����:��ν�ع�,���ҵ�һ��function(����),������������(�Ա���),�����һ��Ԥ��ֵ(�����)
������Ԥ��Pokemon����Ĺ�������Ϊ���ӽ���ع�IJ��������������
����ѧϰ(��)
���汦��(��)
����ϣ������:
����:����ǰ��CPֵ,����,Ѫ��,����,�߶�
���:�������CPֵ
���ع�һ�㾭��������������:
�� step1:ģ�ͼ���,ѡ��ģ��
��step2:������ʧ��������ģ�ͺû�
��step3:�ݶ��½�ɸѡ����ģ��
Step1:ģ�ͼ���,ѡ��ģ��
1.һԪ����ģ��(����������)
���Ƿ���:
y
=
b
+
w
x
c
p
y=b+wx_{cp}
y=b+wxcp?
���������ʱ,cpֵֻ������,���Կ����ų�w<0�����������
����ʵ���Ǽ�һ�κ���,��������ǰcpֵ,���뷽�̱�����һ��y,���������cpֵ
���������Ǹ����ӵ����
2.��Ԫ����ģ��(���������)
���������cpֵ��ȷ��,��Ȼ���ܽ��������е�cpֵ,�������뾫���Ѫ��,����,����,�߶ȵ������й�,�������������Ԫ����ģ��:
y
=
b
+
��
w
i
x
i
y=b+\sum{w_ix_i}
y=b+��wi?xi?
����b��ʾƫ����,w��ʾ����������Ȩ��,x��ʾ������ֵ��
Step2:������ʧ��������ģ�ͺû�
��ν��ʧ����(loss function),������������ѡ���ģ�͵ĺû��̶ȵķ���,����ʧ�������Ժ���ģ��Ԥ��ֵ����ʵֵ֮��IJ����С��
�� һԪ����ģ�͵���ʧ����
���ڼ�һԪ����ģ��,���Ƕ�����ģ�ͺ�������:
f
(
x
c
p
)
=
b
+
w
x
c
p
f\left( x_{cp} \right) =b+wx_{cp}
f(xcp?)=b+wxcp?
�����������ص�ֱ��,����֤��ЩԤ��Ľ������cpֵ��,��Ҫ����ʵ����½������cpֵ�����Ƚϡ����Ǽ���ץ����10ֻ����,����¼�����ǽ���ǰ���cpֵ,��ʾ����:
(
x
1
,
y
^
1
)
,
(
x
2
,
y
^
2
)
,
(
x
3
,
y
^
3
)
.
.
.
.
.
.
(
x
10
,
y
^
10
)
\left( x_1,\hat{y}_1 \right) ,\left( x_2,\hat{y}_2 \right) ,\left( x_3,\hat{y}_3 \right) ......\left( x_{10},\hat{y}_{10} \right)
(x1?,y^?1?),(x2?,y^?2?),(x3?,y^?3?)......(x10?,y^?10?)
����x���ʾ����ǰ��cpֵ,y���ʾ�������cpֵ,ע����Щ������ʵ����,����Ϊ��¼�����ġ�
���������ֱ��,���ǿ��Կ���������,������Ԥ��ֵ����ʵֵ֮��IJ���,�Ӷ�������ʧ����:
L
(
f
)
=
��
n
=
1
10
(
y
^
n
?
f
(
x
n
)
)
2
L\left( f \right) =\sum_{n=1}^{10}{\left( \hat{y}_n-f\left( x_n \right) \right) ^2}
L(f)=n=1��10?(y^?n??f(xn?))2
��һ��չ��,��:
L
(
w
,
b
)
=
��
n
=
1
10
(
y
^
n
?
f
(
x
n
)
)
2
=
��
n
=
1
10
(
y
^
n
?
(
b
+
w
x
n
)
)
2
L\left( w,b\right) =\sum_{n=1}^{10}{\left( \hat{y}_n-f\left( x_n \right) \right) ^2}=\sum_{n=1}^{10}{\left( \hat{y}_n-\left( b+wx_n \right) \right) ^2}
L(w,b)=n=1��10?(y^?n??f(xn?))2=n=1��10?(y^?n??(b+wxn?))2
������̿��Ƹ���,����ʵҲ�Ƿ���ֱ����,����˵,���ǽ���ʵֵ��Ԥ��ֵ����,ƽ����,�����,����ƽ��,��Ϊ�˱�����ʵֵС��Ԥ��ֵ�Ӷ����ָ����������,��Ϊ���ָ����ᵼ��������ʧ������ֵƫС,�Ӷ�Ӱ����жϡ�
Step3:�ݶ��½�ɸѡ����ģ��
������Ȼ����һԪ����ģ��
�������ڼ���,��������ʧ������,w,b������δȷ��,Ҳ����˵,������Ҫȷ�������w,b��ֵ,ʹ����ʧ������С,�������Dz����Ŀ�ꡣ��:
w
?
