Object Transformer:Towards Long-Form Video Understanding
��ƪ���ڻ��ڹ�ϵ��ģ��ʱ����Ϊ���������
Object Transformer
����ƪ������,����Ϊ��AVA���ݼ����а��Ͽ���Object Transformerģ��������һ,�ﵽ31%mAP,��������������,����ָ����
Object Transformerģ������Ҫ�����dz�����Ƶ����,ּ�����ⳤ����Ƶ�����ߵ���ͼ,����֮��Ĺ�ϵ,�������,���ȵȡ���Ȼ,���ģ��Ҳ��������ʱ����Ϊ��⡣

��ʵ�鲿��,Ҳ��֤����һ��,�����ܹ�����:(a)��ϵ,(b)˵����ʽ,?����,(d)'like������,�ȡ�

����
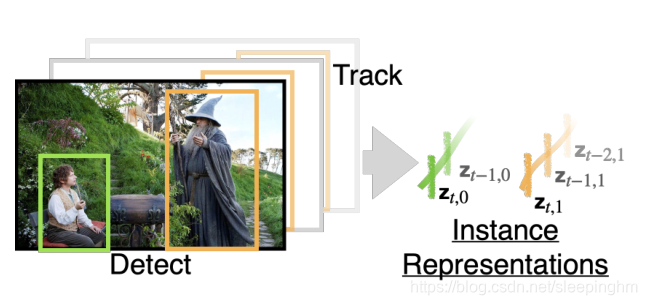
������Ϊ,��ͳ�Ķ�����Ƶ��������ֻ�ܻ�ȡ�ֲ���Ϣ(Ŀ��,�ص�,��״),����Ч���ó�����Ƶ�е�Ŀ���Ľ�����ϵ,�Գ�����Ƶ�������������,���������Ŀ��Ϊ����(Object-centric),����Ŀ���Ľ�����ϵ���н�ģ(Ŀ��ָ�����ˡ����塢������Щʵ��)��
- ����ͼ����ģ��ȥ���(Faster R-Cnn+SlowFast),�Ҹ�������Ŀ��(Objects),��Ŀ�꼰���Ӿ����������������塣
- ����Object Transformer(����ObT),��Ŀ��֮��ĸ��ӽ�����ϵ���н�ģ��
����˼·
Object-Centric���
��Ƶ�ľֲ�����:
- ������Ŀ����(Action and Object Detection):����ʹ�ö���ʶ��ģ��(SlowFast)��ʶ�������ԭ�Ӷ���,��ʹ��Ŀ����ģ��(Faster R-CNN)�����Ҿ��ж�������Ŀ�ꡣ
- Ŀ����:�ж�Ŀ���ڿռ��е������Լ�Ŀ�����,����Ҫʱ����Ϣ��
- ����ʶ��:�ж�һ�ζ���Ƶ(����Ϊ2D֡����)�е�Ŀ�궯�����,Ϊ���������,ʱ����Ϣ�Ϳռ���Ϣ���ڶ���ʶ��ģ��������Ҫ��
- s t , i �� R 4 s_{t,i}��R^4 st,i?��R4 :��ʾ�ڵ�t ֡��Ŀ�� i i i�ı߽��(bounding box); z t , i z_{t,i} zt,i? :��ʾ���������
- ��(Tracing):һ��Ŀ�꾭�������ڶ��֡�С�
�����㷨����ʱ������Ƹ�����Щ��۲���������Ŀ��ID�������- �� t , i ��_{t,i} ��t,i? :��ʾ��ʱ�� t t t��Ŀ�� i i i��
- ��ͷ���ɼ��(Shot Transition Detection):������Ϊ,��video���й��ɻ�ָ��һ�ζ�shots(��ͷ)�� �������γ���Ȼ���ȱ߽硣 ʹ�û��ڹ������ֵ���Կ��Խ���shotת����⡣
- C u C_u Cu? ��ʾʵ�� u u u���ڵľ�ͷ��
�������ǽ��ֲ�������������,������������Ƶ��ϵ��
-
����һ��Ŀ��ʵ�� U U U(������,����,���ȵ�),ʹ�ö���(shorter-term)Ŀ��������㷨���м����١�ÿ��ʵ�� u �� U u��U u��U,��ʱ���������������, { ( t , s t , i , z t , i ) �O �� t , i = u , ? V , i } \{(t,s_{t,i},z_{t,i})|��_{t,i}=u,?V,i\} {(t,st,i?,zt,i?)�O��t,i?=u,?V,i},Ҳ���Ǽ�Ŀ�� i i i��ʵ�� u u uʱ,������ʱ��,�ռ�����,���ڵ�ʱ������( z z z)����ʾ�佻����Ϣ������ͼ��
- t t t��ʱ�䲽��,
- s t , i s_{t,i} st,i?�ǿռ�����,
- z t , i z_{t,i} zt,i?�Ƕ�������,
-
��
t
,
i
��_{t,i}
��t,i?����ID��
-
