目录
(二)没有免费午餐定理(NFL:no free lunch Theorem)
零、引言
本笔记的主要参考资料是周志华的《机器学习》和李航的《统计学习方法》以及网上的一些资料,我不会每一个概念都照搬定义,我喜欢增加一些自己的理解,但对于重点,我会加粗
一、机器学习的概念(什么是机器学习)
(一)定义
明确说明了了机器学习领域的研究目的、研究对象和研究方法
对于这个问题,先稍安勿躁,因为机器学习并不仅仅是赋予机器(其实也就是计算机,叫做机器是为了和人区分开)学习的能力那么简单,因为机器学习并不是凭空而来的,而是人工智能领域发展的产物。
在周志华的《机器学习》中有这么一句话:“机器学习是人工智能研究发展到一定阶段的必然产物”,也就说机器学习是人类在探索人工智能过程中的得到一项成果。
先来简单说一下人工智能,人工智能所追求的就是让机器拥有像人一样(虽然说动物领域的研究发现动物并不比人笨,但人总愿意相信自己是全世界最聪明的物种,原因吗。。。傲慢)的智能(或者说智慧)。也就是探索让机器具有智能的方法。结合周志华的那句话结合起来就是:机器学习是人类在人工只能领域探索中发现的一条可行道路。
对于人工智能,cs科学家们经历了认为只要让机器有推理能力就能实现智能的“推理期”和让人通过编程实现让机器获取知识的“知识期”,通过不断地探索人们开始认为到让机器具有智能就需要让机器有学习能力。至于机器学习详细的发展历程我会专门写一篇学习笔记,模仿科学史评话。
好了,认识到这一步,总算是到了机器学习的概念了,机器学习的概念网上说的很模糊,而且其实机器学习并没有绝对权威性的唯一定义,《统计学习方法》上只说了什么叫统计学习(机器学习的一部分),机器学习的总体定义在《机器学习》中有提到:机器学习是致力于研究如何通过计算的手段,利用经验来改善自身系统的性能的学科。这个定义高度概括了机器学习的研究内容,说明了机器学习的研究目的。
对于机器学习具有指导作用的定义有两个,分别对机器学习划分了研究领域和规定了研究方法:
(1)在研究领域方面,早在1959年就有权威的科学家给出了定义:机器学习是这样的领域,它赋予计算机学习的能力,这种学习能力不是通过显著式编程获得的。但是什么是显著式编程呢?显显著式编程是需要人为地根据周围的环境、规则、经验等给计算机规定一些机械化步骤或判断依据,就比如给图片分类,显著式编程就是直接将按照颜色分辨规则编辑程序。与显著式编程对立的便是非显著式编程,即让机器自行挑选并总结规律的编程方法。这个定义将机器学习的研究领域明确地划分出来,对于机器学习具有重要的指导意义。