,
b
?
=
a
r
g
?
min
?
w
,
b
��
n
=
1
10
(
y
^
n
?
(
b
+
w
x
n
)
)
2
w^*,b^*=arg\ \underset{w,b}{\min}\sum_{n=1}^{10}{\left( \hat{y}_n-\left( b+wx_n \right) \right) ^2}
w?,b?=arg?w,bmin?n=1��10?(y^?n??(b+wxn?))2
$$
$$
��ôʵ����һ������,�����õ��ļ��ɾ���Gradient Descent,���ݶ��½���
�����ȼ��迼��wһ������,����Ҫ��һ��wʹ��������ʧ������С,���ǿ���������:
����1:���ѡȡһ��w0
����2:�Ըõ�����:
? ����>0:��ʹw0����,�õ�w1
? ����<0:��ʹw0����,�õ�w1
����3:����ѧϰ���ƶ�,���ظ�2,3��,ֱ��loss functionȡֵ��͡�
�������ó���,��Ҫ����,��,��ͼ:
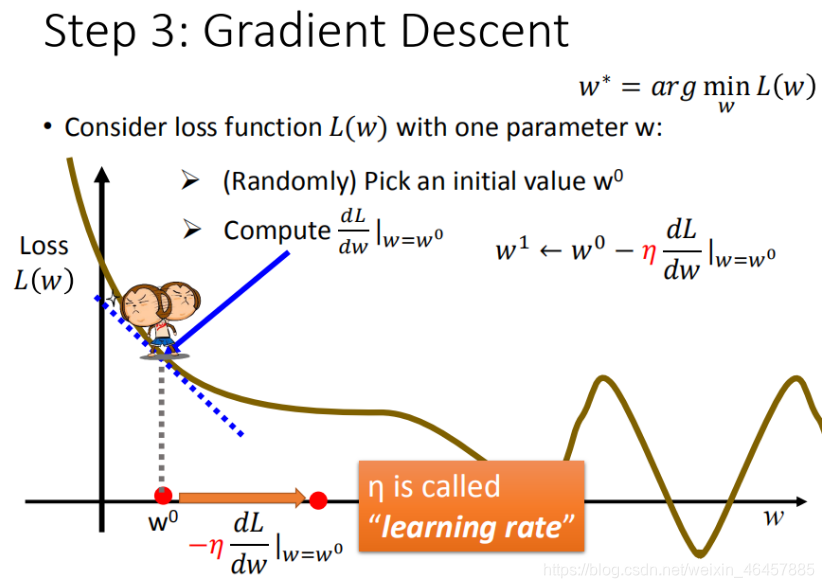
������������,���ǿ��Խ�ÿһ��w������������:
w
1
=
w
0
?
��
d
L
d
w
�O
w
=
w
0
w_1=w_0-\eta \frac{dL}{dw}\mid_{w=w_0}^{}
w1?=w0??��dwdL?�Ow=w0??
w 2 = w 1 ? �� d L d w �O w = w 1 w_2=w_1-\eta \frac{dL}{dw}\mid_{w=w_1}^{} w2?=w1??��dwdL?�Ow=w1??
