西瓜书第一二章
第一章
相关概念
下面以使用范围较广的监督学习为例子,介绍机器学习的概念
数据集
- 训练集 有正确答案的,被标记的,用来学习,归纳的数据集。
- 测试集 没有正确答案的,没有标记的,用来测试模型的优劣的数据集。
对于非监督学习,训练集和测试集就没与什么区别了,只是使用时的目的不一样而已。
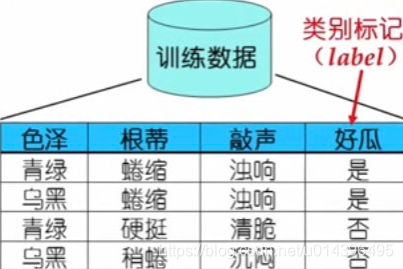
上图中数据的每一行,叫做一个示例(instance)、样例(example)、样本(sample)
前三列每一列的表头叫做:属性(attribute)、特征(feature)
每个样本的每一列上的值叫做:属性值、特征值
所有的属性构成一个属性空间,所有的样本构成一个样本空间,输入‘X’可能取值的集合就是输入空间(input space)
属性向量:每一个属性有一个列向量,这些列向量构建: [x1,x2,…xn] 成为一个特征向量
机器学习的整个流程:根据数据的类型,特点等,采用不同学习方法(监督与无监督)中不同的学习算法(learning algorithm)来进行训练,从而得到一个模型,然后对这个模型进行测试,然后改进、迭代。
模型/假设(hypothesis)/学习器(learner):估计函数,对规律和模式的预测
学习机(learner):使用的学习算法
真相(ground-truth):标签、标准答案
样本(sample) = 属性(attribute)/特征(feature)+标记/标签(label)
监督学习与非监督学习
监督学习
给定有标签的数据集,通过它学习输入与输出的对应关系
就像刷题一样,自己做题,然后根据给的答案(label)来不断调整自己的方法和思路,最终作出正确答案。
监督学习目前使用较为广泛
-
回归问题
预测连续值
根据数据样本上抽取的特征,预测连续值结果,如:房价多少,得分多少,GDP多少回归问题是在做计算题
-
分类问题
预测离散值根据数据样本上抽取出的特征,判定其属于有限个类别中的哪一个,比如:垃圾邮件识别(结果类别:yes or no),文本情感褒贬识别(结果类别:褒、贬),图像内容识别(结果类别:猫,狗,人,其他)
分类问题是在做选择题
非监督学习
给定数据集,没有标签,期望模型学习到数据的结构特征
无监督学习没有给出“正确的答案”(标签),而是只有数据,通过程序自己去挖掘数据具有的特征。
聚类算法:将数据分成几类,根据数据样本抽取出的特征,挖掘数据的关联、聚合模式。
第二章
过拟合和欠拟合
过拟合(Overfitting):学习器将训练样本学的太好,导致泛化性能下降。过拟合无法避免只能缓解
欠拟合(Underfitting):学习器学习能力低下造成
评估方法
通常机器学习中,用训练集训练学习方法然后测试集测试学习器对样本的判别能力,以测试集上的测试误差作为泛化误差近似。本节提到几个如何划分测试集和训练集的方法。
- 留出法(handout)
- 保持数据分布的一致性,保持用于学习的数据集与用于测试的数据集的分布特征一致(例如:分层采样)
- 多次重复划分
- 测试集不能太大,也不能太小(例如:1/5~1/3)
- k 折交叉验证法(cross validation)
- 留出法总归是使用了一部分数据,没有测试全部数据,因此 k 折交叉验证就是解决这个问题。
- 假设将数据集分成 k = 10 份,第一次使用 D10 作为测试集,第二次使用 D9 作为测试集,直至每个都当过测试集,然后将 k 个结果求平均,就是最终结果。
- 自助法(bootstrap )
- 基于”自助采样“的方法,也称:“有放回采样”、“可重复采样”
- 对数据集进行有放回采样,并且采样出的集合与原样本集同规模,但是数据分布有所改变
各种性能度量概念
- 均方误差
- 错误度与精度
- 查准率,查全率