�˹����ܵ��˳�����ϯ��ȫ��,���ʻ�ʱ�����������Ƕ���:�˹�����(Artificial Intelligence)������ѧϰ(Machine Learning)�����ѧϰ(Deep Learning)��������Ҫ�Ƕ������γ����ݽ��бʼ�����,�ο���������ĩ�Ѿ�������
3-�ع�
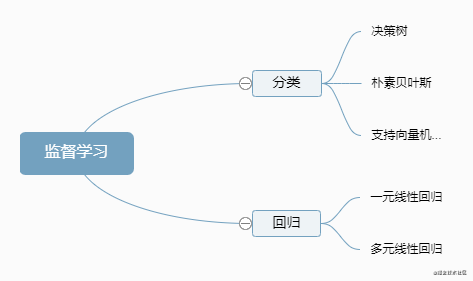
���Իع�Ķ���
���Իع�Ķ�����:Ŀ��ֵԤ�������������������ϡ�����˵,����ѡ��һ�����Ժ������ܺõ������֪���ݲ�Ԥ��δ֪���ݡ�
�ع������,ֻ����һ���Ա�����һ�������,�Ҷ��ߵĹ�ϵ����һ��ֱ�߽��Ʊ�ʾ,���ֻع������ΪһԪ���Իع����������ع�����а����������������ϵ��Ա���,����������Ա���֮�������Թ�ϵ,���Ϊ��Ԫ���Իع������
Ӧ�þ���
- ����Ԥ��(Stock market forecast)
- ����:��ȥ10���Ʊ�ı䶯��������ѯ����˾������ѯ��
- ���:Ԥ����������ƽ��ֵ
- �Զ���ʻ(Self-driving Car)
- ����:���˳��ϵĸ���sensor������,����·��������ij����
- ���:�����̵ĽǶ�
- ��Ʒ�Ƽ�(Recommendation)
- ����:��ƷA������,��ƷB������
- ���:������ƷB�Ŀ�����
- Pokemon���鹥����Ԥ��(Combat Power of a pokemon):
- ����:����ǰ��CPֵ������(Bulbasaur)��Ѫ��(HP)������(Weight)���߶�(Height)
- ���:�������CPֵ
ģ�Ͳ��轲��
- step1:ģ�ͼ���,ѡ��ģ�Ϳ��(����ģ��)
- step2:ģ������,����ж��ڶ�ģ�͵ĺû�(��ʧ����)
- step3:ģ���Ż�,���ɸѡ���ŵ�ģ��(�ݶ��½�)
������������һ������ѧϰ����IJ���,������step��������:ѡ��һ��ģ�Ϳ��,Ȼ��ʼѵ��,����ģ�ͺû�����ʹ����ʧ��������,Ϊ��ʹ��ʧ������С,����ʹ�����ݶ��½����������ʧ��������Сֵ��Ҫ���һ������ѧϰ����,��Ҫ������µIJ���:
- �����ռ�:�˲���������Ҫ,��Ϊ���ռ����ݵ����������������������Ԥ��ģ�͵�ȷ�ԡ�
- ������:һ���ռ�������,����Ҫ������ص�ϵͳ��,��Ϊ����ѧϰѵ��������,�����е�ʱ�������ռ��������ݿ��ܻ��н϶����õ�����,�����Ǹ�����,����Ҫ����ʵ��������������������������������Ӧ�����ӻ���ɾ����
- ѡ����ʵ�ģ��:�������Ƕ�����������Լ�����,ѡ����ʵ�ѵ��ģ�͡�
- ѵ��ģ��:ʹ�����ݽ�һ��������ģ�͵�����,��ģ�ͽ���ѵ����
- ����ģ��:���۹�����Ҫ���ģ���Ƿ�õ���Ч��ѵ�����Ƿ�����������ͨ�����ַ���,������������ѵ����δ���ֹ�������������ģ�͡�������Ϊ�˲���ģ�������Ӧ��δ����������,����������Ϊ�˷���ģ�͵���Ӧ������
- ����������:����Ϊ�˼������ѵ����ģ���Ƿ����иĽ�����ء�����ͨ������ijЩ����(ѧϰ�ʻ���ѵ��������ѵ��ģ�����еĴ���)��ʵ�֡���ѵ���ڼ�,��Ҫ���Ƕ������������ÿ������,��Ҫ֪��������ģ��ѵ�������������,���������ܻᷢ���Լ����˷�ʱ������κ��ʱ�����ˡ�
- Ԥ��:���һ��,һ����ѭ����������,�Ϳ��Զ�ģ�ͽ��в��ԡ�
Step 1:ģ�ͼ��� - ����ģ��
һԪ����ģ��(��������)
����: Ҳ��һԪ���Իع�,һԪ���Իع��Ƿ���ֻ��һ���Ա�������һ������ֵԤ��һ�����ֵ,����/����Ķ�Ӧ��ϵ����һ�����Ժ�����
����ģ�ͼ��� y = b + w ? x c p y=b+w*x_{cp} y=b+w?xcp?���� w�� b���Բ²�ܶ�ģ��
��Ԫ����ģ��(�������)
����: �ڻع������,������������������ϵ��Ա���,�ͳ�Ϊ��Ԫ�ع顣�������������漰�������ʱ,��������ͱ���Ϊ��Ԫ���Իع顣
��ʵ��Ӧ����,���������϶���ֹ$ x_{cp}$��һ��������,�γ��н��ı����ν���ǰ��CPֵ������(Bulbasaur)��Ѫ��(HP)������(Weight)���߶�(Height)��,�������кܶࡣ
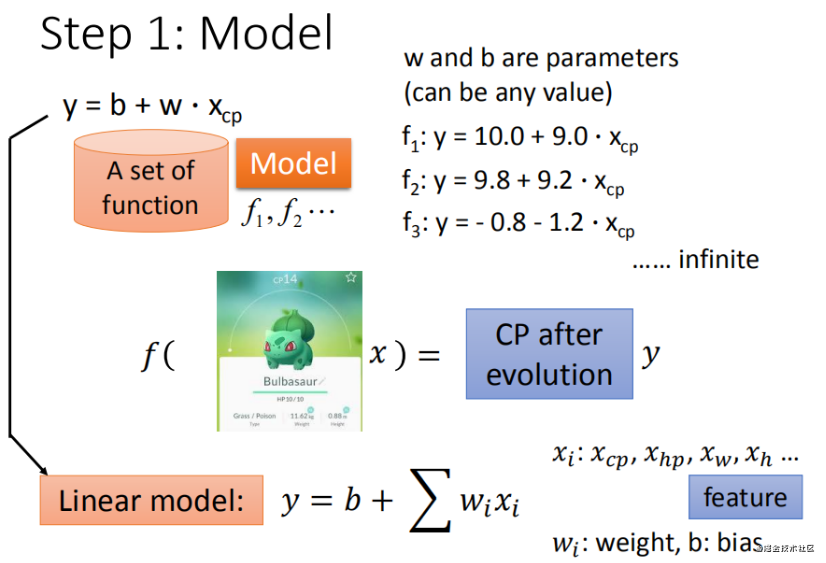
�������Ǽ��� ����ģ�� Linear model:
y
=
b
+
��
w
i
x
i
y = b + \sum w_ix_i
y=b+��wi?xi?
