目录
前言
预训练模型,百度的ERNIE第三代。相比T5 10billion, GPT 175billion 还有清华的M6的100billion,它只有10billion个参数,并且效果在中文50多项NLP任务上,刷新了最好记录。重点关注中文预训练模型。
一、ERNIE结构分析
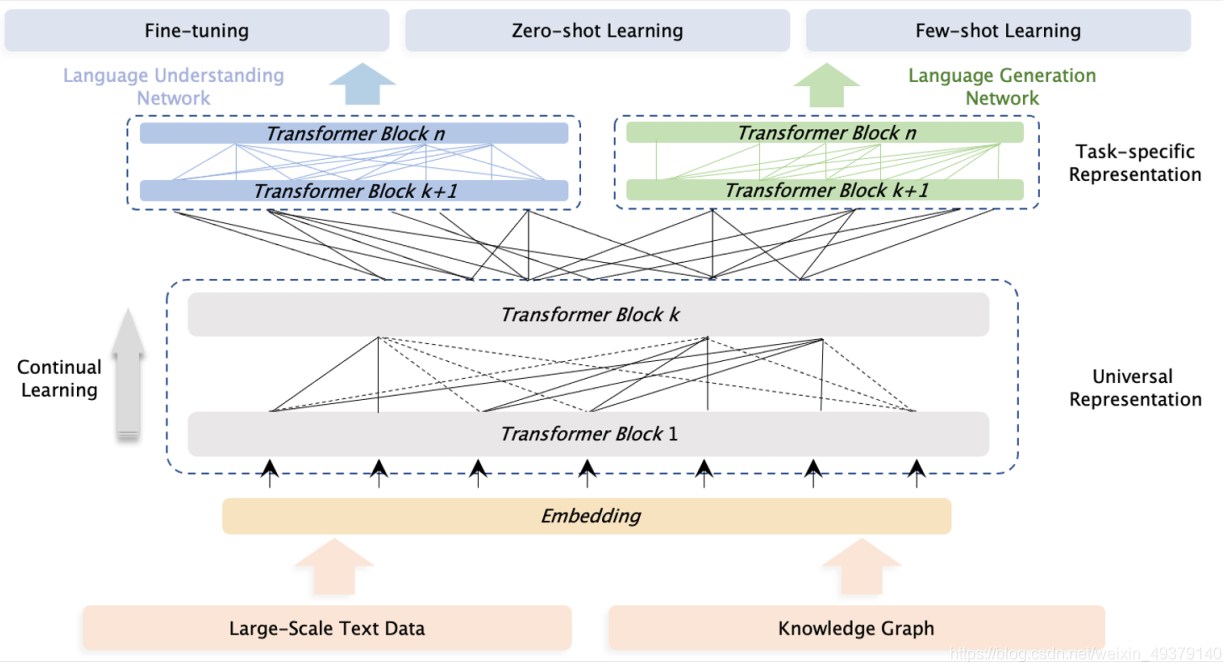
整个架构分为两个模块
1. Universal Representation Module, 负责提取语义特征(可以使用多层的transformer).在任何时候,这里权重都是共享。采用一个多层的transformer-XL作为backbone。
2.Task-specific Representation Modules,负责提取task-specific的语义特征,参数是从在执行task-specific任务上学习的。
- ERNIE3不仅可以提取不同任务中的task-specific语义信息,也可以解决大预训练模型在计算硬件和计算时间受限的问题。因为在fine-tune任务时,它能够只更新task-specific的网络。
- 也是一个多层的transformer-XL,因为它可以捕捉顶层的语义表征。这个模块设置成一个base model size的大小。这样做的好处有三点:a.基本网络有跟强的捕捉语义信息能力; b.可以减少模型参数; c.更小的的可以获得可以感知的,当只有一个fine-tune任务的时候,小模型会可以感知的实现效果。
- 这个模块包含NLU表征模块(双向网络) 和 NLG表征模块(无方向网络)
二、预训练的结构
1.基于字的Pretraining
Knowledge masked language modeling从ERNIE1.0开始就引用了知识融合。通过mask盖住短语与命名实体词。这样做可以让模型去学习上下文环境和全文环境的依赖关系信息?
