原文:https://arxiv.org/abs/2107.01319
笔记:百度网盘提取码:zg95
1 摘要
- 提出层次化GNN模型,将一组图像聚类成n个实体
- 使用一种新方法融合不同层次间的连接成分,从而在下一层形成新的图
- Hi-LANDER模型与当前基于GNN的聚类算法相比,F-score平均提高了54%,标准化相互信息(NMI)平均提高了8%。
- 用统一框架预测节点信息(这里指节点密度)和边信息(指节点间的连接概率),减少了7倍计算量。
2 解决的问题
- 元学习解决方案利用元数据集(训练集数据和测试集数据label不一致)来聚合新的未知类别数量的数据
3 方法思路
- 概述:利用KNN算法进行图像聚合,每个图像代表图中每个节点,节点属性是图像的视觉嵌入特征,边则连接了与该节点相连的k个其他节点(k表示KNN算法中的k),函数φ通过节点图G = {V, E}和节点特征F得到边子集E’ = φ(G, F),从而更新得到的新节点图G = {V, E’} 。
- Hi-LANDER模型如图所示
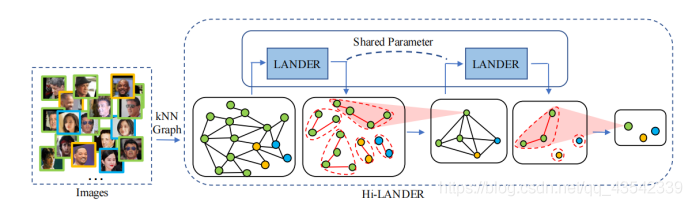
- 相同颜色代表相同label,首先通过KNN算法聚类成图结构,进一步通过多个LANDER模型进行分层聚类。其中LANDER模型是一个GNN模型,用于估计节点密度特征和边连接属性。
- 具体算法流程如下:

算法大致理解:
- 输入节点个数N、节点特征F、KNN算法k
- 根据KNN聚合得到图G,H表示节点特征(视觉嵌入特征)
- 将(G,H)作为E0 = φ(G, F)公式的输入,得到边缘信息
- 将得到的E通过连接组件(其实就是节点)得到聚合后的新图G’,
- 将得到的新图G’和H作为函数ψ的输入,得到新的节点特征H’
- (2)―(5)循环终止条件:节点已经完全聚合,即没有新边产生
- Return:最后一层图结构中节点,以及每个节点包含的初始节点
整个模型中有3点需要介绍:
1. 边信息聚合函数:φ函数
- (1)φ是一个GAT模型,输入为各个节点的密度特征和边连接信息(邻接矩阵),输出新的边缘连接信息
- (2)图编码过程:对于每两个节点之间的边,采用拼接的方式组成[h1,h2],然后通过MLP和softmax得到两个节点相连接的概率,
定义两节点间的相似度为特征向量的内积,即

随后计算相应的边缘信息,其中P(yi=yj)代表两个节点相同的概率,即MLP的输出。

最后,节点密度则如下定义:di表示节点密度,k表示源节点周围选定的次节点个数,也就是KNN算法中的k

注:当目标节点与次节点最相似,且具有共同label时,密度d就会很大。 - (3)图解码过程:
设定候选边集,E表示原始边集合(即KNN算法中源节点与k个节点之间的边集),pτ表示边缘连接阈值。论文强调阈值是在元训练集中的验证集上调节的超参数,而在新的元测试集上时,它是已经确定的参数,与无监督学习中可随意调节的聚类个数有所不同。

在遍历完所有节点后,E形成一组connected component,用于聚合节点 - 为什么要设置di<dj? 因为di较小时表示该节点周围的相似同标签节点较少,说明该节点处在不同节点重合的区域中,这种节点往往离聚类中心更远,个人认为体现了一个从密度高往密度低方向聚类的过程。
2. 节点特征聚合函数ψ

- 定义了两个节点特征:
(1)身份特征:其中mi 表示对节点密度特正经进行argmax的结果,也就是说每一个component选择密度最大的那个特征。

(2)均值特征:与身份特征类似,只不过这里是求平均

身份特征可以用于识别跨层次结构的类似节点,而平均特征提供了集群中所有节点的信息的概述。将两个特征拼接作为变换后的节点特征。
3. Hi-LANDER模型训练
- 给定k、label以及聚类层数L即可开始训练,
损失函数如下:包括两项

第一项:计算根据边缘信息预测的相邻节点的类别来计算损失函数

第二项:计算邻居节点的平均损失,也就是让相邻节点间的差距变小

4 小结
- 文章提出了一种基于GAT的层次化聚类的方法,损失函数中的第一项计算的是全层次的总体损失,也就是说既顾及总体,又有层次信息。能否将其迁移至面向对象遥感分割,将每个对象视为一个节点,光谱特征视为节点信息,邻接矩阵表示边缘信息,利用图模型融合先验知识驱动影像分割?
- 遥感影像中蕴含着丰富的多尺度信息,能否借助这种端到端的聚类方式迁移至影像信息提取上。
- 初探图模型,了解程度有所欠缺,有不对的地方烦请批评指正。