目录
sklearn 代码相关
2.1 sklearn生成数据集
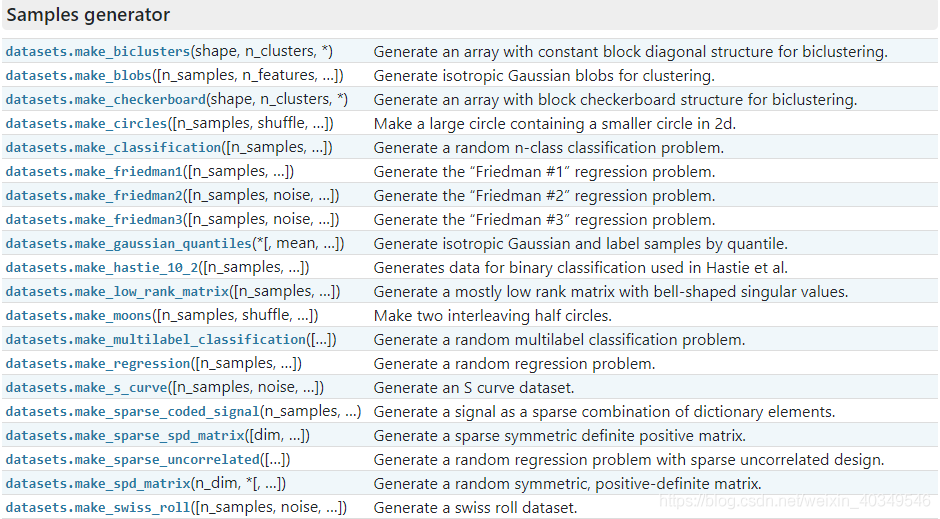
eg. 生成符合正态分布的聚类数据
from sklearn import datasets
x, y = datasets.make_blobs(n_samples=5000, n_features=2, centers=3)
2.2 sklearn 构建完整的回归项目
- 明确项目任务:回归/分类
- 收集数据集并选择合适的特征。
- 选择度量模型性能的指标。
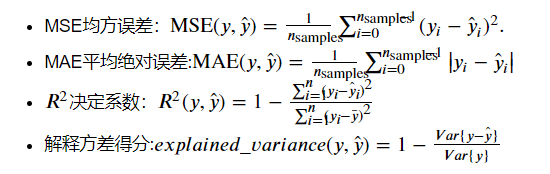
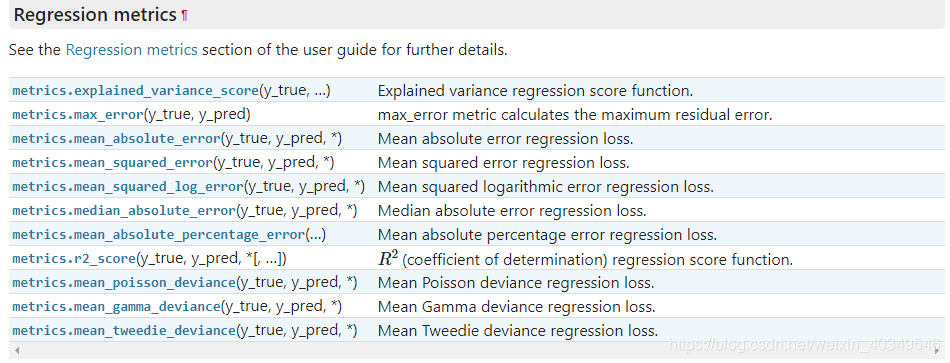
- 选择具体的模型并进行训练以优化模型。
- 特征选择
- 对测试误差进行估计
- 训练误差修正:?加入关于特征个数的惩罚
- 交叉验证:我们把训练样本分成K等分,然后用K-1个样本集当做训练集,剩下的一份样本集为验证集去估计由K-1个样本集得到的模型的精度,这个过程重复K次取平均值得到测试误差的一个估计
- 对测试误差进行估计
- 压缩估计
- 将回归系数往零的方向压缩
- 岭回归
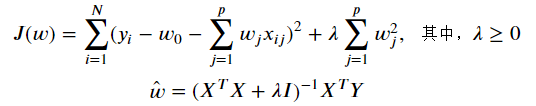
-
from sklearn import linear_model reg_rid = linear_model.Ridge(alpha=.5) reg_rid.fit(X,y) reg_rid.score(X,y)
- LASSO回归