ʹ��Transformer��ģÿ��ʵ���仯����Ϣ,ʵ����ʵ��֮�佻������Ϣ��Transformerʹ�ñ���������Ϊ����,�ڸ�������,ÿ��������Ӧһ��boxλ��,����link��Ϣ,��ͷshot��Ϣ������ÿ����ʵ�� u u u������ ( t �� , s �� , z �� ) (t',s',z') (t��,s��,z��),������������:
y �� : = W ( f e a t ) z �� + W ( s p a t i a l ) s �� + E t �� ( t e m p o r a l ) + E u ( i n s t a n c e ) + E c u ( s h o t ) + b y':=W^{(feat)}z'+W^{(spatial)}s'+E^{(temporal)}_{t'}+E^{(instance)}_{u}+E^{(shot)}_{c_u}+b y��:=W(feat)z��+W(spatial)s��+Et��(temporal)?+Eu(instance)?+Ecu?(shot)?+b- ʹ�þ��� W ( f e a t ) W^{(feat)} W(feat)�� W ( s p a t i a l ) W^{(spatial)} W(spatial)�� z �� z' z���� s �� s' s��ӳ�䵽������768άʸ���ռ䡣
- E ( t e m p o r a l ) E^{(temporal)} E(temporal)�� E ( s h o t ) E^{(shot)} E(shot)�ֱ���ʱ���(time stamp)�;�ͷ��������λ��Ƕ��(position embedding)��
-
E
(
i
n
s
t
a
n
c
e
)
E^{(instance)}
E(instance)��ʵ��Ƕ������,��ģ��ѧϰ��Щ��������ͬһʵ����
- Ϊ������ģ�ͷ�������,����ģ��ֻѧϰ��������ʵ���ı�������,�����ǰ��������,�����ѡʵ��ID��
-
û�������桭
- ʹ�� E [ C L S ] E^{[CLS]} E[CLS]��ʾÿ�������ĵ�һ����ʶ(token),����BERT��
- ʹ�ö�Ӧ��λ�õ�������� v [ C L S ] v^{[CLS]} v[CLS] ��Ϊ��Ƶ�ı���(as the video-level representation)��
- ʹ���������ͷ h ( t a s k ) h^{(task)} h(task)( v [ C L S ] v^{[CLS]} v[CLS])��ִ��ÿ����Ƶ�Ľ�������(videl-level end-task)��
- ���ԼලԤѵ���л������������ͷ�� h ( m a s k ) h^{(mask)} h(mask), h ( c o m p a c t ) h^{(compact)} h(compact)�Լ���Ӧ����ʧ���� l ( m a s k ) l^{(mask)} l(mask), l ( c o m p a c t ) l^{(compact)} l(compact)��
-
�봫ͳ������ģ˼·�ĶԱ�(Object-Centric vs. Frame-Centric vs. Pixel-Volume):
-
���еķ���Ҫô��2Dͼ,������ T �� W �� H T��W��H T��W��H�����뷽ʽȥ��ģ��������Ƶ,�Բ����ϳ����ķ�ʽ��Ϊ������ģ��ȥ������Щ�ź�,��ô���ᵼ��ģ��ѧϰ����,���ֲ��á�
-
��Ϊ�ķ�����������Ȼ�Ĺ���,�����뻷���Ĺ�ϵ������֮��Ľ�������Ϊ����Ϊ֮��Ĺ����ȶ��ǿ�����ģ���õ��жϵ�ǰ��Ϊ����뷢��λ�õ�������Ϣ����Ҳ��Object-Centric��Ƶ���ּ��
-
���ҼලԤ����

���ҼලԤ��������:���ø�������(pretext)�Ӵ��ģ���ල�������ھ������ļල��Ϣ,ͨ�����ֹ���ļල��Ϣ���������Ԥ��ѵ��,�Ӷ�����ѧϰ�������������м�ֵ�ı���������,�Լලѧϰ�ļල��Ϣ�����˹���ע��,�����㷨�ڴ��ģ�ල�������Զ�����ල��Ϣ,�����мලѧϰ��ѵ����
- ������û�б�ǩ�����ݽ���Ԥѵ��,�ҵ����ʵ�ģ��Ȩ��,��ʱ��ģ��Ȩ���ܹ���ģ�����������Ƶ��Ϣ������NLPģ���е�Ԥ������ʽ��MASK,���Ĵ�Ԥ��,����˳��Ԥ��ȵ�,����Ҫ����ı�ע���ܹ�ѵ��,Ŀ�������ܹ���ģ��ȫ��������������Ϣ,�����������Ķ�����,ֻ��ȫ�����������µ���˼,�ſ���������Ŀ��
- �������мල�����ݶ�ģ�ͽ�������
�ڱ�����,����ʹ��������Ԥѵ������:
- ����ʵ��Ԥѵ��(Masked-Instance Pre-Training),������,���������סijЩʵ��������,��ģ����������û���ڵ�����Ϣ���ڵ��IJ��ֽ���Ԥ��,Ҳ����ѵ��ObJ��Ԥ������ʵ��������(Ŀ�����,���ﶯ��)������,������������յ���Ŀ,�����Ķ�����,�������Ǽ�����Ƶ���⡣
- ������Ԥѵ��(Compatibility Pre-Training),�ж�����shots(video���ú��С����Ƶ)֮���Ƿ���Υ��,�Ƕ���������,����"���,�̻�"���ʺϳ�����"����"�ֳ�������"¶Ӫ"�ֳ�,Ҳ�Ǽ�����Ƶ�����һ��������
����ЩԤ������Ŀ��,�����ߵĻ�˵,������ģ��Ԥ��ѧϰ��������,��ʶ,���������Ϊ,�ܶ���֮,������ģ�����������Ƶ��Ϣ��
����ʵ��Ԥѵ��
-
ֻ�������������� z z z,������ʱ��� t t t,�ռ�λ�� s s s,ʵ��Ƕ������ E ( i n s t a n c e ) E^{(instance)} E(instance),��ͷǶ������ E ( s h o t ) E^{(shot)} E(shot)��
-
��BERT����һ��,��80%���ʱ�mask,10%���ʱ�������,10%���ʱ��ֲ��䡣
-
�������ε�ÿ�����,ʹ�����ͷ h ( m a s k ) h^{(mask)} h(mask)��Ԥ��������� p ^ �� �� d ? 1 \widehat{p}�ʡ�^{d-1} p ?����d?1,��distillation��ʧ(temperature T=1)�ع�α��ǩ(pseudo-label) p �� �� d ? 1 p�ʡ�^{d-1} p����d?1��
l ( m a s k ) ( p , p ^ ) : = �� k = 0 d ? 1 ? p k l o g ( p ^ k ) l^{(mask)}(p,\widehat{p}):=\displaystyle \sum^{d-1}_{k=0}-p_klog(\widehat{p}_k) l(mask)(p,p ?):=k=0��d?1??pk?log(p ?k?) -
��ͼ(b)��ʾ,���������ʡ���������ʲô����?�����ߡ�һ���˿�������ʲô?��������������,���ڱ�������,ʹ��ObJȥѧϰ���֪ʶ�ͳ�ʶ��

-
�ڱ�ʵ��Ԥ��vs�ռ�����ѧϰ����:
- ��ǰ������Ƶ���Ҽල�����Ĺ���Ŀ��ͨ���漰����ʱ����ٶ������Ȥ��,����һ��ʵ����ѧϰ(����,�ӵ㡢�������ڵ�������)������,Ҳ����Ϊ��ѧϰ³���Ŀռ�������ʾ��
- �ڱ�����,����ּ��ѧϰ��Ƶ�еij���ģʽ��
��ȼ�����Ԥѵ��
-
��������Ƶ����Ƿ��ݡ����з��ࡣ���߶����������(span),����������ͬһ����������̷���ʱ,�����Ǽ��ݵġ�
-
����ģ��ѧϰ���������,����,������Ӧ�ñȡ�¶Ӫ����ˤ�ӡ������ϡ��ۻᡱ�͡����͡���
-
��һ�����ͷ h ( c o m p a t ) h^{(compat)} h(compat)����� v = h ( c o m p a t ) v = h^{(compat)} v=h(compat)( v [ C L S ] v^{[CLS]} v[CLS]),��ʹ��InfoNCE��ʧ���м�����ѵ��
l ( c o m p a t ) ( v , v + , v ? ) = ? l o g e ( v ? v + ) e ( v ? v + ) + �� n = 0 N ? 1 e ( v ? v n ? ) l^{(compat)}(v,v^+,v^-)=-log\frac{e(v��v^+)}{e(v��v^+)+\sum^{N-1}_{n=0}e(v��v^-_n)} l(compat)(v,v+,v?)=?loge(v?v+)+��n=0N?1?e(v?vn??)e(v?v+)?
