目标检测文章阅读(一)
文章《End-to-end Object Detection with Transformer》
code: https://github.com/facebookresearch/detr
Introduction
本篇文章是比较有影响力的DETR,开End-to-end object detection之先河。
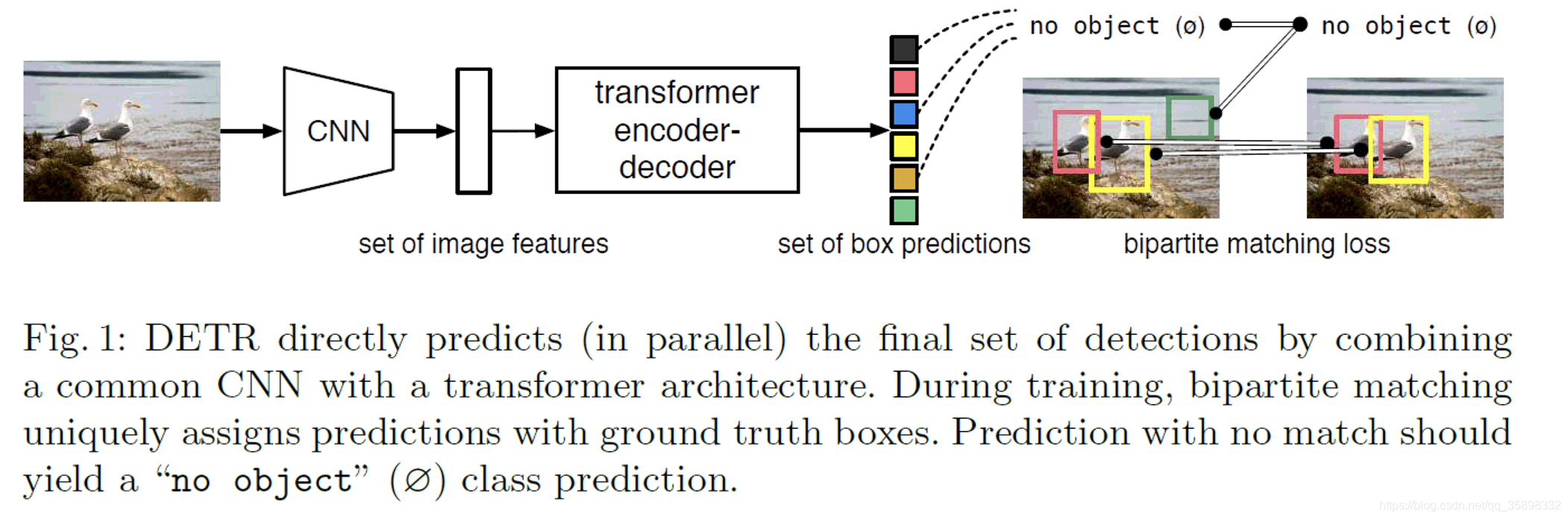
之前的object detection的model,ex. Fast-RCNN,YOLOv2,RetinaNet等都会通过对数据集的先验知识来设计一些proposal, anchors, window centers,然后通过一些后处理的方法,ex.NMS, 来消除一些临近的重复预测框。因为有后处理以及需要借助一些对数据集的先验知识, ex.数据集object的size等,之前的model并不是end-to-end的framework并且需要手动设计proposals以及后处理。