������Ϊ�Լ�ѧϰ�������ʦ2021������ѧϰ�γ������ʼ�,��¼�Լ���Ϊ���Ž�С��ѧϰ����,�����©������,�����λ���Ѳ���ָ��,��л!!
��������ģ��
��������ģ��(Probabilistic Generative Model)�������ģ��,ָһϵ������������ɿɹ۲����ݵ�ģ�͡�
������һ����������ɢ�ĸ�ά�ռ� X \mathcal{X} X��,����һ��������� X \mathnormal{X} X����һ��δ֪�����ݷֲ� p r ( x ) , x �� X p_r(x), x \in \mathcal{X} pr?(x),x��X������ģ����һЩ�ɹ۲������ x ( 1 ) , x ( 2 ) , ? ? , x ( N ) x^{(1)},x^{(2)}, \cdots ,x^{(N)} x(1),x(2),?,x(N)��ѧϰһ����������ģ�� p �� ( x ) p_\theta(x) p��?(x)������δ֪�ֲ� p r ( x ) p_r(x) pr?(x),�����������ģ��������һЩ����,ʹ�����ɵ���������ʵ�����������ܵ����ơ�
����ģ�͵�������������:�����ܶȹ�������������(������)��
��ʽ�ܶ�ģ��
������ģ�͵���������������,���ֻ��ϣ��һ��ģ�������ɷ������ݷֲ� p r ( x ) p_r(x) pr?(x)������,���Բ���ʾ�Ĺ��Ƴ����ݷֲ����ܶȺ�����
�����ڵ�ά�ռ� Z \mathcal{Z} Z����һ�������ײ����ķֲ� p ( z ) p(z) p(z), p ( z ) p(z) p(z)ͨ��Ϊ����Ԫ��̬�ֲ� N ( 0 , I ) \mathcal{N}(0,\mathnormal{I}) N(0,I),�����������繹��һ��ӳ�亯�� G : Z �� X G : \mathcal{Z} \rightarrow \mathcal{X} G:Z��X,��Ϊ�������硣����������ǿ����������,ʹ�� G ( z ) G(z) G(z)�������ݷֲ� p r ( x ) p_r(x) pr?(x)������ģ�;ͳ�Ϊ��ʽ�ܶ�ģ��(Implicit Density Model)��
��ʽ�ܶ�ģ�����������Ĺ�������ͼ��ʾ:
���ɶԿ�����
���ɶԿ�����(Generative Adversarial Networks,GAN)��һ����ʽ�ܶ�ģ��,�����б�����(Discriminator Network)����������(Generator Network)��������,ͨ���Կ�ѵ���ķ�ʽ��ʹ�������������������������ʵ���ݷֲ���
�����ɶԿ�������:
- �б�����:Ŀ���Ǿ���ȷ���ж�һ����������������ʵ���ݻ������������������
- ��������:Ŀ���Ǿ��������б�������������Դ��������
���ɶԿ������ѵ������
��ѵ��������,���б���������������������粻�ϵؽ��н���ѵ�������������ʱ,����б�������Ҳ���ж�һ����������Դ,��ôҲ�͵ȼ�����������������ɷ�����ʵ���ݷֲ������������ɶԿ����������ͼ����ͼ��ʾ:

