1. naive Bayes
���ʹ���
���ر�Ҷ˹���ǵ��͵�����ѧϰ����,���ɷ�����ѵ������ѧϰ���ϸ��ʷֲ� P ( X , Y ) P(X,Y) P(X,Y),Ȼ����ú�����ʷֲ� P ( Y �O X ) P(Y|X) P(Y�OX)��������˵,����ѵ������ѧϰ�������� P ( X �O Y ) P(X|Y) P(X�OY) �� ������� P ( Y ) P(Y) P(Y),�õ����ϸ��ʷֲ�:
P ( X , Y ) = P ( Y ) P ( X �O Y ) P(X,Y)=P(Y)P(X|Y) P(X,Y)=P(Y)P(X�OY)
���ʹ��Ʒ��������Ǽ�����Ȼ���ƻ�Ҷ˹����,��Ҷ˹���� ���� ������Ȼ���� �ϼ���һ������ �� \lambda ��,�� �� = 1 \lambda = 1 ��=1:
P ( Y = c k ) = �� i = 1 N I ( y i = c k ) + �� N + K �� \displaystyle P(Y=c_k) = \frac{\displaystyle \sum_{i=1}^N I(y_i=c_k) + \lambda}{N+K \lambda} P(Y=ck?)=N+K��i=1��N?I(yi?=ck?)+��?
P ( X ( j ) = a j l �O Y = c k ) = �� i = 1 N I ( x i ( j ) = a j l , y i = c k ) + �� �� i = 1 N I ( y i = c k ) + S j �� \displaystyle P(X^{(j)}=a_{jl}|Y=c_k) = \frac{\displaystyle \sum_{i=1}^N I(x_i^{(j)}=a_{jl},y_i=c_k)+ \lambda}{\displaystyle \sum_{i=1}^N I(y_i=c_k)+S_j \lambda} P(X(j)=ajl?�OY=ck?)=i=1��N?I(yi?=ck?)+Sj?��i=1��N?I(xi(j)?=ajl?,yi?=ck?)+��?
����, S j S_j Sj? Ϊ����ĵ� j ������������ȡֵ������, K K K Ϊ�������,�������Ա������Ϊ��������
��������
���ر�Ҷ˹���Ļ��������� ����������:
P ( X = x �O Y = c k ) = P ( X ( 1 ) = x ( 1 ) , ? ? , X ( n ) = x ( n ) �O Y = c k ) = �� j = 1 n P ( X ( j ) = x ( j ) �O Y = c k ) \begin{aligned} P(X&=x | Y=c_{k} )=P\left(X^{(1)}=x^{(1)}, \cdots, X^{(n)}=x^{(n)} | Y=c_{k}\right) \\ &=\prod_{j=1}^{n} P\left(X^{(j)}=x^{(j)} | Y=c_{k}\right) \end{aligned} P(X?=x�OY=ck?)=P(X(1)=x(1),?,X(n)=x(n)�OY=ck?)=j=1��n?P(X(j)=x(j)�OY=ck?)?
����һ����ǿ�ļ���,��Ҳ�dz�Ϊ���ص�ԭ��������һ����,ģ�Ͱ������������ʵ�������Ϊ����,������ر�Ҷ˹����Ч,������ʵ��,ȱ���Ƿ�������ܲ�һ���ܸߡ�
���� ���� ����������
���ر�Ҷ˹�����ñ�Ҷ˹������ѧ�������ϸ���ģ�ͽ��з���Ԥ�⡣
P ( Y �O X ) = P ( X , Y ) P ( X ) = P ( Y ) P ( X �O Y ) �� Y P ( Y ) P ( X �O Y ) P(Y | X)=\frac{P(X, Y)}{P(X)}=\frac{P(Y) P(X | Y)}{\sum_{Y} P(Y) P(X | Y)} P(Y�OX)=P(X)P(X,Y)?=��Y?P(Y)P(X�OY)P(Y)P(X�OY)?
