\nabla f(x, y)
?f(x,y),����:
gradf
?
(
x
,
y
)
=
?
f
(
x
,
y
)
=
{
?
f
?
x
,
?
f
?
y
}
=
f
x
(
x
,
y
)
i
?
+
f
y
(
x
,
y
)
j
?
\operatorname{gradf}(\mathrm{x}, \mathrm{y})=\nabla f(x, y)=\left\{\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}\right\}=f_{x}(x, y) \vec{i}+f_{y}(x, y) \vec{j}
gradf(x,y)=?f(x,y)={?x?f?,?y?f?}=fx?(x,y)i+fy?(x,y)j?
����
?
=
?
?
x
i
?
+
?
?
y
j
?
\nabla=\frac{\partial}{\partial x} \vec{i}+\frac{\partial}{\partial y} \vec{j}
?=?x??i+?y??j? ��Ϊ(��ά��)���������ӻ�Nabla���ӡ��ݶ�����,
?
f
=
?
f
?
x
i
?
+
?
f
?
y
j
?
\nabla f=\frac{\partial f}{\partial x} \vec{i}+\frac{\partial f}{\partial y} \vec{j}
?f=?x?f?i+?y?f?j? ��
�����������������ݶȼ�Ĺ�ϵ:
�������ɿ���ƫ������һ�㻯,����ʵ�����ⷽ�����,���Ա�������ijһ����仯ʱ�ĵ��������÷���ָ������Ա����������᷽��,����������ƫ������

�ſ˱Ⱦ���(Jacobian����)
�ſɱȾ�������������������ƫ�������ɵľ���,�ɼ���ʽ����ı���,�ڶ�Ԫ�����Ļ�Ԫ������Ӧ����
���� F : R n �� R m F: \mathbb{R}_{n} \rightarrow \mathbb{R}_{m} F:Rn?��Rm? ��һ����nάŷ�Ͽռ�ӳ�䵽��mάŷ�Ͽռ�ĺ���(��������������ӳ��: y = f ( x ) \boldsymbol{y}=f(\boldsymbol{x}) y=f(x))�����������m��ʵ�������: y 1 = ( x 1 , ? ? , x n ) , ? ? , y m = ( x 1 , ? ? , x n ) y_{1}=\left(x_{1}, \cdots, x_{n}\right), \cdots, y_{m}=\left(x_{1}, \cdots, x_{n}\right) y1?=(x1?,?,xn?),?,ym?=(x1?,?,xn?) ��
��Щ������ƫ����(�������)�����һ��m��n�еľ���,���ſɱȾ���(�ɶ����Ԫ�����ݶ���ɵľ���):
[
?
y
1
?
x
1
?
?
y
1
?
x
n
?
?
?
?
y
m
?
x
1
?
?
y
m
?
x
n
]
\left[\begin{array}{ccc} \frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}} \end{array}\right]
?????x1??y1????x1??ym????????xn??y1????xn??ym???????
�ɼ�,�ݶ��������ſ˱Ⱦ��������!
��ɭ����(Hessian ����)
��������(Hessian Matrix),�ֳƺ�ɭ����ɪ�����������,����һ����Ԫ�����Ķ���ƫ�������ɵķ���,�����˺����ľֲ����ʡ�
������һʵ������
f
(
x
1
,
x
2
,
��
,
x
n
)
f\left(x_{1}, x_{2}, \ldots, x_{n}\right)
f(x1?,x2?,��,xn?),���
f
f
f ���ɵ�,��ô
f
f
f �ĺ�ɭ����Ϊ:
H
(
f
)
=
[
?
2
f
?
x
1
2
?
2
f
?
x
1
?
x
2
?
?
2
f
?
x
1
?
x
n
?
2
f
?
x
2
?
x
1
?
2
f
?
x
2
2
?
?
2
f
?
x
2
?
x
n
?
?
?
?
?
2
f
?
x
n
?
x
1
?
2
f
?
x
n
?
x
2
?
?
2
f
?
x
n
2
]
H(f)=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right]
H(f)=?????????x12??2f??x2??x1??2f???xn??x1??2f???x1??x2??2f??x22??2f???xn??x2??2f????????x1??xn??2f??x2??xn??2f???xn2??2f??????????