���������ʦ���ٵ����ɶ���Ԫͷ��������������ɶԿ������ѵ������:
Step 1:�̶���������,ѵ���б�����
���������������б���������ij�ʼ��֮��,�̶�ס��������,���ǽ��ӷֲ� p ( z ) p(z) p(z)�в����������������뵽����������,�õ���Ӧ�����(ͼƬ)��
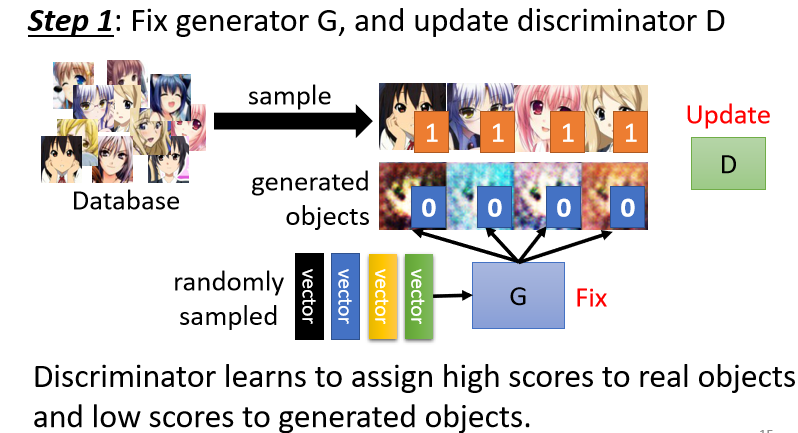
�����õõ����������������Ķ���Ԫͷ����ѵ���б�����,Ŀ�������б�����ѧϰ������ͼƬ֮��IJ���,�Ӷ����Խ����ǽ������֡�������˵,���ǿ��Խ������Ķ���Ԫͷ��ͼƬ��Ϊ1,�����������������Ϊ0��������,���Ǽȿ��Խ��˿���һ����������,Ҳ���Կ���һ���ع�����:
- ��������:��������ͷ�������1,�������������ͼ�������2,Ȼ��������ЩͼƬѵ��һ����������
- �ع�����:ѵ���б����翴��������ͷ��ͼƬʱ���1,���������������ɵ�ͷ��ͼƬʱ���0,��ѧϰ����֮��IJ��졣
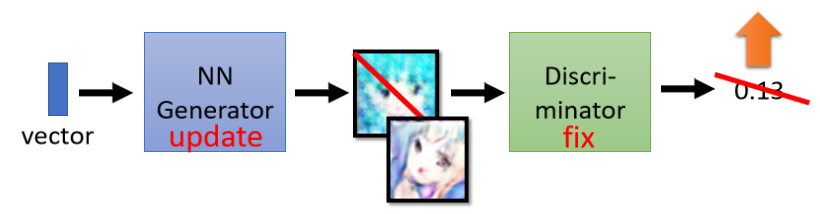
Step 2: �̶��б�����,ѵ����������
�������������������ͼƬ���뵽�б�������,����ѵ����Ŀ���������б���������ֵԽ��Խ�����б�������ѵ���Ĺ����о��ǿ����õ�ͼƬ������ķ���,�������������������������ͼƬ���б������еõ��߷�,����ζ�������������ɵ�ͼƬ�DZȽ���ʵ�ġ�
�����ѵ��������,���Կ�����Generator��Discriminatorƴ�ӳ�һ�����������,����������������,���ǹ̶�ס����Discriminator�����ز�IJ���,ֻ��������Generator�����ز�IJ�����Generator��Discriminatorƴ�ӵ��м䲿����һ���ܿ����м��,�ڸò���,���ǽ�Generator����Ľ��������ͼƬ����ʽ���뵽Discriminator�еõ�����÷֡�
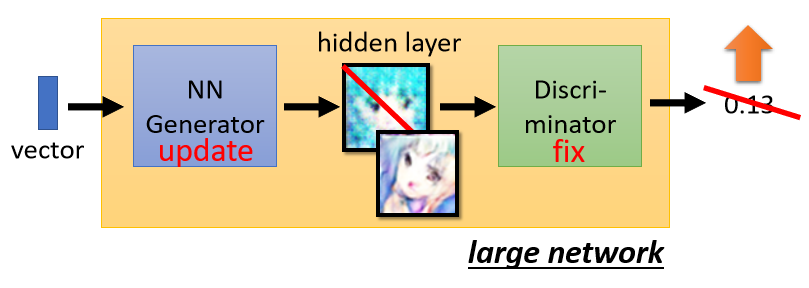
��������
������ѵ��һ�������ʱ��,������˼·��:
- ȷ��һ��Loss Function
- ʹ��Gradient Descent ���ڲ���
- Ȼ����С��Loss Function�Ϳ�����
��������������,����ҪMinimize����Maximize��Ŀ����ʲô��?�ڸ�������,�������������Normal Distribution �в�������������,�õ�һ���Ƚϸ��ӵķֲ�
p
��
(
x
)
p_\theta(x)
p��?(x),����ʵ�������γ���һ���ֲ�
p
r
(
x
)
p_r(x)
pr?(x)����ô������������,���ǵ�Ŀ�������
p
��
(
x
)
p_\theta(x)
p��?(x)��
p
r
(
x
)
p_r(x)
pr?(x)Խ�ӽ�Խ��,����Ϊ���¹�ʽ:
G
?