������ x x x �ֵ�������������� y y y :
y = arg ? max ? c k P ( Y = c k ) �� j = 1 n P ( X j = x ( j ) �O Y = c k ) y=\arg \max _{c_{k}} P\left(Y=c_{k}\right) \prod_{j=1}^{n} P\left(X_{j}=x^{(j)} | Y=c_{k}\right) y=argck?max?P(Y=ck?)j=1��n?P(Xj?=x(j)�OY=ck?)
����������ȼ���0-1��ʧ����ʱ������������С����
ģ��
ģ��:��˹ģ�͡�����ʽģ�͡���Ŭ��ģ��
������ֵ��ȡֵ�������ʱ,���Լ�������ֵ�����п���ȡֵ�ĸ���;����������ȡֵ�� ���� �������,��Ҫ������ൽ��ͬ��ʱ,ÿһ������ȡֵ�ĸ����ܶȺ���,����������ȡֵ����Ϊ ��˹�����ܶȺ��� PDF
2. GaussianNB ��˹���ر�Ҷ˹
GaussianNB ��˹���ر�Ҷ˹��������ȡֵ�Ŀ�����Ϊ��˹�����ܶȺ���:
P ( x i �O y ) = 1 2 �� �� y 2 exp ? ( ? ( x i ? �� y ) 2 2 �� y 2 ) P(x_i \mid y) = \frac{1}{\sqrt{2\pi\sigma^2_y}} \exp\left(-\frac{(x_i - \mu_y)^2}{2\sigma^2_y}\right) P(xi?�Oy)=2����y2??1?exp(?2��y2?(xi??��y?)2?)
����, x i x_i xi?Ϊ������������ x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1?,x2?,...,xn? �еĵ� i i i ������, �� y \sigma_{y} ��y? ���� x x x �����ൽ y y y ��ʱ, x i x_i xi? �ķ���, �� y \mu_y ��y? ���� x i x_i xi? �ľ�ֵ,����������Ϊ�����Ȼ���Ƽ���õ��ġ�
2.1 ���ݼ�Ԥ����
ʹ�� iris �β�����ݼ�,20% ���������ڲ���:
import math
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, :])
return data[:, :-1], data[:, -1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
2.2 ���� NaiveBayes ģ��
ʹ�� naive bayes ����IJ�������:
- ���� label ��ǩ�����ݼ�����,label �ж�����ȡֵ�Ͱ����ݷ�Ϊ������
- ���� label ��ͬ����������,����ÿһ�������ľ�ֵ�ͷ���,���ڼ�����ڵ�����ȡֵ�ĸ����ܶȺ���(����ͼ��ʾ)
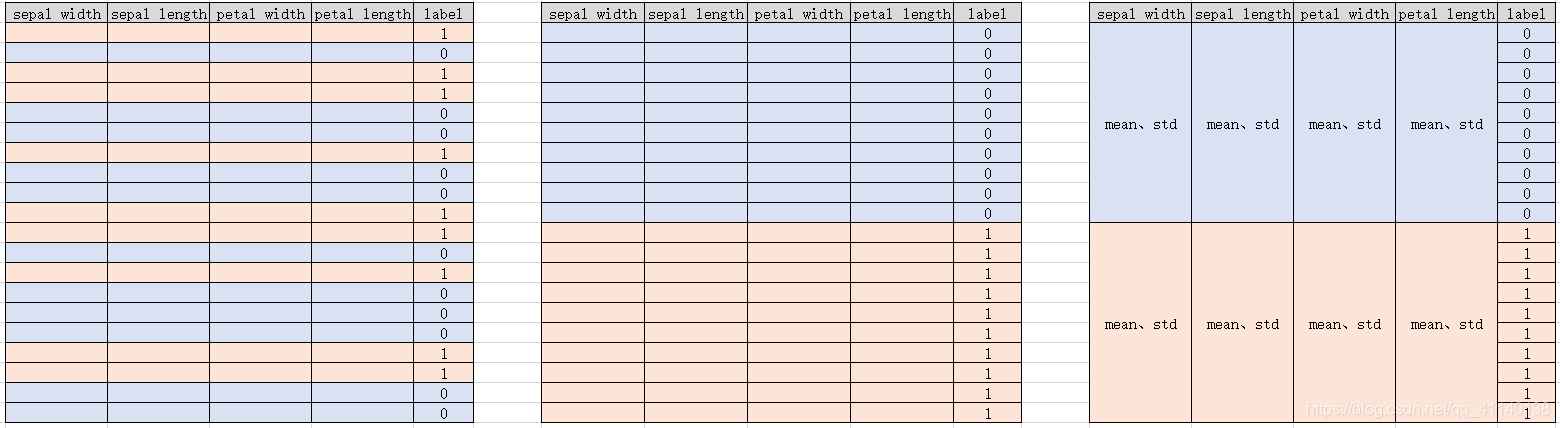
- �����������������,������ൽÿһ����ڵĸ���
- ѡ�������������ΪĿ����
Python ��������:
class NaiveBayes:
def __init__(self):
self.model = None
# Gaussian probability density function
def gaussian_pdf(self, x, mean, std):
exp_part = math.exp(-(math.pow(x-mean, 2))/(2*math.pow(std, 2)))
return 1/(math.sqrt(2*math.pi*std)) * exp_part
# caculate mean and std for each feature of each label
def summarize(self, train_data):