- X i X_i Xi?:���Ǹ�������(feature) X c p , X h p , X w , X h X_{cp},X_{hp},X_w,X_h Xcp?,Xhp?,Xw?,Xh?��
- W i W_i Wi?:����������Ȩ�� W c p , W h p , W w , W h W_{cp},W_{hp},W_w,W_h Wcp?,Whp?,Ww?,Wh?��
- b b b:ƫ����
Step 2:ģ������ - ��ʧ����
����: ��ʧ���� (Loss Function) Ҳ�ɳ�Ϊ���ۺ��� (Cost Function)������(Error Function),���ں���Ԥ��ֵ��ʵ��ֵ��ƫ��̶���һ����˵,�����ڽ��л���ѧϰ����ʱ,ʹ�õ�ÿһ���㷨����һ��Ŀ�꺯��,�㷨���Ƕ����Ŀ�꺯�������Ż�,�ر����ڷ�����ع�������,����ʹ����ʧ����(Loss Function)��Ϊ��Ŀ�꺯��������ѧϰ��Ŀ�����ϣ��Ԥ��ֵ��ʵ��ֵƫ���С,Ҳ����ϣ����ʧ������С,Ҳ������ν����С����ʧ������
��ʧ��������������ģ�͵�Ԥ��ֵ y ^ = f ( X ) \widehat{y}=f(X) y ?=f(X)����ʵֵ Y Y Y�IJ�һ�³̶�,����һ���Ǹ�ʵֵ������ͨ��ʹ�� L ( Y , f ( x ) ) L(Y,f(x)) L(Y,f(x))����ʾ,��ʧ����ԽС,ģ�͵����ܾ�Խ�á�
��ʧ����������: ����ģ��ģ��Ԥ��ĺû�
ͳ��ѧϰ�г��õ���ʧ���������¼���:
- 0-1��ʧ����(0-1 lossfunction):
L ( Y , f ( X ) ) = { 1 , Y �� f ( X ) 0 , Y = f ( X ) L(Y,f(X))=\left\{ \begin{aligned}&1,\quad Y\ne f(X)\\& 0,\quad Y=f(X) \end{aligned} \right. L(Y,f(X))={?1,Y��?=f(X)0,Y=f(X)?
����ʧ�������������,��Ԥ�����ʱ,��ʧ����ֵΪ1,Ԥ����ȷʱ,��ʧ����ֵΪ0������ʧ����������Ԥ��ֵ����ʵֵ�����̶�,Ҳ����ֻҪԤ�����,Ԥ������һ��Ͳ�ܶ���һ���ġ�
- ƽ����ʧ����(quadraticloss function)
L ( Y , f ( X ) ) = ( Y ? f ( X ) ) 2 L(Y,f(X))=(Y-f(X))^2 L(Y,f(X))=(Y?f(X))2
����ʧ����������Ҳ�ܼ�,����ȡԤ�����ƽ��,Ҳ����ʵ�ʽ���۲���֮�����ƽ����,һ���������Իع���,��������Ϊ��С���˷�
- ������ʧ����(absoluteloss function)
L ( Y , f ( X ) ) = �O Y ? f ( X ) �O L(Y,f(X))=|Y-f(X)| L(Y,f(X))=�OY?f(X)�O
����ʧ�����������������,ֻ������ȡ�˾���ֵ�����������ֵ,���ᱻƽ���Ŵ�
- ������ʧ����(logarithmicloss function)�������Ȼ��ʧ����(log-likelihood loss function)
L ( Y , P ( Y �O X ) ) = ? l o g P ( Y �O X ) L(Y,P(Y|X))=-logP(Y|X) L(Y,P(Y�OX))=?logP(Y�OX)
�����ʧ�����ͱȽ��������ˡ���ʵ��,����ʧ�����õ��˼�����Ȼ���Ƶ�˼�롣 P ( Y �O X ) P(Y|X) P(Y�OX)ͨ�Ľ��;���:�ڵ�ǰģ�͵Ļ�����,��������X,��Ԥ��ֵΪY,Ҳ����Ԥ����ȷ�ĸ��ʡ����ڸ���֮���ͬʱ������Ҫʹ�ó˷�,Ϊ�˽���ת��Ϊ�ӷ�,���ǽ���ȡ�����������������ʧ����,����Ԥ����ȷ�ĸ���Խ��,����ʧֵӦ����ԽС,����ټӸ�����ȡ����
Step 3:���ģ�� - �ݶ��½���
�ݶ��½��ǵ�������һ��,�ǽ��������Ժͷ�������С��������ķ���֮һ���������������ʧ��������Сֵ,ͨ���ݶ��½�����һ�����ص������,�õ���С������ʧ������ģ�Ͳ���ֵ��
����㷽�������мı�ʾ: a n + 1 = a n ? �� ? a n �� a_{n+1}=a_n-\eta*\overrightarrow{a_n} an+1?=an??��?an??