һ��,��Ԫ�����Ļ�϶���ƫ������������,�� ? 2 f ? x i ? x j = ? 2 f ? x j ? x i \frac{\partial^{2} f}{\partial x_{i} \partial x_{j}}=\frac{\partial^{2} f}{\partial x_{j} \partial x_{i}} ?xi??xj??2f?=?xj??xi??2f?��
ʵ����,Hessian�������ݶ�����g(x)���Ա���x��Jacobian������
��Ԫ�����µļ�ֵ����(���Ż�����)
��nԪʵ����
f
(
x
1
,
x
2
,
?
?
,
x
n
)
f\left(x_{1}, x_{2}, \cdots, x_{n}\right)
f(x1?,x2?,?,xn?) �ڵ�
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) ���������ж�������ƫ��,����:
?
f
?
x
j
�O
(
a
1
,
a
2
,
��
,
a
n
)
=
0
,
j
=
1
,
2
,
��
,
n
\left.\frac{\partial f}{\partial x_{j}}\right|_{\left(a_{1}, a_{2}, \ldots, a_{n}\right)}=0, j=1,2, \ldots, n
?xj??f?�O�O�O�O?(a1?,a2?,��,an?)?=0,j=1,2,��,n
����
A
=
[
?
2
f
?
x
1
2
?
2
f
?
x
1
?
x
2
?
?
2
f
?
x
1
?
x
n
?
2
f
?
x
2
?
x
1
?
2
f
?
x
2
2
?
?
2
f
?
x
2
?
x
n
?
?
?
?
?
2
f
?
x
n
?
x
1
?
2
f
?
x
n
?
x
2
?
?
2
f
?
x
n
2
]
A=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right]
A=?????????x12??2f??x2??x1??2f???xn??x1??2f???x1??x2??2f??x22??2f???xn??x2??2f????????x1??xn??2f??x2??xn??2f???xn2??2f??????????
�������½��:
(1) ��AΪ��������ʱ,
f
(
x
1
,
x
2
,
?
?
,
x
n
)
f\left(x_{1}, x_{2}, \cdots, x_{n}\right)
f(x1?,x2?,?,xn?) ��
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) ������Сֵ;
(2) ��AΪ��������ʱ,
f
(
x
1
,
x
2
,
?
?
,
x
n
)
f\left(x_{1}, x_{2}, \cdots, x_{n}\right)
f(x1?,x2?,?,xn?) ��
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) ��������ֵ;
(3) ��AΪ��������ʱ,
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) ���Ǽ�ֵ�㡣
(4) ��AΪ�����������븺������ʱ,
M
0
(
a
1
,
a
2
,
��
,
a
n
)
M_{0}\left(a_{1}, a_{2}, \ldots, a_{n}\right)
M0?(a1?,a2?,��,an?) �ǡ�����"��ֵ��,���������������ж���
����ʽԼ�����Ż�����(�������ճ��ӷ�Lagrange Multiplier Method)
��Ԫ�����´���ʽԼ�����Ż�����:���� z = f ( x , y ) z=f(x, y) z=f(x,y) ������ �� ( x , y ) = 0 \varphi(x, y)=0 ��(x,y)=0 �µļ�ֵ��
�����������պ��� L ( x , y ) = f ( x , y ) + �� �� ( x , y ) L(x, y)=f(x, y)+\lambda \varphi(x, y) L(x,y)=f(x,y)+����(x,y) , �� \lambda ��Ϊ��������Ա���,��Ϊ�������ճ��ӡ�
�������Ա�����ƫ��,������Ϊ0,�ü�ֵ�����������: { L x ( x 0 , y 0 ) = 0 L y ( x 0 , y 0 ) = 0 �� ( x 0 , y 0 ) = 0 \left\{\begin{array}{l}L_{x}\left(x_{0}, y_{0}\right)=0 \\ L_{y}\left(x_{0}, y_{0}\right)=0 \\ \varphi\left(x_{0}, y_{0}\right)=0\end{array}\right. ????Lx?(x0?,y0?)=0Ly?(x0?,y0?)=0��(x0?,y0?)=0?