本文提出的DETR是direct set prediction,是end-to-end的framework并且不需要手动设计proposal以及后处理,framework如下图所示:主体部分是CNN+Transformer,本文中所用为ResNet+standard Transformer,CNN提取的feature送入Transformer的encoder-decoder结构,输出的box再经过双向的matching来将box唯一地对应到ground truth(此操作应该是与传统的pipline是相同的)。得益于Transformer的global self-attention机制,DETR在COCO数据集的large object的效果要远远优于Fast-RCNN,但是在small object上的效果不如Fast-RCNN,一个可能的解释是,精心设计过的Fast-RCNN中的FPN提供了多尺度的信息,DETR在后续的改进中可能可以借鉴这种思想来提高对small object的效果。最终在整个COCO数据集上的AP因为large object的巨大提升是超过Fast-RCNN的。另外,通过在pre-trained Transformer上训练一个head network,DETR可以在语义分割任务上也超过有竞争力的一个baseline。
Transformer相比于LSTM以及RNN,最大的优点在于全局计算以及完美记忆,因此更适合长序列。
Method
DETR结构以及很多实现细节,笔者未完全理解,在精读code后再补充
Loss
因为每一个预测框需要唯一地分配一个ground truth的框,所以首先需要确定这个对应关系,即min下述loss
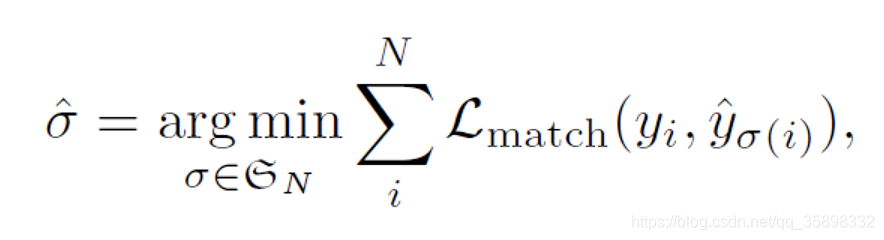
L
m
a
t
c
h
L_{match}