�� \eta ��:��ʾ��������ѧϰ��lr����ÿһ���߹��ľ��������
������һ������:ΪʲôҪ��-k
��:����Ҫ����С�ݶ�,������֮�����Һ�������͵�,�����������ѧ˼ά������,�Ե�ǰ������,�������С��0,��ʾ��͵��ڸõ���Ҳ�,����Ϊ����,��-k��Ϊ����w��ֵ,����������0,��ʾ��͵��ڸõ�����,����Ϊ����,��-k��Ϊ��Сw��ֵ��
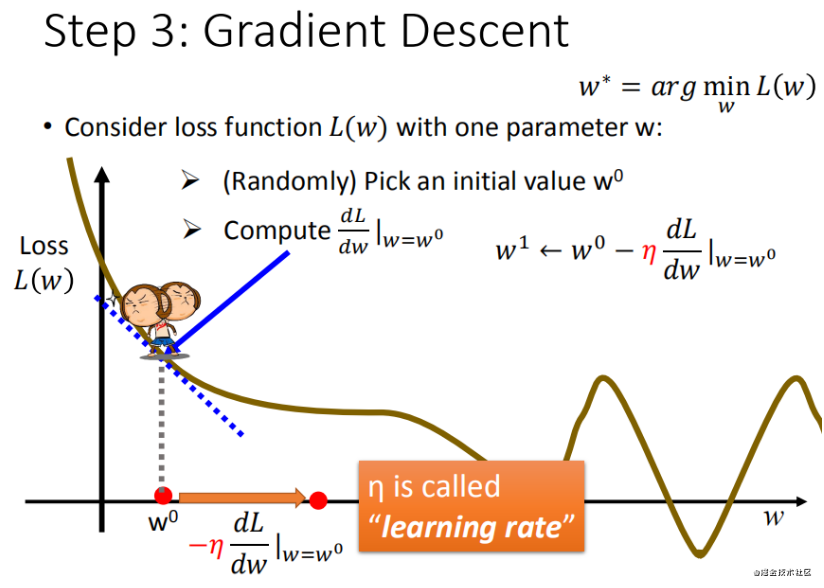
- ����1:���ѡȡһ�� w 0 w^0 w0
- ����2:������,Ҳ���ǵ�ǰ��б��,����б�����ж��ƶ��ķ���
- ����0�����ƶ�(��Сw)
- С��0�����ƶ�(����w)
- ����3:����ѧϰ���ƶ�
- �ظ�����2�Ͳ���3,ֱ���ҵ���͵�
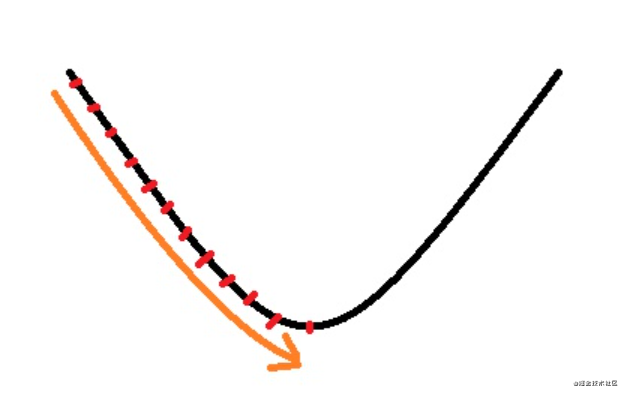

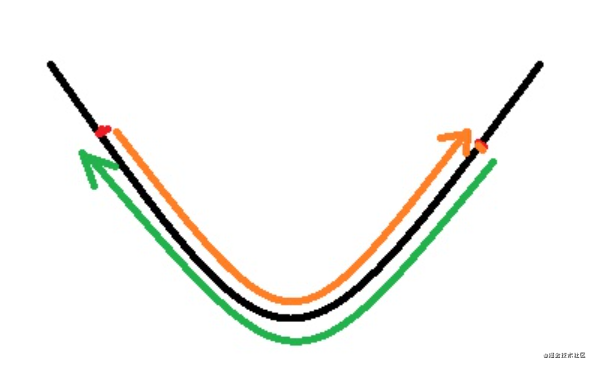
ʵ������ѧϰ������,����Ӧ�ý�ѧϰ�ʵ���ֵ��֮�������������Ӷ���С