- v + v^+ v+�� v n ? v^-_n vn??�ֱ��Ӧ����v���ݺͲ����ݵĿ��(spans)��
-
��"��һ��Ԥ��"����ĶԱ�
- ������Ԥ����NLP�г��õġ���һ��Ԥ�⡱������İ汾��
- ������,��Ȼ����ͨ�����ϸ����ͷḻ�Ľṹ,����Ƶ�ڽṹ�ϸ�������,�����͡��¼�������������������һ�������ⳤ��ʱ��,���ҿ�������Ƶ�Ķ����ͷ�г��֡�
- ���,���߷ſ���Ԥ��ֱ���ڽӵ�Ҫ��,��ʵʩ�˸����ɵġ������ԡ�Ŀ�ꡣ
ʵʩϸ��
ʵ���ı�������(Instance Representations):ʹ�ô���ResNet-101���ɵ�Faster R-CNN����COCO��Ԥ��ѵ����FPN��Ѱ�����������Object������ʹ��RoIAlign��������������Faster R-CNN�������Ϊ���� z z z��
- ���ﶯ�����,���ô���Faster R-CNN��ܵļ��ģ�����ṩ��λbox,�Ǹ������滻ΪNon-Local�� ResNet-101 SlowFast,������RoIAlign����������Ϊÿ������box������
z
z
z��(��һ���ֲ���SlowFast����)
- ��AVA��Ԥѵ��,�ﵽ29.4%mAP��
- ʹ��AVA������Gu�ķ�������Ŀ����١�
- ʹ��PySceneDect�㷨���о�ͷ���ɼ��
������Ԥ��(Compatibility Prediction):��Ƶ���ݼ�Ϊ1��3���ӵĵ�ӰƬ��,���������һ��segment,�������ݵġ���СΪn��bacth����n/2������ ( v , v + ) (v,v^+) (v,v+),bacth��ʣ������Ϊ���� v ? v^- v?��
���ͷ(Output Heads): h ( m a s k ) h^{(mask)} h(mask)��˫��MLP�� h ( c o m p a t ) h^{(compat)} h(compat)������end-task����ʹ��0.1��dropout,�������Բ㡣
ʵ��
-
����1-����Ƶ����
- ��������
- ����ϵrelationship������˵�����way of speaking����������/�ص�scene/place��
