题目
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations
作者:Shizhe Diao, Jiaxin Bai, Yan Song, Tong Zhang, Yonggang Wang
机构:创新工厂,香港科技大学
年份:2019
研究的问题:
关注预训练字符编码问题。对句子的细粒度例如词,子词,字符等相关的细片边界问题研究,中文的这个特点特别明显,中文的词或词组都是没边界标准的。
文章通过引用N-gram来处理这个问题,提出了ZEN[BERT-based Chinese (Z) text encoder Enhanced by N-gram representations],整合字符与词或词组信息去预训练。
模型

Figure 1: The overall architecture of ZEN, where the area marked by dashed box ‘A’ presents the character encoder (BERT, in Transformer structure); and the area marked by dashed box ‘B’ is the n-gram encoder. [NSP] and [MLM] refer to two BERT objectives: next sentence prediction and masked language model, respectively. [MSK] is the masked token. The incorporation of n-grams into the character encoder is illustrated by the addition operation presented in blue color. The bottom part presents n-gram extraction and preparation for the given input instance.
backbone model(character encoder): bert
N-gram Extraction
第一步, 准备一个n-gram的词典;---- 从预测语料的语料中抽取出词,根据他们的频率来过滤一批词出来,频率范围5~40。
第二步,在预训练时,根据每个训练样本从词典中选择n-gram词组;
第三步,把这些词组根据训练样本构造一个匹配矩阵M来记录相关位置;即是每个词构成一个向量,向量长度为句子字符数,词在对应位置是标为1,否则为0.有点像是one-hot.
Encoding N-grams
B部分。
Transformer作为编码器。
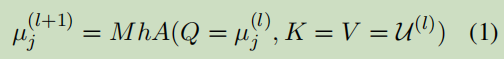
u_j_l:表示第j个n-gram在第l层隐向量;MhA:multi-head self-attention,多头自关注;
补充一个知识点----MhA:

Representing N-grams in Pre-training
A部分。
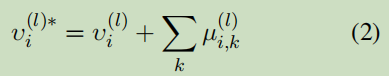
这里的i表示输入样本的第i个字符,后面的k表示这个字符出现在n-gram上的个数,采用了把所有向量的按元素相加。采用这种方式把n-gram加入正常的bert中。对于bert中的每层都采用这种方式进行注入n-gram的信息。
实验
任务及数据集
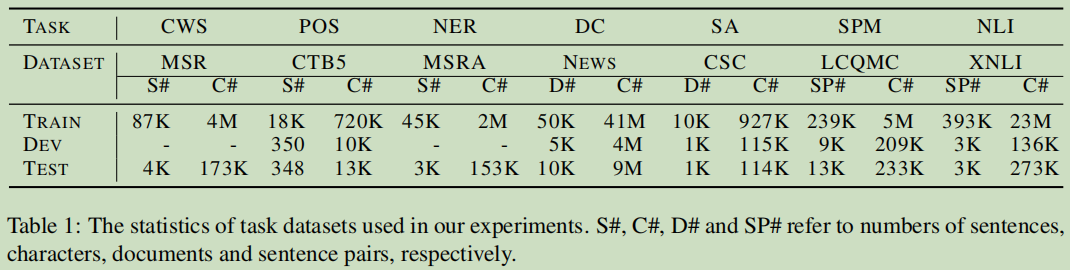
注意,这里有一个语料工具Chinese Wikipedia dump:https://dumps.wikimedia.org/zhwiki/
预测训练的语料:474M tokens and 23K unique characters
fine-tunnig任务(7个):Chinese word segmentation (CWS),Part-of-speech (POS) tagging,Named entity recognition (NER),Document classifification (DC),Sentiment analysis (SA),Sentence pair matching (SPM),Natural language inference (NLI).
结果
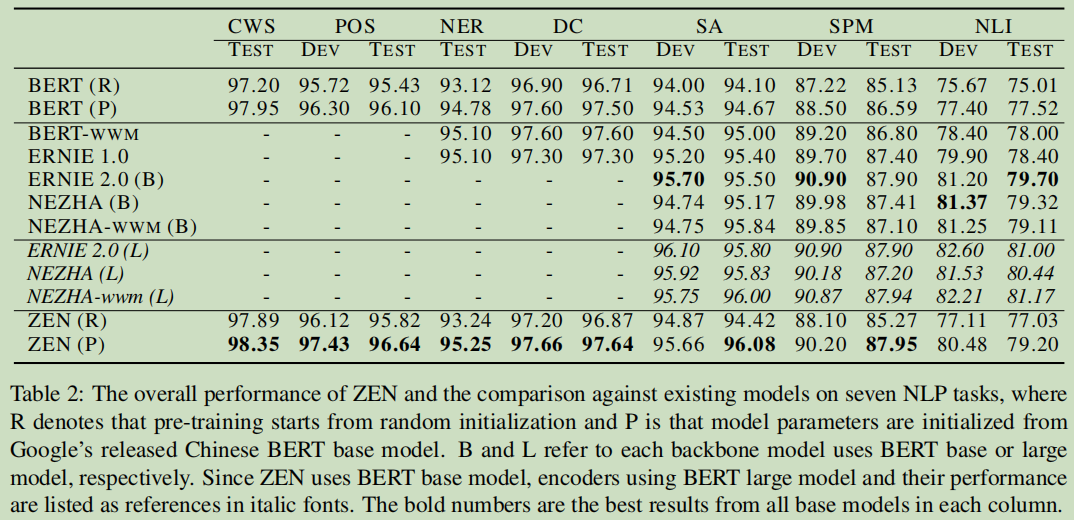
对专门的领域,小样本是一个硬伤,小样本时的对比,这里数据采用之前的1/10的规模:

分析
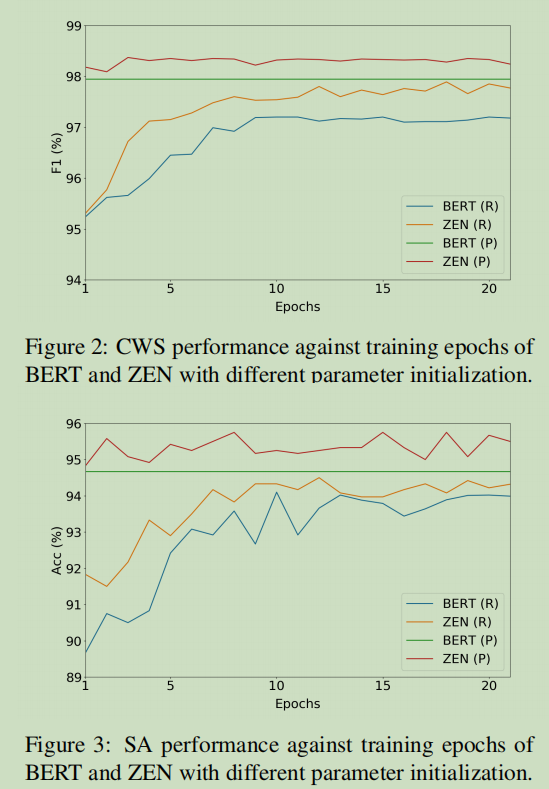
预训练中Epochs的影响
Effects of N-gram Extraction Threshold
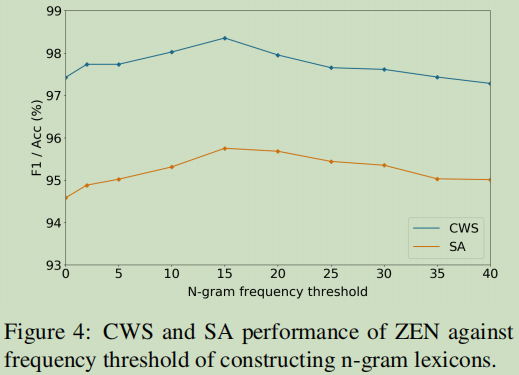
词频的研究,这个曲线可以看到选用15.
最大n-gram数影响对比
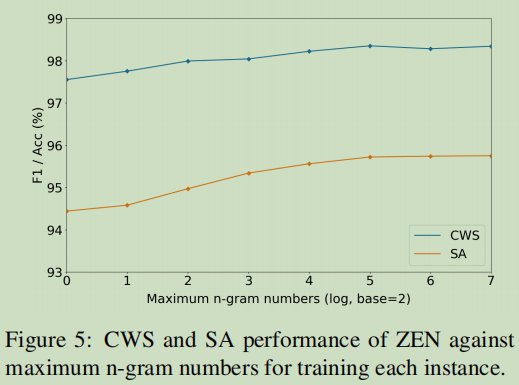
这里看到n=5就趋向平稳了。
Visualization of N-gram Representations
可以从编码后的权重来突显出哪些词是有效的:
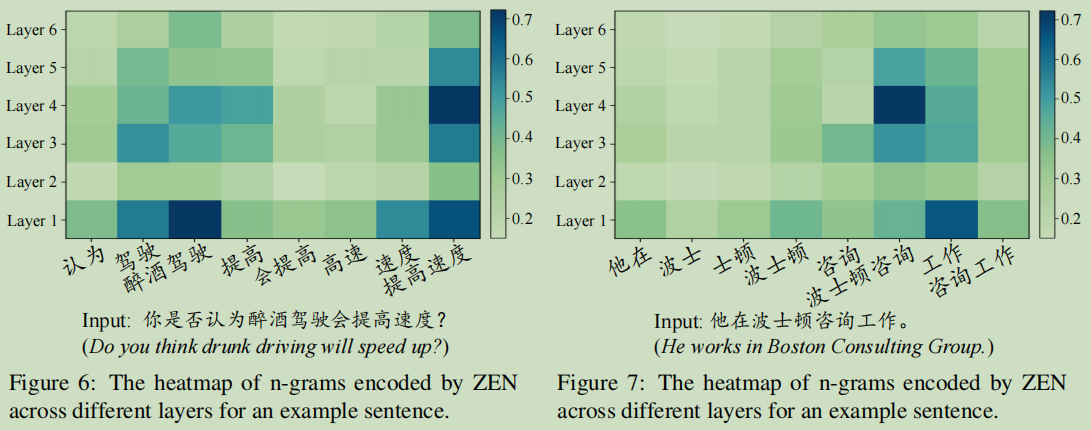
总结
提出了zen;
Bert结构可以通过另外的Transformer来扩展;
只是用了语料本身的数据,没有引入其它数据,对于少量数据预测也有一定的效果;
Zen采用了不同的方法去整合词信息;
评价
通过另外一个网络的编码来向主编码网络加入n-gram的信息,方法是挺新的,在bert方面。之前bert的很多改进在mask上,在目标任务上也很多。
参考
https://arxiv.org/abs/1911.00720
https://github.com/sinovation/ZEN
happyprince