��һ��Ķ�������:
��ֵ����: min ? x f ( x ) \min\limits_{x} f(x) xmin?f(x) s.t. h i ( x ) = 0 , i = 1 , 2 , �� , n h_i(\boldsymbol{x})=0, i=1,2, \ldots, n hi?(x)=0,i=1,2,��,n (s.t.��subject to�����ڵ���˼)
�������պ���Ϊ: L ( x , �� ) = f ( x ) + �� i = 1 p �� i h i ( x ) L(\boldsymbol{x},\boldsymbol{\lambda})=f(\boldsymbol{x})+\sum\limits_{i=1}^{p} \lambda_{i} h_{i}(\boldsymbol{x}) L(x,��)=f(x)+i=1��p?��i?hi?(x)
���������ճ��Ӻ����������Ա�����ƫ����,������Ϊ0��������� x \boldsymbol{x} x�� �� \boldsymbol{\lambda} ����,�õ����з�����:
KaTeX parse error: No such environment: split at position 15: \left\{\begin{?s?p?l?i?t?}? \nabla_{x} f(\��
**���÷����鼴�ɵõ������ĺ�ѡ��ֵ�㡣**һ���ٽ�Ϻ�������,���ݸõ㴦������������������ж��Ǽ�Сֵ�㻹�Ǽ���ֵ�㡣�������ճ������ļ��ν���:�ڼ�ֵ�㴦Ŀ�꺯�����ݶ���Լ�������ݶȵ�������� ? x f ( x ) = ? �� i = 1 p �� i ? x h i ( x ) \nabla_{x} f(\boldsymbol{x})=-\sum\limits_{i=1}^{p} \lambda_{i} \nabla_{x} h_{i}(\boldsymbol{x}) ?x?f(x)=?i=1��p?��i??x?hi?(x)
̩�չ�ʽ
̩�չ�ʽ������һ������ʽ����ȥ�ƽ�һ�������ĺ���(������ʹ����ʽ����ͼ����ϸ����ĺ���ͼ��)��
̩�չ�ʽ�ڻ���ѧϰ����ҪӦ�����ݶȵ���
����:��
n
n
n ��������,���������һ������a�������ϵĺ���
f
f
f ��
a
a
a �㴦
n
+
1
n+1
n+1 �οɵ�,��ô������������ϵ�����
x
x
x ����:
f
(
x
)
=
f
(
a
)
0
!
+
f
��
(
a
)
1
!
(
x
?
a
)
+
f
��
��
(
a
)
2
!
(
x
?
a
)
2
+
?
+
f
(
n
)
(
a
)
n
!
(
x
?
a
)
n
+
R
n
(
x
)
=
��
i
=
0
n
f
(
i
)
(
a
)
i
!
(
x
?
a
)
n
+
R
n
(
x
)
\begin{array}{l} f(x)=\frac{f(a)}{0 !}+\frac{f^{\prime}(a)}{1 !}(x-a)+\frac{f^{\prime \prime}(a)}{2 !}(x-a)^{2}+\cdots+\frac{f^{(n)}(a)}{n !}(x-a)^{n}+R_{n}(x) \\ =\sum\limits_{i=0}^{n} \frac{f^{(i)}(a)}{i !}(x-a)^{n}+R_{n}(x) \end{array}
f(x)=0!f(a)?+1!f��(a)?(x?a)+2!f����(a)?(x?a)2+?+n!f(n)(a)?(x?a)n+Rn?(x)=i=0��n?i!f(i)(a)?(x?a)n+Rn?(x)?