(2)在研究方法方面,1998年另一位cs科学教在一本经典的书《MACHINE LEARNING》中提出:一个计算机程序可以被学习,是指它能够针对某个任务T和某个性能指标P,从经验E中学习。这种学习的特点是,它在任务T上被性能指标P衡量性能,会随着经验E的增加而提高。解释起来就是针对任务――构造算法――使得算法具有随着经验E的增加,性能指标P随着E的增加而增加的特性。这个特性增加的问题就是数学上典型的最优化问题,实现了机器学习数学化。从此往后,机器学习的问题就转化为了数学问题,从而规定了机器学习的研究方法,同时也使得数学在现代机器学习中占有重要的作用。
自此以后机器学习就正式成为了一个独立的具有特定研究方法的研究领域?。
(二)机器学习的重要概念
说明:这里的概念主要针对监督学习
1.样本空间、输入空间和输出空间
样本空间:所有可能取得的样本所组成的集合成为样本空间
输入空间和输出空间:对于一个模型(尤其是监督学习),输入和输出的所有可能取值的集合分别成为输入空间和输出空间。两者可以是一个空间,也可以不同,但往往输入空间远大于输出空间。
样本空间是机器学习中的概念,输入空间是统计学习的概念,机器学习和统计学习的最大的区别简单说就是研究目的的不同,一个是实战一个是兵法,二者相符相成。
机器学习(往往特指监督学习)的目的是预测,预测的操作对象是样本,所以样本空间有了上面的定义。
统计学习的目的是寻找规律,操作对象是模型,一个模型的意义就在于从输入到输出,所以输入和输出空间就有了以上的定义。
但模型是预测的基础,因此模型的输入就是样本或者表示样本的数据值,所以输入空间和样本空间往往说的是一件事。
2.输入空间与特征空间
特征向量:每一个具体的输入(样本空间的提取)是一个实例(样本),通常由特征向量表示。
特征空间:所有的特征向量存在的空间成为特征空间。
特征空间和输入空间有时候是一个空间,有时就不是一个空间,区别在于对应的具体问题中是否对样本进行了特征提取。
3.联合概率分布和决策函数
也就是输入与输出之间的内在规律。统计学习(或机器学习)中,总要先假设样本存在着一定的可以被发现并进行数学描述的规律(虽然说可能并不存在)。但这个规律一开始是不知道的,但正因为它不知道,所以才需要去学习。
当内在规律以概率的形式呈现的时候被称为联合概率分布:P(X,Y)
当内在规律以函数的形式呈现的时候被称为决策函数:Y=F(X)
4.假设空间
监督学习的目的是找到一个由输入到输出的映射,这一映射由模型表示。
学习的目的就是找到最好的模型。
从哪里找呢?我们只能先假设模型的大体样貌,找到一个模型(函数)簇,簇中仅仅是模型参数未知,模型结构股东
所需要寻找的模型所处在集合即为假设空间,也就是上面说的模型簇。
所以学习的过程就是在调整模型中的参数,调好了就是找到了合适的模型
(三)机器学习的本质
1.机器学习的本质
机器学习的本质是通过有限的已知数据,在复杂的高维特征空间(复杂的模型)中预测未知的样本