- ����������������,���ǽ�����ÿ����Ƶ�����������,��ʹ����������(����,�����ѡ��������Ӻ��ɷ�)���γ�����(���确��ϵ��Ԥ��)��
- ���ڲ����Ԥ��
- ��YouTube like ratio������YouTube������
- ����ʹ��YouTubeͳ�����ݽ����û������Ԥ������
- ��ӰԪ����Ԥ��
- ������director����������genre���������writer��������Ӱ��ӳ���year��
- ����Ԫ����Ԥ������,���Ǵ���Ӧ��IMDb��Ŀ�л�ȡԪ���ݡ�
- ����ָ��
- ���������Ԫ����Ԥ�������ǵ���ǩ��������,ͨ��top-1���ྫ�Ƚ���������
- �û������Ԥ�������ǵ�ֵ�ع�����,ͨ������������������
- ʵ�����

- ObJ���ڶ���ģ��SlowFast��VideoBERT,��ʹSlowFast�д�Ǹ�����(�� R101-SlowFast+NL ')�ͽ���ǿԤѵ��(��dynamics-600��AVA���ݼ���),������Ч��Զ����ObJ,֤���˳��ڽ�����Ϣ��ģ����Ҫ�ԡ�
- ����֡Ϊ���ĵĽ�ģ���,��Ŀ��Ϊ���ĵĽ�ģ(ObJ)�������ơ�
- ����ģ�����Ժܺõ��������Ԥ�⡣��Ϊ����ͼ��������ɫ�ʷ��֮��������ܹ����������Ƶ����ݡ�����Ϣ��

- VideoBERT���ʺϱ��writerԤ��,���������������ܲ���Ҫ̫����ϸ�Ľ�����ģ��
- ��������
-
����2-AVAʱ�ն������
-
����ָ��:map,���ݼ�:AVA��
-
����:���ں϶���Ԥ��(short-term prediction),ֻ�����Բ㡣
-
ʵ�����:
- ��ʹ����Ƶ+����(V+F)����Ƶ+��Ƶ(V+A),������Ҫ������Ĺ��̵ķ���,ObT������Ƶ��Ϊ���������������������
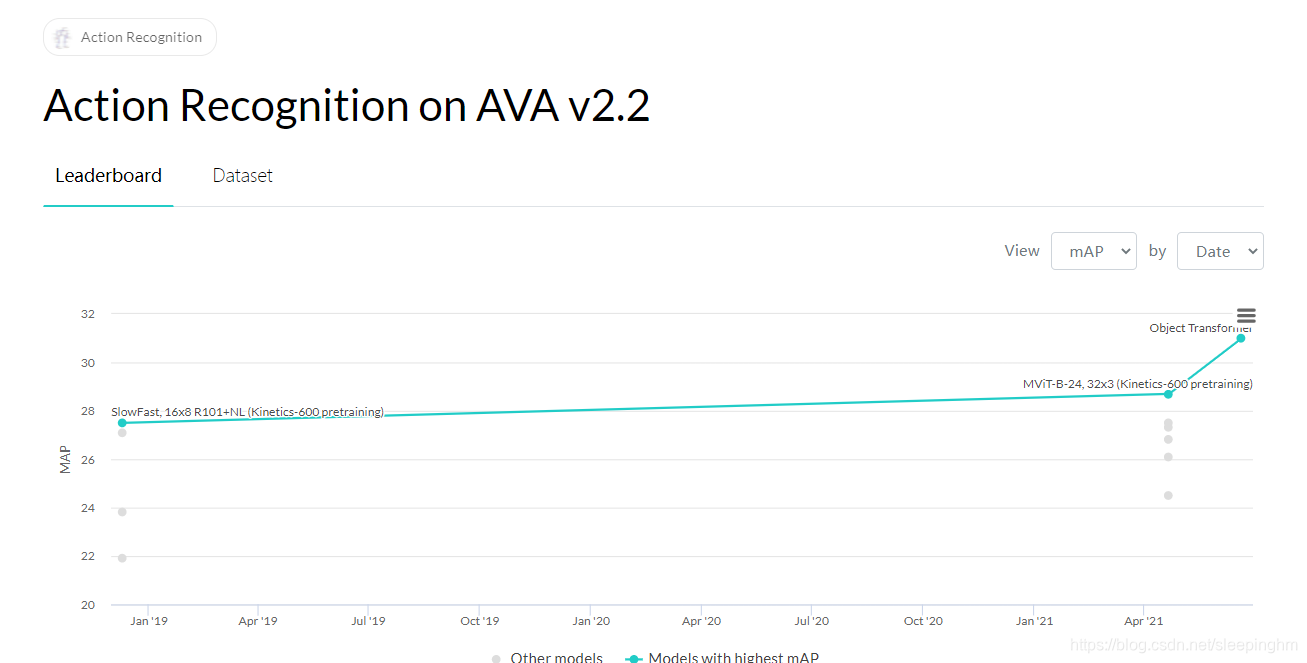
- ��SlowFast������1.6%mAP(29.4%->31.0%),ֻ�ȶ���0.7%�Ķ��⸡��������ۡ�
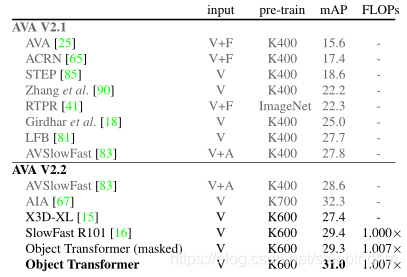
- ��ʹû�н��к����ں�(��),��ʹ��mask��ObJҲ�ܴﵽ29.3%����,֤�����ܹ�����������,Ԥ����Ƶ���ڱβ��ֵ����塣
-