�Դ�����,��ÿһ����õ��µ�w������ʧ����,ֱ����ʧ������С��
�����ʽ����������һ������
��
\eta
��
���dz�֮Ϊѧϰ�ʡ�
������ʽ�ӿ���ֱ�۸��ܵ�,ÿһ���µ�w��������һ��w�Ļ������ƶ��õ���,����Ӧ����ƶ��ġ�������,Ҳ���ǵ����ƶ����ٲ�,���ǾͿ��������ѧϰ����������
�ٸ�����˵,���������������ij�㴦����>0,��˵���õ���loss function��������,����ϣ���ҵ�loss function����Сֵ,��wһ������Сֵ��,��������ϣ����һ�����������wҪ�������ˡ�,��Ҫ�ټ�����������,��������Ҫʹ��w���١�
ͬ��,���������øõ㴦��<0,˵���õ㴦��loss function���½���,����ϣ���ҵ���Сֵ��,��ȻҪ����һ��w������ǰ��,����������w���ӡ����Ͻ���Ҳ��˵��,Ϊʲôѧϰ�ʵ�ϵ���Ǹ��ġ�
**�������w,b����ȷ���������?**��������Ҳ��һ����,����ľ���ƫ�֡�

������ͼ��ʾ��
�������ǻ�����һ������,���ǵ������ҵ���Сֵʱ,�����Сֵ��һ����ȫ����С,�������Ǿֲ���С,�������Ǻ���˵����
����ͼ��ƫ�ֲ���������һ����������ʽ,��:
?
L
=
[
?
L
?
w
?
L
?
b
]
g
r
a
d
i
e
n
t
\nabla L=\left[ \begin{array}{c} \frac{\partial L}{\partial w}\\ \frac{\partial L}{\partial b}\\ \end{array} \right] _{gradient}
?L=[?w?L??b?L??]gradient?
�����ݶ��½���ֱ�ۿ��ӻ�����:
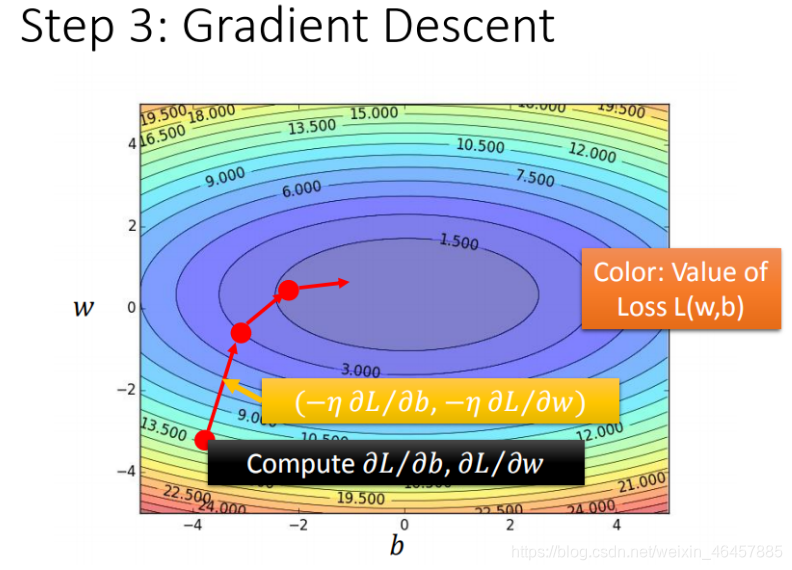
ÿһȦ�����൱�ڵ���ѧ�еĵȸ���,������ʧ������ֵ,��ɫԽ��,��ʧ����ԽС
���к�ɫ��ͷ�ķ���,����ÿһ���ȸ����ڸõ㴦�ķ��߷���,��������ƫ��ʱ,ʵ���Ͼ�����ȷ���������,���ŷ��߷�������ҵ����(��)��,һ�������ġ�
�ݶ��½��㷨����ʵ�����е�����:
�� ���뵱ǰ����
�� ����0
�� ������0
��֤��ѵ��ģ�͵ĺû��̶�
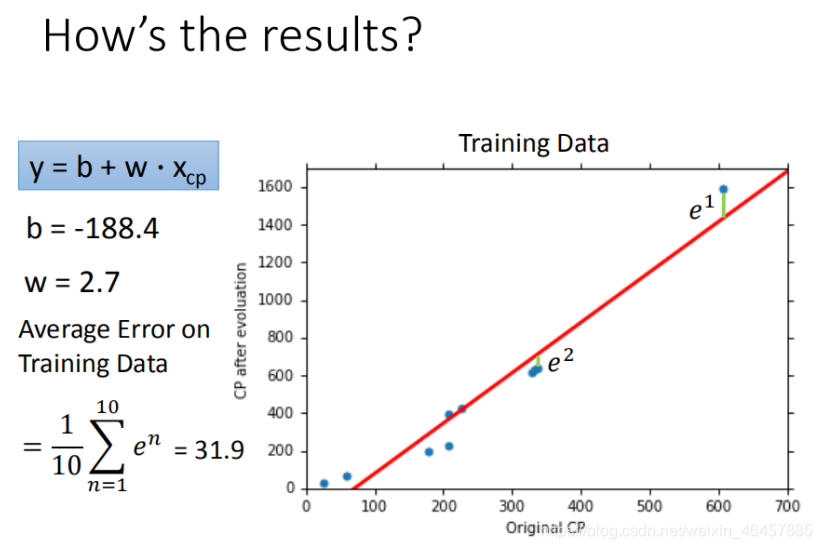
һԪ�ߴ�����ģ��
�������ᵽ�Ķ���һԪһ�ε�����ģ��,����ϳ̶���,�ֲ�����Ƚ�����,�������ǿ�������ߴη���,��:
y
=
b
+
w
1
x
c
p
+
w
2
x
c
p
2
+
?