�����е�ʱ��������ôһ������,�㵱ǰ�ﵽ�����ŵ�,��һ�������ȫ�����ŵ�,�������Ǿֲ����ŵ�,����ͼ��ʾ:
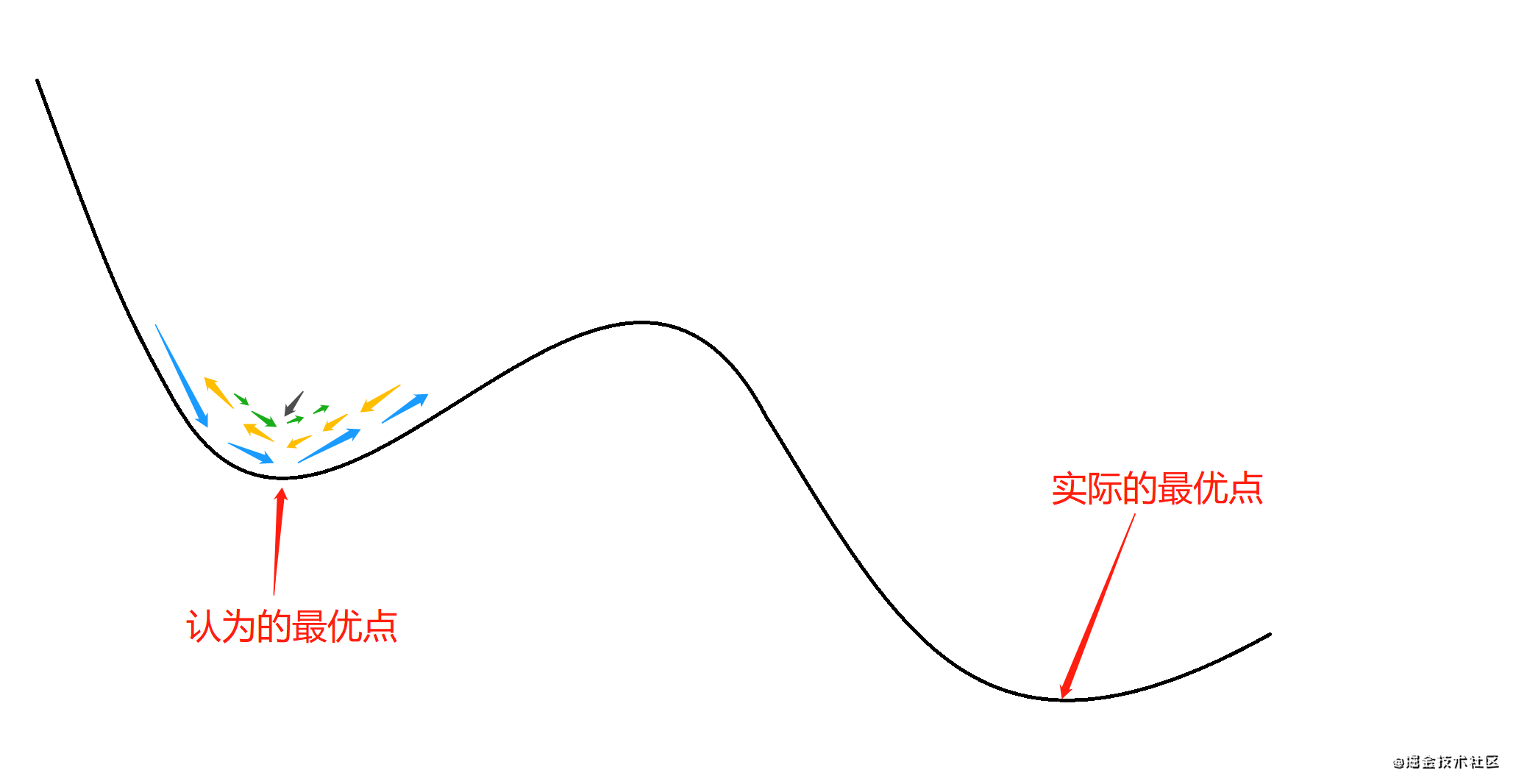
��ʵ������,���dz��������²�������ͼ���������ֲ���Сֵ,�Ӷ��ﵽȫ����Сֵ:
- �Զ��鲻ͬ����ֵ��ʼ�����������,��������ѵ����,ȡ���������С�Ľ���Ϊ���ղ���,���൱�ڴӶ����ͬ�ij�ʼ���㿪ʼ����,�Ӷ�����Ѱ��ȫ�����š�
- ʹ��ģ���˻�����,ģ���˻���ÿһ������һ���ĸ��ʽ��ܱȵ�ǰ�����Ľ��,�Ӷ������ڡ��������ֲ���С����ÿ������������,���ܡ����Ž⡱�ĸ�������ʱ������ƶ�����,�Ӷ���֤�㷨���ȶ���
- ʹ������ݶ��½�,������ݶ��½�����ȷ�����ݶȲ�ͬ,����ݶ��½����ڼ����ݶ�ʱ��������������ء�����,��������ֲ���С��,����������ݶ�ʱ�������������,����,��������ֲ���С��,����������ݶȿ��ܲ�Ϊ0,�������л��������ֲ���С����������
�����֤ģ�ͺû�
- ����ѵ�����Ͳ��Լ�
- ���۷�����:���ȡ����������ʡ��ٻ��ʡ�F1 Score��ROC���ߵ�
- ���ۻع���:MSE��RMSE��MAE��R Squared
������������
��ģ����,�����ٿ��Խ�һ���Ż�,ʹ�ø��ߴη���ģ�͡����ǻᷢ����ѵ����������ָ�Ϊ�����ģ��,Ϊʲô�ڲ��Լ���Ч�����������?�����ģ����ѵ�����Ϲ���ϵ����⡣
�������ʽ��ͼ�λ�չʾ,����3�η����ϵ�ģ��,�Ѿ������˹���ϵ�����:

����ѵ�����̵Ľ���,ģ���Ӷ�,��training data�ϵ�error������С����������֤���ϵ�errorȴ����������������ѵ������������������ѵ����,��ѵ�������������ȴ��work��
�ڻ���ѧϰ�㷨��,���Ǿ�����ԭʼ���ݼ���Ϊ������:ѵ����(training data)����֤��(validation data)�����Լ�(testing data)��
����:��֤����ʲô?