(对于强化学习我还不知道)
2.机器学习和统计学习
首先要说明的就是,机器学习和统计学习的界定本身就很模糊
机器学习和统计学习的区别终于要体现在研究目的上:
机器学习算法的评估使用测试集来验证其准确性。
然而,对于统计模型,通过置信区间、显著性检验和其他检验对回归参数进行分析,可以用来评估模型的合法性。
因为这些方法产生相同的结果,所以很容易理解为什么人们会假设它们是相同的。
二、?机器学习的分类
(一)机器学习的大分类?
从机器学习的概念中,得到了任务T、性能指标P和经验E。机器学习的划分标注便是通过经验? ? ? ? E的获取方式划分的:
(1)如果经验E是通过人工搜集的方式输入进入计算机,那么就称这种机器学习方式为监督学习,最终对未知数据进行预测。例如识别垃圾邮件、人脸识别、图像识别、天气预测、污染物浓度预测等。
(2)如果经验E是通过由计算机与环境互动的方式获得,这种机器学习方式称为强化学习,意为计算机通过与环境的互动逐渐强化行为模式实现收益最大化。例如机器下棋、自动驾驶等。
其中,强化学习的并不是两本教材的重点,而且概念较新。相对而言,监督学习较为基础,因此我的学习只能先从学好监督学习开始。
(二)监督学习的分类
1.监督学习可以通过是否打标签分为:
(1)(传统)监督学习:每一个训练数据都有对应的标签
通过标签训练
例如:
――支持向量机
――人工神经网络
――深度神经网络
(2)非监督学习:所有训练数据都没有对应标签
首先做出假设(同一类的训练数据在空间中距离更近)基于样本的(空间)信息,设计算法将样本狙击为几(两)类,这些类由机器自动生成,可能对应着一些潜在的概念划分,有助于了解数据的内在规律,为更为深入地分析数据建立基础。(我还不是很明白)
例如:
――聚类(代表)
――EM算法
――主成分分析
(3)半监督学习:训练数据中一部分有标签,一部分没有标签
通过少量的标注数据和大量的未标注数据(结合监督学习和无监督学习)设计出更好的机器学习算法(这个更不明白了)
例如:
――半监督聚类
――生成式方法
2.监督学习还可以通过标签的固有属性分为分类问题和回归问题
(1)分类问题:标签是离散的值
(2)回归问题:标签是连续的值
但是分类问题和回归问题没有明确的边界,因为离散和连续往往可以相互转化
三、机器学习算法的实现过程
第一步 提取特征
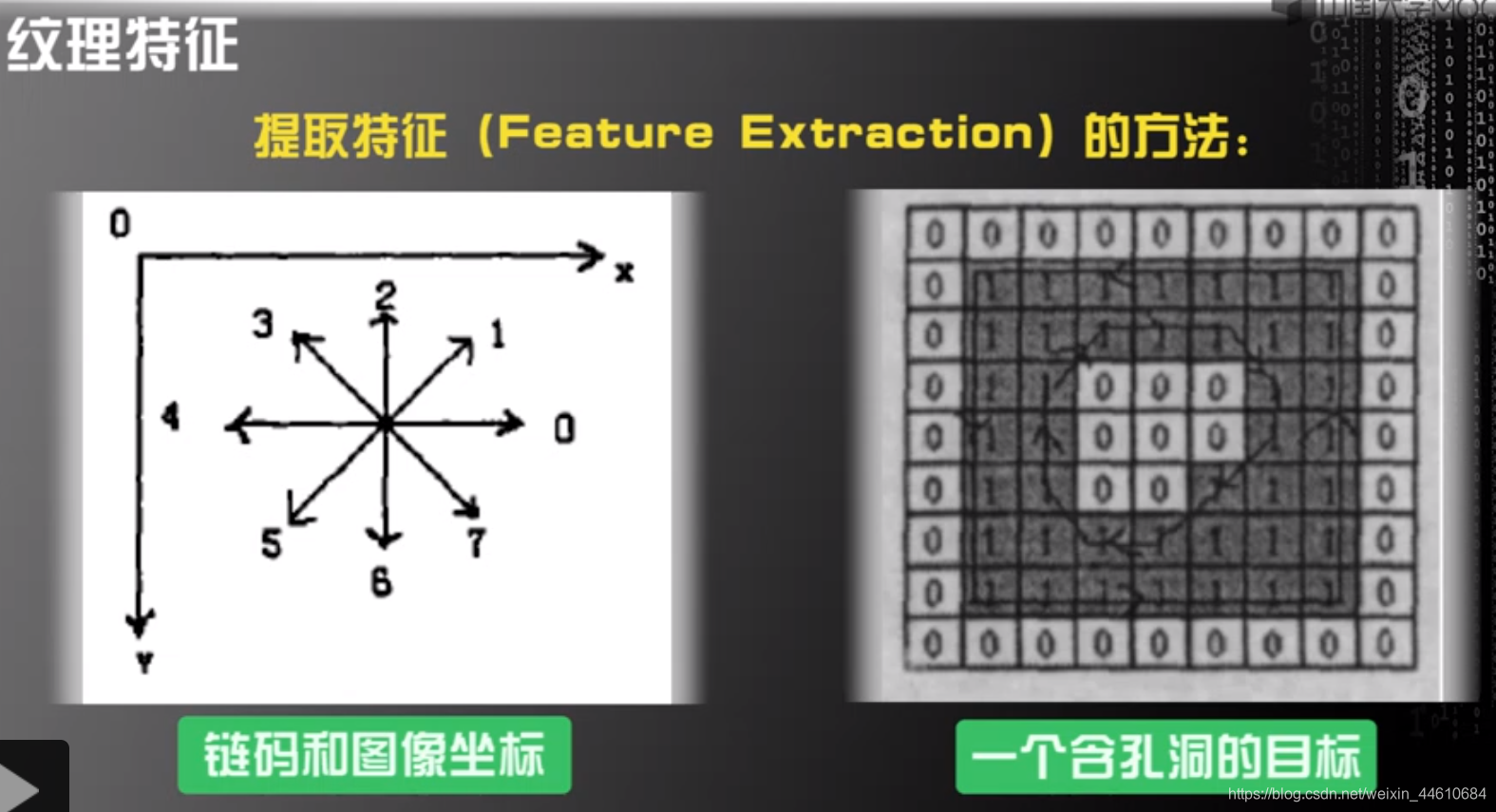
特征:通过训练样本获得的,对机器学习任务有帮助的多维度数据。
这一步很重要,但并不是机器学习研究领域的重点。
原因是不同媒质不同任务,提取特征的方式千变万化,无法归入机器学习研究领域。
第二步 特征选择(描绘特征向量)
??