Lmatch?的定义如下,注意这里有object的box的loss才和预测框有关系,没有object的loss是一个常数且为了平衡正负样本的关系,其权重降低10。
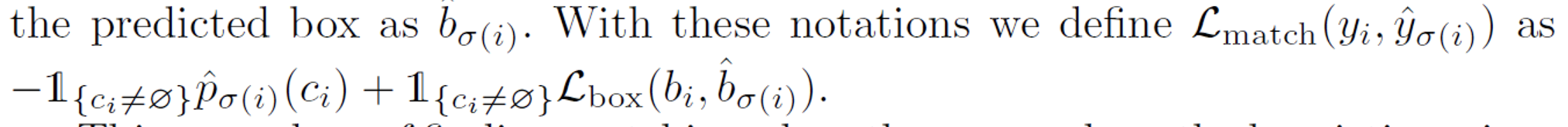
确定好预测框和ground truth框的对应关系后,优化框以及预测分类的loss如下:这里loss和上面
L
m
a
t
c
h
L_{match}
Lmatch?很像,其实分类的交叉熵loss本质上带log,但是文中提到经验上
L
m
a
t
c
h
L_{match}
Lmatch?不带log效果更好
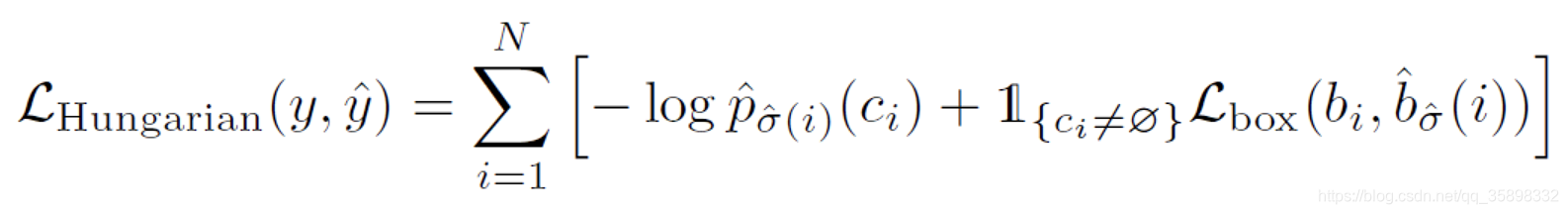
L
b
o
x
L_{box}
Lbox?分为两部分,一部分是坐标的L1 loss,但是文中提到对于large object和small object,L1的绝对值代表的误差程度是不一样的,所以加了iou loss