=
a
r
g
min
?
G
D
i
v
(
p
��
,
p
r
)
(1)
G^*=arg\min_{G}Div(p_\theta, p_r) \tag{1}
G?=argGmin?Div(p��?,pr?)(1)
����
D
i
v
Div
Div��ʾ
p
��
(
x
)
p_\theta(x)
p��?(x)��
p
r
(
x
)
p_r(x)
pr?(x)�����ֲ�֮���ɢ��(Divergence)��ɢ���Ǻ��������ֲ�֮�����ƶȵı�,ɢ��Խ��,��ʾ�����ֲ�Խ����,ɢ��ԽС,��ʾ�����ֲ�Խ������,��������������ķֲ��ϵ�ɢ��,�����������������,��ͻ����һ�������Ƶķ������Ǻ��б����罻��ѵ������Ż���
�����
�������һ����������,���б�������,����һ������
(
x
,
y
)
(x,y)
(x,y),
y
=
{
1
,
0
}
y=\{1,0\}
y={1,0}��ʾ����������ʵ�ֲ�
p
r
(
x
)
p_r(x)
pr?(x)��������ģ��
p
��
(
x
)
p_\theta(x)
p��?(x),�������
D
(
x
;
?
)
D(x;\phi)
D(x;?)���������
x
x
x������ʵ���ݷֲ��ĸ���:
p
(
y
=
1
�O
x
)
=
D
(
x
;
?
)
(2)
p(y=1|x)=D(x;\phi) \tag{2}
p(y=1�Ox)=D(x;?)(2)
��������������ģ�͵ĸ���Ϊ:
p
(
y
=
0
�O
x
)
=
1
?
D
(
x
;
?
)
(3)
p(y=0|x)=1 - D(x;\phi) \tag{3}
p(y=0�Ox)=1?D(x;?)(3)
����,�б������Ŀ�꺯��Ϊ��С��������,��:
min
?
?
?
(
E
x
[
y
l
o
g
p
(
y
=
1
�O
x
)
+
(
1
?
y
)
l
o
g
p
(
y
=
0
�O
x
)
]
)
(4)
\min_{\phi}- (\mathbb{E}_x[ylog p(y=1|x)+(1-y)logp(y=0|x)]) \tag{4}
?min??(Ex?[ylogp(y=1�Ox)+(1?y)logp(y=0�Ox)])(4)
����ֲ�
p
(
x
)
p(x)
p(x)���ɷֲ�
p
r
(
x
)
p_r(x)
pr?(x)�ͷֲ�
p
��
(
x
)
p_\theta(x)
p��?(x)�ȱ�����϶���,��
p
(
x
)
=
1
2
(
p
r
(
x
)
+
p
��
(
x
)
)
p(x)=\frac{1}{2}(p_r(x)+p_\theta(x))
p(x)=21?(pr?(x)+p��?(x)),����ʽ�ȼ���:
max
?
?
V
(
D
,
G
)
=
max
?
?
E
x
��
p
r
(
x
)
[
l
o
g
D
(
x
;
?
)
]
+
E
x
��
��
p
��
(
x
��
)
[
l
o
g
(
1
?
D
(
x
��
;
?
)
)
]
=
max
?
?
E
x
��
p
r
(
x
)
[
l
o
g
D
(
x
;
?
)
]
+
E
z
��
p
(
z
)
[
l
o
g
(
1
?
D
(
G
(
z
;
��
)
;
?