Document Language Modeling生成的预训练模型使用传统的模型如GPT GPT2或者序列到序列模型如BART T5? ?ERNIE-GEN, 后者需要一个可靠的解码结构。 此处使用的是传统的方法。除此外,介绍了一种名为ENhanced Recurrence Memory Mechanism 在ERNIE-Doc中,能够比传统recurrence tranformer兼容更长的文本。实现的方法是是改变高层到底层的recurrence变成同层的recurrence.
2.基于结构的Pretraining
sentence reordering延续ERNIE2,目的是为了让模型去学习被打乱句子顺序的关系。一个自然段,被随机切分成1到m个片段,然后随机的打乱这些片段。然后模型要求去识别这些所有的组合,可以看作是一个k分类的问题??
sentence distance 修改传统长度NSP为一个三分类:
????????????????????????两个句子是否相邻;? ?不相邻句子是否在同一个文章;? ? 句子是否在不同文章?
3.基于知识的Pretraining
Universal Knowledge-text prediction(UKTP) 这个是知识词mask的延伸。 这里除了那些无结构化的知识词外,还需要知识图Graph.?
?三、预训练的流程
1.Pipeline
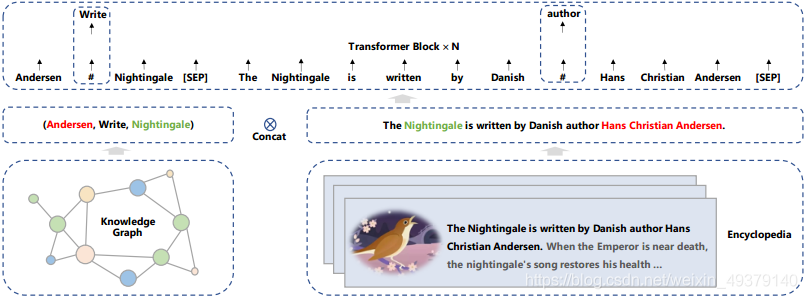
一对输入
- 知识图的三元组?
- 与之对应的百科里面的句子
Mask:随机的盖住三元组的关系与句子中的字 。
这样做的目的,是为了预测三元组的关系,模型需要识别出来三元组中实体的头和尾,然后再确定他们的在对应句子中的语义关系。处理的本质和distant supervision 算法在关系抽取任务中类似。distant supervision中,如果两个实体存在一种关系,任何包含这两个实体的句子都很大概率有这种关系。与此同时,在与之相对应的句子中预测字词,模型不仅需要考虑句子中的依存关系,也要考虑三元组的逻辑关系。
2.实例
一个从百科给出的句子,
? ?1. 首先去寻找知识图中的候选三元组,这些三元组中实体的头或者尾是文章的标题。?
? ?2.然后从候选三元组中选出一些,方法是选择那些实体头和尾都出现在文中同一个句子。
3.综述
ERNIE3.0训练NLU网络是通过知识掩盖的方法,去提升模型在学习词汇信息; sentence reordering
和sentence distance是为了学习语法信息;最后UKTP是提升模型的记忆能力和推理能力。另外ERNIE3.0 是通过文本语言模型来训练NLG网络
四、总结
1.数据处理
训练数据:很多
数据的处理数据做的处理:
1)去重
- 字级别的去重(删除一些标点)
- ?段落级别的去重(用一个单独的段落 替换掉 两个连续的完全一样的段落)
- 文本级别的去重(Message Digest5 MD5去重文本,是通过比较最长三个句子的MD5和是否相同)
2)字数少于10个的句子去掉
3)分词用百度自己的工具,去获得命名实体等,从而mask
2.模型参数
- 通用表征模型和具体任务表征模型都是使用Transformer-XL作为backbone
- 通用表征模型的结构为48层,4096个hidden units和64个头
- 具体任务表征模型结构为12层,758个hidden units和12个头
- 两种模型总共的参数有10billion
- 激活函数使用GeLU
- 最大的句子序列长度为6144
- Adam优化器,学习率是1e-4
总共375billion tokens, 使用了384块 v100显卡