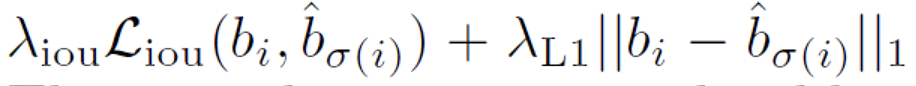
iou loss是generalized IoU,B代表smallest box containing
b
σ
(
i
)
b_{\sigma(i)}
bσ(i)?,
b
i
^
\hat{b_i}
bi?^? (GIoU参考GIoU)
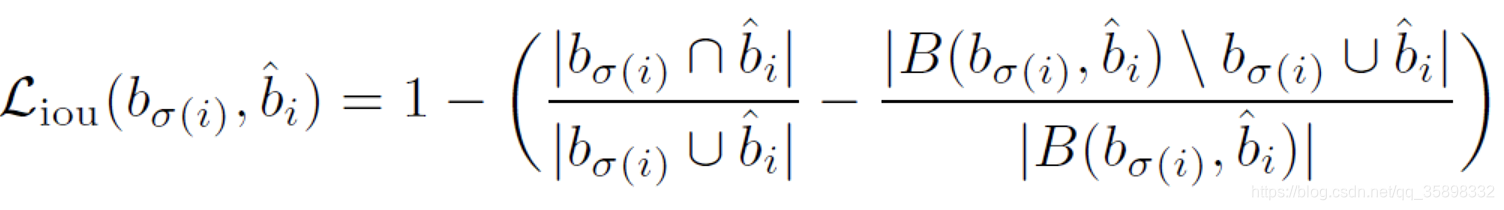
DETR
首先经过CNN backbone出C*H*W的feature tensor,这里C=2048(笔者很少见到这么大的C,一般见到的最大也是512),然后经过1*1 conv(降维)将C=2048降到d维。然后经过标准的Transformer。这里的batch操作,因为每张image size不同,所以需要对小的image padding,这里的做法是以batch内最大image的H和W最大尺寸,对其他图片padding 0。Transformer结构如下:详情参考代码