summeries = [(np.mean(i), np.std(i)) for i in zip(*train_data)]
return summeries
def fit(self, X, y):
# classify features by labels
labels = list(set(y))
data = {label: [] for label in labels}
for features, label in zip(X, y):
data[label].append(features)
# conditional probability
self.model = {
label: self.summarize(features)
for label, features in data.items()
}
return 'gaussian naive Bayes train done!'
def caculate_probabilities(self, input_data):
probabilities = {}
for label, value in self.model.items():
probabilities[label] = 1
for i in range(len(value)):
mean, std = value[i]
probabilities[label] *= self.gaussian_pdf(
input_data[i], mean, std)
return probabilities
def predict(self, X_test):
label = sorted(
self.caculate_probabilities(X_test).items(),
key=lambda x: x[-1])[-1][0]
return label
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
if y == self.predict(X):
right += 1
return right / float(len(X_test))
����,self.model �洢�˻��ֵ�ÿһ�����������ֵ�ľ�ֵ����,�൱�ڴ洢��ÿһ������ȡֵ����������(ѡ�����Ϊ����);
�������� zip() ����,�����Ժϲ������б�,*��������Բ��б�:
print(*[1, 2, 3]) # 1 2 3
a = zip([0, 1, 2], [3, 4, 5])
print(list(a)) # [(0, 3), (1, 4), (2, 5)]
a = [[0, 1], [2, 3], [4, 5]]
print(list(zip(*a))) # [(0, 2, 4), (1, 3, 5)]
2.3 ѵ����Ԥ��
# train
model = NaiveBayes()
model.fit(X_train, y_train)
# predict
print(model.score(X_test, y_test))
�õ��Ľ��Ϊ 1.0,ȷ�� 100% 🍻
3. scikit - learn ʵ��
scikit-learn ����� Gaussian Naive bayes:
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
clf = GaussianNB()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test)) # 0.933
print(clf.predict([X_test[0]])) # [1]
���� sklearn.datasets.load_iris �IJ��� return_X_y Ϊ True ��ʾ���� (data, target) ������һ������,��ʱѵ���������ݼ������� 3 ���β��,��ʱ��Ԥ��ɹ���Ϊ 93.3%
��� 🍻
REFERENCE
- �ͳ��ѧϰ����
- lihang-machine-learning-code
- scikit learn