����ʵ�Ͼ��������������ϵġ���ѵ��������,����ͨ����ʹ������ȷ��һЩ������(�ȷ�,����validation data�ϵ�accuracy��ȷ��early stopping��epoch��С������validation dataȷ��learning rate�ȵ�)����Ϊɶ��ֱ����testing data������Щ��?���ڼ�����testing data����Щ,��ô����ѵ���Ľ���,���ǵ�����ʵ���Ͼ�����һ��һ��ع�������ǵ�testing data,�������õ���testing accuracyû��ʲô�������塣���,training data�������Ǽ����ݶȸ���Ȩ��,testing data�����һ��accuracy���ƶ�����ĺû���
��ֹ����Ϸ�����Ҫ��:
- ����(Regularization)(L1��L2)
- ������ǿ(Data augmentation),Ҳ��������ѵ����������
- Dropout
- early stopping
������Բο�:https://blog.csdn.net/u010899985/article/details/79471909
�����Ż�
Step1�Ż�:2��input���ĸ�����ģ���Ǻϲ���һ������ģ����
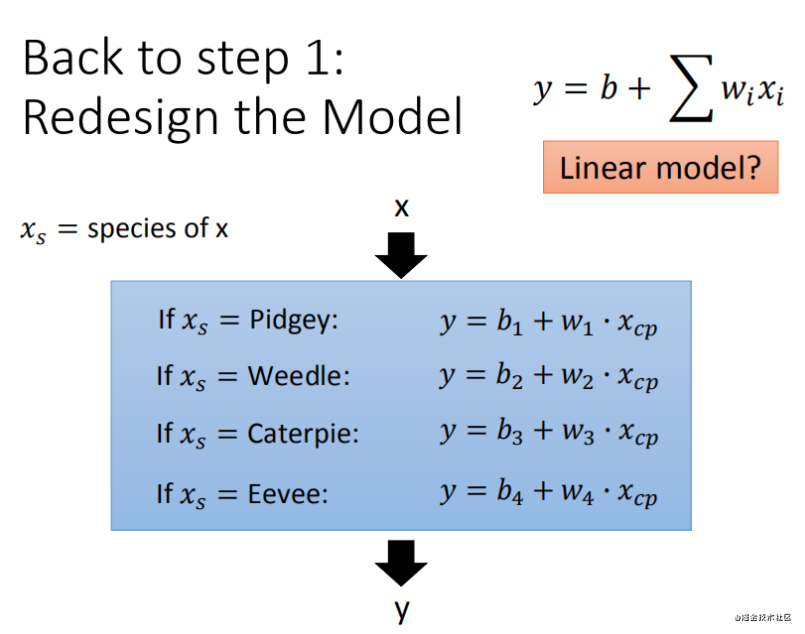
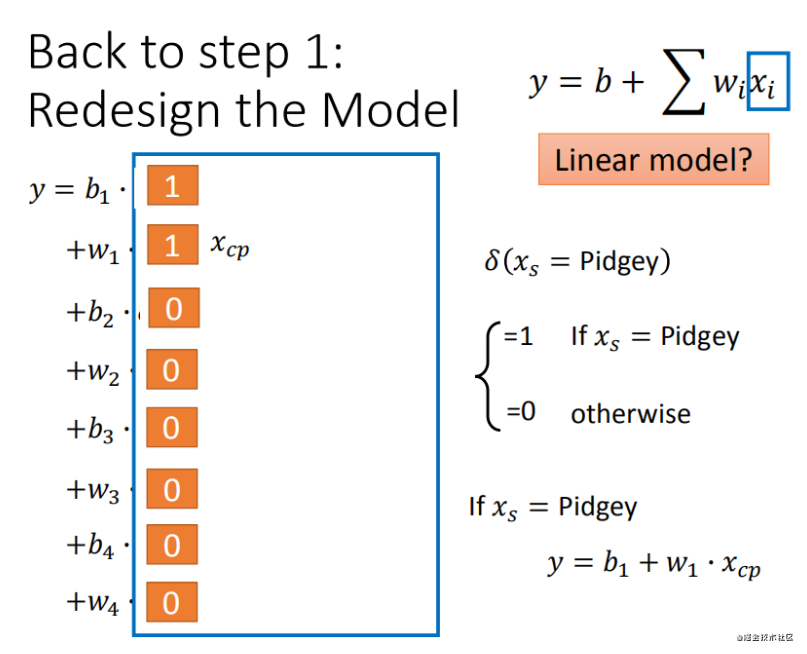
Step2�Ż�:���ϣ��ģ��ǿ����ָ���(�������,����input)
���ʼ�����кܶ�����,ͼ�λ���������,��Ѫ��(HP)������(Weight)���߶�(Height)Ҳ���뵽ģ����
Step3�Ż�:��������
��������,����Ȩ�� w ���ܻ�ʹijЩ����Ȩֵ����,�Ծɵ���overfitting,���Լ�������
- w ԽС,��ʾ function��ƽ����,function���ֵ������ֵ����
- �ںܶ�Ӧ�ó�����,������wԽСģ��Խƽ��Խ��,���Ǿ���ֵ��������wԽС������¶��Ǻõġ�
- b ��ֵ�ӽ���0 ,������ƽ����û��Ӱ��
4-�ع���ʾ
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
# matplotlibû����������,��̬���
plt.rcParams['font.sans-serif'] = ['Simhei'] # ��ʾ����
mpl.rcParams['axes.unicode_minus'] = False # �������ͼ���Ǹ���'-'��ʾΪ���������
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
x_d = np.asarray(x_data)
y_d = np.asarray(y_data)
x = np.arange(-200, -100, 1)
y = np.arange(-5, 5, 0.1)
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
# loss
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0 # meshgrid�³����:yΪ��,xΪ��
for n in range(len(x_data)):
Z[j][i] += (y_data[n] - b - w * x_data[n]) ** 2
Z[j][i] /= len(x_data)
# linear regression
# b = -120
# w = -4
b = -2
w = 0.01