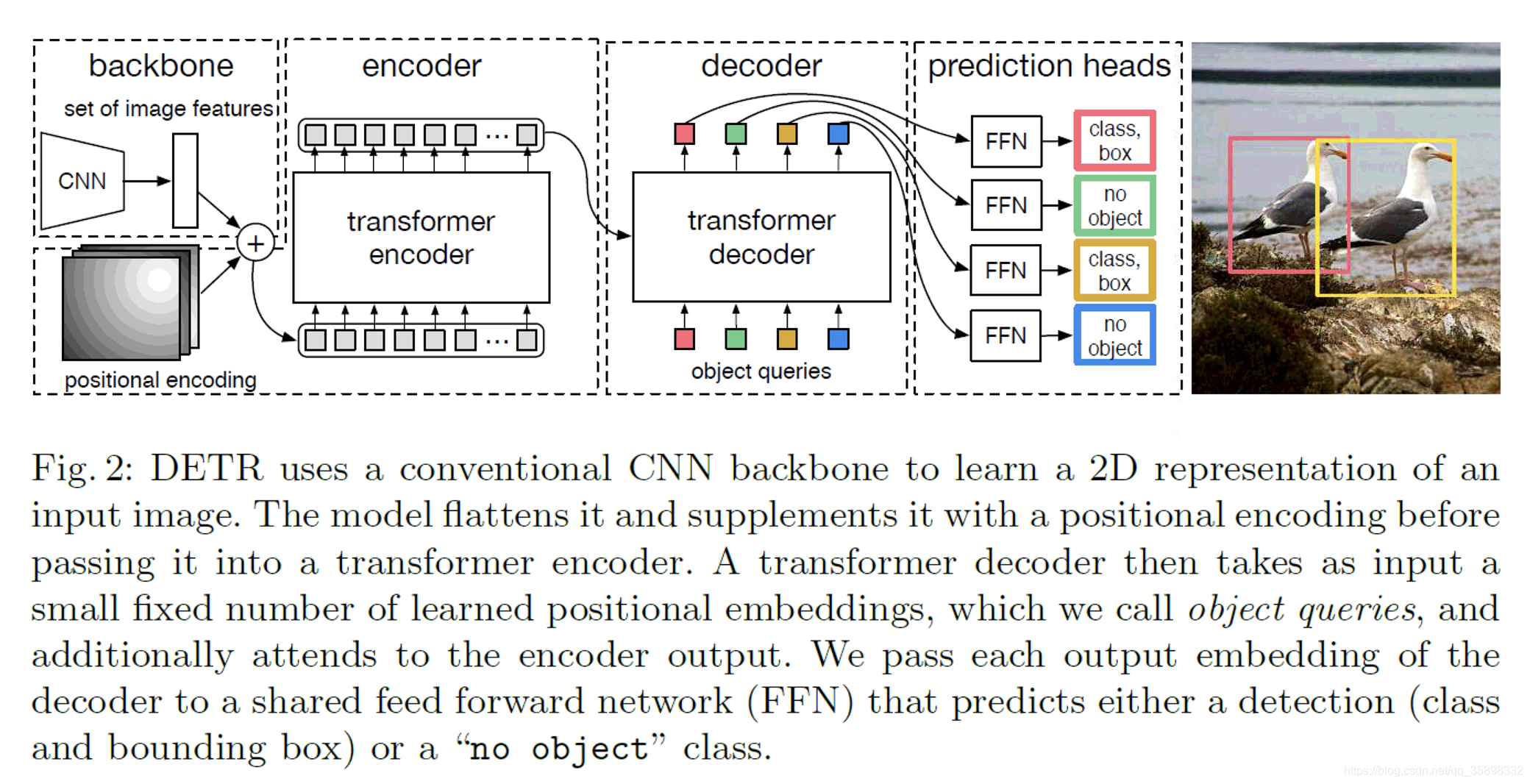
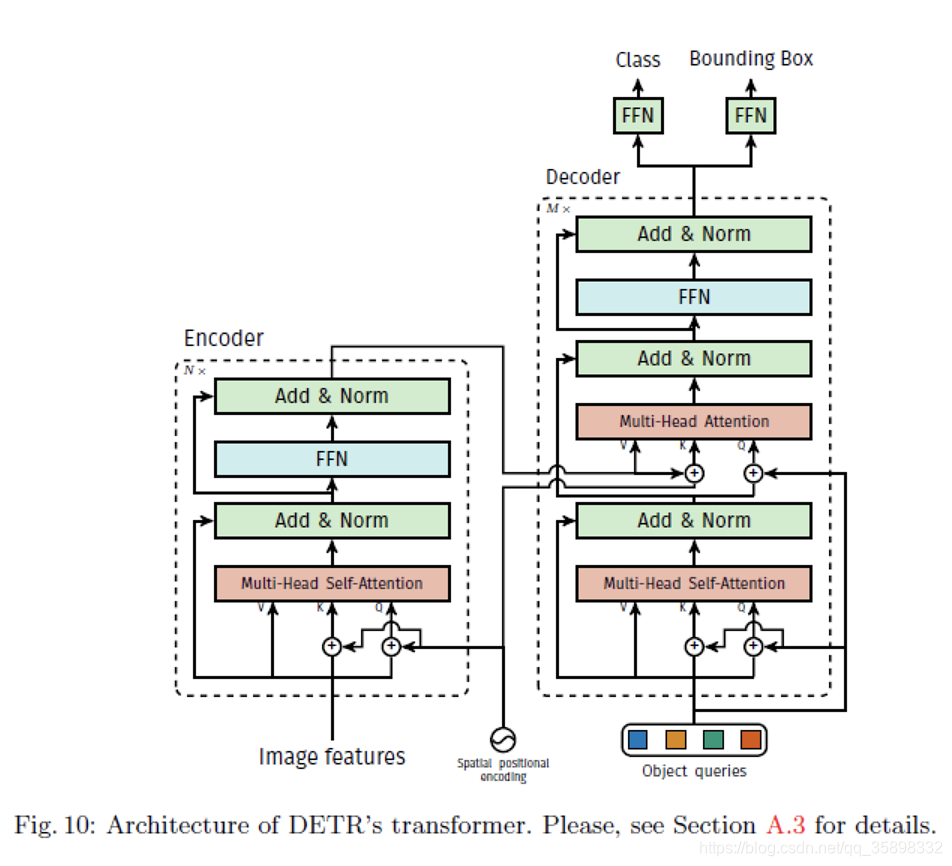
FFN
feed-forward networks,本文中用了3层感知机+ReLu/1层 linear layer,输出为center, width, height/class,其中因为设置输出N个预测框,一般N大于image中实际的object,所以有些框的class被设为null,这相当于传统目标检测中的background class。
Auxiliary decoding losses
参考《Character-level language modeling with deeper self-attention》,笔者理解后补充
Datasets
COCO 2017 detection and panoptic segmentation datasets