+
w
n
x
c
p
n
y=b+w_1x_{cp}+w_2x_{cp}^2+\cdots +w_nx_{cp}^n
y=b+w1?xcp?+w2?xcp2?+?+wn?xcpn?
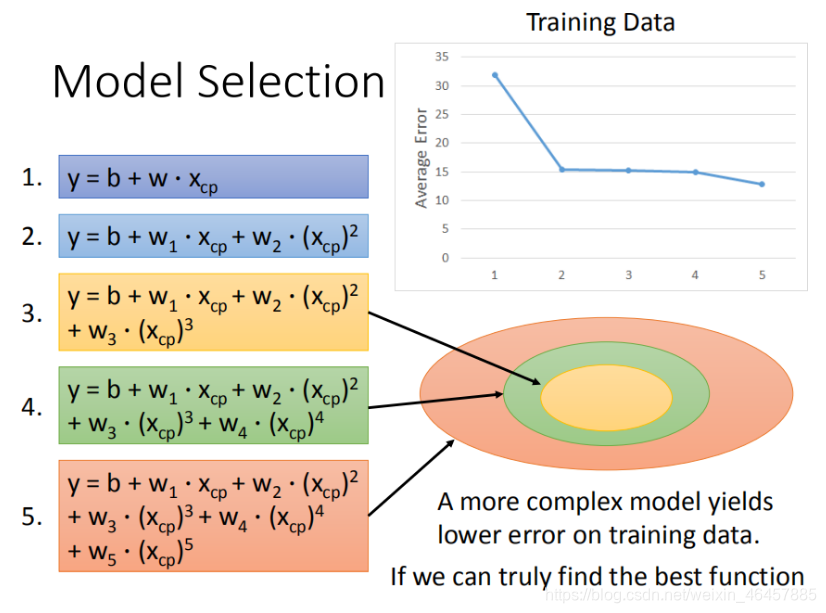
��������˵,������ߴη���������,ƽ�����Average ErrorҲ���½�,��������ζ�Ŵη���Խ��ģ�;�Խ��,����������������,����ͼ��ʾ:

���Կ���,��3�η�֮��ʼ,���Ѿ������˹��������,���ѡ��ģ��Ӧ�ø���ʵ�������뾫����ȷ����
�Ż�:������ģ��
�� ���������
����ģ����,����ֻ�����˾����ֽ��µ�CPֵ,�ݴ�Ԥ��������CPֵ����ʵ��������,��������Ƿ��,CPֵ��ȷ���п����ɶ������������,�������֡�
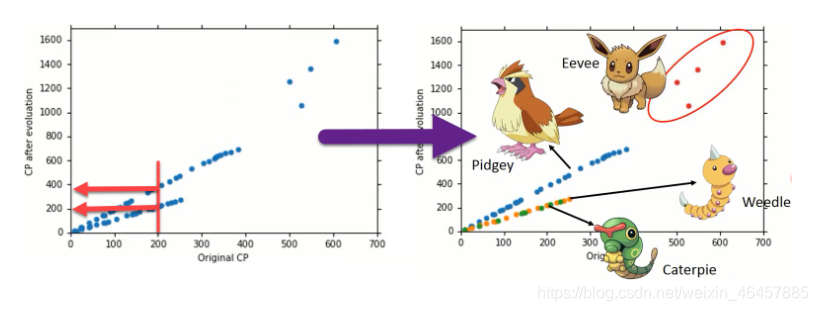
��ͼ��ʾ���ĸ����������ֵ�CPֵԤ��ģ��,���Կ�����ͬ���ֵĻع鷽���Dz�ͬ��,���ǽ��������ǽ�����4��ģ��,ͳһ��һ��ģ����ȥ��
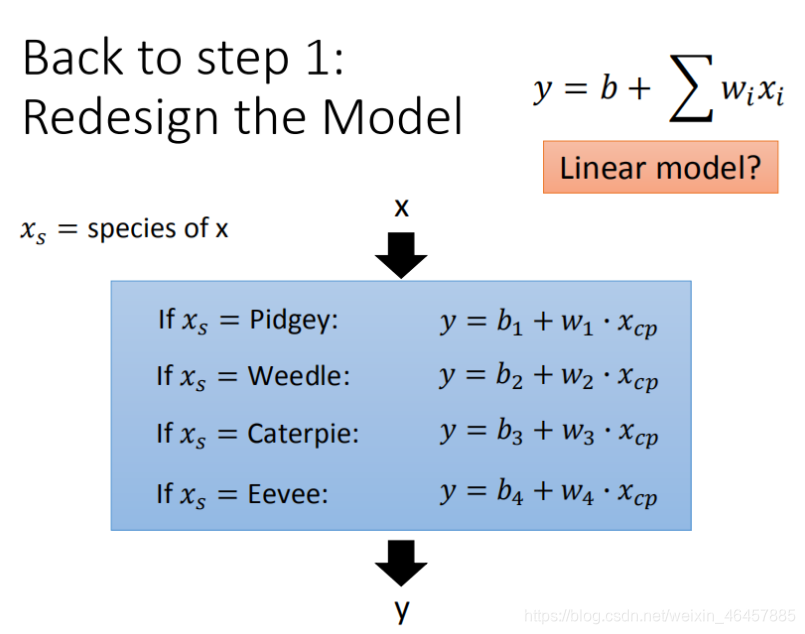
����������:
y
=
��
1
(
b
1
+
w
1
x
1
)
+
��
2
(
b
2
+
w
2
x
2
)
+
��
3
(
b
3
+
w
3
x
3
)
+
��
4
(
b
4
+
w
4
x
4
)
y=\delta _1\left( b_1+w_1x_1 \right) +\delta _2\left( b_2+w_2x_2 \right) +\delta _3\left( b_3+w_3x_3 \right) +\delta _4\left( b_4+w_4x_4 \right)
y=��1?(b1?+w1?x1?)+��2?(b2?+w2?x2?)+��3?(b3?+w3?x3?)+��4?(b4?+w4?x4?)
�������Ƕ���:
��
1
=
{
1
������
P
i
d
g
e
y
0
����
\delta _1=\begin{cases} 1& \text{������}Pidgey\\ 0& \text{����}\\ \end{cases}
��1?={10?������Pidgey����?
������������ͬ����
�� ����������
��������:
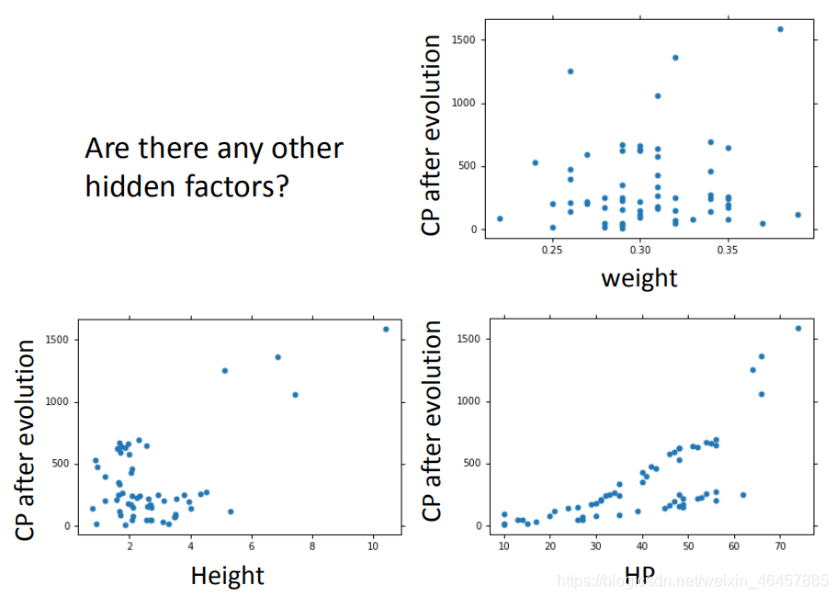