lr = 0.000005
iteration = 1400000
b_history = [b]
w_history = [w]
loss_history = []
import time
start = time.time()
for i in range(iteration):
m = float(len(x_d))
y_hat = w * x_d + b
loss = np.dot(y_d - y_hat, y_d - y_hat) / m
grad_b = -2.0 * np.sum(y_d - y_hat) / m
grad_w = -2.0 * np.dot(y_d - y_hat, x_d) / m
# update param
b -= lr * grad_b
w -= lr * grad_w
b_history.append(b)
w_history.append(w)
loss_history.append(loss)
if i % 10000 == 0:
print("Step %i, w: %0.4f, b: %.4f, Loss: %.4f" % (i, w, b, loss))
end = time.time()
print("��Լ��Ҫʱ��:", end - start)
# plot the figure
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet')) # ���ȸ���
plt.plot([-188.4], [2.67], 'x', ms=12, mew=3, color="orange")
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$')
plt.ylabel(r'$w$')
plt.title("���Իع�")
plt.show()
# linear regression
b = -120
w = -4
lr = 1
iteration = 100000
b_history = [b]
w_history = [w]
lr_b = 0
lr_w = 0
import time
start = time.time()
for i in range(iteration):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 2.0 * (y_data[n] - n - w * x_data[n]) * 1.0
w_grad = w_grad - 2.0 * (y_data[n] - n - w * x_data[n]) * x_data[n]
lr_b = lr_b + b_grad ** 2
lr_w = lr_w + w_grad ** 2
# update param
b -= lr / np.sqrt(lr_b) * b_grad
w -= lr / np.sqrt(lr_w) * w_grad
b_history.append(b)
w_history.append(w)
# plot the figure
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet')) # ���ȸ���
plt.plot([-188.4], [2.67], 'x', ms=12, mew=3, color="orange")
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$')
plt.ylabel(r'$w$')
plt.title("���Իع�")
plt.show()
�����:
- ����:https://zhuanlan.zhihu.com/p/112692430
- ����:https://zhuanlan.zhihu.com/p/72589970
- ����:https://blog.csdn.net/qq547276542/article/details/77980042/
- ����:https://zhuanlan.zhihu.com/p/136438005