118k images for training/5k images for validation
平均一张图7个instances,最多一张图有63个instances
Experiments
实现细节:AdamW,weiht decay=1e-4, CNN initial lr=1e-5, Transformer initial lr=1e-4,CNN weights are pre-trained ImageNet weights, Transformer weights are initialized with Xavier Init,Transformer dropout=0.1, scale and random crop aug。
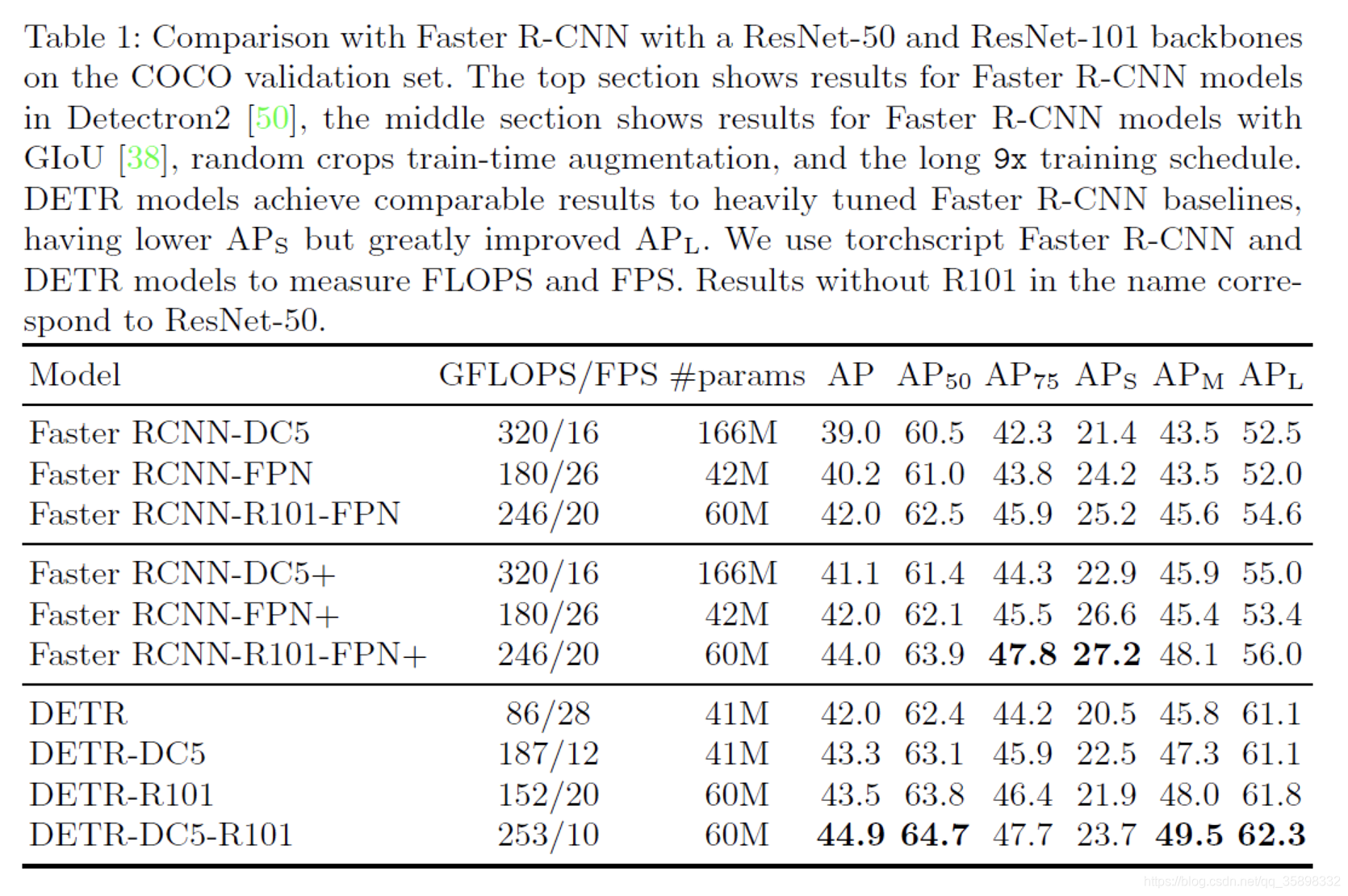