)
)
]
(5)
\begin{aligned} &\max_\phi V(D,G) \\ =&\max_{\phi} \mathbb{E}_{x \sim p_r(x)}[logD(x;\phi)]+\mathbb{E}_{x' \sim p_\theta(x')}[log(1-D(x';\phi))] \\ =& \max_{\phi}\mathbb{E_{x \sim p_r(x)}}[logD(x;\phi)] + \mathbb{E}_{z \sim p(z)}[log(1-D(G(z;\theta); \phi))] \end{aligned} \tag{5}
==??max?V(D,G)?max?Ex��pr?(x)?[logD(x;?)]+Ex����p��?(x��)?[log(1?D(x��;?))]?max?Ex��pr?(x)?[logD(x;?)]+Ez��p(z)?[log(1?D(G(z;��);?))]?(5)
- E x �� p r ( x ) \mathbb{E}_{x \sim p_r(x)} Ex��pr?(x)?:������ʵ��ͼ���������뵽�б�������,�õ�һ��������ȡ l o g D ( x ; ? ) logD(x;\phi) logD(x;?),Ϊ���ù�ʽ(5)�е�Ŀ�꺯��Խ��,�����ֵԽ��Խ����
- E z �� p ( z ) \mathbb{E}_{z \sim p(z)} Ez��p(z)?:�������ɵ�ͼ���������뵽�б�������,�õ�һ��������ȡ l o g ( 1 ? D ( G ( z ; �� ) ; ? ) ) log(1-D(G(z;\theta); \phi)) log(1?D(G(z;��);?)),Ϊ���ù�ʽ(5)�е�Ŀ�꺯��Խ��,�����ֵԽСԽ����
������GANԭʼ��Paper,����Ĺ�ʽ(5)�õ��Ľ����ʽ(1)�е�ɢ����ʵ����ص�������ͼ��ʾ:
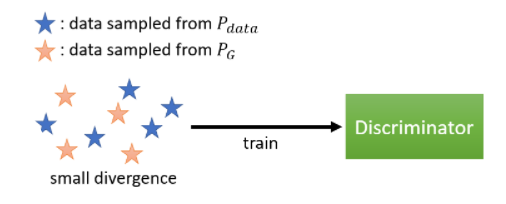
ͼ�� P d a t a P_{data} Pdata?��ʾ��ʵ�ֲ�, P G P_G PG?��ʾ�����������ķֲ����ڸ�ͼ��,ֱ�۵���˵,�����ֲ���ɢ�ȱȽ�С,������ʵͼ�����ɫ���Ǻʹ�������ͼ��ĺ�ɫ���������һ��,����ʹ���б��������ѽ���ֿ�,���������ڽ�����Ż������ʱ��,��û�а취�����Ŀ�꺯����ֵ�dz��Ĵ�,���յõ��Ĺ�ʽ(5)��ֵ�ͱȽ�С��
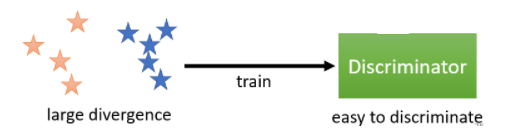
�ڸ�ͼ��,�������ݺܲ���,���ǵ�ɢ�Ⱥܴ�,��������ʹ���б�����������Ľ����Ƿֿ�,��ʱ��Ŀ�꺯����ֵҲ�ͱ�ĺܴ���������,С�Ĺ�ʽ(5)��ֵ��ӦС��ɢ��,��Ĺ�ʽ(5)��ֵ��Ӧ���ɢ�ȡ�
��Ȼ��ʽ(5)�е�Ŀ�꺯���ͺ����ֲ������ɢ�����,�����������滻:
G
?
=
a
r
g
min
?
G
max
?
D
V
(
G
,
D
)
(6)
G^* = arg \min_{G}\max_{D}V(G,D) \tag{6}
G?=argGmin?Dmax?V(G,D)(6)
�����������������Ҫ���Ŀ�꺯����,����������������������б����罻��ѵ����ɵġ�
�����:
�������������ѧϰ�� ������