-
from sklearn import linear_model reg_lasso = linear_model.Lasso(alpha = 0.5) reg_lasso.fit(X,y) reg_lasso.score(X,y)
- 岭回归
- 将回归系数往零的方向压缩
- 特征选择
测试均方误差曲线呈现U型曲线,这表明了在测试误差曲线中有两种力量在互相博弈。增加模型的复杂度,会增加模型的方差,但是会减少模型的偏差,我们要找到一个方差--偏差的权衡,使得测试均方误差最小。
-
?评估模型的性能并调参
- 超参数
- 网格搜索
- 随即搜索
- 可以独立于参数数量和可能的值来选择计算成本。
- 添加不影响性能的参数不会降低效率。
- 超参数
2.3 回归模型
2.3.1 线性回归模型
求解
利用最小二乘估计,解的
线性回归最小二乘估计噪声
的极大似然估计
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??的解, 即
在
平面上的投影
代码?

?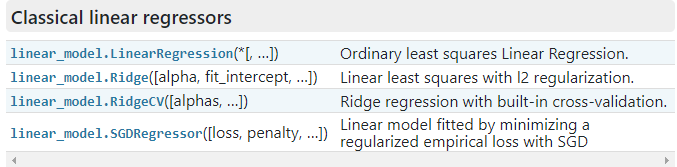
?lin_reg.coef_ 为模型系数
2.3.2 多项式回归
?![]()
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(2)
poly.fit_transform(X)2.3.3 广义可加模型(GAM)

from pygam import LinearGAM
gam = LinearGAM().fit(boston_data[boston.feature_names], y)
gam.summary()2.3.4 回归树

from sklearn.tree import DecisionTreeRegressor
reg_tree = DecisionTreeRegressor(criterion = "mse",min_samples_leaf = 5)
reg_tree.fit(X,y)
reg_tree.score(X,y)2.3.5 支持向量机回归(SVR)
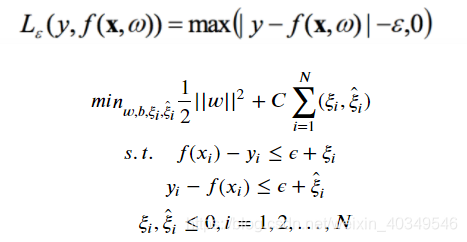
?落在f(x)的
邻域空间中的样本点不需要计算损失,看为正确的预测

from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler # 标准化数据
from sklearn.pipeline import make_pipeline # 使用管道,把预处理和模型形成一个流程
reg_svr = make_pipeline(StandardScaler(), SVR(C=1.0, epsilon=0.2))
reg_svr.fit(X, y)
reg_svr.score(X,y)代码技巧:
1.?对数据集转换成DataFrame格式的数据
iris_data = pd.DataFrame(X,columns=features)2.对数据特征进行可视化
marker = ['s','x','o']
for index,c in enumerate(np.unique(y)):
plt.scatter(x=iris_data.loc[y==c,"sepal length (cm)"],y=iris_data.loc[y==c,"sepal width (cm)"],alpha=0.8,label=c,marker=marker[c])
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.legend()
plt.show()3.?使用管道,把预处理和模型形成一个流程
from sklearn.pipeline import make_pipeline # 使用管道,把预处理和模型形成一个流程
reg_svr = make_pipeline(StandardScaler(), SVR(C=1.0, epsilon=0.2))