表一表明DETR相比于Fast-RCNN,在large object上有很大提升,在small object上不如Fast-RCNN。
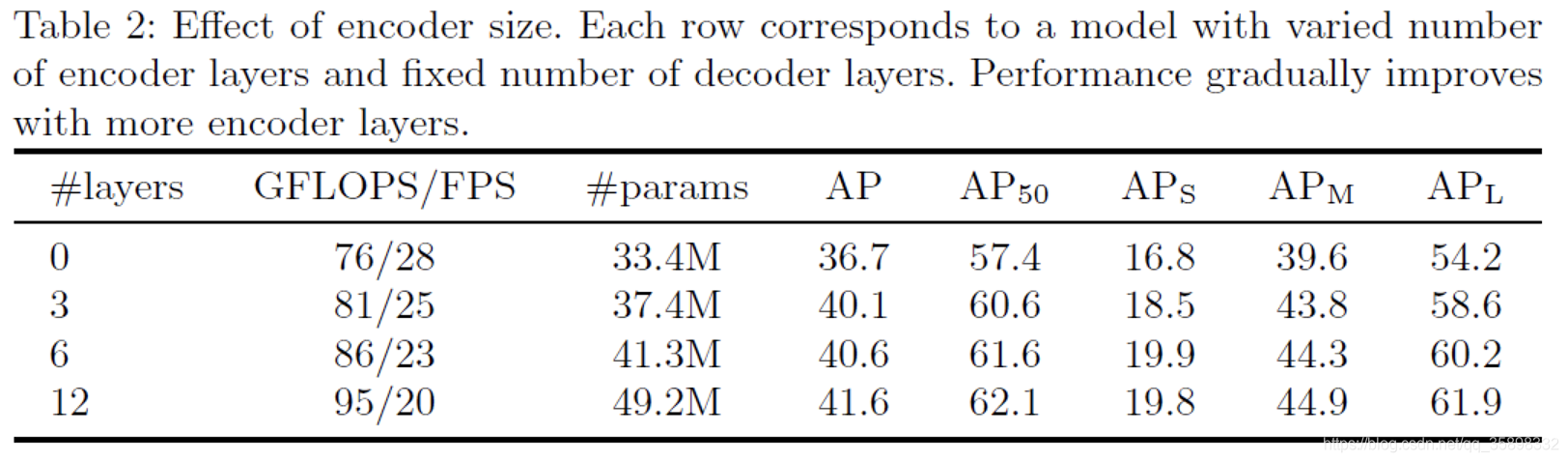
Transformer不同encoder layer层数的ablation study
下图是encoder后的几个typical pixel的self-attention map,可以看出已经将不同object分开了。

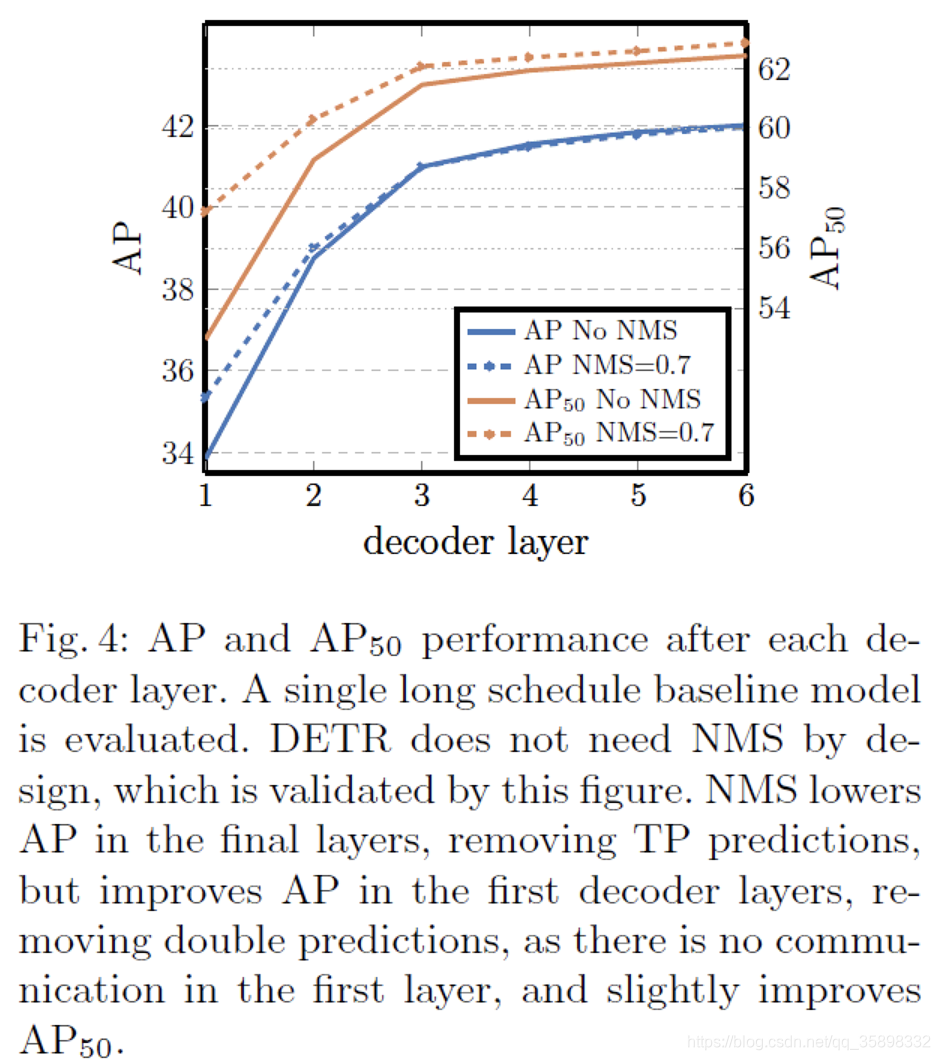
decoder缓和了需要NMS的gap
decoder的attention map更多侧重于object的边界,这是make sense的,因为要预测object的边界框

不同positional embedding的ablation study
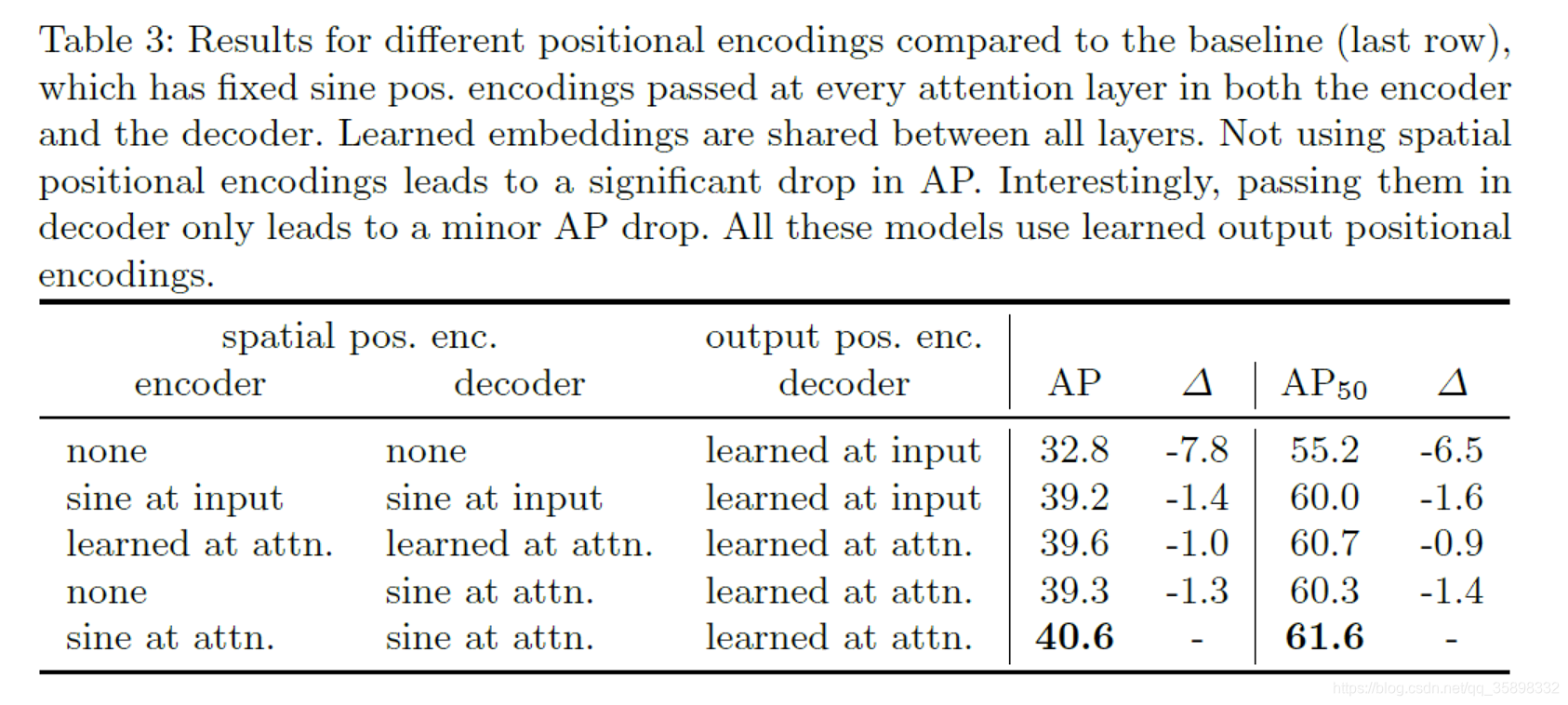
loss的ablation study