���еĶ���ʽ��Ϊ������a����̩��չ��ʽ,
R
n
(
x
)
R_{n}(x)
Rn?(x) ��̩�չ�ʽ�����
�����ݶȵ��Ż������C�ݶ��½���(Pythonʵ�־���)
�����ݶ��½�������ɲμ�:�ݶ��½�(Gradient Descent)С��,�ݶ��½��㷨(������ʵ��)
�ݶ��½�Gradient Descent ���Ż���ʽ: x k + 1 = x k ? �� ? f ( x ) \boldsymbol{x}_{k+1}=\boldsymbol{x}_{k}-\alpha\nabla f(\boldsymbol{x}) xk+1?=xk??��?f(x) ,���� x \boldsymbol{x} x �Ǵ���IJ���, �� \alpha �� ��ѧϰ��-����ÿ���Ż��IJ���, f ( x ) f(\boldsymbol{x}) f(x) ��Ŀ�꺯����
�ݶ��½���һ�������Ĺ���,���ǽ�����,����һ�����͵ġ�
�ݶ��½����㷨����:
����:Ŀ�꺯�� f ( x ) f(\boldsymbol{x}) f(x),�ݶȺ��� g ( x ) = ? f ( x ) g(\boldsymbol{x})=\nabla f(\boldsymbol{x}) g(x)=?f(x),���㾫�� �� \varepsilon ��
���: f ( x ) f(\boldsymbol{x}) f(x)�ļ�Сֵ�� x ? \boldsymbol{x^*} x?����Ӧ�ļ�ֵ
ȡ��ʼֵ x 0 �� R n \boldsymbol{x_0} \in \mathbf{R}^{n} x0?��Rn, k = 0 k=0 k=0
���� f ( x k ) f(\boldsymbol{x_k}) f(xk?)
�����ݶ� g k = g ( x k ) g_k=g(\boldsymbol{x_k}) gk?=g(xk?),�� �O �O g k �O �O < �� ||g_k||<\varepsilon �O�Ogk?�O�O<��ʱ,ֹͣ����,�� x ? = x k \boldsymbol{x^*}=\boldsymbol{x_k} x?=xk?;����,��ݶȷ��� p k = ? g ( x k ) p_k=-g(\boldsymbol{x_k}) pk?=?g(xk?),�� �� k \lambda_k ��k?ʹ f ( x k + �� k p k ) = min ? �� �� 0 f ( x k + �� k p k ) f(\boldsymbol{x_k}+\lambda_k p_k)= \min\limits_{\lambda \geq 0} f(\boldsymbol{x_k}+\lambda_k p_k) f(xk?+��k?pk?)=����0min?f(xk?+��k?pk?)
x k + 1 = x k + �� k p k \boldsymbol{x_{k+1}} = \boldsymbol{x_k} + \lambda_k p_k xk+1?=xk?+��k?pk? ,���� f ( x k + 1 ) f(\boldsymbol{x_{k+1}}) f(xk+1?)
�� �O �O f ( x k + 1 ) ? f ( x k ) �O �O < �� ||f(\boldsymbol{x_{k+1}})-f(\boldsymbol{x_{k}})|| < \varepsilon �O�Of(xk+1?)?f(xk?)�O�O<�� �� $||\boldsymbol{x_{k+1}} - \boldsymbol{x_k}|| < \varepsilon $ ʱ,ֹͣ����,�� x ? = x k + 1 \boldsymbol{x^*}=\boldsymbol{x_{k+1}} x?=xk+1?��
����,ȡ k = k + 1 k=k+1 k=k+1,ת����3
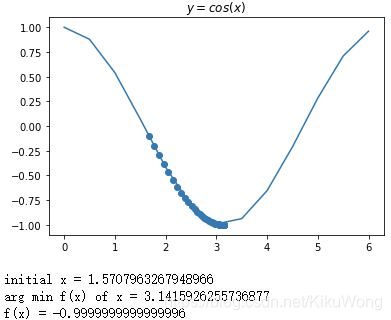
# ʹ���ݶ��½������� 𝑦=𝑐𝑜𝑠(𝑥) ������ 𝑥��[0,2𝜋] �ļ�Сֵ��
import numpy as np
import matplotlib.pyplot as plt
import math
# ���庯��:y=cos(x)
def f(x):
return np.cos(x)
# �Զ���ĺ�����(��Ԫ����ʱ��ƫ��)-�漰������ݶ�
def df(f, x, delta=1e-4):
'''
�����ĵڶ��ַ���:�ö���
'''
return (f(x+delta) - f(x-delta)) / (2 * delta)