选择具有代表性,容易处理,区分度比较高的特征
特征提取决定了算法实现效果的上限:
如果特征提取的好,即使算法不好也能获得不错效果
如果特征提取不好,再好的算法也难以获得好的效果
第三步 描绘特征空间
将特征向量集合行成特征空间
在实际应用中,往往特征向量维度很大,难以用肉眼观察,需要用机器学习算法训练
选择合适的假设空间训练得到合适的假设,此过程即为在图中画线的过程
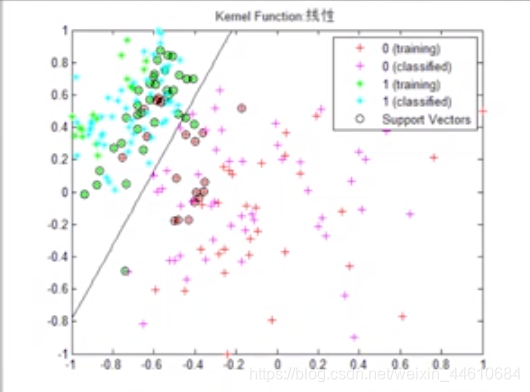
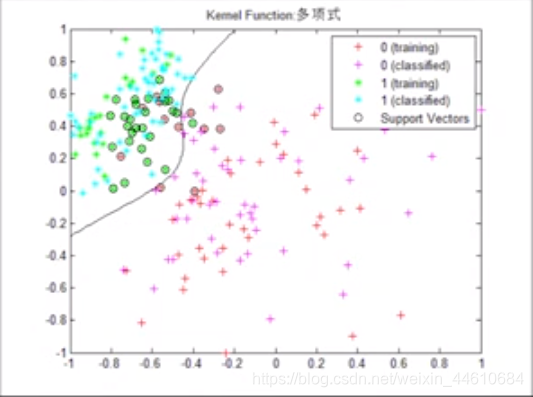
第四步 选用并编写算法
四、归纳偏好和没有免费午餐定理
(一)归纳偏好?
如上图所示,有多个假设和训练集一致的假设,此时需要采用其中一个假设。
此时,学习算法本身的偏好就会发挥作用
归纳偏好;机器学习算法在学习过程中对某种类型假设的偏好称为归纳偏好(偏好)
所有机器学习算法都需要有归纳偏好,否则无法生成确定的学习结果。
奥卡姆剃刀原理:若多个假设与观察符合一致,则选最简单的那个。
是一种常用的、自然科学研究中最基本的原则。但并非唯一可行原则。
(二)没有免费午餐定理(NFL:no free lunch Theorem)
解释一:没有一种机器学习算法是适用于所有情况的
解释二:更一般地说,对于所有机器学习问题,任何一种算法(包括瞎猜)的期望效果都是一样的
解释三:一个机器学习算法在这个问题上有好的效果,则一定会在另一个问题效果不好
注意,这个定理有个前提:“对于所有机器学习问题,且所有问题同等重要”。而我们实际情况不是这样,我们在实际中往往更关心的是一个特定的机器学习问题,对于特定的问题,特定的机器学习算法效果自然比瞎猜更好。
这个定理说明了没有放之四海而皆准的机器学习算法,但人们依旧在寻找终极算法,就像物理学中的大一统理论。
没有免费午餐定理我会在其他文章中尝试证明。