MNIST是一个手写体数字的图片数据集,该数据集来由美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。该数据集的收集目的是希望通过算法,实现对手写数字的识别。
1998年,Yan LeCun 等人发表了论文《Gradient-Based Learning Applied to Document Recognition》,首次提出了LeNet-5 网络,利用上述数据集实现了手写字体的识别。
Mnist数据集官网:http://yann.lecun.com/exdb/mnist/
数据下载
官网上提供了数据集的下载,主要包括四个文件:
| 文件下载 | 文件用途 |
|---|---|
| train-images-idx3-ubyte.gz | 训练集图像 |
| train-labels-idx1-ubyte.gz | 训练集标签 |
| t10k-images-idx3-ubyte.gz | 测试集图像 |
| t10k-labels-idx1-ubyte.gz | 测试集标签 |
在上述文件中,训练集一共包含了 60,000 张图像和标签,而测试集一共包含了 10,000 张图像和标签。测试集中前5000个来自最初NIST项目的训练集.,后5000个来自最初NIST项目的测试集。前5000个比后5000个要规整,这是因为前5000个数据来自于美国人口普查局的员工,而后5000个来自于大学生。
该数据集自1998年起,被广泛地应用于机器学习和深度学习领域,用来测试算法的效果,例如线性分类器(Linear Classifiers)、K-近邻算法(K-Nearest Neighbors)、支持向量机(SVMs)、神经网络(Neural Nets)、卷积神经网络(Convolutional nets)等等。
数据集解读
下载上述四个文件后,将其解压会发现,得到的并不是一系列图片,而是 .idx1-ubyte和.idx3-ubyte 格式的文件。这是一种IDX数据格式,其基本格式如下:
magic number
size in dimension 0
size in dimension 1
size in dimension 2
.....
size in dimension N
data
其中magic number为4字节,前2字节永远是0,第3字节代表数据的格式:
0x08: unsigned byte
0x09: signed byte
0x0B: short (2 bytes)
0x0C: int (4 bytes)
0x0D: float (4 bytes)
0x0E: double (8 bytes)
第4字节的含义表示维度的数量(dimensions): 1 表示一维(比如vectors), 2 表示二维( 比如matrices),3表示三维(比如numpy表示的图像,高,宽,通道数)。
训练集和测试集的标签文件的格式(train-labels-idx1-ubyte和t10k-labels-idx1-ubyte)
idx1-ubtype的文件数据格式如下:
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
- 第0 ~ 3字节,是32位整型数据,取值为0x00000801(2049),即用幻数2049记录文件数据格式,这里的格式为文本格式。
- 第4~7个字节,是32位整型数据,取值为60000(训练集时)或10000(测试集时),用来记录标签数据的个数;
- 第8个字节 ~ ),是一个无符号型的数,取值为对应0~9 之间的标签数字,用来记录样本的标签。
训练集和测试集的图像文件的格式(train-images-idx3-ubyte和t10k-images-idx3-ubyte)
idx3-ubtype的文件数据格式如下:
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
即:
-
第0 ~ 3字节,是32位整型数据,取值为0x00000803(2051),即用幻数2051记录文件数据格式,这里的格式为图片格式。
-
第4~7个字节,是32位整型数据,取值为60000(训练集时)或10000(测试集时),用来记录图片数据的个数;
-
第8~11个字节,是32位整型数据,取值为28,用来记录图片数据的高度;
-
第12~15个字节,是32位整型数据,取值为28,用来记录图片数据的宽度;
-
第16个字节 ~ ),是一个无符号型的数,取值为0~255之间的灰度值,用来记录图片按行展开后得到的灰度值数据,其中0表示背景(白色),255表示前景(黑色)。
数据读取
由于数据集的格式是一个特殊的二进制文件,规则如上所述。要读取数据,则需要按照文件数据结构进行解读,使用到了struct,并且涉及到Endian数据结构知识。有关资料如下:
这里我们尝试从训练集中读取并展示一组数据,首先将文件解压,将train-labels.idx1-ubyte?和?train-images.idx3-ubyte?文件放置同一路径下,并在此路径新建python文件,内容如下:
python
import os
import struct
import numpy as np
# 读取标签数据集
with open('./train-labels.idx1-ubyte', 'rb') as lbpath:
labels_magic, labels_num = struct.unpack('>II', lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
# 读取图片数据集
with open('./train-images.idx3-ubyte', 'rb') as imgpath:
images_magic, images_num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(images_num, rows * cols)
# 打印数据信息
print('labels_magic is {} \n'.format(labels_magic),
'labels_num is {} \n'.format(labels_num),
'labels is {} \n'.format(labels))
print('images_magic is {} \n'.format(images_magic),
'images_num is {} \n'.format(images_num),
'rows is {} \n'.format(rows),
'cols is {} \n'.format(cols),
'images is {} \n'.format(images))
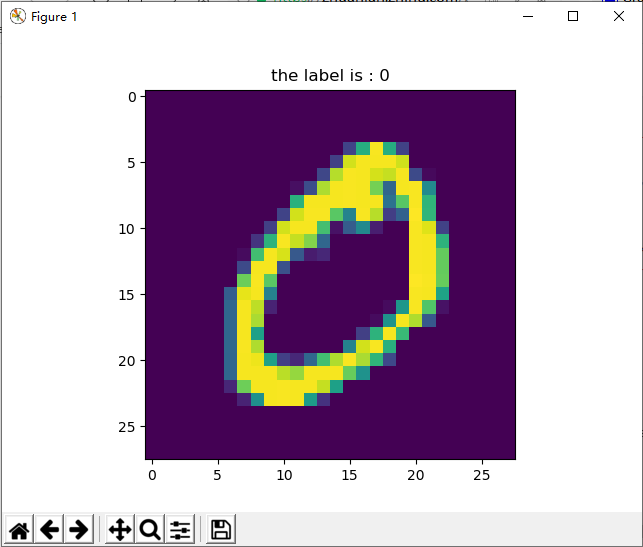
# 测试取出一张图片和对应标签
import matplotlib.pyplot as plt
choose_num = 1 # 指定一个编号,你可以修改这里
label = labels[choose_num]
image = images[choose_num].reshape(28,28)
plt.imshow(image)
plt.title('the label is : {}'.format(label))
plt.show()
结果如下:
shell
labels_magic is 2049
labels_num is 60000
labels is [5 0 4 ... 5 6 8]
images_magic is 2051
images_num is 60000
rows is 28
cols is 28
images is [[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
当然,目前已经有许多深度学习框架已经内置了Mnist数据集,并且有相关的函数直接读取并划分数据集,但是对数据集进行详细的解读十分有必要,相信有了上面的解读,你将对Mnist数据集更加深刻!