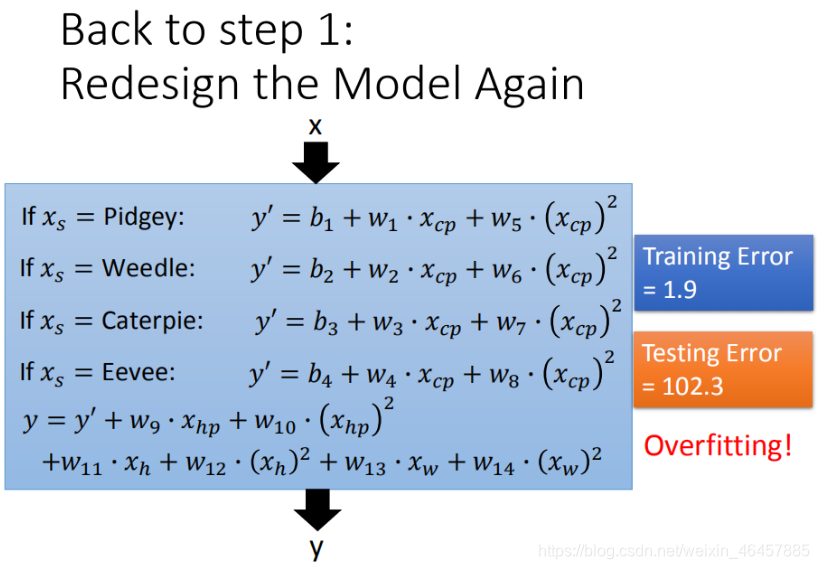
�� ��������(Regularization)
��ν��������,������ʧ����������ijЩ��,����ֹ������õ�ģ����ϵ�һ���ֶΡ�
���ǻص�֮ǰ��loss function,�ں������һ��:
L
=
��
n
(
y
^
n
?
(
b
+
w
i
x
i
)
)
2
+
��
��
w
i
2
L=\sum_n^{}{\left( \hat{y}_n-\left( b+w_ix_i \right) \right) ^2}+\lambda \sum{w_i^2}
L=n��?(y^?n??(b+wi?xi?))2+����wi2?
���ǵ�Ŀ�����˹������Ǹ�����ȡֵ,ʹ�����յ�wԽСԽ��,��������õ�ģ�ͺ���Խƽ��,ƽ������ζ�Ŷ�һЩ���ĸı䲻���С�
����ͼ��ʾ:
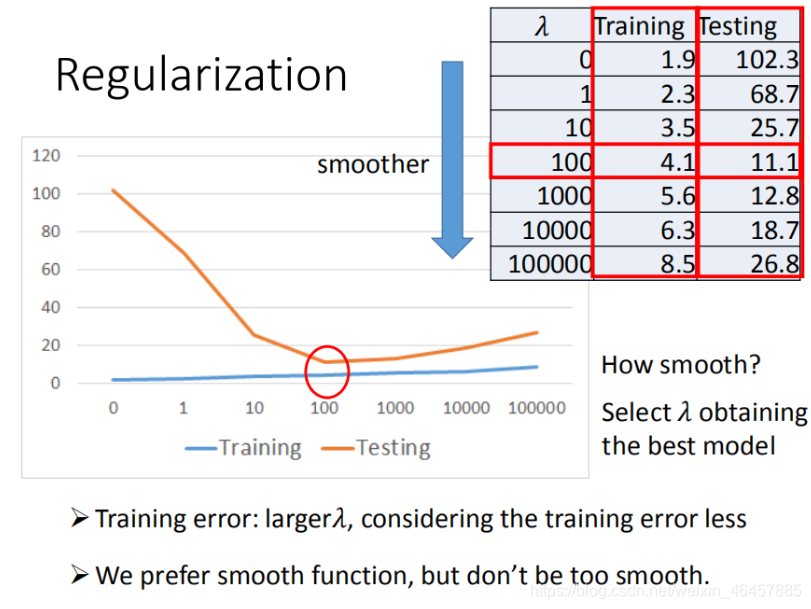
����ע�Ⲣ��Խƽ��Խ��,�ʵ��IJ�����õġ�����
�������ľ�������պ��л��ᶨ���ٳ�һƪ����ϸ����,����ȷ�����̸һ����~~