# ���ӻ�����:y=cos(x)
xs = np.arange(0, 2*math.pi, 0.5)
plt.plot(xs, f(xs))
# ����ѧϰ��learning rate �� ����iterate����
learning_rate = 0.1
max_loop = 500
# ��ʼ�� x
x = 0.5*math.pi
x_list = [] # ÿ�θ��µ�����x��ֵ��������
# �����ݶ��½���-����
for i in range(max_loop):
df_x = df(f,x) # ��
x = x - learning_rate * df_x # �ݶ��½����Ĺ�ʽ
x_list.append(x)
# ���ӻ�ѧϰ����
x_list = np.array(x_list)
plt.scatter(x_list, f(x_list), c="r") # ɢ��
plt.title("$y = cos(x)$")
plt.show()
print('initial x =', x_init) # ��ӡ��ʼֵ
print('arg min f(x) of x =', x) # ��ӡʹf(x)��С��x��ֵ
print('f(x) =', f(x)) # ��ӡf(x)����Сֵ
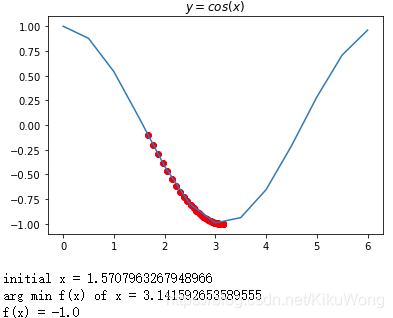
import numpy as np
import matplotlib.pyplot as plt
import math
# ���庯��:y=cos(x)
def f(x):
return np.cos(x)
# �Զ���ĺ�����(��Ԫ����ʱ��ƫ��)-�漰������ݶ�
def df(f, x, delta=1e-4):
'''
�����ĵڶ��ַ���:�ö���
'''
return (f(x+delta) - f(x-delta)) / (2 * delta)
# ���ӻ�����:y=cos(x)
xs = np.arange(0, 2*math.pi, 0.5)
plt.plot(xs, np.array(f(xs)))
# ����ѧϰ�� ��ʼ��x
learning_rate = 0.1 # Ҳ���Ը���ѧϰ��
x = 0.5*math.pi # �����ʼ����x,������ֵҲ����
x_list = [] # ÿ��x���º��ֵ��������б�����
y_list = [] # ÿ�θ���x��Ŀ�꺯����ֵ��������б�����
f_current = f_change = f(x)
iter_num = 0
while iter_num <=5000 and f_change > 1e-500: #��������С��5000�λ��ߺ����仯С��1e-500�η�ʱֹͣ����
iter_num += 1
x = x - learning_rate * df(f, x) # �ݶ��½����Ĺ�ʽ
tmp = f(x)
f_change = abs(f_current - tmp) # ����ֵ�ı仯
f_current = tmp # ������ĺ���ֵ
x_list.append(x)
y_list.append(f_current)
# ���ӻ�ѧϰ����
plt.scatter(x_list, y_list)
plt.title("$y = cos(x)$")
plt.show()
print('initial x =', x_init) # ��ӡ��ʼֵ
print('arg min f(x) of x =', x) # ��ӡʹf(x)��С��x��ֵ
print('f(x) =', f(x)) # ��ӡf(x)����Сֵ
�����ݶȵ��Ż������Cţ�ٵ�����
�ݶ��½���ֻ����һ������Ϣ,�����ٶ�����ͨ��,���ö�������Ϣ���Լӿ������ٶ�,���ʹ�����:ţ�ٷ�����ţ�ٷ���
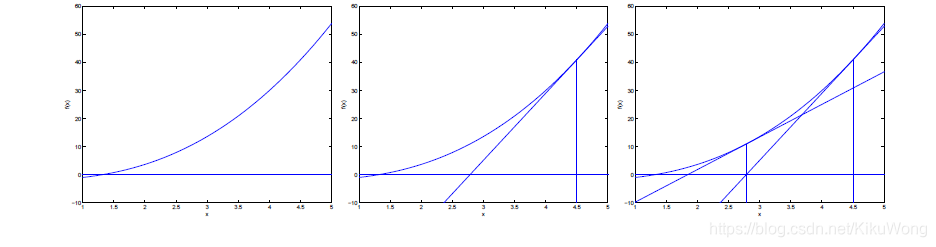
ţ�ٷ���ÿ�������㴦��Ŀ�꺯������Ϊ���κ���,Ȼ��ͨ������ݶ�Ϊ 0 \boldsymbol{0} 0�ķ��̵õ���������
ţ�ٷ���ÿ�ε���ʱ������ݶ�������Ŀ�꺯���ĺ�������������,����һ�����Է�����,�������������ٺ�������������⡣��ţ�ٷ��Ƕ����ĸĽ�,�㷨�����һ������������Ϊ����������������Ľ��ơ�
ţ�ٷ�:
ţ�ٷ�:�������Ŀ�꺯���ļ�Сֵ�ı�Ҫ����:
?
f
(
x
)
=
0
\nabla f(\boldsymbol{x})=0
?f(x)=0 ,ת������ʹĿ�꺯�����ݶ�(һ��)Ϊ0�IJ���ֵ��
�����Ĺ�ʽ����:
KaTeX parse error: No such environment: split at position 8: \begin{?s?p?l?i?t?}? \boldsymbol{x}��
������������ڵ�ǰλ��
x
0
x_0
x0?��ú���������,�����ߺ�x��Ľ���
x
1
x_1
x1?,��Ϊ�µ�
x
0
x_0
x0?,�ظ��������,ֱ������ͺ���������غϡ���ʱ�IJ���ֵ����ʹ��Ŀ�꺯��ȡ�ü�ֵ�IJ���ֵ��
�������������:
ţ�ٷ��㷨����:
����:Ŀ�꺯�� f ( x ) f(\boldsymbol{x}) f(x),�ݶȺ��� g ( x ) = ? f ( x ) g(\boldsymbol{x})=\nabla f(\boldsymbol{x}) g(x)=?f(x),�������� H ( x ) H(\boldsymbol{x}) H(x) ,���㾫�� �� \varepsilon ��
���: f ( x ) f(\boldsymbol{x}) f(x)�ļ�Сֵ�� x ? \boldsymbol{x^*} x?����Ӧ�ļ�ֵ
- ȡ��ʼֵ x 0 �� R n \boldsymbol{x_0} \in \mathbf{R}^{n} x0?��Rn, k = 0 k=0 k=0
- �����ݶ� g k = g ( x k ) g_k=g(\boldsymbol{x_k}) gk?=g(xk?)
- �� �O �O g k �O �O < �� ||g_k||<\varepsilon �O�Ogk?�O�O<��ʱ,��ֹͣ����,�ý��ƽ� x ? = x k \boldsymbol{x^*}=\boldsymbol{x_k} x?=xk?
- ���� H k = H ( x k ) H_k = H(\boldsymbol{x}_{k}) Hk?=H(xk?) ,����ţ�ٷ��� p k = ? H k ? 1 g k p_k=-{H_k}^{-1} g_k pk?=?Hk??1gk? # �� p k p_k pk?�ϸ���,���������Ľ�����
- x k + 1 = x k + �� k p k \boldsymbol{x_{k+1}} = \boldsymbol{x_k} + \lambda_k p_k xk+1?=xk?+��k?pk?
- ȡ k = k + 1 k=k+1 k=k+1,ת����2
ţ�ٷ����ݶ��½����ıȽ�
ţ�ٷ�:��ͨ�����Ŀ�꺯����һ����Ϊ0ʱ�IJ���,�������Ŀ�꺯����Сֵʱ�IJ�����
�����ٶȺܿ졣
��ɭ��������ڵ��������в��ϼ�С,��������С������Ч����
ȱ��:��ɭ���������㸴��,���۱Ƚϴ�,���������ţ�ٷ���
�ݶ��½���:��ͨ���ݶȷ���Ͳ���,ֱ�����Ŀ�꺯������Сֵʱ�IJ�����
Խ�ӽ�����ֵʱ,����Ӧ�ò��ϼ�С,�����������ֵ����������
���Դ���
���Դ������漰���Ļ�����������:
�����ռ䡢���������ڻ������������������(���ˡ��˷�������ʽ������ʽ����������������������)��������
������� ������Է����鼰���ռ䡢����ֵ����������������ļ��������͡���ͬ��������������Hesse����(��������)
������������ͳ��
����¼�����ʡ��������ʡ��¼������ԡ�ȫ���ʹ�ʽ�뱴Ҷ˹��ʽ
��������ɢ���������ʷֲ�/�����ܶȺ���/��ѧ����/����/Э����
���ؿ������ģ��
������Ȼ���ơ���Ҷ˹����
��ע��:ʱ���ˮƽ����,�ߴ�������֪ʶ���������
�ο�:���� ������ѧϰ����ѧ��